The largest human cognitive performance dataset reveals insights into the effects of lifestyle factors and aging
- 1Lumos Labs Inc., San Francisco, CA, USA
- 2Combined Program in Education and Psychology, University of Michigan, Ann Arbor, MI, USA
- 3Department of Psychiatry and Duke Institute for Brain Sciences, Duke University, Durham, NC, USA
Making new breakthroughs in understanding the processes underlying human cognition may depend on the availability of very large datasets that have not historically existed in psychology and neuroscience. Lumosity is a web-based cognitive training platform that has grown to include over 600 million cognitive training task results from over 35 million individuals, comprising the largest existing dataset of human cognitive performance. As part of the Human Cognition Project, Lumosity's collaborative research program to understand the human mind, Lumos Labs researchers and external research collaborators have begun to explore this dataset in order uncover novel insights about the correlates of cognitive performance. This paper presents two preliminary demonstrations of some of the kinds of questions that can be examined with the dataset. The first example focuses on replicating known findings relating lifestyle factors to baseline cognitive performance in a demographically diverse, healthy population at a much larger scale than has previously been available. The second example examines a question that would likely be very difficult to study in laboratory-based and existing online experimental research approaches at a large scale: specifically, how learning ability for different types of cognitive tasks changes with age. We hope that these examples will provoke the imagination of researchers who are interested in collaborating to answer fundamental questions about human cognitive performance.
Introduction
While many scientific fields ranging from biology to the social sciences are being revolutionized by the availability of large datasets and exponentially increasing computational power, the dominant approach to studying human cognitive performance still involves running small numbers of participants through brief experiments in the laboratory. This approach limits the kinds of questions that can be practically studied in important ways. For one, most studies depend on a convenience sample of university undergraduates, limiting the broad applicability of findings (Heinrich et al., 2010). The need for research participants to return to the laboratory also limits the ability to study fundamental questions about the variables that influence learning over time and across the lifespan.
Understanding how demographic and lifestyle factors influence cognitive function has important health and policy implications. These questions are often difficult to examine using laboratory-based approaches because they require the experimenter to recruit sufficient numbers of participants across a wide range of demographic backgrounds. Studies of how cognitive performance changes with age tend to compare a sample of university undergraduates to older adults, and as a result can only tell us about the discrete differences between these samples. Since age varies continuously in the population, determining the rate at which performance and learning change with age across the lifespan would require studying a large number of participants across a continuous range of ages. This type of study would be prohibitively time-consuming and expensive to run in a conventional psychology laboratory. Likewise, even the largest observational or multi-center controlled clinical trials examining effects of various interventions on cognitive performance have generally consisted of no more than several thousand individuals from restricted geographic and demographic backgrounds—e.g., Whitehall II N = 10,314 (Marmot et al., 1991) Women's Health Initiative Memory Study N = 8,300 (Craig et al., 2005).
The Lumosity Platform and Dataset
Given the limitations of conventional approaches, it is worthwhile to consider alternative methods to gathering data on human cognitive performance. With the rise of the Internet, web-based research in the behavioral sciences has become more common, particularly in studies of human cognition (Reips, 2004). While concerns remain, the potential of web-based research to recruit larger samples from a wider variety of demographic backgrounds has been widely acknowledged (Kraut et al., 2003; Birnbaum, 2004; Skitka and Sargis, 2006).
Lumosity is a web-based cognitive training platform that includes a suite of cognitive training exercises, assessments, and an integrated training system designed for the purpose of improving users' cognitive abilities. As the user base has grown rapidly over the past six years, the database of users' cognitive performance has become the largest dataset of human cognitive performance to our knowledge. As of January 23, 2013, the dataset includes 36,140,947 users representing 231 distinct ISO-3166 country codes. These users have trained on the cognitive exercises 609,017,147 times and taken online neuropsychological assessments 6,661,302 times (see Figure 1A for screenshots of the game and assessment pages).
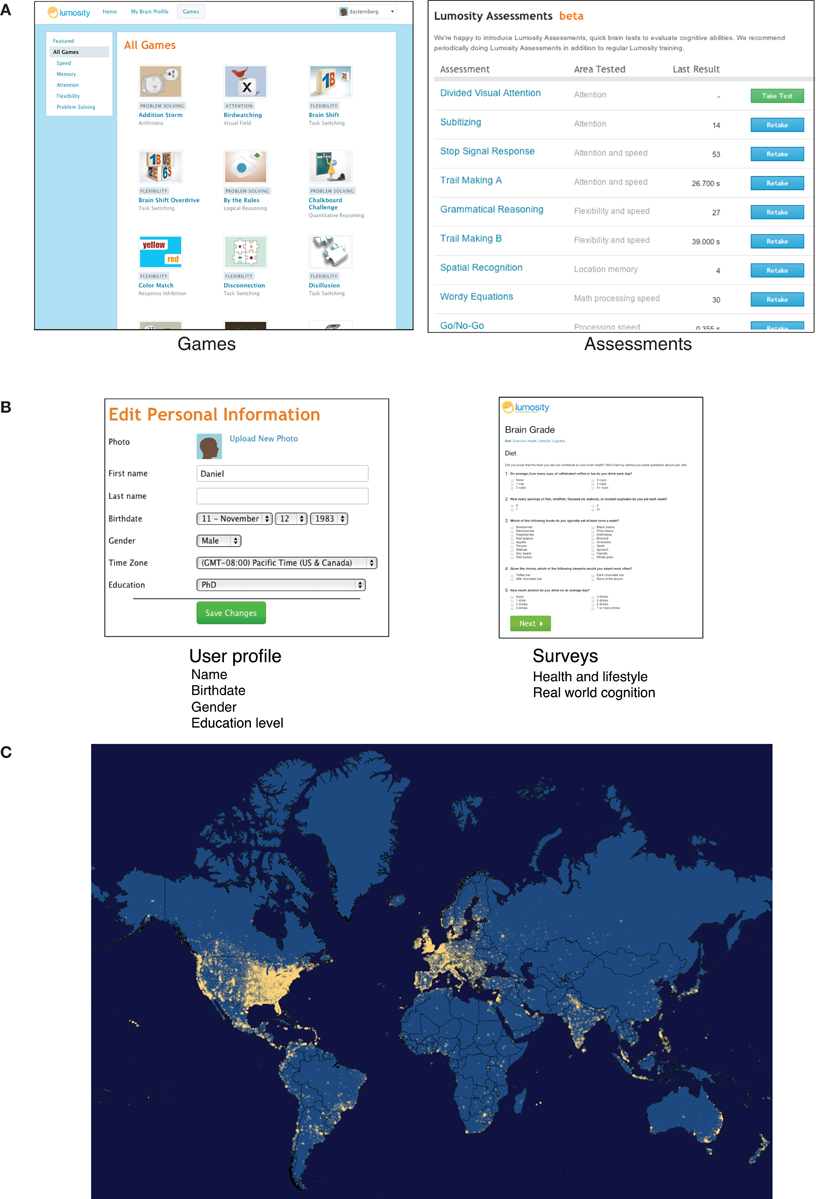
Figure 1. (A) Lumosity includes exercises designed to improve cognitive performance targeting five areas of cognition, along with assessments based on standard neuropsychological tasks. (B) Demographic information is available from users' profiles and surveys that users can choose to participate in. (C) A map of users' locations based on their IP address at last login. The map was generated from a database of user IP addresses at login. Approximate Latitude and longitude coordinates were obtained for each IP address using MaxMind's GeoLiteCity database (available at http://www.maxmind.com/app/geolitecity). These coordinates were then rounded to the nearest 1/100th of a degree and aggregated to obtain a count of the number of users at each rounded coordinate. The size of each dot was mapped to the floor of the base-10 log of the number of users. As IP addresses were missing for some users, and in some cases IP addresses could not be mapped to geographic coordinates, the data used to generate the map was based on the geographic coordinates for 15,162,193 users.
In addition to engaging in training tasks and taking assessments, users voluntarily provide demographic information, including their age, gender, and level of education. They also have the opportunity to participate in a number of surveys about health, lifestyle, and real-world cognitive activities (Figure 1B). A user's location can be roughly determined from his or her IP address, which allows researchers to relate approximate geographic information to cognitive performance and to measure geographic reach (Figure 1C).
While internal research using this growing dataset has been ongoing for some time, Lumos Labs has recently begun to work with outside researchers who are also interested in analyzing cognitive performance at large scale, as one arm of the Human Cognition Project (HCP), a collaborative research program to understand the human mind. External researchers interested in analyzing de-identified portions of the dataset apply through the HCP website (http://hcp.lumosity.com). As part of the application process, researchers are asked to present a specific analysis plan. The Lumos Labs research and development team, and in some cases, external research advisors, vet proposals based on the quality of the specific analysis plan. All well-designed proposals are accepted. Lumos Labs allows researchers to publish any findings following from the accepted analysis plan without requiring further consultation with the company. At this time, the large majority of ongoing projects analyzing the Lumosity dataset are focused on basic psychological phenomena that are not directly related to validating cognitive training.
Here, we present two initial demonstrations of the power afforded by examining human cognitive performance at large scale. In the first example, we examine how cognitive performance relates to general health and lifestyle factors, based on a large survey of hundreds of thousands of users from the dataset. In the second example, we look at how task improvements change with age, and how these age-related changes differ for tasks that depend on different cognitive abilities.
Example 1: Health, Lifestyle, and Cognitive Performance
Many lifestyle factors have been shown to influence cognitive abilities, and a cognitively active lifestyle has been linked to reduced levels of potential precursors to dementia (Landau et al., 2012) and a reduced likelihood of developing dementia (Doraiswamy, 2012). For these reasons, we were interested in whether users' initial performance correlated with their self-reported lifestyle habits. In order to examine this question, we designed a survey of health and lifestyle habits that has now been taken by millions of individuals across the world (available at: http://www.lumosity.com/surveys/brain_grade). Here, we focus on two particularly interesting questions about lifestyle habits from this survey that vary continuously in the population: sleep and alcohol consumption. These variables have been included in other surveys that also measured cognitive function (e.g., Marmot et al., 1991), and we were interested in whether the influence of these variables on performance in our user base would correspond to what has been observed in the existing literature.
Methods and Materials
We obtained survey data for all users who took the health and lifestyle survey between March 2011 and January 2012. For each of these users, we also obtained their initial scores on three cognitive exercises, where available. These exercises were chosen for reliability as well as coverage: they are some of the most popular training tasks, are shown within the first few days of training, and represent distinct cognitive abilities. The three exercises are described below.
Speed Match is a one-back matching task in which users respond whether the current object matches the one previously shown. Users respond to as many trials as they can in 45 s. We used the number of correct responses the user made before the end of the task as the measure of performance.
Memory Matrix is a spatial working memory task in which users are shown a pattern of squares on a grid, and must recall which squares were present following a delay. The tasks uses a variant of a one-up one-down staircase method (Levitt, 1971) in order to find the user's memory threshold. We used this threshold as the measure of performance.
Raindrops is a speeded arithmetic calculation task in which new arithmetic problems continuously appear at the top the screen inside of raindrops. Users need to answer the problems before the raindrops reach the bottom of the screen. Once three raindrops have reached the bottom of the screen, the task ends. We used the number of correct responses made before the task ended as the measure of performance.
Results
Figure 2A provides sample sizes and demographic information from the three tasks. For each task, the relevant measure was first fit to a general linear model including age (up to 4th degree polynomial), level of education (approximate years), gender, and the interactions of these variables as predictors. In the case of Speed Match and Raindrops, where the relevant measure was the number of correct responses, the model included a Poisson link function in order to capture the distribution. The residuals returned by each model were used as the dependent measure for the further analyses.
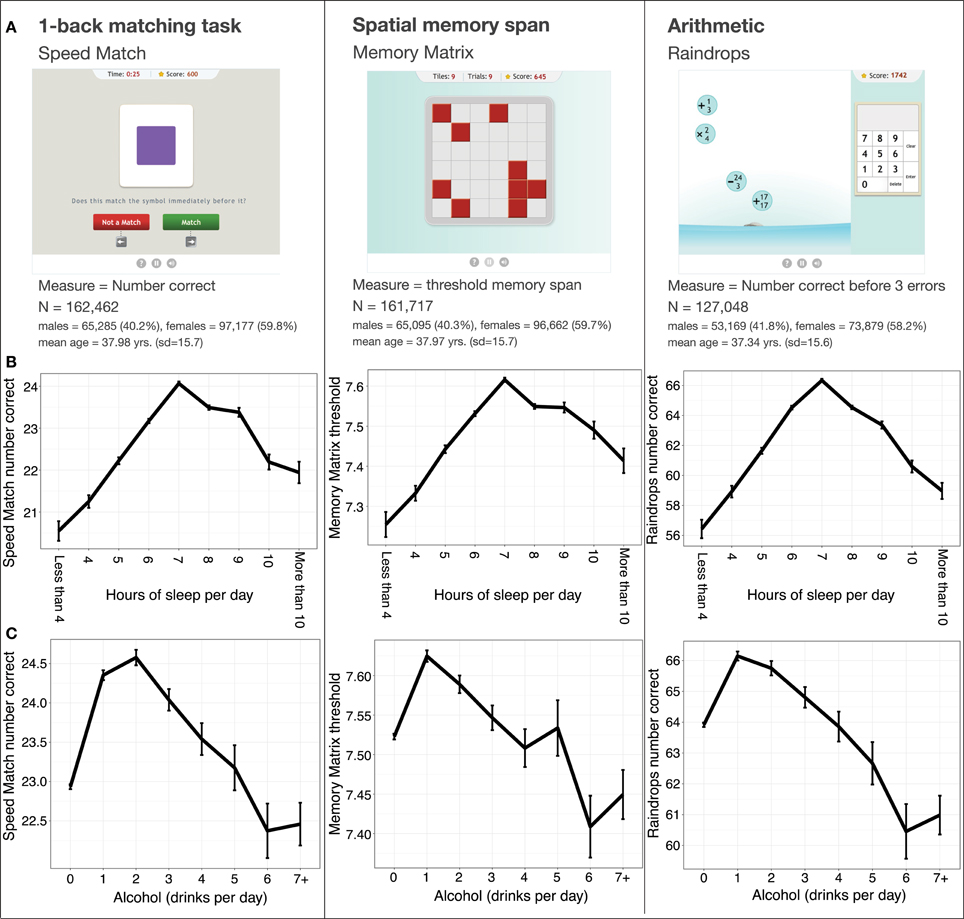
Figure 2. (A) Exercises used in the analysis of the health and lifestyle survey. (B) The effect of reported sleep on game performance. (C) The effect of reported alcohol intake on game performance (controlling for age, gender, and level of education).
The main effects of self-reported sleep and alcohol intake were measured for each task via separate multivariate linear regression models. These models revealed positive linear effects of hours of sleep for and negative quadratic effects of sleep for all three tasks (see Table 1 for model coefficients and relevant statistics). More specifically, we found that cognitive performance in all three tasks was greater for users reporting larger amounts of sleep up to 7 h per night, after which it began to decrease (Figure 2B). The models also revealed significant negative linear and negative quadratic effects of alcohol for all three tasks. Low to moderate alcohol intake was associated with better performance in all three tasks, with performance peaking at a self-reported 1 or 2 drinks per day, depending on the task (Figure 2C), and decreasing as alcohol intake increased from there. The presence of negative quadratic effects for both predictors indicated that the effects of sleep and alcohol intake on performance had an inverted U-shape.
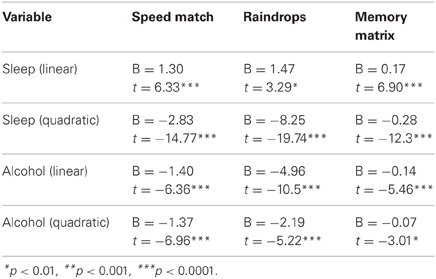
Table 1. Model coefficients and t-statistics for the linear and quadratic effects of reported hours of sleep and alcohol intake, taken from the grand regression model.
Discussion
The associations between sleep, alcohol intake, and cognitive function observed here are comparable to previous findings from the Whitehall II study. An analysis of Whitehall II participants also found that those who reported around 7 h of sleep showed the highest cognitive performance on a battery of psychological assessments (Ferrie et al., 2011). Another study of the same cohort found that alcohol intake reduces the likelihood of poor cognitive function (Britton et al., 2004), though this study did not observe the same reduction in cognitive performance at higher levels of consumption that we found in our analysis. One possible explanation for this difference is that Britton and colleagues focused on whether a participant's cognitive performance scored in the bottom quintile, as a measure of “poor cognitive function,” while our analysis looked at the average performance at each level of alcohol consumption. The increased scale of our dataset may have allowed us to observe this non-linearity in the dose-dependent effects of alcohol consumption. Other unobserved demographic covariates may also provide some explanation for the divergent findings, as the Whitehall II cohort is also restricted to civil service workers from the United Kingdom, while Lumosity users come from a wide range of demographic backgrounds and are located all over the world.
As these findings are correlational in nature, there may be other related but unobserved variables that explain some of the effects of alcohol consumption and sleep in our data. For example, the apparent cognitive advantage for those who report moderate alcohol intake may be in part due to increased social and cognitive engagement compared to those who report little or no alcohol consumption. Thus, while we would not want to strongly assert that the real causal effects of these variables exactly mirror our findings, these results instead provide a rough profile of the habits of individuals who tend to show higher cognitive function that can be filled in as we obtain additional health and lifestyle data. This first example should also serve as a testament to the ability to quickly obtain reliable data from a large numbers of individuals using the survey platform, as we were able to gather all of this data solely from new users who had joined the site within a 9-month period.
Example 2: Cognitive Task Improvements and Aging
While aging researchers have discovered a great deal about how baseline performance declines with age for different cognitive abilities (Park, 1999; Salthouse, 2009) less is known about how the ability to learn different kinds of skills changes over the lifespan. Exploring this question using standard laboratory-based approaches would require recruiting a large number of participants across a wide range of ages and bringing them into the lab to perform multiple tasks many times over the course of weeks or months. Existing web-based approaches also face their own difficulties in studying learning over time. Other platforms that have recently become popular for running psychology studies on the web, such as Amazon Mechanical Turk (Buhrmester et al., 2011; Mason and Suri, 2012), are poorly suited for running the multi-session studies necessary to obtain this type of data, and even very recent work measuring cognitive performance across the lifespan at a relatively large scale has to date only examined baseline performance (Hampshire et al., 2012).
This type of data may be difficult to obtain via other web-based platforms in part because, while it is relatively simple to use small payments to individuals and/or online advertising to quickly obtain baseline cognitive performance data from a large number of individuals, there is little incentive for participants to return on a regular basis. In contrast, Lumosity users are specifically interested in cognitive training and are able to train on a large variety of cognitive tasks as often as they would like. As a result, they commonly return regularly over the course of months and years. These unique characteristics make it possible to examine how learning ability changes year by year over the lifespan, and how aging might affect learning differently across distinct cognitive abilities. As a preliminary demonstration of the ability to measure these differences in this dataset, we looked at how a user's age influences how much he or she improves over the course of the first 25 sessions of a cognitive task, and compared tasks that rely on abilities linked to fluid intelligence, such as working memory tasks, vs. those that rely more on crystallized knowledge, such as verbal fluency and basic arithmetic.
Methods and Materials
In order to test for differential effects of aging on improvement in fluid intelligence and crystallized knowledge tasks, we chose four particular exercises in our database, two of which rely on working memory, a known correlate of fluid intelligence, and two that rely on declarative knowledge—verbal fluency and basic arithmetic. For each of the four tasks, we pulled the first 25 sessions for all user who had trained on that task at least 25 times. (minimum N = 22,718). Two of the tasks (Memory Matrix and Raindrops) were the same as those used in the health and lifestyle analysis. For these tasks, the same measures that were used in the health and lifestyle analysis were used. The other two tasks are described below.
Memory Match is a 2-back working memory task in which users respond whether the current object matches the one shown two trials ago. Users respond to as many trials as they can in 45 s. The relevant measure of performance in this task was the number of correct responses users made.
Word Bubbles is a verbal fluency task in which users type as many words as possible matching a particular word stem, with the constraint that their score depends on making multiple words of different lengths. The task lasts 3 min. The relevant measure of performance was the number of correct responses users made.
Figure 3 shows sample sizes and demographic information for each task. In order to compare performance across the tasks on the same scale, the dependent variable for each task was transformed via a scaling table obtained by applying an inverse rank normalization procedure to a separate dataset of baseline raw scores from a large number of users (range = 93,832-3,600,595). For each task, the empirical percentile for each baseline raw score was mapped to its corresponding place on a normal distribution with μ = 100, σ = 15.
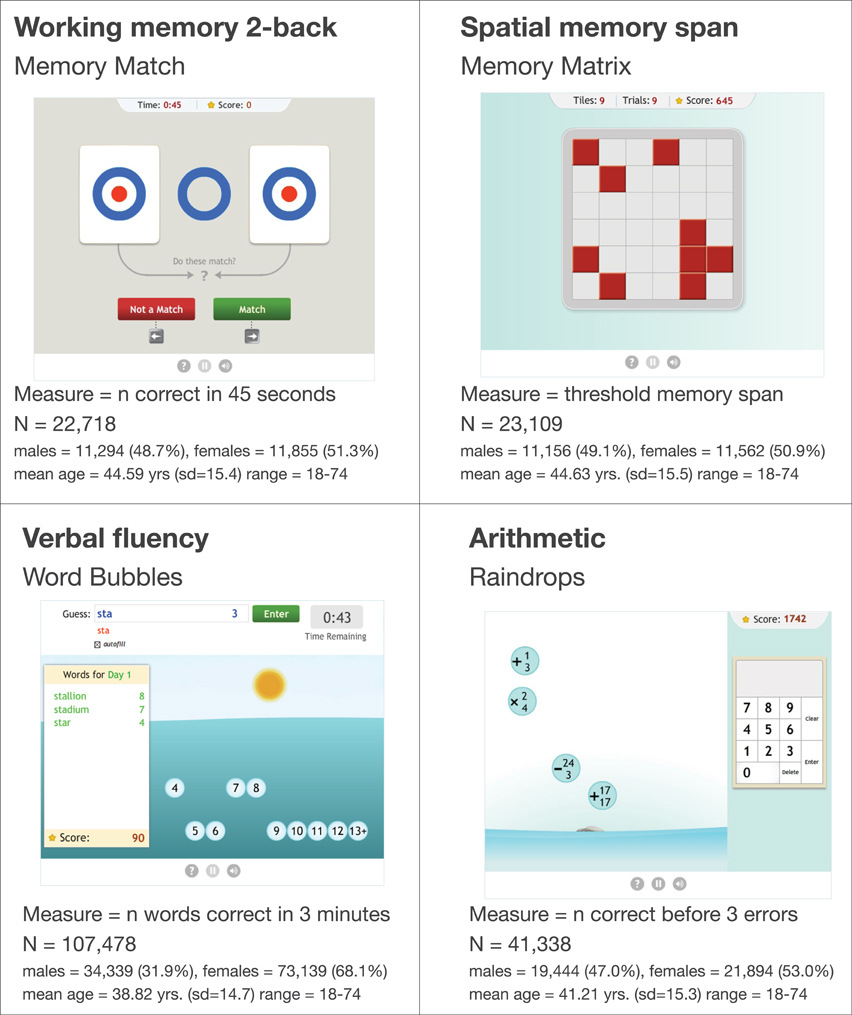
Figure 3. The four exercises used in the aging and learning analysis, and demographic information for each game.
For at least one task (Word Bubbles), the mean baseline score for users who trained at least 25 times was greater than 100, indicating that the subset of users who chose to train 25 times had higher baseline scores than the average user who may have trained only once. In the analysis below, the main effects of the variables contrasting individual tasks at baseline should control for any differences between the average baseline score for each task.
Results
We examined the effect of age on performance at baseline and on learning across tasks using linear mixed effects model predicting the scaled score based on the user's age level of education, gender, task, and session (1st vs. 25th). The model also included interaction terms for gender × task, education level (approximate years) × task, session × task, age × task, and age × task × session. A quadratic effect of age was also included in the model, along with the same respective interactions with task and time. Continuous covariates (age and education) were centered before inclusion in the model. The model also included a separate random intercept for each user.
The task variables in the model were coded using the following planned orthogonal contrasts. Contrast 1 compared the “fluid intelligence” tasks (Memory Matrix, Memory Match) to the “crystallized knowledge” tasks (Raindrops, Word Bubbles). Contrast 2 compared Memory Match and Memory Matrix. Contrast 3 compared Raindrops and Word Bubbles. Gender, education, and their interactions with the task contrasts were included in the model specifically to control for known effects of these variables. Table 2 gives the coefficients and t-statistics for the fixed effects in the model.
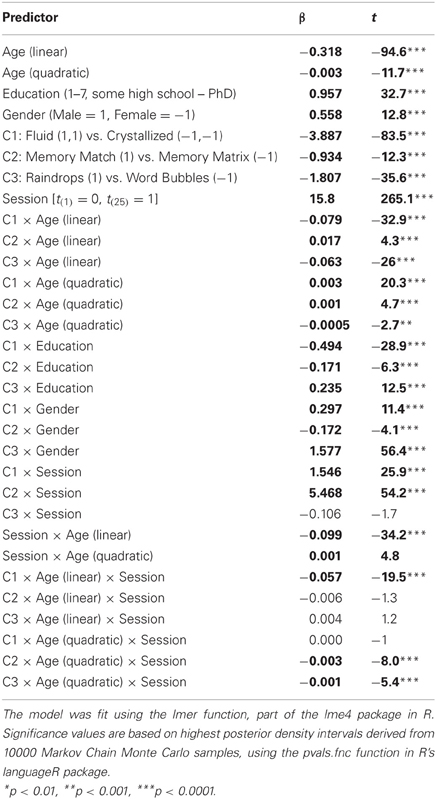
Table 2. Coefficients and t-statistics for age and learning mixed effects model.
We observed negative age-related differences in performance on all tasks, as indicated by the negative linear coefficient for age. However, the presence of an interaction of age and the crystallized/fluid game contrast indicates that performance on the tasks that rely on fluid intelligence decreased with increasing age at a faster rate than the tasks that rely on crystallized intelligence. The negative coefficient for the fluid/crystallized tasks contrast with the quadratic effect of age suggests that the negative age-related effect of age on the fluid intelligence tasks started earlier and leveled off compared to the crystallized intelligence tasks, which were preserved for longer before beginning to decrease. Looking within the two tasks types, the negative linear age-related difference was steeper for Memory Match than for Memory Matrix, and was steeper for Raindrops than for Word Bubbles. These additional interactions may provide some indication of the relative importance of fluid and crystallized knowledge and/or processing speed in these tasks.
In general, users improved with training, as indicated by the main effect of session. The significant interaction of session with the first two game contrasts reveals that users improved more at the fluid intelligence tasks than the crystallized knowledge tasks, and improved most at Memory Match. The amount of improvement between sessions decreased as age increased, and this negative effect of aging on learning was greater for the tasks that relied on fluid intelligence than those that relied on crystallized knowledge, as indicated by the strong three-way interaction of this contrast with the linear effect of age and training session. Finally, the relatively large three-way (game × quadratic age × session) interaction for the second task contrast suggests that the reduction in improvement in older adults began later and accelerated for Memory Match compared to Memory Matrix, where the reduction in improvement began earlier before leveling off.
Discussion
At baseline, we found that performance decreased in all exercises with increasing age, but did so to a greater degree for the exercises thought to rely more on fluid intelligence than those that rely more on crystallized knowledge (Figure 4A). This finding is in line with other research that has found that processing speed and memory span decline earlier than verbal fluency and crystallized intelligence, which are preserved until later in life (Park, 1999; Salthouse, 2009).
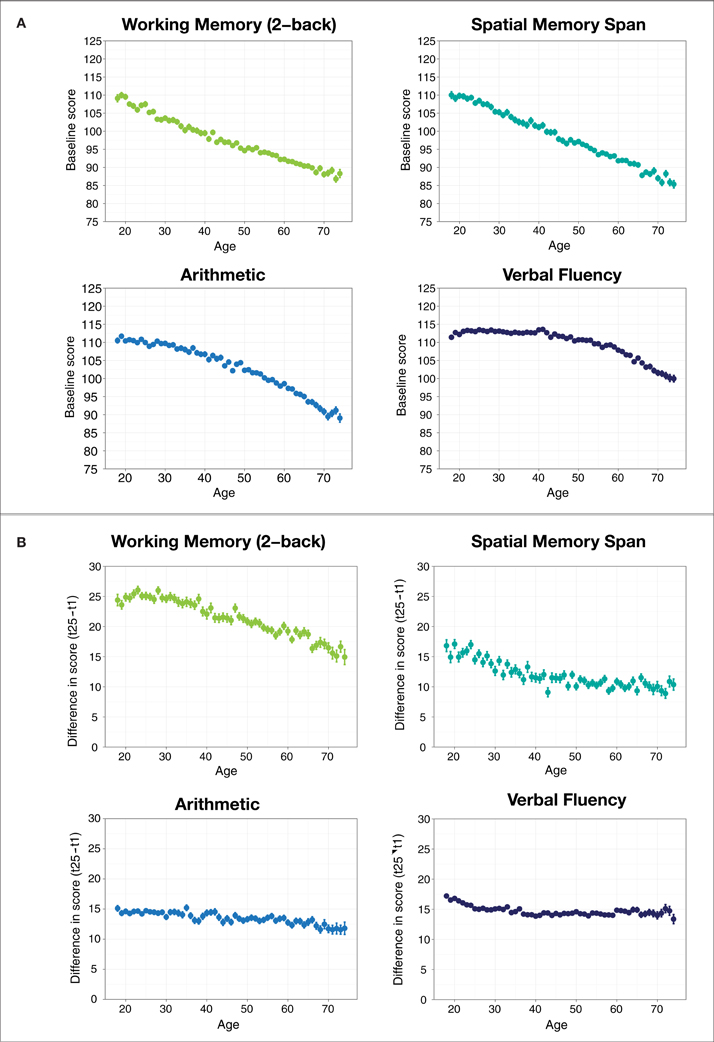
Figure 4. (A) Mean game score by age at baseline. (B) Difference between 25th and 1st game score by age for each game. Error bars represent standard errors of the mean.
As we noted earlier, one particular advantage of the dataset is that it contains information about changes in users' in performance over the course of many training sessions. While users showed improvements in all four tasks with training, the effect was largest for the 2-back working memory task, and smallest for spatial memory span (Figure 4B), perhaps indicating differences in the difficulty and novelty of these tasks. The working memory task also showed the largest negative age-related difference in training improvement, while improvements in verbal fluency remained relatively constant across ages. We also observed that when taken together, training improvements on working memory tasks were less affected by a user's age than performance on the verbal fluency and arithmetic tasks. This provides preliminary evidence that the ability to improve at a task changes with age in the same way that baseline ability changes with age—with an earlier and more rapid effect of age on learning for tasks that rely on fluid intelligence and a more gradual influence of age for tasks that rely more on crystallized knowledge. This finding also runs counter to the theory that individuals who have more initial difficulty with a particular type of task should show greater improvement with training at that task compared to ones that they find easier, based on the idea they have more room for improvement. We found instead that older individuals, who start with lower performance on fluid intelligence tasks, also show slower rates of improvement with training compared to those that rely to a greater degree on crystallized knowledge.
General Discussion
While this initial glimpse at this dataset hints at the potential for very large datasets to provide unique insights to our understanding of human cognition, there are also challenges and potential limitations to the approach taken here. For one, since users are free to train in a variety of more or less controlled ways on the website, our ability to control the training experiences of our samples is reduced when compared to controlled laboratory-based experiments. As with any self-selected online population, the demographics of the Lumosity user base may not perfectly mirror the population, and it isn't currently possible to fully verify users' self-reported health and demographic information.
In the future it will be important complement the “big data” approach taken here with more controlled studies that can further validate these findings. The ability to deliver training and testing online, and the large existing user base offers promise for conducting large-scale controlled experiments that would not be possible in traditional laboratory research. Lumos Labs researchers and external research collaborators are currently designing and running several such studies in different settings, including in schools and in specific patient populations. Making it possible to run controlled experiments on subsets of this user population who have opted in to experimental training will also be crucial to determining the factors underlying peak cognitive performance.
We have only scratched the surface of what the further study of this dataset might uncover, and we would like to invite other researchers interested in questions related to health and cognition to partner with us in exploring our growing dataset in order to make new breakthroughs.
Conflict of Interest Statement
Daniel Sternberg, Kacey Ballard, Joseph Hardy and Michael Scanlon are employed by Lumos Labs, and have stock options with the company. Benjamin Katz was also employed by Lumos Labs at the time he contributed to this project. P. Murali Doraiswamy has received research grants and/or advisory fees from NIH and several pharmaceutical companies (for other studies), and he owns stock in Sonexa and Clarimedix (whose products are not discussed here). He has no financial relationship with Lumos Labs.
Use of Human Subjects Data
The analyses of aggregated de-identified data reported in this manuscript met the criteria for “exempt research” as determined by the Duke University Medical Center Institutional Review Board.
References
Birnbaum, M. H. (2004). Human research and data collection via the Internet. Annu. Rev. Psychol. 55, 803–832. doi: 10.1146/annurev.psych.55.090902.141601
Britton, A., Singh-Manoux, A., and Marmot, M. (2004). Alcohol consumption and cognitive function in the Whitehall II study. Am. J. Epidemiol. 160, 240–247. doi: 10.1093/aje/kwh206
Buhrmester, M., Kwang, T., and Gosling, S. D. (2011). Amazon Mechanical Turk: A new source of inexpensive, yet high quality, data. Perspect. Psychol. Sci. 6, 3–5. doi: 10.1177/1745691610393980
Craig, M. C., Maki, P. M., and Murphy, D. G. M. (2005). The Women's Health Initiative Memory Study: findings and implications for treatment. Lancet. Neurol. 4, 190–194. doi: 10.1016/S1474-4422(05)01016-1
Heinrich, J., Heine, S. J., and Norenzayan, A. (2010). The weirdest people in the world. Behav. Brain Sci. 33, 61–83. doi: 10.1017/S0140525X0999152X
Doraiswamy, P. M. (2012). Is the idle mind a devil's workshop. Biol. Psychiatry 71, 765–766. doi: 10.1016/j.biopsych.2012.02.032
Ferrie, J. E., Shipley, M. J., Akbaraly, T. N., Marmot, M. G., Kivimäki, M., and Singh-Manoux, A. (2011). Change in sleep duration and cognitive function: findings from the Whitehall II study. Sleep 34, 565–573.
Hampshire, A., Highfield, R. R., Parkin, B. L., and Owen, A. M. (2012). Fractionating human intelligence. Neuron 76, 1225–1237. doi: 10.1016/j.neuron.2012.06.022
Kraut, R. E., Olson, J., Banaji, M., Bruckman, A., Cohen, J., and Couper, M. (2003). “Psychological research online: opportunities and challenges,” in Report prepared for the American Psychological Association's Taskforce on the Internet and Psychological Research. Retrieved May 29, 2013. Available online at: http://www.apa.org/science/leadership/bsa/internet/internet-report.pdf
Landau, S. M., Marks, S. M., Mormino, E. C., Rabinovici, G. D., Oh, H., O'Neil, J. P., et al. (2012). Association of lifetime cognitive engagement and low be β-amyloid deposition. Arch. Neurol. 69, 623–629. doi: 10.1001/archneurol.2011.2748
Levitt, H. (1971). Transformed up-down methods in psychoacoustics. J. Acoust. Soc. Am. 49, 467–477. doi: 10.1121/1.1912375
Marmot, M. G., Stansfield, S., Patel, C., North, F., Head, J., White, I., et al. (1991). Health inequalities among British civil servants: the Whitehall II study. Lancet 337, 1387–1393. doi: 10.1016/0140-6736(91)93068-K
Mason, W., and Suri, S. (2012). Conducting behavioral research on Amazon Mechanical Turk. Behav. Res. Methods 44, 1–23. doi: 10.3758/s13428-011-0124-6
Park, D. C. (1999). “The basic mechanisms accounting for age-related decline in cognitive function,” in Cognitive Aging: A Primer, eds D. C. Park and N. Schwarz (Bridgeport, NJ: Taylor and Francis), 3–21.
Reips, U. D. (2004). “The methodology of internet-based experiments,” in The Oxford Handbook of Internet Psychology, eds. A.Johnson, K. McKenna, T. Postmes, and U. D. Reips (Oxford: Oxford University Press), 373–390.
Salthouse, T. (2009). When does age-related cognitive decline begin. Neurobiol. Aging 30, 507–514. doi: 10.1016/j.neurobiolaging.2008.09.023
Keywords: lifestyle factors, learning, aging, cognition, cognitive enhancement, fluid intelligence
Citation: Sternberg DA, Ballard K, Hardy JL, Katz B, Doraiswamy PM and Scanlon M (2013) The largest human cognitive performance dataset reveals insights into the effects of lifestyle factors and aging. Front. Hum. Neurosci. 7:292. doi: 10.3389/fnhum.2013.00292
Received: 26 January 2013; Accepted: 03 June 2013;
Published online: 20 June 2013.
Edited by:
Hauke R. Heekeren, Freie Universität Berlin, GermanyReviewed by:
Florian Schmiedek, Max Planck Institute for Human Development, GermanyCopyright © 2013 Sternberg, Ballard, Hardy, Katz, Doraiswamy and Scanlon. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and subject to any copyright notices concerning any third-party graphics etc.
*Correspondence: Daniel A. Sternberg, Lumos Labs Inc., 153 Kearny Street, 6th Floor, San Francisco, CA 94108, USA e-mail: daniel@lumoslabs.com