How to calculate Renyi entropy from heart rate variability, and why it matters for detecting cardiac autonomic neuropathy
 David J. Cornforth
David J. Cornforth Mika P. Tarvainen
Mika P. Tarvainen Herbert F. Jelinek
Herbert F. Jelinek- 1Applied Informatics Research Group, Faculty of Science and IT, The University of Newcastle, Callaghan, NSW, Australia
- 2University of Eastern Finland, Kuopio, Finland
- 3Kuopio University Hospital, Kuopio, Finland
- 4Charles Sturt University, Albury, NSW, Australia
Cardiac autonomic neuropathy (CAN) is a disease that involves nerve damage leading to an abnormal control of heart rate. An open question is to what extent this condition is detectable from heart rate variability (HRV), which provides information only on successive intervals between heart beats, yet is non-invasive and easy to obtain from a three-lead ECG recording. A variety of measures may be extracted from HRV, including time domain, frequency domain, and more complex non-linear measures. Among the latter, Renyi entropy has been proposed as a suitable measure that can be used to discriminate CAN from controls. However, all entropy methods require estimation of probabilities, and there are a number of ways in which this estimation can be made. In this work, we calculate Renyi entropy using several variations of the histogram method and a density method based on sequences of RR intervals. In all, we calculate Renyi entropy using nine methods and compare their effectiveness in separating the different classes of participants. We found that the histogram method using single RR intervals yields an entropy measure that is either incapable of discriminating CAN from controls, or that it provides little information that could not be gained from the SD of the RR intervals. In contrast, probabilities calculated using a density method based on sequences of RR intervals yield an entropy measure that provides good separation between groups of participants and provides information not available from the SD. The main contribution of this work is that different approaches to calculating probability may affect the success of detecting disease. Our results bring new clarity to the methods used to calculate the Renyi entropy in general, and in particular, to the successful detection of CAN.
Introduction
Cardiovascular function is controlled by intrinsic and extrinsic mechanisms including membrane properties of the sino-atrial node, neuro-hormonal, and autonomic nervous system (ANS) modulation (Valensi et al., 2002; Vinik et al., 2003). The natural rhythm of the human heart is known to vary in response to sympathetic and parasympathetic signals and dysfunction of either of these mechanisms is often associated with diabetes, which can manifest at different times during diabetes disease progression. This dysfunction is referred to as cardiac autonomic neuropathy (CAN) (Pop-Busui, 2010; Tarvainen et al., 2013). As it affects the control of heart rate, it should be manifested in changes to cardiovascular rhythm, which are observable and therefore classifiable.
A common type of ECG signal is shown in Figure 1. Such signals have been studied extensively and the diagnostic value of the different features is well established. The RR interval, shown in Figure 1, is the time between successive heart beats. Heart rate is the reciprocal of this. Generally, sympathetic activity increases heart rate and decreases variability, whereas parasympathetic activity decreases heart rate and increases variability (Berntson et al., 1997). Therefore, heart rate variability (HRV) is a useful indication of the health of the cardiovascular system, and is commonly used in assessing the regulation of cardiac autonomic function (Flynn et al., 2005; Vinik et al., 2013). HRV may be described by a variety of measures such as time domain, frequency domain, and non-linear measures (TFESC, 1996; Khandoker et al., 2009; Sacre et al., 2012).
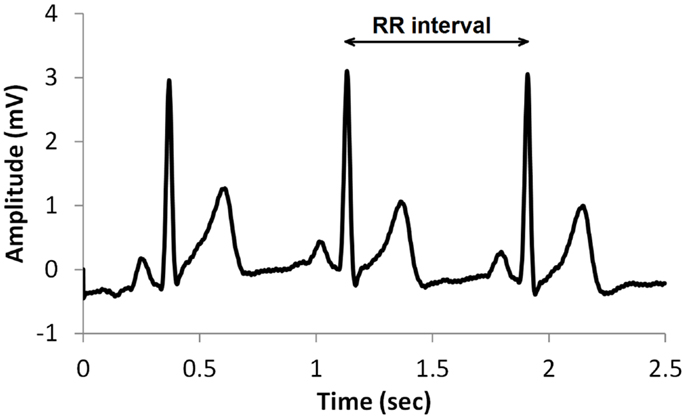
Figure 1. A typical ECG signal showing the RR interval.
Guidelines for the use of HRV for clinical practice were established in 1996 and included time and frequency domain measures as well as non-linear analysis and geometric methods from the time signal in the form of heart rate or inter-beat intervals (RR intervals) (TFESC, 1996). Geometrical methods are less sensitive to noise in the biosignal and offer a good alternative to the more often time and frequency domain analysis applied to determine HRV (Sztajzel, 2004) but require longer recording times (Malik and Camm, 1993). Geometric methods require the time series to be converted to a discrete scale, which allows the binning of RR intervals as histograms. More recently, geometric-based methods have also been shown to be robust for classification of CAN with shorter recording periods (Karmakar et al., 2009, 2013; Jelinek et al., 2013). Geometric methods are in general based on converting the RR intervals into a geometric form such as a triangle or ellipse, which can assist with visualization and can provide summary measures such as measures that describe the shape of such figures, to be calculated. Another approach is to express the RR intervals as a frequency distribution histogram, which can then be analyzed (Nasim et al., 2011). Common examples of HRV features derived from the geometric forms include the triangular index (Tri), triangular interpolation of NN interval (TINN), the Poincaré plot including the complex correlation method (CCM), and wavelet-based analysis (Tulppo et al., 1996; Acharya et al., 2002, 2006; Voss et al., 2007). More recent geometric methods for HRV analysis include the entropy measures, especially if the feature extracted is based on a histogram presentation of the RR intervals or autoregressive spectral estimation of the tachogram (Wessel et al., 2000; Tarvainen et al., 2013).
Non-linear measures include determination of the time signal’s entropy in an attempt to quantify randomness in the system and include approximate entropy (ApEn), sample entropy (SampEn), and multiscale entropy (MSE). Renyi entropy generalizes the Shannon entropy and includes the Shannon entropy as a special case (Rényi, 1960). Renyi entropy H is defined as:
where pi is the probability that a random variable takes a given value out of n values, and α is the order of the entropy measure. H(0) is simply the logarithm of n. As α increases, the measures become more sensitive to the values occurring at higher probability and less to those occurring at lower probability, which provides a picture of the RR length distribution within a signal. However, the entropy requires an estimate of probabilities, and there are a number of ways in which this can be determined.
The histogram method has advantages in terms of its low computational effort and its ability to allow a simple visualization of the distribution of RR values. However, its reliance on binning the data points introduces an artificial discretization, leading to a boundary problem where an individual value may be included in one bin or the other depending on a very small perturbation. This can be ameliorated by using a smoothing method that spreads data points into adjacent bins, but does not take into account how close a particular data point was to the bin boundary. Figures 2–4 show histograms of detrended RR intervals using data from participants in this study classified as Normal (N), Early CAN (E), or Definite CAN (D), respectively. The effect of the discretization is clear, especially for the data from participants with definite CAN (Figure 4), where all RR intervals fell into only two bins. The difference in distribution between the three classes is also clear, with participants in the Normal group (Figure 2) showing much greater variability of RR intervals than those with CAN (Oida et al., 1999; Khandoker et al., 2009). Notice also that this particular example of early CAN (Figure 3) appears to fit somewhere between Normal and Definite CAN.
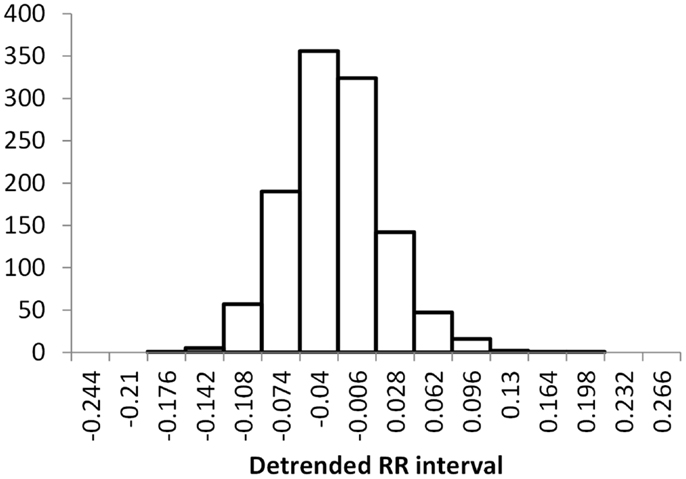
Figure 2. Histograms of the detrended RR intervals for participants in the Normal group made using the same bin divisions for all data used. The vertical axis shows the count of RR intervals falling into each bin. The SD is 0.050.
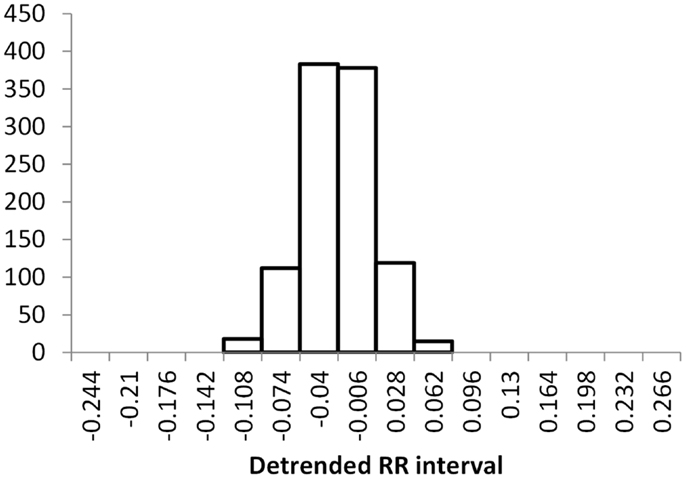
Figure 3. Histograms of the detrended RR intervals for participants in the Early CAN group made using the same bin divisions for all data used. The vertical axis shows the count of RR intervals falling into each bin. The SD is 0.038.
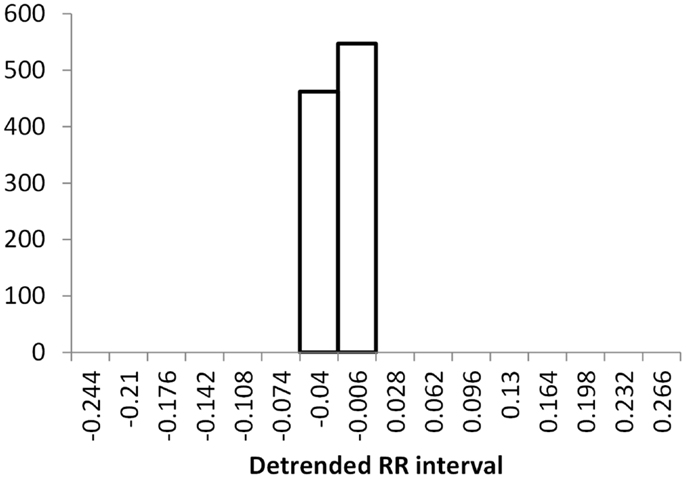
Figure 4. Histograms of the detrended RR intervals for participants in the Definite CAN group made using the same bin divisions for all data used. The vertical axis shows the count of RR intervals falling into each bin. The SD is 0.026.
An alternative approach is to estimate the probability of an individual RR interval using a notional density of space around the individual data point. This can be done by considering other RR intervals in the vicinity of the individual RR interval using Euclidean distance and imposing a threshold. For example, a calculation of sample entropy is described in Costa et al. (2002) as counting all RR intervals that are closer to the individual RR interval given a specific threshold. However, this still introduces a boundary problem and depends on choosing a suitable value for the threshold. Alternatively, a Gaussian kernel is centered on the individual RR interval and all RR intervals are added, weighted by the Gaussian function, based on the distance between the individual RR interval and the other RR intervals. A density measure can be calculated for the individual RR interval with index i, as the sum of all contributions from other RR intervals with index j:
where σ is a parameter of the method and controls the dispersion of the function, and distij is the Euclidean distance between two RR intervals:
Apart from the advantage of allowing a continuous rather than a discretized measure, this method also allows more than one dimension, as long as a suitable distance measure can be provided. In the case of RR intervals, higher dimensions allow sequences of RR intervals to be compared, rather than individual RR intervals. In this case, a single RR interval with length RRi is replaced by a sequence of RR intervals Si,λ = {RRi+1, RRi+2, RRi+λ}, where λ is the number of intervals in the sequence of length λ. The calculation of distance now becomes:
where 1 ≤ k ≤ λ.
This value of distij can be used in Eq. 2 to estimate the probability of a sequence of RR intervals, and the resulting probability can be used in Eq. 1 to calculate the Renyi entropy of a sequence of RR intervals. This provides several advantages over the histogram method. First, there are no boundary issues associated with placing RR intervals into a finite number of bins, where the bin boundaries are set at arbitrary values, possibly introducing bias. Second, this method can be applied to sequences of RR intervals, where this is infeasible for the histogram method. This method does, however, have two parameters to set: the sequence length λ and the Gaussian dispersion σ.
Figures 5–7 show visualization of the results of this process, for Normal, Early CAN, and Definite CAN classes, respectively. For every RR interval, its density measure ρ has been plotted against the RR interval value. This results in a much smoother curve than the histogram method, and note that each graph shown here comprises approximately 1000 points. As with the figures showing histograms, the effects of CAN may be seen in terms of the reduced variability of heart rate.
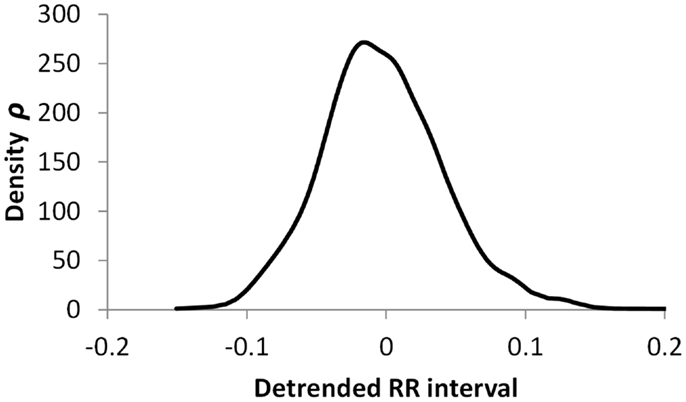
Figure 5. Density of detrended RR intervals plotted against the RR interval value for participants in the Normal group. The SD is 0.030.
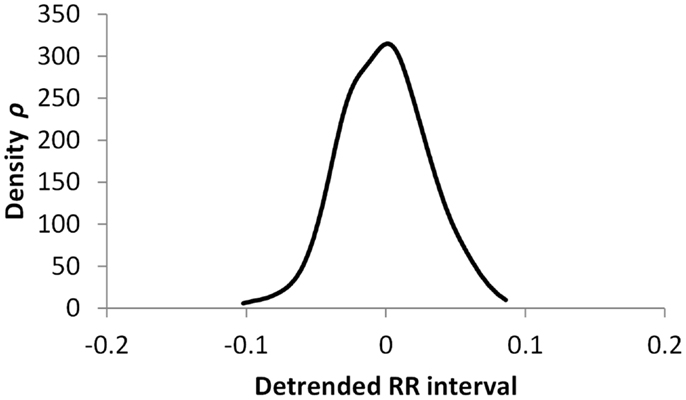
Figure 6. Density of detrended RR intervals plotted against the RR interval value for participants in the Early CAN group. The SD is 0.023.
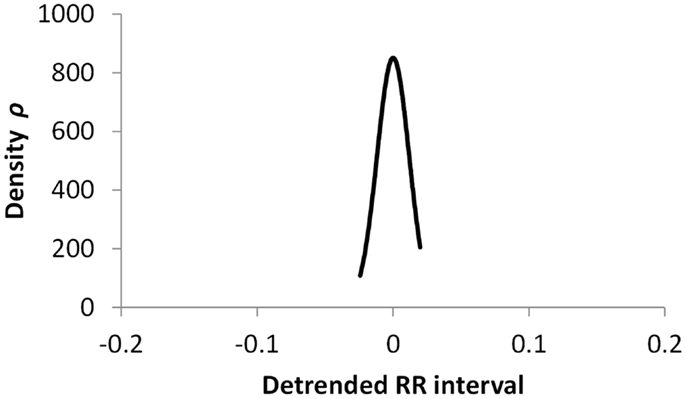
Figure 7. Density of detrended RR intervals plotted against the RR interval value for participants in the Definite CAN group. The SD is 0.006.
Materials and Methods
The work reported here used data from the Charles Sturt Diabetes Complications Screening Group (DiScRi), Australia (Jelinek et al., 2006). The study was approved by the Charles Sturt University Human Ethics Committee, and written informed consent was obtained from all participants. A 20-min lead II ECG recording was taken from participants attending the clinic, using a Maclab Pro with Chart 7 software (ADInstruments, Sydney, NSW, Australia). Participants were comparable for age, gender, and heart rate, and after initial screening, those with heart disease, presence of a pacemaker, kidney disease, or polypharmacy (including multiple anti-arrhythmic medication) were excluded from the study. The same conditions were used for each participant. The status of CAN was defined using the Ewing battery criteria (Ewing et al., 1985; Javorka et al., 2008; Khandoker et al., 2009), and each participant was assigned as either without CAN (71 participants), early CAN (67 participants), or definite CAN (11 participants). From the 20-min recording, a 15 min segment was selected from the middle in order to remove start up artifacts and movement at the end of the recording. From this shorter recording, the RR intervals were extracted. No other information was used in this study. The RR interval series for each participant was pre-processed using the Kubios HRV software (Tarvainen et al., 2014). Ectopic and other aberrant beats, if any, were first corrected using a simple threshold based artifact correction algorithm of the software. The very low frequency trend components (frequencies below 0.04 Hz) were then removed from the RR interval series using a smoothness priors detrending method (Tarvainen et al., 2002). All the HRV measures were then applied on these pre-processed data.
The SD of RR intervals as a time domain feature and the Renyi entropy, using a scaling exponent α of integer values from −5 to +5, were analyzed. The Renyi entropy was calculated using nine different methods for calculating the probabilities, resulting in 90 Renyi measures for every participant (values for α = 0 were discarded since these measure only the support). For probabilities calculated using histograms, the RR intervals were separated into 30 bins using bin boundaries calculated in two different ways. In the first binning method, the maximum and minimum of all RR intervals in the entire datasets were calculated. The interval between the global maximum and minimum was divided into 30 equal portions, and a histogram was formed for each participant using these bin boundaries. Examples of this approach are shown in Figures 2–4. It may be observed that some of the histogram bins are effectively unused in this approach. In the second binning method, the maximum and minimum of the RR intervals for just one participant were used to calculate the boundaries of 30 bins in order to form a histogram for that participant. In this approach, all histograms have 30 useful bins.
After calculating each histogram by either method, the result is an estimate of the distribution of RR intervals for one participant in the study. To obtain probability values, each histogram was normalized by dividing the number of RR intervals in each bin by the total RR intervals in the sequence. This resulted in estimates of the probability of each bin, and these 30 probability values were used to calculate the Renyi entropy for the participant. This was repeated to calculate the Renyi entropy for each participant.
For each histogram, smoothing was performed using a five-term Gaussian kernel filter, and another set of Renyi entropy values was calculated from the smoothed histogram. The smoothing calculates a new frequency m for each bin i as follows:
where mi is the number of samples falling into bin i, and is the filtered number of samples in bin i. The filter coefficients ak were calculated from a Gaussian function:
where σ is the range parameter of the filter. In this work, σ was set to 1, so the filter parameters used were 0.135, 0.607, 1, 0.607, and 0.135. As these parameters do not sum to 1, normalization is required, which was performed after calculating all probabilities, so that the sum of all 30 probabilities was made equal to 1. After Renyi values were obtained, these were also normalized by dividing by log2 of the number of bins. In this way, all Renyi entropies using α = 0 were 1, and could be compared between the different method used to calculate them, and allowed for the different number of intervals within each 15 min time series obtained from the participants.
For probabilities calculated using the Density method, probabilities were estimated from Eqs 2 and 4. Parameters were varied, as a range of sequence lengths λ were used, and the dispersion of the Gaussian function σ was varied in proportion, as detailed in the following list.
The nine methods are summarized here:
1. Histogram of 30 bins using a global maximum and minimum, based on the range of RR intervals obtained from all participants.
2. Same as method 1, but using Gaussian kernel smoothing.
3. Histogram using widths based on the individual maximum and minimum obtained from each participant.
4. Same as method 3, but using Gaussian kernel smoothing.
5. Density method for sequence length λ = 1 and σ = 0.01.
6. Density method for sequence length λ = 2 and σ = 0.02.
7. Density method for sequence length λ = 4 and σ = 0.04.
8. Density method for sequence length λ = 8 and σ = 0.08.
9. Density method for sequence length λ = 16 and σ = 0.16.
The Renyi measures were analyzed separately for each of the nine methods and positive and negative exponents were also treated separately in the analysis. For each measure, A Mann–Whitney test was performed to compare the Normal (N) to the Early (E) group, the Early to the Definite (D) group, and the Definite to the Normal group. Mann–Whitney tests were performed using the u_test procedure of GNU Octave with the default arguments. For each of the nine methods, we summarized the results of the separation between classes by finding the minimum p-value from three tests (Normal vs. Early, Early vs. Definite, and Definite vs. Normal) and for 10 different Renyi measures (−5 ≤ α ≤ +5). The minimum was used to indicate the best potential of each method to separate the classes and was followed by a more detailed examination or the actual p-values obtained. Thus the minimum p-value from 30 tests is used to summarize each method. The nine methods were also compared using the mean correlation coefficient from 11 Renyi values.
Results
Table 1 summarizes the result of the nine versions of Renyi entropy used in the experiments. Each row corresponds to one of the methods of calculating probabilities. The numbers in column 1 correspond to those used in the Section “Materials and Methods.” The next two columns provide the minimum probability achieved by the Mann–Whitney tests comparing the three classes. These columns summarize the degree of class separation that was achieved. For example, method 3 produced Renyi entropy values that were unable to separate the three classes of participants, because the minimum p-values obtained from the Mann–Whitney test were 0.275 for the negative Renyi coefficients and 0.575 for the positive Renyi coefficients.
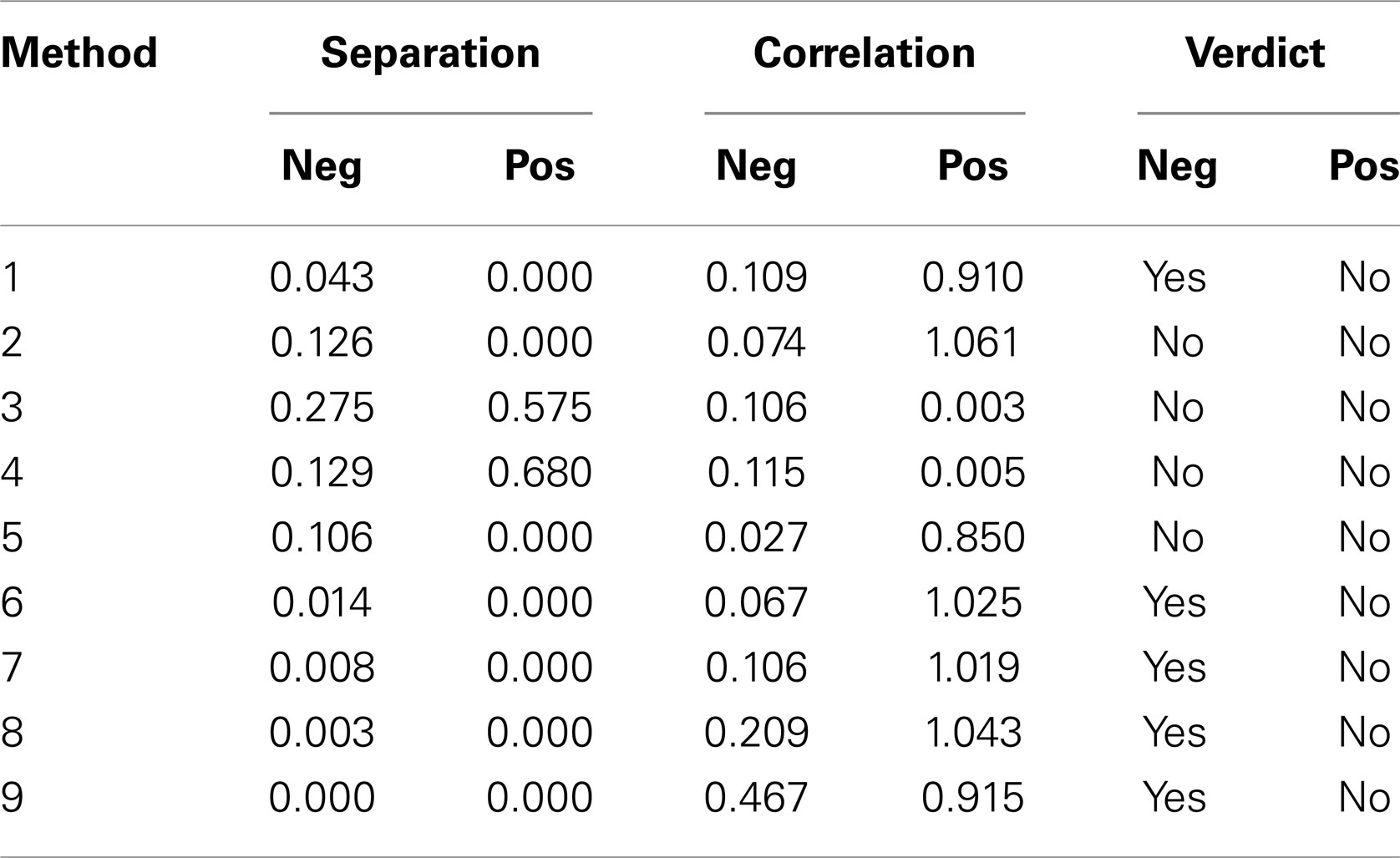
Table 1. Summary of results of Mann–Whitney tests for Renyi entropy calculated using nine different methods of estimating probabilities.
Columns 4 and 5 provide the average Pearson r2 value comparing the SD with the negative and for the positive Renyi values, respectively. For example, method 3 produced Renyi entropy values that were not correlated with the SD, with the mean Pearson r2 value of 0.106 for the negative Renyi coefficients and 0.003 for the positive Renyi coefficients.
The final two columns provide a measure of the suitability of the method for assisting with the task of discriminating between classes. The verdict achieves an affirmative only if the probability value from columns 2 or 3 is <0.05 (a 5% probability that an apparent difference in classes occurs by chance), and if the correlation value from columns 4 or 5 is <0.5. For example, method 3 is considered unsuitable because although it produces measures that are uncorrelated with SD, the separation of classes was not achieved as indicated by the high p-values.
According to these criteria, the only measures that were deemed to satisfy the two outcome requirements are the negative Renyi measures for method 1 (Histogram) and all of the density methods except for method 5. However, Table 1 provides only a summary of results, as it lists only the minimum p-value found. Now, we examine more closely the results deemed satisfactory. All results are provided as p-values from the Mann–Whitney test on Renyi entropy calculated with negative exponents of α (in brackets) and significant results highlighted in yellow.
Table 2 shows the individual results using method 1. Only one test produced a p-value lower than 0.05, and that was using an exponent of −1, for discrimination between Normal and Early. The fact that method 1 did not distinguish between Normal and Definite casts doubt on this result, as it should be easier to detect a difference between control and definite CAN than a difference between control and early CAN. However, this may be a function of the smaller sample size for the definite CAN group or the shorter interval length. For all values of exponent, the correlation with the SD is small, suggesting that these Renyi measures contain additional information, with only 14.5% of the variability in the Renyi entropy explained by the SD.
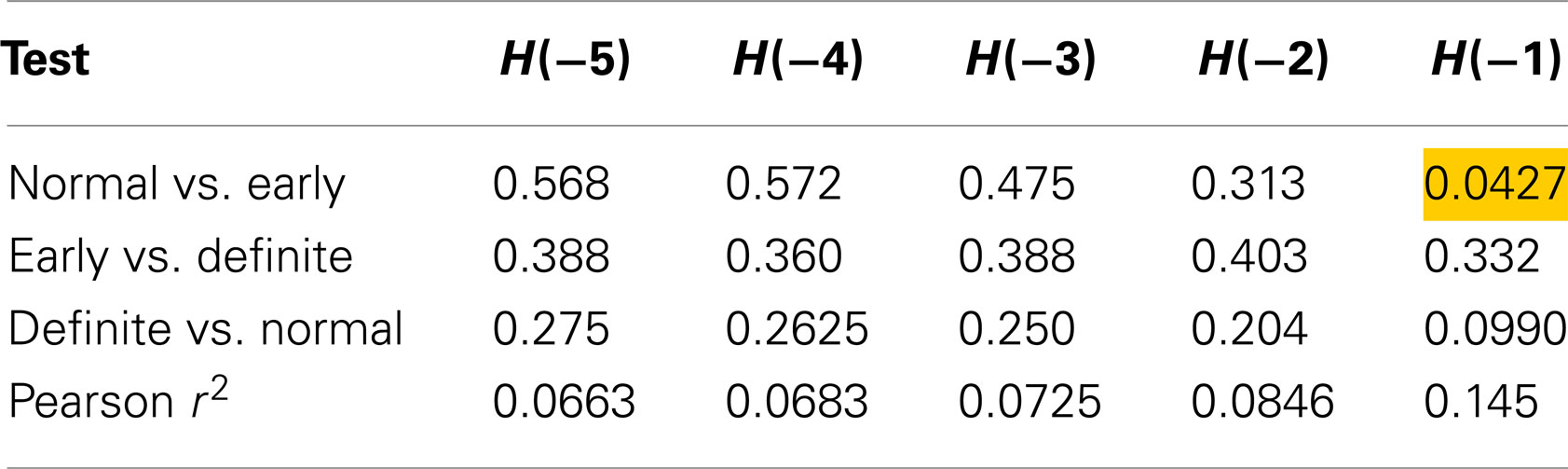
Table 2. Results of Mann–Whitney tests for Renyi entropy calculated with negative exponents and using method 1.
The density measures provided better results in that they were able to differentiate between all three clinical groups and added additional information in terms of the differences of the biosignals between the three groups (Normal, early CAN, and definite CAN).
Using method 6 (sequences of length 2), only one test was significant, differentiating between Definite CAN and Normal with H(−1) (Table 3). Also, differentiation between Normal and Early CAN nearly reached significance (p = 0.0536). The result further suggests that 23.4% of the variability in Renyi entropy H(−1) is explained by the SD.
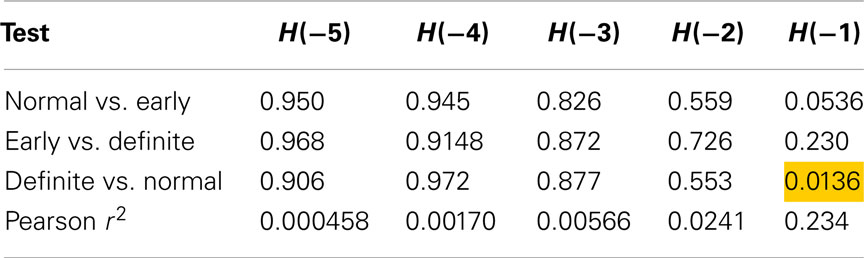
Table 3. Results of Mann–Whitney tests for Renyi entropy calculated with negative exponents and using method 6.
Table 4 shows the individual p-values from Renyi entropy calculated with negative exponents and using method 7 (sequences of length 4). Here, two tests produced a p-value lower than 0.05, implying that the Renyi entropy with exponent −1 may be able to discriminate these classes. The correlation between SD and Renyi entropy for H(−1) suggests that 26% of the variability of the latter is explained by the former.
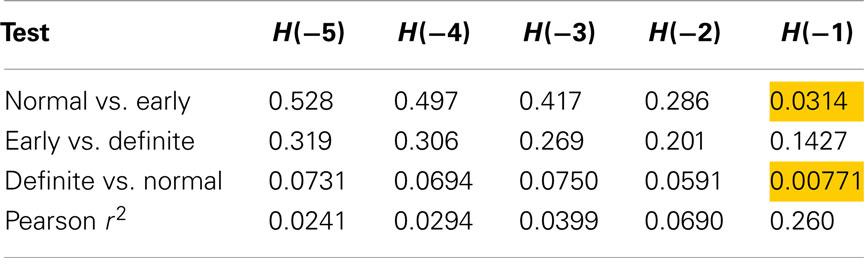
Table 4. Results of Mann–Whitney tests for Renyi entropy calculated with negative exponents and using method 7.
The results for using method 8 (sequences of length 8) are shown in Table 5. The longer sequence length and larger Gaussian smoothing may have contributed to the entropies calculated with the more negative α values to also differentiate between Normal and Definite CAN. However, this was not the case for Normal versus early CAN. The contribution of the SD observed was found to be 11.8% for H(−5) and increased to 31% for H(−1) with a concomitant improvement in discriminatory power.
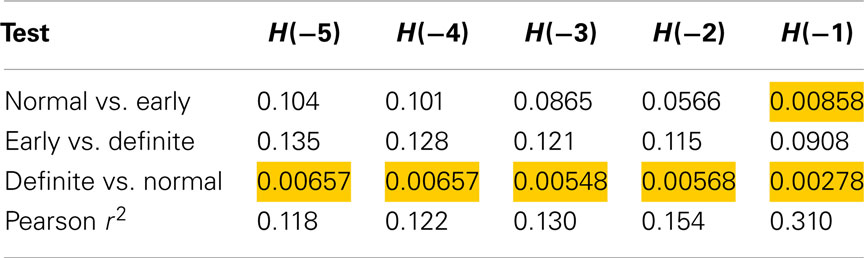
Table 5. Results of Mann–Whitney tests for Renyi entropy calculated with negative exponents and using method 8.
Method 9 (sequences of length 16) discriminated between Normal and Definite CAN as well as Normal versus Early CAN for all values of the exponent (Table 6), and also between Early and Definite CAN with H(−1). This suggests that increasing the sequence length allows further measures to be extracted that could be used in the discrimination of these disease subtypes. However, the correlation values are higher than those observed for shorter lengths (λ) and smaller Gaussian kernel smoothing with 43% of the variance explained by the SD for discrimination between any of the groups with H(−1).
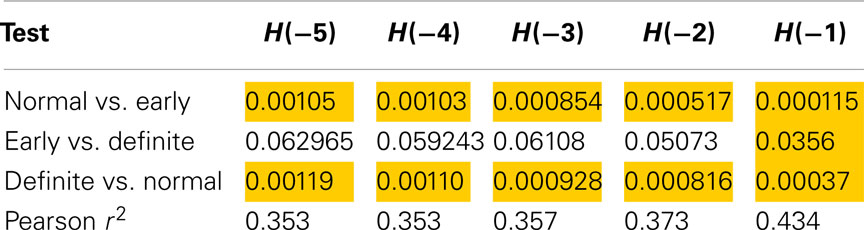
Table 6. Results of Mann–Whitney tests for Renyi entropy calculated with negative exponents and using method 9.
Figure 8 illustrates the trade-off between separation and correlation for the density method. The horizontal axis shows the sequence length λ for methods 5–9 defined in the Section “Introduction.” In this figure, the average p-value obtained from t-tests is shown by dark gray bars and labeled as separation. The height of the bars has been scaled by 10, to lie in the range 0–1. The selected threshold of p = 0.05 therefore occurs at 0.5 on the vertical axis. All choices of sequence length λ >1 yield p < 0.05. Correlation is shown by the light gray bars, where the vertical scale indicates Pearson r2. The diagram shows that as the sequence length λ that is used to calculate probabilities increases, the ability to distinguish between classes improves. However, at the same time, the correlation between Renyi entropy and SD increases, suggesting that the Renyi entropy provides a diminishing about of useful information over and above that, which could be obtained from SD.
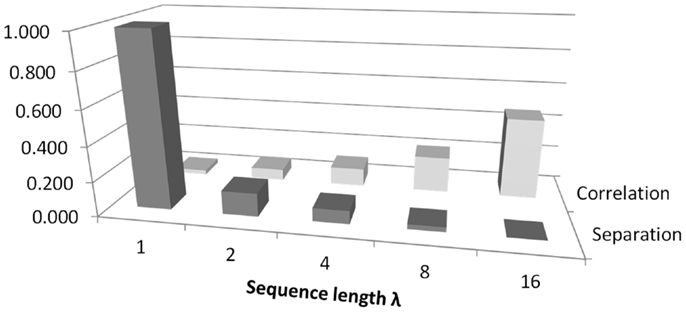
Figure 8. An illustration of the trade-off between correlation and separation for choosing sequence length λ when using the density method of estimating probabilities for calculating Renyi entropy. The figure relates to methods 5–9 as defined in the Section “Introduction.” The vertical axis shows Pearson’s r2 for correlation. For separation, the vertical axis is scaled for convenience, so that 1.0 corresponds to a p-value of 0.1.
Discussion
In this paper, we have shown that the Renyi exponent combined with the sequence length λ and the dispersion of the Gaussian function σ are important for classification paradigms such as determination of CAN progression. The main focus is to point out that any method for determining biosignal characteristics, such as entropy, needs to be able to show additional information about the biosignal, which is being analyzed. In the case of entropy evaluation, the standard method depends on binning the RR intervals into groups, and calculations are then based on the obtained histogram. Therefore, current entropy measures show a strong correlation with the SD of the biosignal, and in actuality, do not provide additional information.
Nine methods for calculating Renyi entropy were assessed in two ways: by the ability of the resulting values to allow identification of Definite CAN, Early CAN, or Normal, and whether the resulting values added extra information to that afforded by the SD. Results show that out of the histogram methods only the first method, which applied a histogram of 30 bins using a global maximum and minimum based on the range of RR intervals obtained from all participants, produced a positive assessment by these criteria. However, this method was only able to differentiate Normal and Early CAN using Renyi entropy with exponent α = −1. The positive Renyi coefficients associated with the remaining histogram methods were able to distinguish classes, but were also highly correlated with the SD and add no additional information.
The variants of the density method (methods 6–9) provided good separation between classes, but only for Renyi entropy calculated using negative exponents. The results using the density methods also improved as the sequence length was increased, but this also led to an increasing correlation with the SD. Therefore, an optimum sequence length that provides a compromise between good separation for classes and low correlation with SD is necessary. The current results suggest that for discriminating between Normal and early CAN, an optimal sequence length would be λ = 16 and a Gaussian kernel smoothing, σ = 0.16 with α being set at −5. The most difficult pair of classes to separate was Early CAN with Definite CAN. However, this is the problem likely to be of least interest. It is far more likely that a diagnostic test would rely on discrimination between Normal and Definite or between Normal and Early CAN (Vinik et al., 2013).
In order to distinguish between Normal and Definite classes, Table 5 represents a good compromise and corresponds to sequence length λ = 8 and σ = 0.08. The same situation also provides a good compromise for distinguishing Normal from Early CAN with p = 0.00858 and a correlation of only 0.310.
Conclusion
The main finding of this work is that when calculating the Renyi entropy in order to provide variables that can discriminate between classes of CAN, the method chosen for estimation of probabilities may result in variables that are strongly correlated with the SD. As the latter is computationally easy to calculate, it casts doubt on why a more complicated measure such as entropy would be calculated, since it seems to provide little extra information. However, this work shows that more advanced methods of calculating probabilities can be applied, and that these yield entropy measures that not only provide good discrimination, but also contain information over and above that provided by the SD. The application of a variety of sequence lengths in the calculation of probabilities allows a trade-off between discrimination power and independence from SD. Use of a density method, based on sequences of RR intervals, produced Renyi measures that allowed discrimination between definite CAN, normal controls, and even early CAN. We found the best result for longer sequences of 8 or 16 beats. This suggests that a more sophisticated method for estimation of probabilities is justified by its improved results, and shows that Renyi entropy is suitable for use in discriminating CAN. Furthermore, we show that the method chosen for probability estimation is important and has a large effect on the outcome.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Acharya, U. R., Hegde, B. M., Bhat, S., Rao, A., and Cholayya, N. U. (2002). Wavelet analysis of heart rate variability: new method of studying the heart’s function. Kuwait Med. J. 34, 195–200.
Acharya, U. R., Joseph, K. P., Kannathal, N., Lim, C. M., and Suri, J. S. (2006). Heart rate variability: a review. Med. Biol. Eng. Comput. 44, 1031–1051. doi: 10.1007/s11517-006-0119-0
Berntson, G. G., Bigger, J. T. Jr., Eckberg, D. L., Grossman, P., Kaufmann, P. G., Malik, M., et al. (1997). Heart rate variability: origins, methods, and interpretive caveats. Psychophysiology 34, 623–648. doi:10.1111/j.1469-8986.1997.tb02140.x
Costa, M., Goldberger, A. L., and Peng, C. K. (2002). Multiscale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 89, 068102. doi:10.1103/PhysRevLett.89.068102
Ewing, D. J., Martyn, C. N., Young, R. J., and Clarke, B. F. (1985). The value of cardiovascular autonomic functions tests: 10 years’ experience in diabetes. Diabetes Care 8, 491–498. doi:10.2337/diacare.8.5.491
Flynn, A. C., Jelinek, H. F., and Smith, M. C. (2005). Heart rate variability analysis: a useful assessment tool for diabetes associated cardiac dysfunction in rural and remote areas. Aust. J. Rural Health 13, 77–82. doi:10.1111/j.1440-1854.2005.00658.x
Javorka, M., Trunkvalterova, Z., Tonhajzerova, I., Javorkova, J., Javorka, K., and Baumert, M. (2008). Short-term heart rate complexity is reduced in patients with type 1 diabetes mellitus. Clin. Neurophysiol. 119, 1071–1081. doi:10.1016/j.clinph.2007.12.017
Jelinek, H. F., Imam, H. M., Al-Aubaidy, H., and Khandoker, A. H. (2013). Association of cardiovascular risk using nonlinear heart rate variability measures with the Framingham risk score in a rural population. Front. Physiol. 4:186. doi:10.3389/fphys.2013.00186
Jelinek, H. F., Wilding, C., and Tinley, P. (2006). An innovative multi-disciplinary diabetes complications screening programme in a rural community: a description and preliminary results of the screening. Aust. J. Prim. Health 12, 14–20. doi:10.1071/PY06003
Karmakar, C. K., Khandoker, A., Gubbi, J., and Palaniswami, M. (2009). Complex correlation measure: a novel descriptor for Poincaré plot. Biomed. Eng. Online 8, 17. doi:10.1186/1475-925X-8-17
Karmakar, C. K., Khandoker, A. H., Jelinek, H. F., and Palaniswami, M. (2013). Risk stratification of cardiac autonomic neuropathy based on multi-lag tone-entropy. Med. Biol. Eng. Comput. 51, 537–546. doi:10.1007/s11517-012-1022-5
Khandoker, A. H., Jelinek, H. F., and Palaniswami, M. (2009). Identifying diabetic patients with cardiac autonomic neuropathy by heart rate complexity analysis. Biomed. Eng. Online 8, 3. doi:10.1186/1475-925X-8-3
Malik, M., and Camm, J. (1993). Components of HRV variability – what they really mean and what they really measure. Am. J. Cardiol. 72, 821–822. doi:10.1016/0002-9149(93)91070-X
Nasim, K., Jahan, A. H., and Syed, S. A. (2011). Heart rate variability – a review. J. Basic Appl. Sci. 7, 71–77. doi:10.7439/ijbar.v5i2.659
Oida, E., Kannagi, T., Moritani, T., and Yamori, Y. (1999). Diabetic alteration of cardiac vago-sympathetic modulation assessed with tone-entropy analysis. Acta Physiol. Scand. 165, 129–135. doi:10.1046/j.1365-201x.1999.00494.x
Pop-Busui, R. (2010). Cardiac autonomic neuropathy in diabetes. Diabetes Care 33, 434–441. doi:10.2337/dc09-1294
Rényi, A. (1960). “On measures of information and entropy,” in Proceedings of the Fourth Berkeley Symposium on Mathematics, Statistics and Probability (Berkeley, CA: University of California Press), 547–561.
Sacre, J. W., Jellis, C. L., Marwick, T. H., and Coombes, J. S. (2011). Reliability of heart rate variability in patients with type 2 diabetes mellitus. Diab. Med. 29, e33–40. doi:10.1111/j.1464-5491.2011.03557.x
Sztajzel, J. (2004). Heart rate variability: a noninvasive electrocardiographic method to measure the autonomic nervous system. Swiss Med. Wkly. 134, 514–522. doi:10.4414/smw.2013.13751
Tarvainen, M. P., Cornforth, D. J., Kuoppa, P., Lipponen, J. A., and Jelinek, H. F. (2013). “Complexity of heart rate variability in type 2 diabetes – effect of hyperglycemia,” in Proceedings of the 35th Annual International Conference of the IEEE – EMBS (Osaka: IEEE Press).
Tarvainen, M. P., Niskanen, J.-P., Lipponen, J. A., Ranta-aho, P. O., and Karjalainen, P. A. (2014). Kubios HRV – heart rate variability analysis software. Comput. Methods Programs Biomed. 113, 210–220. doi:10.1016/j.cmpb.2013.07.024
Tarvainen, M. P., Ranta-aho, P. O., and Karjalainen, P. A. (2002). An advanced detrending method with application to HRV analysis. IEEE Trans. Biomed. Eng. 49, 172–175. doi:10.1109/10.979357
TFESC. (1996). Special report: heart rate variability standards of measurement, physiological interpretation, and clinical use. Circulation 93, 1043–1065.
Tulppo, M. P., Mäkikallio, T. H., Takala, T. E. S., and Seppänen, T. (1996). Quantitative beat-to-beat analysis of heart rate dynamics during exercise. Am. J. Physiol. 271, H244–H252.
Valensi, P., Johnson, N. B., Maison-Blanche, P., Estramania, F., Motte, G., and Coumel, P. (2002). Influence of cardiac autonomic neuropathy on heart rate variability dependence of ventricular repolarization in diabetic patients. Diabetes Care 25, 918–923. doi:10.2337/diacare.25.5.918
Vinik, A. I., Erbas, T., and Casellini, C. M. (2013). Diabetic cardiac autonomic neuropathy, inflammation and cardiovascular disease. J. Diabetes Investig. 4, 4–8. doi:10.1111/jdi.12042
Vinik, A. I., Maser, R. E., Mitchell, B. D., and Freeman, R. (2003). Diabetic autonomic neuropathy. Diabetes Care 26, 1553–1579. doi:10.2337/diacare.26.5.1553
Voss, A., Schroeder, R., Truebner, S., Goernig, M., Figulla, H. R., and Schirdewan, A. (2007). Comparison of nonlinear methods symbolic dynamics, detrended fluctuation, and Poincaré plot analysis in risk stratification in patients with dilated cardiomyopathy. Chaos 17, 015120. doi:10.1063/1.2404633
Keywords: Renyi entropy, heart rate variability, cardiac autonomic neuropathy, probability estimation, disease discrimination
Citation: Cornforth DJ, Tarvainen MP and Jelinek HF (2014) How to calculate Renyi entropy from heart rate variability, and why it matters for detecting cardiac autonomic neuropathy. Front. Bioeng. Biotechnol. 2:34. doi: 10.3389/fbioe.2014.00034
Received: 31 March 2014; Accepted: 23 August 2014;
Published online: 09 September 2014.
Edited by:
Ahsan H. Khandoker, The University of Melbourne, AustraliaReviewed by:
Silvina Ponce Dawson, Universidad de Buenos Aires, ArgentinaSima Setayeshgar, Indiana University, USA
Copyright: © 2014 Cornforth, Tarvainen and Jelinek. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: David J. Cornforth, School of Design, Communication and IT, University of Newcastle, Callaghan, NSW 2308, Australia e-mail: david.cornforth@newcastle.edu.au