
- 1 Department of Electrical Engineering, Korea Advanced Institute of Science and Technology, Daejeon, Republic of Korea
- 2 Information and Electronics Research Institute, Korea Advanced Institute of Science and Technology, Daejeon, Republic of Korea
In recent years, predictive coding strategies have been proposed as a possible means by which the brain might make sense of the truly overwhelming amount of sensory data available to the brain at any given moment of time. Instead of the raw data, the brain is hypothesized to guide its actions by assigning causal beliefs to the observed error between what it expects to happen and what actually happens. In this paper, we present a variety of developmental neurorobotics experiments in which minimalist prediction error-based encoding strategies are utilize to elucidate the emergence of infant-like behavior in humanoid robotic platforms. Our approaches will be first naively Piagian, then move onto more Vygotskian ideas. More specifically, we will investigate how simple forms of infant learning, such as motor sequence generation, object permanence, and imitation learning may arise if minimizing prediction errors are used as objective functions.
Introduction
With 50 million neurons and several hundred kilometers of axons terminating in almost one trillion synapses for every cubic centimeter, yet consuming only about 20 W of energy for the entire cortex, the brain is arguably one of the most complex and highly efficient information processing systems known (Hart, 1975; Drubach, 2000). It is also the seat of sensory perception, motor coordination, memory, and creativity – in short, what makes us human. How this is precisely achieved by an approximately 1500 g piece of flesh remains one of the last frontiers of modern science.
This task becomes even more Herculean if one attempts to build an artificial system capable of emulating at least some of the core competences of the mammalian brain. von Neumann (1958) in his remarkable little book titled “The Computer and the Brain” elegantly elaborated the key puzzle here: programmable digital computers (as co-championed by him; now termed “von Neumann machines”) solve complex problems by subdividing them into myriads of elementary logical propositions that are then processes in a serial fashion. This is possible since (a) digital computers operate at incredibly high clock speed, and (b) because – assuming no hardware/software flaw – the result of each computation step is error-free. So much different, however, is how the brain solves problems. Individual neurons encode/decode information at <103 Hz, yet, in less than 200–300 ms, complex visual objects are recognized. That is to say, within 102 to 103 computation steps, our brain somehow manages to clean up the noisy spatio-temporal fluctuations of incoming photons on the retina, encode key information embedded within such fluctuations in the language of spike trains, relay them to dozens of more specialized high-order visual areas, extract invariant visual features using mysteriously judicious neuromorphic machine learning algorithms, and finally bind the distributed features into a uniform percept which lets “us” feel the qualia of the perceived object. Reminding ourselves that even the simplest “hello world” can take up almost 101 lines of code in modern object oriented programming languages, and most non-trivial machine learning algorithms require anywhere between 103 and 106 encoding steps, this is indeed a very remarkable achievement. Even more puzzling, as von Neumann observed, neurons are most likely able to perform computations at a mere two to three decimals only. Given the rapidly accumulating rounding errors at such low level of precision, truly complex computations seem out of question. Yet, ipso facto the brain must have figured out how to do it.
In recent years, predictive coding strategies have been proposed as a possible means by which the brain might indeed escape the von Neumannian limitations (Rao and Ballard, 1999; Bar, 2009; Bubic et al., 2010; Wacongne et al., 2011). In this brave new prediction-land, the traditional perception-to-cognition-to-action strategies are deemed to be incompatible with what we know about how the brain, in real time, makes sense of truly massive amount of sensory data. As other papers in this special issue will elaborate in great detail, predictive encoding schemes will most likely entail two distinct mechanisms: one that uses prediction error rather than incoming raw data as the fundamental currency of the brain’s information processing (Srinivasan et al., 1982; Hosoya et al., 2005; Navalpakkam and Itti, 2007); and the secondary information interpretation system that assigns a cause (“belief”) to the observed prediction error (Nijhawan, 1997; Kersten et al., 2004; Collerton et al., 2005; Summerfield et al., 2006; Hohwy et al., 2008). From a more teleological point of view, the objective function of the brain is then to minimize the prediction error (i.e., “free energy” or “surprise”; Friston, 2010; Friston et al., 2011, 2012) in the next iteration by modifying the state and/or the sensory bandwidth of the brain. This is where neurorobotics comes in. Notwithstanding the various incarnations of this field, neuroroboticists unite the conviction that embodiment (Weng et al., 2001; Pfeifer et al., 2007; Kaplan, 2008; Friston, 2011; Kaplan and Oudeyer, 2011), i.e., the physical state of the artificial agent should play a significant role in determining its behavioral fabric (Dickinson et al., 2000; Pfeifer and Bongard, 2007). Secondly, albeit conceptually simple forward processing robotics schemes have gained some traction thanks to the availability of cheap brute force number crunchers (Siciliano and Khatib, 2008), more inferential systems make a much better use of the available resources than those that do not (see, e.g., Rucci et al., 2007 versus Siciliano and Khatib, 2008). Thirdly, and this being more our personal bias, many neurorobotics frameworks not only attempt to replicate the behavioral outcomes per se, but they also venture to explain the entire genesis of behavioral chains within neurobiologically realistic constraints (Fleischer et al., 2007; Oudeyer et al., 2007; Yamashita and Tani, 2008; Namikawa et al., 2011).
In this paper we will present a variety of neurorobotics experiments in which minimalist prediction error-based encoding strategies are utilized to elucidate the emergence of infant-like behavior in robots. Our approaches will be first naively Piagian (Piaget, 1954), then move onto more Vygotskian (Vygotsky, 1986), which are psychological hypotheses on the development of the cognitive abilities in the human infants. First, we will build a robot which generates the self-emerging cognitive functions by experiences, similarly to Piaget’s explanation of infant learning. We will demonstrate this in our first and second experiments on motor sequence learning and object permanence learning. Then, we will show that a robot performs imitative learning, which is the core of Vygotskian development. Thus, we will investigate how simple forms of infant-like functions may arise from the frameworks to use minimization of prediction errors as the objective functions.
Overall Materials and Methods
For all experiments described in this study, commercially available humanoid robots have been used in conjunction with a variety of custom-written neural modeling software in Matlab (MathWorks, Natick, MA, USA) and C++. AnNAO humanoid robot system (Aldebaran Robotics, Paris, France) was the platform of choice for experiments #1 and #2 (see Figures 1, 2, and 4). Its movements are controlled by actuators with a total of 25 degrees of freedoms (five DOFs in one arm; body size: 57.3 cm with an internal camera module in the head). To achieve the higher image resolution and frame rate (>10 fps) needed for experiment #2, we used an external CCD camera (920 p) mounted on the head. Experiment #3 was performed by using two identical sets of the DARwIn-OP humanoid robot platform (RoMeLa, Blacksburg, VA, USA; see Figure 7). It is 45.5 cm tall (20 degree of freedom movement) and has a built-in 2-mega pixels resolution camera. For the sake of computational efficacy, the effective resolution was reduced to 320 × 240 pixels. Finally, for the imitation experiments described in this work, only the 2 × 3 degrees of freedom associated with the left and right arm motions were used.
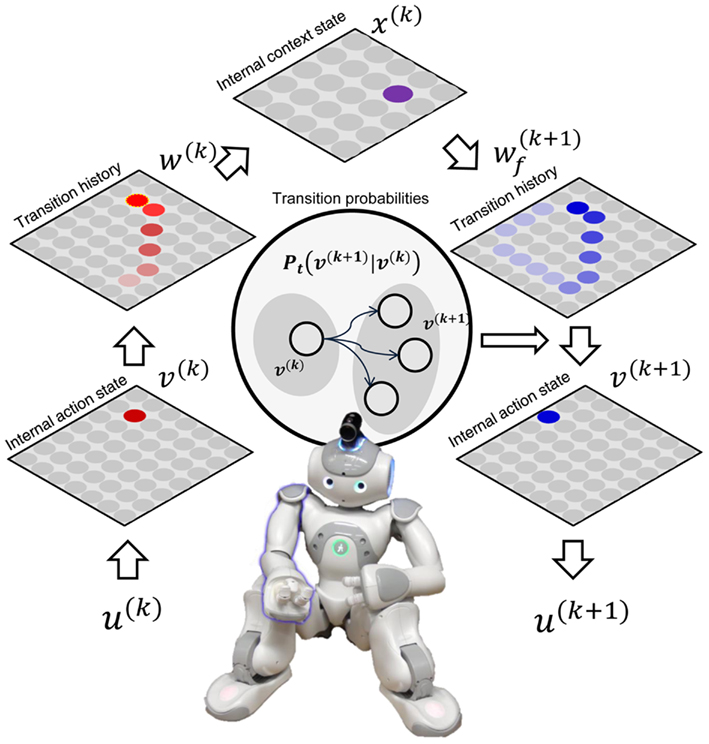
Figure 1. Structure of motor action learning and reproduction system. The current action feature vector u(k) is reduced to internal action state v(k). From recent history w(k) of the internal action state (bright red is recently activated neuron), we can evaluate the most probable current action sequence state x(k). An action sequence state stores the probability of an action state within a sequence [w(k + 1) bright blue node is a more feasible action state]. With this top-down probability and the immediate probability of the next action state (Pt), we can find the posterior probabilities of the incoming action state, v(k + 1). From the first SOFM layer, this action state maps to action feature vector u(k + 1). The robot generates the action represented by u(k + 1).
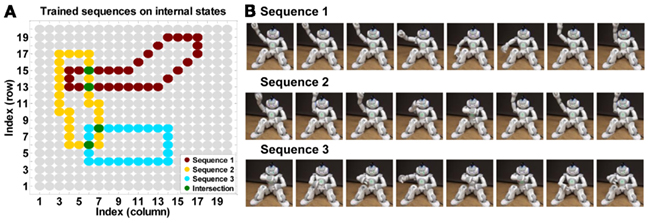
Figure 2. Training action sequences and regeneration. (A) Three target sequences represented on internal action space. Green dots represents action states overlapped in two sequences. (B) These trained action sequences are reproduced by the humanoid robot.
Neurorobotic Experiments
Learning Motor Sequences through Prediction Error Minimization
During the first 2 months of life, human infants explore the kinematic envelope of their body motion through brisk and repetitive body movements, such as kicking their legs (Maja, 1998). Such purely itinerant motor actions are soon replaced by more coherent motor sequences. In neurorobotics, a few studies (Tani, 2003; Tani et al., 2004; Kober and Peters, 2009) have reported the emergence of motor sequences from experiences. In particular, Tani et al. reported an arm robot with recurrent neural network with parametric bias (RNNPB), which could passively learn and reproduce it. Similar to their approaches, we attempted to replicate the transition from random to coherent motor action sequences of infants, using a humanoid neurorobotic platform. In contrast to Tani’s model, we used two-layered self-organizing feature map (SOFM) and the transition matrixes within them.
The task for the robot was to learn and reproduce three distinct motor sequences by representing motor sequences as continuous trajectories in a SOFM (see, e.g., Kohonen, 1990, 2001). Our system is composed of a two-layer SOFM and a transition probability matrix for each layer. The first layer stores feasible motor conformations, and its transition matrix stores direct transition probability among the conformations. The second layer stores feasible motor sequences built from the first layer and transition probabilities among the sequences. To minimize predictive error, our system generated the most probable actions from top-down and bottom-up Bayesian methods. Robot could restore precise trained behavior. Detailed methods are followed.
First, our robot extracted the set of feasible states of its own motor action space. While a human subject manipulated the robot’s right arm exploring the feasible action states, the five respective actuator angle values were sampled (10 Hz, total 1500 samples) indicated as feature vectors u(k) ∈ ℝ5 for k = 1, …, 1500. This set of feature vectors of feasible states was used by the SOFM to build a map of 20 × 20 two-dimensional internal action states, vs (Figure 1).
After the internal action state space was formed with the SOFM, three action sequences were trained by a predefined dataset. The dataset was given as sequences of internal states vs for 120 time steps, and it was a simple shape of trajectory (Figure 2A). While the three sequences were being trained, the state transition probabilities Pt(vm | vn) for all state vn to all other states vm were computed. Additionally, action sequences were represented in action sequence space w ∈ ℝ20 × 20 by tracing action history: the value of each cell in w is set to one when corresponding internal state v is activated, and the value diminished according to Eq. 1 with increasing time steps (Figure 2A, action sequence). The action sequences were given to 10 × 10 SOFM to build a map of sequence states, xs. Each sequence state neuron memorized parts of the action sequence.
To reproduce motor actions, the immediate transition probability (Pt) of the current action state and top-down probabilities of actions from the current sequence are combined. The current action sequence was generated by Eq. 1, and this was mapped to the action sequence map to find the current sequence state. This sequence state determined the probabilities of activation of action states. Those two probabilities are multiplied for posterior probability. The robot activated the action with the maximum posterior probability. For initializing actions, initial 10 action states of trained sequences were delivered to the system, and this was followed by 120 time steps of actions generated by the system. We tested our model for 1000 randomly selected different initial conditions for three sequences. In 100% of the cases, it could generate perfect sequence trajectories.
Interestingly, our model could resolve overlapping sequence problems. There were four internal action states in which sequences overlapped (one example is Figure 3A, sequence 2 and 3 overlap). In those states, the robot should select the feasible action for the current sequence, and it is impossible only with transition probabilities (Figure 3A, the robot will select sequence 3 instead of sequence 2). The recent actions of the robot are represented in action sequence space as (Eq. 1), and this is used to define the current action sequence. The current action sequence fed back probabilities of activation of action states (Figure 3B). Top-down prior knowledge about a sequence could resolve the conflict to produce the right action sequence (Figure 3C). As a result, we made our robot to learn possible motor sequences by itself.
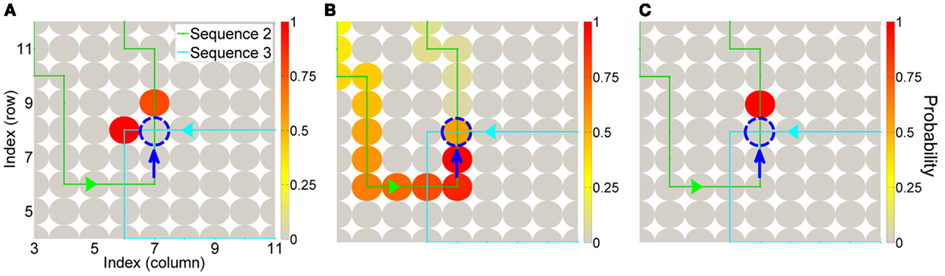
Figure 3. Resolving conflict between overlapping sequences. The next action state was resolved, in which two sequences are overlapping. (A) In generating action sequence 2, the robot arrived at the cell emphasized with the blue dashed line, where two sequences (2 and 3) are overlapping. Only with state transition probability Pt(vm | vn) the robot should follow the left cell of the blue dashed line in sequence 3. (B) The top-down probability from the current sequence cell shows the probability of activation for each cell. (C) With the top-down probability and transition probability, sequence 2 is selected and followed.
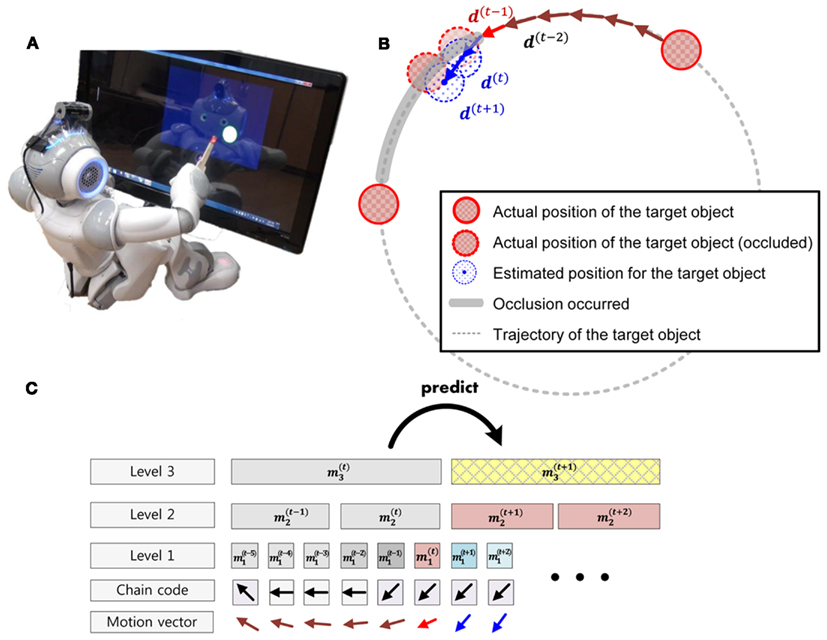
Figure 4. Structure of permanence system. (A) Humanoid robot NAO tracking a target object on a screen. (B) The target object moves in a circular trajectory. When the target object arrived at a predefined position, the object was occluded for specific time. Our humanoid robot stored the trajectory of the object with a hierarchical Bayesian inference system (C) and predicted the position of the object under occlusion.
Our result is comparable to the RNNPB results of Tani et al. (2004). Within RNNPB, the primitive sub-sequence patterns are self-organized in a recurrent neural network. Similarly, the feasible motor spaces and the sequences are hierarchically self-organized in our model. Within the minimization of the prediction error framework, the self-organized model of the world was used to produce the motor sequences. In comparison to Tani’s models, our SOFM has more explicit coding of the state space which is tractable to the system.
Object Permanence
One of the most remarkable cognitive faculties displayed during early infanthood is the ability to form a conception of object permanence (Moore et al., 1978; Gredebäck et al., 2002; Gredebäck and von Hofsten, 2004; Rosander and von Hofsten, 2004). This ability is justly considered a milestone in an infant’s cognitive development, as it enables the brain to perform relational operations on both what is physically present as well as on what is merely inferred to be present in the visual environment. In this second experiment we designed a simplified hierarchical Bayesian inference system (similar to Hierarchical Temporal Memory, Hawkins and Blakeslee, 2004; George, 2008; Hawkins et al., 2009; Greff, 2010) capable of forming beliefs regarding the current position of a visual object, even if it is in fact occluded by a masking object.
A camera attached to a robot head collected the target images (10 Hz, 424 × 240 resolution). The images were preprocessed so that the movements of a visual object were represented by transition directions at each time step, d(t) ∈ D, D = {0 to 7/8π; 1/8π steps}, and we set chain codes, each of which includes the time series of the transition directions of the object for each period of time. We used five consecutive chain code tuples m1 ∈ D5 for the base level of our hierarchical model to describe the movement for each time step.
We let the model learn the movement state sequence with our hierarchical model. Each node of our model at the kth level stored movement states, mk (spatial pooler in Figure 5) and the transition probabilities, between the states (Markov graph in Figure 5). The 2 ∼ 4 consecutive movement states were concatenated to build longer sequence information, mk+1 ∈ mk ⊕ mk ⊕ … ⊕ mk, (Temporal pooler in Figure 5) and this was fed forward to a higher region (Forward output in Figure 5). A higher node repeated this process. As a result, a higher region node stored a longer sequence of movements and the transition probabilities between longer sequences.
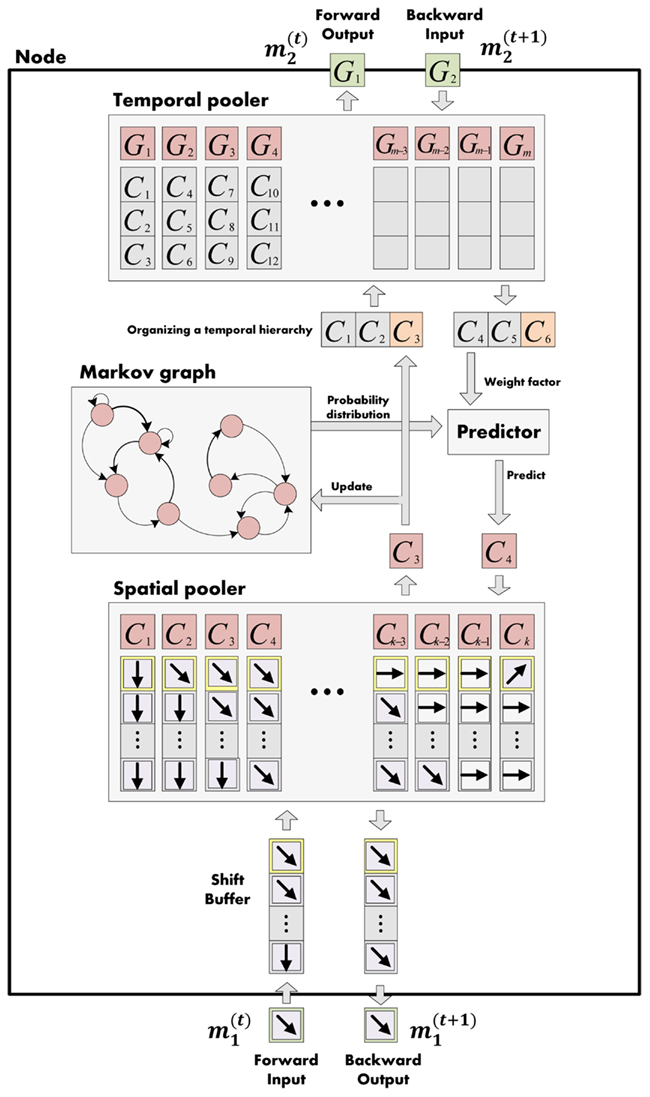
Figure 5. Structure one level of hierarchical Bayesian system. It records movement sequence from forward input (spatial pooler) and finds the transition probability across spatial poolers (markov graph). The movement sequences are concatenated and fed forward to a higher level. As a result, the higher level stores longer sequences. When inferring the next movement, the probability from the current level (from Markov graph) and feedback probability from the higher level (backward input) are combined in the predictor to find the posterior probabilities for the next possible movements.
Training was followed by occlusion tasks. When a target dot arrived at a specific occlusion point in a circular trajectory, the dot was occluded. We conducted an experiment in which the occlusion time was varied from 500 to 3000 ms (500, 1000, 1500, 2000, 2500, 3000 ms). At occlusion times, our model predicted the movement sequence of the target dot in a Bayesian manner. For each node at the kth level, evidence about the current movement was given bottom-up to a higher node. Higher nodes selected longer sequences which had the highest probability for the evidence sequence with length n. The selected sequence gave prior knowledge about incoming movement sequence and it was fed back to a lower node. The node combined the prior probability top-down and probability of immediate transition probability its own Markov graph to build posterior probabilities of movement sequences (Figure 5). The sequence with the best posterior probability in the lowest node was selected as the current predicted motion of the occluded object.
Our model predicted the positions of predicted objects better than without prediction (Figure 6). Our machine could track the correct position of an occluded object more than 80% of the time within 500 ms. This accuracy was reduced as the occlusion time increased but our model tracked occluded objects better than tracking without prediction (Figure 6). We built a map from object position to robot action state. With this map, our robot could follow the visual and occluded object.
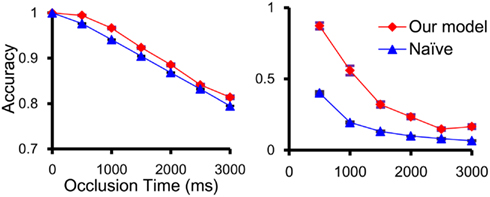
Figure 6. Accuracy of permanence model was calculated as the percentage of time in which the distance between the predicted position and real position were under object size. Our model showed better performance in estimating the position of the object than a model without prediction (naïve) for both the total time tracking (left) and a specific time interval with occlusion (right).
Imitation Learning
In our final neurorobotics experiment, we attempted to provide a simple error-prediction based model to capture the key features of imitation learning. Action learning through imitation is one of the most prominent infant learning behaviors, considered to be a key element in the genesis of unsupervised learning capabilities in humans. In imitation learning, subjects should produce the similar sequences of self-images to the teacher’s image sequences of particular motor actions.
In this area, Ito and Tani (2004) proposed the RNNPB based model. In their experiment, a robot’s RNNPB was trained with the positions of two visual markers and joint angles corresponding to the marker’s positions. When the sequences of the positions of the visual markers were given, the robot could reproduce the corresponding motor sequences. They used only the positions of the visual markers to represent the visual image of self and target. In contrast, our robot had to reproduce motor sequences from the target’s whole visual image.
In our experimental setting (see Figure 7) two physically identical copies of DARwIn-OP humanoid robotic platforms were placed such that their vision systems would capture the other in the center of their respective visual fields. Of the two robots, the independent “teacher” robot performed a number of predefined motor sequences employing its two arms. The dependent “infant” robot, on the other hand, had to learn and imitate the teacher’s motor sequences without any prior knowledge of the teacher’s motor sequences.
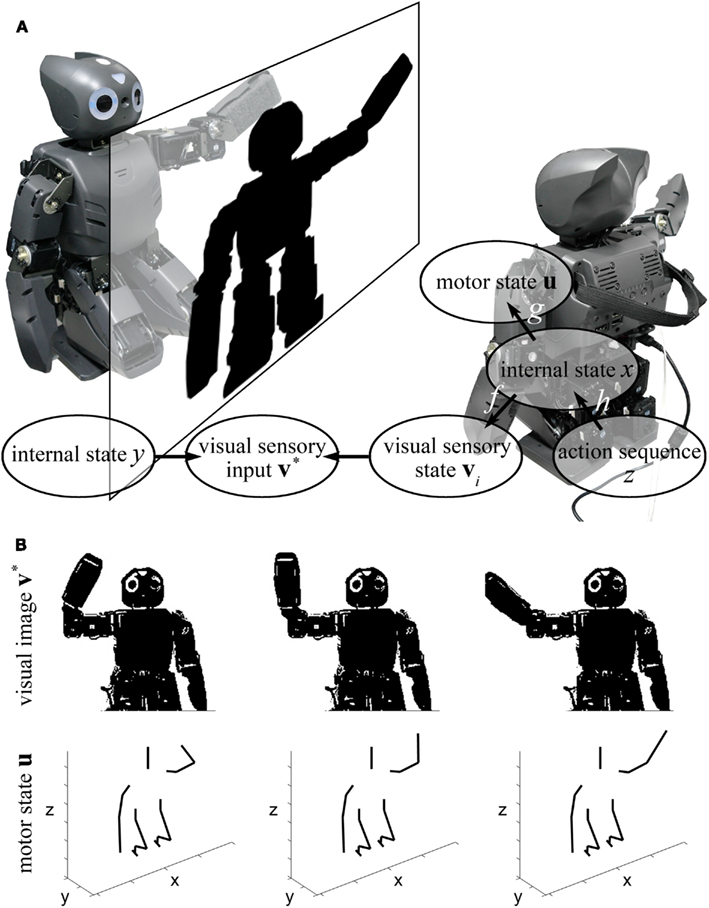
Figure 7. Structure of imitation learning. (A) The target system (left robot) produces image sequence (v*) from internal state sequence (y). The agent system (right robot) follows by mapping the image sequence (v*) to the memorized self-image of (vi) whose internal action states x is known. The target’s visual sequence produces a sequence of internal action states in agent. The agent trains this sequence to build action sequences (z) and reproduces the action to real motor state u. (B) The agent sees visual images of target robot (up), and the motor state of the agent is derived from the image (down).
To imitate another, an infant needs to know how similar/dissimilar its actions are going to be with respect to those displayed by the teacher. We hypothesize that this can be done by acquiring two categories of information: a visuomotor map, how self-body configuration is to imitate teacher robot’s image in a time; and an action sequence model, how the configurations connect to generate particular motor actions.
Our imitation system is composed of three parts: a motor state model g and action sequence model h, which are neural networks to learn and generate motor sequences, and a visuomotor map f, which is the association between self-image and self-model (Figure 7B). By matching the target images to self-image, target image sequences were estimated to the self-motor states of the agent robot. With the sequence of self-motor sequences, the robot could build an action sequence model of actions, which was used to generate real actions.
First, the agent learned the possible motor states. The two arms of the agent robot generated random motions, and the angles of six actuators (three for each arm) were sampled to a set of feature vectors The feature vectors were delivered to SOFM g, and the motor state space u ∈ ℝ6 was reduced to 900 (30 × 30, two-dimensional), the number of internal motor state cells xs, preserving the topology of the feature space. Next, we produced a visuomotor map f between internal motor state cell x and the robot’s self-visual image v. For each internal motor state cell x, a corresponding motor action was generated, and a visual image of the robot was taken. The image was processed to binary visual image v is on visual sensory space ℝ320×240 and mapped to the internal motor state x (Figure 7B).
To imitate the action sequences of the target system, sequences of images for t = 1, …, k generated by the target were given to the agent. By configuring the maximally matched stored images v is in f given image v*, the robot can find what action state the target is performing under the assumption that the target system also follows the f of the agent. The motor state sequences xt for t = 1, …, k were extracted from the sequence of delivered images. Our robot generated transition matrix across each internal motor state and a model h of action sequences as in the first experience. The action sequence model h equals an SOFM having neurons to represent action sequences where each neuron is referred to as action sequence state z. The imitation of the agent was the generation of the most probable motion sequences given the motions of the target. Thus, if the target system generated its motions according to its states, the agent followed the series of motions by estimating the most probable action sequence state z in h at each time t and by generating the most probable internal motor state x and motion u and at t + 1 given zt.
In the experiment, we trained five different motion sequences to imitate. Among the total of 30 action sequences provided, 25 sessions were one of the five action sequences randomly provided, and for five random sessions, random action sequences were delivered. In the test, we provided 100 sessions of action sequences, each of which was an action sequence randomly selected among the five types in the training.
We tested the performance of our model in two domains, where we set the numbers of both internal motor states in a map g and action sequences in a map h to 900, each of which represented a representative motor action and action sequence. First, we tested whether the model of the agent’s actions was the same as the target’s. The generated motor states in the space motor state model resulting from imitative actions of the agent were compared to the motor states of the target system under the assumption that the target system had the same motor state model. Second, we compared the image of the target and agent during imitation. For each image in all imitation time, we classified pixels of the target and agent’s images into two classes: robot and background by brightness threshold. We summated the number of pixels in the same class.
In the case of performance measure in internal state space, the predicted internal states xs of the agent at each time were compared against the series of states ys of the target, assuming that the target system had the same SOFM g. Examples of imitative actions of the agent against each of the five types of target system actions are shown in Figure 8. The skeleton images of the target system were flipped with respect to y–z plane for qualitative comparisons between the actions of the target and the imitation of the agent. The result of quantitative measure over motor space is shown in Table 1, and is only 31.20% while the qualitative result in Figure 8 indicated reliable performance.
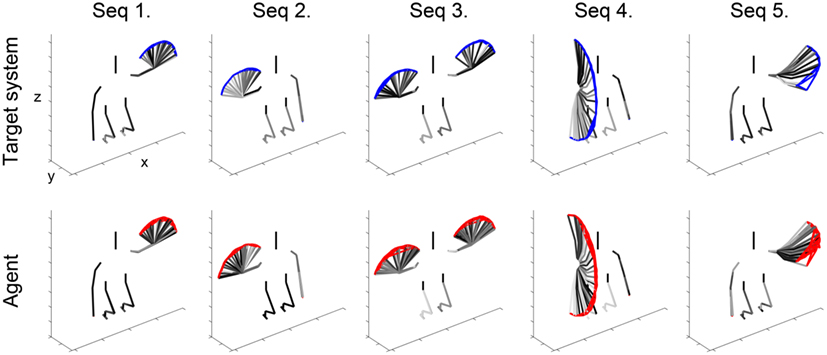
Figure 8. Our agent imitates five target action sequences. The agent (bottom) imitates all five action sequences of the target system (top). Red and blue lines show the trajectory of the tip of the hand, and black line is the skeleton of the systems during overlapping for task time.
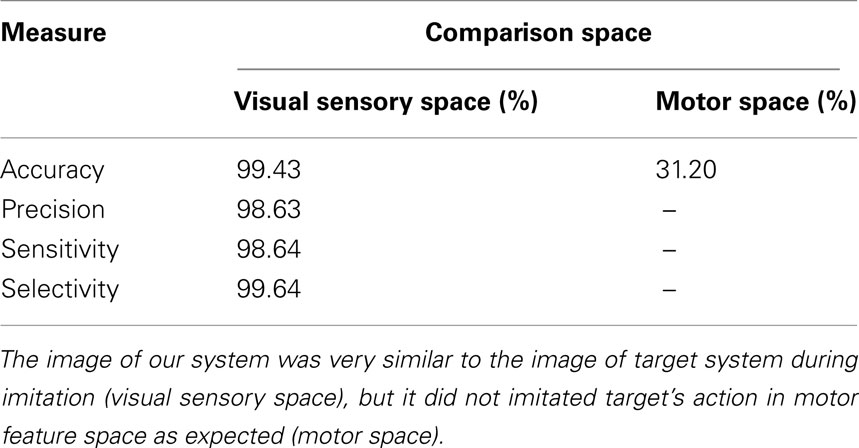
Table 1. Result of imitation of the agent in visual sensory and internal state space.
In the case of performance measure in visual sensory space, we measured four quantities, namely, accuracy, precision, sensitivity, and selectivity, as shown in Table 1. The results show that the imitative actions generated by the series of predictive estimation of xs under the estimation of the most probable action sequences z were over 98% for all four measures while the performance measure over the SOFM g was low.
The results demonstrate inconsistent performance of the imitative actions of the agent against each domain where the performance were measured. The measures over the visual sensory space indicated successful imitative actions of the agent as with the qualitative comparisons, while the measure over the internal state space showed discrepancy. This inconsistency, especially of the result over the internal state space, resulted because the internal states of the target estimated by the agent based on the visual sensory inputs were different from the actual internal states of the target; however, the estimated state and the actual one represented similar or almost identical features over motor and visual sensory inputs because of the characteristics of SOFM g, in which neurons neighboring each other represent similar information. Thus, the behavioral performance for the imitative actions of the agent was above 98%, even though the estimated sequences of the internal states differed from the actual states of the target.
Furthermore, our results indicate that learning and internalization by imitation of motor action sequences of a target system in terms of the internal motor map help an agent to learn a set of action sequences, expending from random actions to a congruent set of actions. Using the association between self-images and self-motor conformations, our robot could figure out what conformation should be used to imitate the target’s images. Our robot internalized the target robot’s image and image sequences into the self-image sequence and finally into self-motor sequences.
Conclusion
Infants are born with only a limited model of the world encoded in their genes, and they need to construct successive belief models about most causes and their causal relations in the world. This learning process includes causal models about their own bodies. Even more, our brain is faced with only incomplete data about the world. Predictive coding schemes may explain how the brain constructs a hypothetical model of the world and uses this model to generate prediction for incoming signals. With such an ideomotor perspective, predictive coding can explain how actions are produced by minimizing prediction error. With this framework, the results of our study suggest that even minimalist prediction error (experiment #1) and causal inference (experiments #2, and #3) can replicate key features observed during the emergence of infant learning phenomena, such as action sequence generation, object permanence, and imitation. Future studies have yet to provide the full evidence that neurorobotic frameworks using predictive coding schemes will fare substantially better on our challenging task of building truly intelligent machines modeled after human beings.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This research was supported by NAP of the Korea Research Council of Fundamental Science & Technology (P90015) and by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science, and Technology 2011-0004110, 2011-0018288.
References
Bar, M. (2009). Predictions: a universal principle in the operation of the human brain. Philos. Trans. R. Soc. Lond. B Biol. Sci. 364, 1181–1182.
Bubic, A., Von Cramon, D. Y., and Schubotz, R. I. (2010). Prediction, cognition and the brain. Front. Hum. Neurosci. 4:25. doi: 10.3389/fnhum.2010.00025
Collerton, D., Perry, E., and Mckeith, I. (2005). Why people see things that are not there: a novel perception and attention deficit model for recurrent complex visual hallucinations. Behav. Brain Sci. 28, 737–757; discussion 757–794.
Dickinson, M. H., Farley, C. T., Full, R. J., Koehl, M. A. R., Kram, R., and Lehman, S. (2000). How animals move: an integrative view. Science 288, 100–106.
Fleischer, J. G., Gally, J. A., Edelman, G. M., and Krichmar, J. L. (2007). Retrospective and prospective responses arising in a modeled hippocampus during maze navigation by a brain-based device. Proc. Natl. Acad. Sci. U.S.A. 104, 3556–3561.
Friston, K. (2010). The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11, 127–138.
Friston, K. (2011). “Embodied inference: or ‘I think therefore I am, if I am what I think’,” in The Implications of Embodiment: Cognition and Communication, eds W. Tschacher, and C. Bergomi (Exeter: Imprint Academic).
Friston, K., Mattout, J., and Kilner, J. (2011). Action understanding and active inference. Biol. Cybern. 104, 137–160.
Friston, K. J., Shiner, T., Fitzgerald, T., Galea, J. M., Adams, R., Brown, H., Dolan, R. J., Moran, R., Stephan, K. E., and Bestmann, S. (2012). Dopamine, affordance and active inference. PLoS Comput. Biol. 8, e1002327. doi: 10.1371/journal.pcbi.1002327
George, D. (2008). How the Brain Might Work: A Hierarchical and Temporal Model for Learning and Recognition. Ph.D. thesis, Stanford University, Stanford.
Gredebäck, G., and von Hofsten, C. (2004). Infants’ evolving representations of object motion during occlusion: a longitudinal study of 6- to 12-month-old infants. Infancy 6, 165–184.
Gredebäck, G., Von Hofsten, C., and Boudreau, J. P. (2002). Infants’ visual tracking of continuous circular motion under conditions of occlusion and non-occlusion. Infant Behav. Dev. 25, 161–182.
Greff, K. (2010). Extending Hierarchical Temporal Memory for Sequence Classification. M.S. thesis, Technische Universität Kaiserslautern, Kaiserslautern.
Hart, L. A. (1975). How the Brain Works: A New Understanding of Human Learning, Emotion, and Thinking. New York, NY: Basic Books.
Hawkins, J., George, D., and Niemasik, J. (2009). Sequence memory for prediction, inference and behaviour. Philos. Trans. R. Soc. Lond. B Biol. Sci. 364, 1203–1209.
Hohwy, J., Roepstorff, A., and Friston, K. (2008). Predictive coding explains binocular rivalry: an epistemological review. Cognition 108, 687–701.
Hosoya, T., Baccus, S. A., and Meister, M. (2005). Dynamic predictive coding by the retina. Nature 436, 71–77.
Ito, M., and Tani, J. (2004). On-line imitative interaction with a humanoid robot using a dynamic neural network model of a mirror system. Adapt. Behav. 12, 93–115.
Kaplan, F. (2008). Neurorobotics: an experimental science of embodiment. Front. Neurosci. 2:23. doi: 10.3389/neuro.01.023.2008
Kaplan, F., and Oudeyer, P.-Y. (2011). “From hardware and software to kernels and envelopes: a concept shift for robotics, developmental psychology, and brain sciences,” in Neuromorphic and Brain-Based Robots, eds J. L. Krichmar, and H. Wagatsuma (Cambridge: Cambridge University Press), 217–250.
Kersten, D., Mamassian, P., and Yuille, A. (2004). Object perception as Bayesian inference. Annu. Rev. Psychol. 55, 271–304.
Kober, J., and Peters, J. (2009). “Learning motor primitives for robotics,” in Proceedings of the 2009 IEEE International Conference on Robotics and Automation (Kobe: IEEE Press).
Maja, J. M. (1998). Behavior-based robotics as a tool for synthesis of artificial behavior and analysis of natural behavior. Trends Cogn. Sci. (Regul. Ed.) 2, 82–86.
Moore, M. K., Borton, R., and Darby, B. L. (1978). Visual tracking in young infants: evidence for object identity or object permanence? J. Exp. Child. Psychol. 25, 183–198.
Namikawa, J., Nishimoto, R., and Tani, J. (2011). A neurodynamic account of spontaneous behaviour. PLoS Comput. Biol. 7, e1002221. doi: 10.1371/journal.pcbi.1002221
Navalpakkam, V., and Itti, L. (2007). Search goal tunes visual features optimally. Neuron 53, 605–617.
Nijhawan, R. (1997). Visual decomposition of colour through motion extrapolation. Nature 386, 66–69.
Oudeyer, P. Y., Kaplan, F., and Hafner, V. V. (2007). Intrinsic motivation systems for autonomous mental development. IEEE Trans. Evol. Comput. 11, 265–286.
Pfeifer, R., and Bongard, J. (2007). How the Body Shapes the Way We Think: A New View of Intelligence. Cambridge: The MIT Press.
Pfeifer, R., Lungarella, M., and Iida, F. (2007). Self-organization, embodiment, and biologically inspired robotics. Science 318, 1088–1093.
Rao, R. P. N., and Ballard, D. H. (1999). Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 2, 79–87.
Rosander, K., and von Hofsten, C. (2004). Infants’ emerging ability to represent occluded object motion. Cognition 91, 1–22.
Rucci, M., Bullock, D., and Santini, F. (2007). Integrating robotics and neuroscience: brains for robots, bodies for brains. Adv. Robot. 21, 1115–1129.
Srinivasan, M. V., Laughlin, S. B., and Dubs, A. (1982). Predictive coding: a fresh view of inhibition in the retina. Proc. R. Soc. Lond. B Biol. Sci. 216, 427–459.
Summerfield, C., Egner, T., Mangels, J., and Hirsch, J. (2006). Mistaking a house for a face: neural correlates of misperception in healthy humans. Cereb. Cortex 16, 500–508.
Tani, J. (2003). Learning to generate articulated behavior through the bottom-up and the top-down interaction processes. Neural Netw. 16, 11–23.
Tani, J., Ito, M., and Sugita, Y. (2004). Self-organization of distributedly represented multiple behavior schemata in a mirror system: reviews of robot experiments using RNNPB. Neural Netw. 17, 1273–1289.
Wacongne, C., Labyt, E., Van Wassenhove, V., Bekinschtein, T., Naccache, L., and Dehaene, S. (2011). Evidence for a hierarchy of predictions and prediction errors in human cortex. Proc. Natl. Acad. Sci. U.S.A. 108, 20754–20759.
Weng, J. Y., Mcclelland, J., Pentland, A., Sporns, O., Stockman, I., Sur, M., and Thelen, E. (2001). Artificial intelligence – autonomous mental development by robots and animals. Science 291, 599–600.
Keywords: predictive coding, neurorobotics, neuromorphic engineering, neural modeling
Citation: Park J-C, Lim JH, Choi H and Kim D-S (2012) Predictive coding strategies for developmental neurorobotics. Front. Psychology 3:134. doi: 10.3389/fpsyg.2012.00134
Received: 28 February 2012; Paper pending published: 08 March 2012;
Accepted: 16 April 2012; Published online: 07 May 2012.
Edited by:
Lars Muckli, University of Glasgow, UKReviewed by:
Jun Tani, RIKEN Brain Science Institute, JapanKarl Friston, University College London, UK
Copyright: © 2012 Park, Lim, Choi and Kim. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Dae-Shik Kim, Brain Reverse Engineering and Imaging Laboratory, Department of Electrical Engineering, Korea Advanced Institute of Science and Technology, 291 Daehak-ro, Yuseong-gu, Daejeon 305-701, Republic of Korea. e-mail: dskim@ee.kaist.ac.kr
†Jun-Cheol Park and Jae Hyun Lim have contributed equally to this work.