 Aleksandra Bujacz
Aleksandra Bujacz Joar Vittersø
Joar Vittersø Veronika Huta3
Veronika Huta3- 1Faculty of Social Sciences, Institute of Psychology, Adam Mickiewicz University, Poznañ, Poland
- 2Department of Psychology, University of Tromsø, Tromsø, Norway
- 3School of Psychology, University of Ottawa, Ottawa, ON, Canada
Two major goals of this paper were, first to examine the cross-cultural consistency of the factor structure of the Hedonic and Eudaimonic Motives for Activities (HEMA) scale, and second to illustrate the advantages of using Bayesian estimation for such an examination. Bayesian estimation allows for more flexibility in model specification by making it possible to replace exact zero constraints (e.g., no cross-loadings) with approximate zero constraints (e.g., small cross-loadings). The stability of the constructs measured by the HEMA scale was tested across two national samples (Polish and North American) using both traditional and Bayesian estimation. First, a three-factor model (with hedonic pleasure, hedonic comfort and eudaimonic factors) was confirmed in both samples. Second, a model representing the metric invariance was tested. A traditional approach with maximum likelihood estimation reported a misfit of the model, leading to the acceptance of only a partial metric invariance structure. Bayesian estimation—that allowed for small and sample specific cross-loadings—endorsed the metric invariance model. The scalar invariance was not supported, therefore the comparison between latent factor means was not possible. Both traditional and Bayesian procedures revealed a similar latent factor correlation pattern within each of the national groups. The results suggest that the connection between hedonic and eudaimonic motives depends on which of the two hedonic dimensions is considered. In both groups the association between the eudaimonic factor and the hedonic comfort factor was weaker than the correlation between the hedonic pleasure factor and the eudaimonic factor. In summary, this paper explained the cross-national stability of the three-factor structure of the HEMA scale. In addition, it showed that the Bayesian approach is more informative than the traditional one, because it allows for more flexibility in model specification.
Introduction
The distinctions between hedonic and eudaimonic notions of happiness has attracted a rapidly expanding group of well-being researchers (e.g., Keyes et al., 2002; Kopperud and Vittersø, 2008; Berridge and Kringelbach, 2011; Henderson et al., 2013; Huta, 2013; Huta and Waterman, 2013; Oishi et al., 2013; Ryan et al., 2013; Bauer et al., 2014; Proctor et al., 2014; Uchida et al., 2014). Both concepts are derived from ancient philosophy and they came to prominence within positive psychology as a result of research that conceptualized well-being in different ways. Proponents of a strict hedonic approach argue that a good life is properly accounted for by the presence of pleasure and the absence of pain (Kahneman, 1999; Tännsjö, 2007), whereas a broader approach includes positive attitudes and life satisfaction within the idea of hedonia (e.g., Diener, 1984; Feldman, 2004; Diener et al., 2009). By contrast, proponents of eudaimonic approaches believe that there is more to a good life than pleasant feelings and favorable attitudes (Tatarkiewicz, 1976; Ryff, 1989; Waterman, 1993; Ryan and Deci, 2001; Deci and Ryan, 2008; Keyes and Annas, 2009; Vittersø, 2013). In the current study, we enter this debate by looking into an established self-report scale that measures both hedonic and eudaimonic conceptions of well-being—the Hedonic and Eudaimonic Motives for Activities scale (HEMA; Huta and Ryan, 2010). Our two major aims are, first to examine the cross-cultural consistency of the factor structure of the HEMA, and second to illustrate the advantages of using Bayesian estimation for such an examination.
Existing attempts to quantify the associations between elements of hedonic and eudaimonic well-being show mixed results. In a recent review, Huta and Waterman (2013) attributed some of these inconsistencies to conceptual disagreements. Four categories of conceptualizations were identified, as Huta and Waterman observed that well-being has interchangeably been studied as orientations, as behaviors, as experiences and as functioning. Another distinction in the well-being literature relates to the level of analyses: both trait level measures and state level measures were frequently observed. In order to avoid some of these confusions Huta and Waterman argued that it is important to clearly specify which category of analysis and level of measurement is taken into consideration. When focusing specifically on the distinction between eudaimonia and hedonia (as in a factor analysis) and on the stability of the correlation between them (as in a multigroup investigation) the confounding effect of different conceptualizations should be avoided. Therefore, the current paper operationalizes eudaimonia and hedonia as orientations, measured at the trait level. The HEMA scale fulfills both these criteria and was thus elected as the measurement instrument of our study.
The hedonic subscale of the HEMA addresses the two concepts that appear in most conceptions of hedonia: pleasure and absence of pain (e.g., Kahneman, 2000). The absence of pain is assessed in approach terms (as “seeking relaxation” and “seeking to take it easy”) rather than in avoidance terms to minimize the confounding role played by the differential effects of approach and avoidance motivation (for a review see Elliot, 2008). This corresponds with the argument that pleasure—a proactive search for positive experiences—should be distinguished from comfort defined as a state of biological indifference (Scitovsky, 1976; Cabanac, 2010). For this reason the hedonic scale could actually be divided into the two dimensions of seeking relaxation and seeking pleasure (Asano et al., 2014).
The eudaimonic subscale of the HEMA covers three concepts which focus on personal qualities: authenticity (self-knowledge, autonomy, and integrity), excellence (virtue, performing to a high standard), and growth (learning, actualizing one's unique potentials, and maturing as a person). This operationalization is not exhaustive, as other concepts are often emphasized in definitions of eudaimonia (e.g., meaning, engagement). Nevertheless, the advantage of the HEMA scale is that it allows for a simultaneous assessment of both hedonic and eudaimonic orientations (measured together as motives), and therefore provides an opportunity to study the connection between them.
The relationship between factors of stable hedonic and eudaimonic orientations to well-being is hardly ever studied across different samples or national groups. Therefore, we don't know whether a particular figure representing the correlation between the factors is universal or specific for a national sample or a language version. To confirm a stability of connections between well-being constructs multigroup studies are needed. Yet for such designs the issue of measurement invariance (MI) becomes a crucial concern (e.g., Brown, 2006). This means that when a measurement tool is used across groups, its internal structure should follow at least two requirements: (1) the same number of factors should occur in all groups (configural invariance), and (2) the similar pattern of factor loadings should be observed across groups (metric invariance). If a model that imposes both of those requirements fits the data well, structural parameters—such as factor correlations—can be legitimately examined and compared across groups (e.g., Meredith and Teresi, 2006; Raykov et al., 2012). Additionally, when a comparison between latent means is of interest, the similar pattern of item intercepts should be established (scalar invariance).
In sum, the aim of this paper is to provide a systematic investigation of the correlational nature of the HEMA scale in two different nations. A confirmatory and multigroup factor analytic design was chosen for this purpose.
The Application of Bayesian Estimation
With cross-national data from the HEMA scale, the analysis presented in this paper utilizes and compares two different estimation methods: (1) a traditional frequentist approach with maximum likelihood (ML) estimation and (2) a relatively new technique based on Bayesian structural equation models (BSEM) (Muthén and Asparouhov, 2012). This double analyses strategy was chosen in order to compare the results of those two methods and thereby provide an example that will reveal the possible advantages offered by Bayesian estimation. Since computational power nowadays supports the use of the Bayesian approach, it has been widely recommended due to the fundamental advantages of this method. Several introductory discussions of Bayesian estimation and inference exist (e.g., van de Schoot et al., 2013a; Zyphur and Oswald, 2013). The possible advantages of using BSEM can be found in all three steps of the analysis reported here.
First, BSEM allows the replacing of exact zero constraints with approximate zero constraints for different parameters of a model such as cross-loadings or residual covariances (Muthén and Asparouhov, 2012, 2013). This is possible due to the specific assumptions underlying Bayesian estimation. Bayesians treat parameters as variables characterized by a distribution, in contrast to the frequentist approach in which samples have distributions while parameters are fixed in the population (Zyphur and Oswald, 2013). Moreover, in Bayesian analysis a distribution for each of the parameters can be restricted by specifying priors, which are usually based on previous knowledge. For example, in confirmatory factor analyses (CFA) it is often assumed that each of the items will load on one factor only, hence the errant loadings (cross-loadings) are fixed at zero. However, the precise zero constraint has been criticized as unreasonable and unnecessary, because researchers usually want those errant-loadings to be very small (e.g., Golay et al., 2013). In most cases it may be enough to state that cross-loadings do not exceed a particular value, for example 0.3 (Brannick, 1995). Bayesian estimation allows us to place such a constraint by specifying a prior distribution for a cross-loading, in order to have little variance around the mean set to zero (i.e., an informative prior, e.g., van de Schoot et al., 2013b). Thanks to this option, the model fit will not suffer from an unreasonable assumption that does not reflect the true intention of the researcher.
Secondly, the same advantage of an approximate equality, rather than a precise one, can be employed for the MI analyses (Muthén and Asparouhov, 2013; Cieciuch et al., 2014). Traditional MI strategy places strong constraints on the parameters of a scale by forcing them to be identical across groups. Such an approach often leads to the conclusion that a scale is not invariant across groups, with little information about how big the differences are. Previous attempts to deal with this problem by establishing partial MI models remain controversial (e.g., Byrne et al., 1989; Millsap and Kwok, 2004; Schmitt and Kuljanin, 2008). In this study, as in many others, the goal is to show that a scale performs in a very similar way across national groups. Yet, it is not expected that any particular item will behave differently across the groups (this could be solved by a partial MI model). Instead, we assume that all the items in the scale may vary across the nations and the size of these differences is of interest. BSEM allows the estimation of their magnitude by specifying limits for their distribution (which are set up by the informative priors). Thus, we decided to employ an approximate MI approach based on BSEM, and assumed that small deviations (i.e., statistically insignificant) would not jeopardize the comparison between factor covariances.
Thirdly, Bayesian estimation makes the results easier to understand due to its intuitive inference process (van de Schoot et al., 2013a). In the frequentist approach, a confidence interval is provided which shows that over an infinity of samples taken from the population, 95% of these contain the true population value. The interpretation of such an interval is somewhat counterintuitive, as it refers to samples rather than an actual parameter of interest. On the other hand, a Bayesian credibility interval indicates that there is a 95% chance for a parameter to lay within the limits of the interval. Taking this paper as an example, the credibility interval will reflect the most probable range of values for the correlation between the latent factors reflecting hedonic and eudaimonic pursuits of well-being. In other words, Bayesian approach focuses on the magnitude of the parameter for a provided dataset. Such information, in contrast to the traditional confidence intervals, is easier to understand and compare between groups.
In sum, the paper provides a practical application of Bayesian estimation, and aims at investigating some differences between the traditional frequentist approach to CFA with that of a Bayesian approach.
Materials and Methods
Participants
In the Polish sample, 386 adults were surveyed, of whom 79% were female. Their age ranged from 18 to 29 years (M = 21.26, SD = 1.75). The data collection was conducted in two waves: first (n = 197) with the full 9-item version of the scale, and second (n = 189) with the short 8-item version (see the Supplementary Material for the list of items included in both versions). The assessment was based on a structured, anonymous questionnaire investigating a number of lifestyle-related variables (see Kaczmarek et al., 2013). Participation was on a voluntary basis and administration took place during the respondents' free time.
The English sample consisted of 429 North American Anglophone participants. The study involved undergraduates (75% of women) who completed the questionnaire as part of a 1-h screening survey (including measures submitted by a variety of researchers) used as a preliminary step before granting students access to various individual studies. Their age ranged from 18 to 30 years (M = 19.19, SD = 1.92).
Instrument
The HEMA scale is meant to assess motives for activities that can be divided into those that are eudaimonic (e.g., “seeking to develop the best in oneself”) and those that are hedonic (e.g., “seeking pleasure”). It is underlined by Huta and Ryan (2010)—the authors of the scale—that this approach allows the distinguishing of hedonia and eudaimonia as forms of well-being pursuits from well-being products. It also offers the opportunity to study both motives as separate variables. Thus, the HEMA measures eudaimonia and hedonia in parallel terms, operationalizing both as orientations (Huta and Ryan, 2010).
The HEMA is a 9-item instrument comprising a hedonic motivation subscale (5 items) and a eudaimonic motivation subscale (4 items). Responses range from 1 (not at all) to 7 (very much). A back-translation procedure was used to translate the HEMA scale into Polish by two bilingual psychologists (the original English items and their Polish translation are presented in the Supplementary Table 1). During this process, one of the items (“seeking enjoyment”), originally belonging to the hedonic subscale, was identified to have different cultural connotations. In the English language, it reflects striving after pleasant experiences, while in the Polish version, it may have been perceived as reflecting goal achievement, rather than being specific to hedonia or eudaimonia. Such disparity could be expected due to the existence of different well-being definitions across nations (e.g., Wierzbicka, 2004). In this situation a partial MI that leaves out the problematic item could have been employed. However, this would undermine the interpretation of estimated factor correlations (the item reflected the hedonic construct in the English version only). Therefore, in this article we tested a possibility to use the 8-item version of the scale in both language groups.
Analysis
The analysis was conducted in three stages: (1) the dimensional structure of the scale was established through CFA separately for the two national samples, (2) the MI was tested between the countries, and finally (3) the differences between the latent factors' correlations were tested. The research question focuses on the construct validity of the scale, therefore a metric invariance (equality of factor loadings) was of main interest (Byrne, 2012). This type of MI indicates whether respondents across groups attribute the same meaning to the latent construct under the study (van de Schoot et al., 2012). In other words, indicators that are central to the construct in one national group, are also central in the other (Selig et al., 2008). It is assumed here that the similar pattern of item intercepts (scalar invariance) is not required for a meaningful comparison of factor covariances, even though this claim can be considered controversial by some researchers (for discussion see Byrne and van de Vijver, 2010). Although of secondary interest, further analyses of the scalar invariance (i.e., invariance of observed variables' intercepts) were also conducted, and differences between intercepts were tested. This allowed for a better illustration of the functioning of the scale in the two national groups.
All the analyses were performed using Mplus 7.11 (Muthén and Muthén, 1998–2012). For the traditional analyses, ML parameter estimates with standard errors and a chi-square test statistic robust to non-normality was used (MLR, see Muthén and Muthén, 1998–2012). When ML estimation was employed, for the evaluation of a model the following fit indices were used with the respective cut-off values as proposed by Schweizer (2010); χ2, normed χ2 (NC, with values below 3 indicating an acceptable fit and below 2 a good fit), CFI and TLI (acceptable model fit when higher than 0.90, good fit when higher than 0.95), RMSEA (acceptable fit when lower than 0.08, good fit when lower than 0.05) and SRMR (expected to stay below 0.10). Chi-square difference test (using the Satorra-Bentler scaled chi-square), AIC and BIC values were employed to compare models. In the Bayesian analyses, two indicators of a model fit were interpreted: (1) the posterior predictive p-value (PPP, good fit when equal to or higher than 0.05), and (2) the 95% confidence interval of the replicated chi-square value (which was expected to include zero; for details please refer to Muthén and Asparouhov, 2012). We additionally used the deviance information criterion to compare the model (DIC; Spiegelhalter et al., 2002). Model estimation was performed with maximum 500,000 and minimum 20,000 iterations using the Markov chain Monte Carlo (MCMC) algorithm (Muthén and Asparouhov, 2012). MCMC convergence criterion using potential scale reduction (PSR) was set to 0.01 (Gelman and Rubin, 1992). The alignment method for the approximate MI was not employed since it is not yet available for models with cross-loadings (Muthén and Asparouhov, 2014). The data and all Mplus output files are available in the Supplementary Materials.
Results
Factor Structure
In the first step of the analysis a latent structure of the scale had to be established. Based on the theoretical assumptions underlying the HEMA scale, a model separating the hedonic and the eudaimonic factor was expected. Previous exploratory analyses revealed the existence of such two-factor structure (Huta and Ryan, 2010; Anić, 2014). However, a recent confirmatory analysis of the Japanese version of the HEMA scale revealed that a three-factor structure is a better representation of the scale's structure (Asano et al., 2014). Therefore, our goals were to (1) determine the factor structure of the scale, and (2) validate the performance of the short 8-item instrument. In order to do so, each national sample was divided into two groups. In the Polish sample the groups were formed according to the waves of the data collection (in the first wave the 9-item scale was administered, in the second wave the 8-item instrument was used). In the English sample participants were divided at random into two groups, and for the second group the “seeking enjoyment” item was removed from the analyses. Then, the one, two and three-factor solutions were tested in four samples. The analysis was begun with the traditional frequentist approach, followed by the Bayesian estimation.
The results acknowledged that the three-factor model was a better solution (see Table 1, syntaxes 1–7 included in the Supplementary Materials). In both national groups, and for both the short and full versions of the scale, splitting the hedonic factor into two components would notably improve the fit. Due to both the theoretical and empirical plausibility of such a distinction, we decided to continue the analyses with the three-factor structure. The proposed three-factor model categorized the hedonic items into a comfort (“seeking to take it easy”; “seeking relaxation”) and a pleasure group (“seeking fun”; “seeking pleasure”; “seeking enjoyment” in the full version of the scale). The confirmatory procedure verified this model by revealing its acceptable fit in both the English and Polish samples (Table 1). In this traditional approach to the CFA, no cross-loadings between items were allowed.
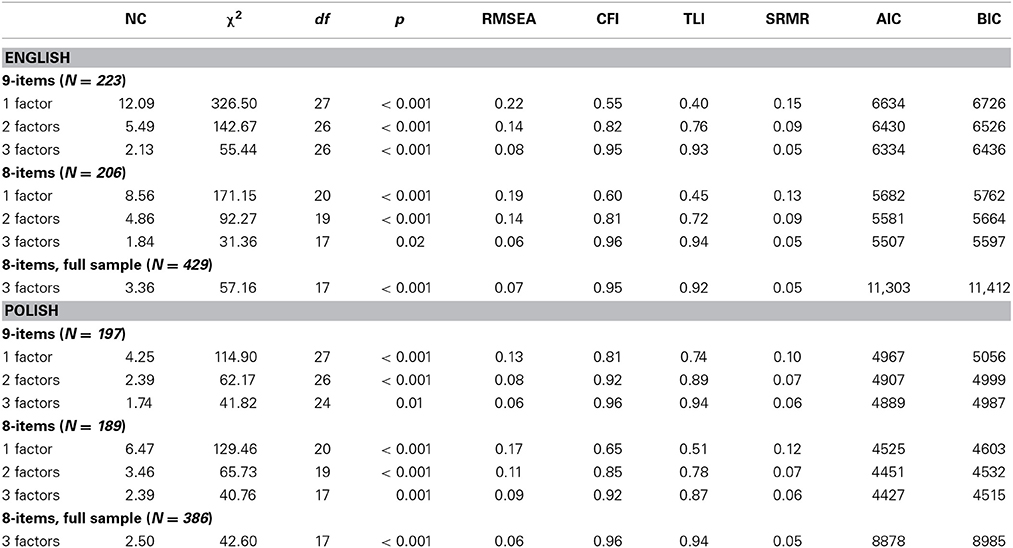
Table 1. The confirmatory factor analyses using maximum likelihood estimation with robust standard errors (ML).
In terms of the short vs. the full version of the scale, the results were somewhat inconclusive. In the English sample the short version (with one item excluded from the analysis) fitted the data slightly better. In the Polish sample, however, the fit was worse when the 8-item version of the scale was administered. To check whether these differences represented the specific variability of a group, rather than a general tendency, we have retested the chosen three-factor model on the full English and Polish samples (using the short version of the scale). This resulted with acceptable fit in both national samples leading to a conclusion that the 8-item instrument produces similar factor structure to the one detected for the full version of the scale.
Bayesian CFA
The factor structure of the HEMA scale was then re-tested using Bayesian estimation (see Table 2 for results, and syntaxes 8–11). First, the noninformative prior distribution was specified using the default prior settings available in Mplus (Muthén and Muthén, 1998–2012). Therefore, no previous knowledge was imposed, meaning that every value of a parameter was equally likely to occur (van de Schoot et al., 2013a). In this case, cross-loadings were fixed to zero, just as in the ML estimated models. With this specification, the two-factor and three-factor models were tested. The one-factor model was omitted for clarity, and due to its very poor fit as revealed in the previous analysis.
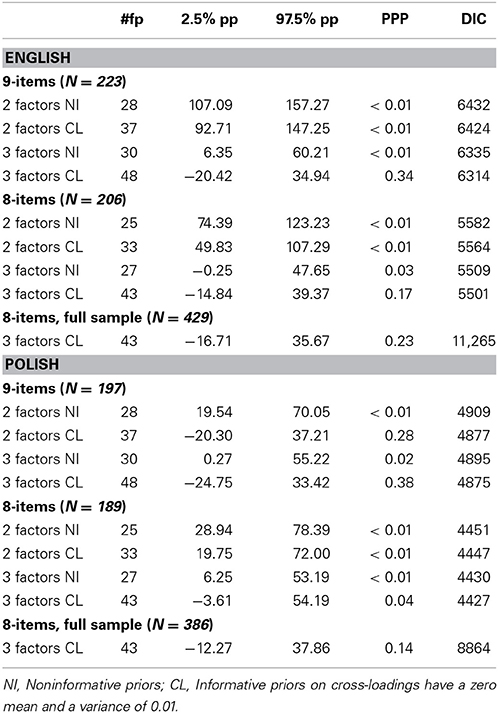
Table 2. The confirmatory factor analyses using Bayesian estimation.
In almost all situations neither the two- nor three-factor model resulted in a satisfactory fit (i.e., the PPP was significant, and the 95% CI of the replicated chi-square values did not include zero). The only exception was the 8-item scale in the English group, where the three-factor model resulted in close to acceptable fit (i.e., the PPP was significant, but the 95% CI included zero). We then changed the requirements of the model so that cross-loadings would be approximately zero rather than exactly zero (syntaxes 12–16). Using small-variance priors (prior mean = 0; prior variance = 0.01) all cross-loadings were restricted to having a value ranging from −0.2 to 0.2 (for more choices please refer to Muthén and Asparouhov, 2012, p. 316). The goal of this strategy was to allow for cross-loadings, yet at the same time keep them small and statistically insignificant. This resulted in an improvement of the three-factor model fit, yet did not help in the case of the two-factor model (see Table 2). Thus, it was again concluded that the three-factor model fit the data better and the analyses were continued employing this structure.
Thanks to the use of weakly informative priors for cross-loadings the results of the Bayesian CFA provided some interesting insights into the performance of the short and full versions of the scale. In the English sample both the 9- and 8-item versions resulted with a good fit when cross-loadings were introduced in the three-factor solution (PPP was accordingly 0.34 and 0.17). In the Polish sample the short version of the scale responded with improvement into an almost acceptable model fit (PPP = 0.04; 95% CI included zero). However, when cross-loadings were allowed in the full version the model yielded a satisfactory fit also for the two-factor solution (PPP = 0.28). In both two- and three-factor models cross-loadings for the problematic “seeking enjoyment” item were large enough to become significant (see the Supplementary Table 3 for details). This suggested that in the Polish sample the 8-item version of the scale represents the measured constructs in a more clear way. Finally, the analyses conducted on the full English and Polish samples confirmed the fit of the three-factor model with small cross-loadings.
Measurement Invariance
In the second step of the analysis, a series of multi-group CFA were executed in order to test the MI between the Polish and the English versions of the HEMA scale (syntaxes 17–21). Stepwise procedures were employed, where the analysis begins with the least restricted solution and subsequent models with increasingly restrictive constraints are evaluated (Brown, 2006). Comparisons were performed with a corrected chi-square differences test due to the fact that the analyses were based on a robust maximum likelihood method (MLR; Muthén and Muthén, 1998–2012). In order to identify the model the factor variance was fixed to 1 in one group only, and in the other group the equality constraints were placed on the factor loadings while a factor variance was estimated (Yoon and Millsap, 2007). This method minimizes problems caused by commonly used solutions such as constraining the first factor loading to one (Bauer and Hussong, 2009).
With a configural invariance model (syntax 17) established across the two language versions of the HEMA, the next step was to test for metric invariance (see Table 3). A model constraining factor loadings to being equivalent across the language versions (syntax 18) fitted slightly worse than a configural model. Then a partial metric invariance model (syntax 19) was tested, where one factor loading was allowed to vary across groups (“seeking relaxation”). This specification represented the data well. Accordingly, the construct validity of the scale was confirmed across the national samples enabling a meaningful comparison between the factor covariances. Finally, a scalar invariance was tested (syntax 20). The results were not supportive for the scalar invariance indicating that the intercepts were not equal across the samples. Partial scalar model (syntax 21) could have been established only when half of the intercepts were allowed to vary. We have therefore retreated to the partial metric MI model and this one was applied for the final step of the analyses (see Table 5 for standardized results of the partial metric MI model).
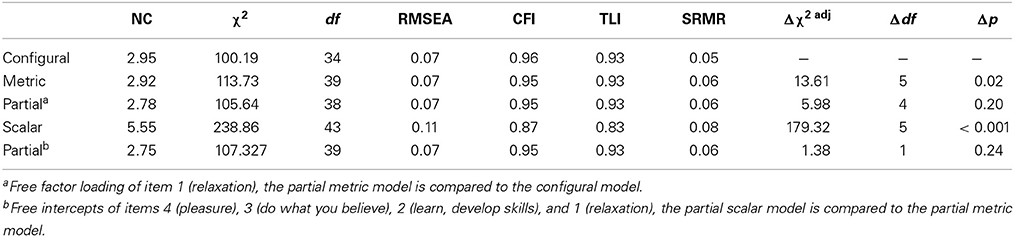
Table 3. The measurement invariance analyses using ML.
Approximate MI
Then, the MI across groups was re-tested with the Bayesian estimator (see Table 4). We have continued with the model where weakly informative priors on the cross-loadings were used (i.e. small cross-loadings were allowed, see syntaxes 22–26). The configural model (syntax 22) fitted the data well as expected, given the previously confirmed stability of the three-factor model across the national groups. The full metric model (syntax 23) resulted in an acceptable fit, yet the PPP-value was still quite low (0.057). We have proceeded to establish and approximate metric invariance model (syntax 24), resulting in a slightly better fit (higher PPP-value, 0.078), but the difference in DIC was small (equals 2.1). Therefore, we have decided to employ the metric invariance model, not the approximate one, in the further analysis. The standardized factor loadings and intercepts estimated for this model are presented in Table 5. Lastly, the scalar invariance (syntax 25) was tested, but the model did not represent the data well. Therefore, the strict equality assumption between the intercepts was released, and the approximate scalar MI (syntax 26) was implemented (Muthén and Asparouhov, 2013). Allowing all the intercepts to be at least approximately equal (prior mean = 0; prior variance = 0.01) did not help to improve the fit. In fact neither of the methods used (the partial invariance with ML or the approximate invariance with Bayes) supported scalar invariance. This suggests that the problem of non-invariant intercepts is not limited to a particular item(s), and that all the items vary to an extent that cannot be disregarded (only for the item 5 credibility intervals for the intercepts overlapped) The intercepts in the Polish sample were higher than the ones of the English sample (see Table 5). Thus, the comparison of factor means would not be possible. Yet, in order to compare factor covariances the metric model could be used (Byrne and van de Vijver, 2010).
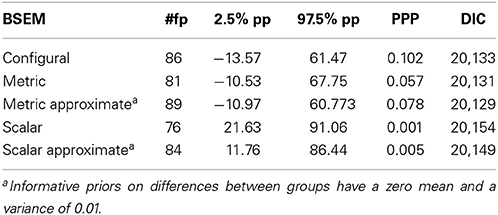
Table 4. The measurement invariance analyses using Bayesian estimation.
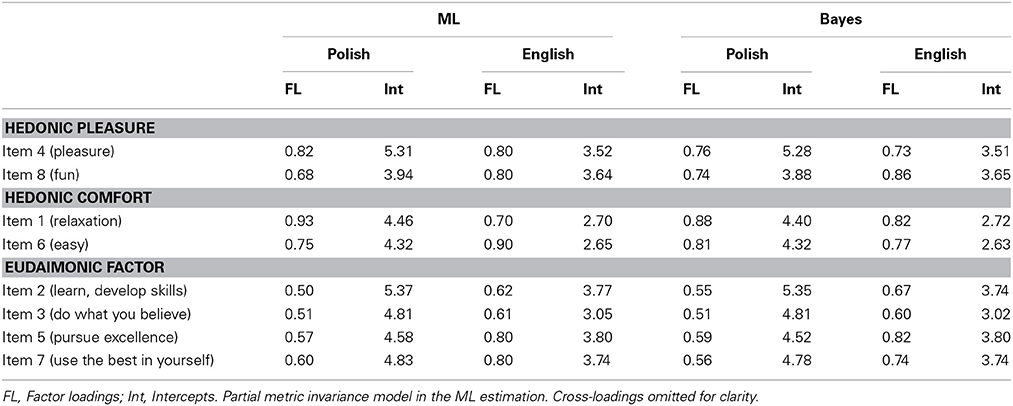
Table 5. Standardized factor loadings and intercepts for the metric invariance model.
Correlation Between Hedonia and Eudaimonia
The third and final step of the analysis was to quantify and compare the covariances between the latent factors representing hedonic and eudaimonic pursuits of well-being (syntaxes 27–28). To do so, the MODEL CONSTRAINT command was included in the Mplus code (Muthén and Muthén, 1998–2012). This function allowed us to create a set of new parameters representing the differences between the estimated factor covariances across and within the national groups. Mplus provided us with confidence intervals (using the Delta method standard errors and z-test for ML estimation) or credibility intervals (for Bayesian estimation) for the newly defined parameters. As a result, the differences between the factor covariances were tested for statistical significance. We continued to use partial metric invariance model for MI estimation (syntax 27), and metric invariance model with small cross-loadings specified with weakly informative priors for Bayes (syntax 28).
Table 6 presents the factor correlations (standardized covariances) for the two national groups and the two estimation methods, marked for the significant differences between and within groups. Both the traditional and Bayesian procedures revealed similar latent factor correlation patterns within each of the national groups. In the Polish sample the connection between the two hedonic factors was found to be the strongest (significantly stronger than each of the other two correlations), while the correlations between the hedonic factors and the eudaimonic factor were rather weak. In the English sample the links connecting the hedonic factors, and the hedonic pleasure with the eudaimonic factor were moderate. The correlation between the hedonic comfort and the eudaimonic factor was weak and mostly insignificant (only in the Polish group with ML p = 0.02). It was weaker than each of the other two correlations in all cases except from ML estimation in the English group. Between group differences were found in the connection between hedonic comfort with the eudaimonic factor (with ML) or in the hedonic pleasure with eudaimonic factor (with Bayes). Even though the correlation between the hedonic factors was stronger in the Polish group than the English group, neither ML nor Bayes found this difference significant.
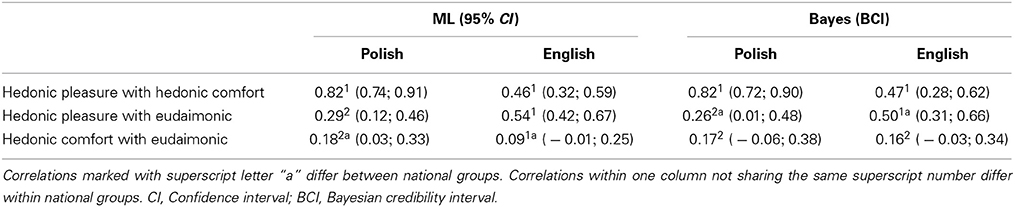
Table 6. Correlations between latent factors of hedonia and eudaimonia as estimated with ML and Bayes.
Discussion
The aim of this paper was to describe the structure of the HEMA scale and its performance across two different nations. Stepwise analyses were conducted to establish a factor structure of the scale, revealing three correlated factors: two hedonic and one eudaimonic. The eudaimonic factor reflected the pursuit for excellence. The hedonic factors include items reflecting the pursuit of affective states and were divided into a comfort factor and a pleasure factor.
Among the two hedonic factors, the one reflecting pleasure was closer to the eudaimonic factor than was the hedonic comfort factor. This pattern was relatively stable across the national groups. Thus, seeking excellence seems to feel more like pleasure and fun, than like being relaxed and at ease. In fact, some researchers include the enjoyment from activities representing the pursuit of excellence into their definition of eudaimonia (Waterman et al., 2010). At the same time, both the hedonic factors were strongly correlated, indicating that these items roughly occupy the same area of the affective landscape. Splitting hedonia into the two components shed more light on unclear previous results regarding its connection to eudaimonia (Huta and Waterman, 2013). This division may be valid for further research, yet building a dedicated scale to assess hedonic comfort and pleasure is recommended.
This paper is a first attempt at a systematic examination of multigroup stability of the HEMA scale components. Future work should address several issues not answered in this study. First of all, the conclusions of this paper are based on the models that fit acceptably well, yet are not perfect. More national samples should be taken into consideration to further justify the cross-national stability of a well-being assessment, including both hedonic and eudaimonic constructs. Secondly, representative samples are preferred in order to avoid possible sampling errors. Especially the lack of gender balance is an important limitation of this study. Thirdly, the lack of scalar invariance revealed in this study should be examined more closely. The differences between intercepts are not surprising when comparing across nations, as they might occur as a result of different norms of socially-acceptable levels for expressions of hedonia and eudaimonia (e.g., Diener, 2000). Detailed analyses of this phenomenon were not within the scope of this paper, but remain an interesting issue. Finally, the division of hedonic comfort and pleasure needs further attention, and a more detailed assessment of those hedonic components could be considered.
In summary, this paper revealed a similar pattern of correlations between the trait-level pursuits of hedonic and eudaimonic elements across the two national samples. Further cross-national studies are needed to confirm the existence of this pattern, as well as to explain the differences in the items' intercepts across the groups (the lack of scalar invariance). It is hoped that using the HEMA scale in various language versions and across different national groups has the potential to substantially advance the knowledge on hedonic and eudaimonic components of well-being.
The Performance of the Bayesian Estimation
Bayesian estimation was employed in this study due to its fundamental advantages over the traditional frequentist approach (e.g., Muthén and Asparouhov, 2012; van de Schoot et al., 2013a; Zyphur and Oswald, 2013). It was expected that specifying weakly informative priors would help us to better assess the differences between groups, and the intuitive inference process would provide a simpler interpretation of the factor correlations. Several points regarding the fulfillment of those expectations are discussed here.
Firstly, Bayesian estimation reported a misfit of the model when strong assumptions of exact zero were imposed. This is interesting given that the estimation based on the ML method reported an acceptable fit. The reason for this lies within the definition of a model fit used in Bayesian estimation. The posterior predictive checking assesses how well a model is specified from the viewpoint of predictive accuracy (how well it predicts the data). Thus, any discrepancies are detected between the values generated by a model and the observed data, suggesting that the model could be improved (van de Schoot et al., 2013a).
Consequently, in Bayesian estimation replacing the exact zero assumption with an approximate zero improved the fit significantly, leading to the acceptance of the model with small cross-loadings. In fact Bayes arrived at a similar outcome to that of the traditional estimation, yet using a longer route. This detour, however, was much more informative. While in the ML approach the CFA is not able to provide information about the reason of model misfit, Bayesian modeling gives more hints about it. Including small priors for cross-loadings (or residual covariances which is also possible, see Muthén and Asparouhov, 2012) helps in verifying why the model does not represent the data well. Yet, it should be underlined that when large discrepancies were observed, such as when scalar invariance was imposed, changing the exact zero assumption into the approximate one (in this case by specifying an approximate MI) did not help in achieving a satisfactory fit. Clearly, according to both ML and Bayes, the differences between the items' intercepts were too big for scalar invariance to be established. This shows that the Bayesian approach can be more informative than ML only when the models are already fairly well specified. Indeed, this method is advised for analyses with a small number of groups, continuous variables and close-to-invariant models (van de Schoot et al., 2013b).
Finally, taking into account the small cross-loadings might have been the reason why the Bayesian estimation did not discover any differences between factor loadings (allowing for full metric invariance). Interestingly, for both methods the estimated factor correlations were almost identical, even though ML used only the partial metric MI model. In this case including small cross-loadings did not influence the structural parameters of the model. In fact, it helped in establishing the metric invariance. This might suggest that non-invariant cross-loadings (not included in the traditionally estimated metric MI model) could actually be the reason for its misfit. Such possibility opens up an interesting discussion, but simulation studies are needed to better understand the role of small and sample specific cross-loadings in multigroup MI analyses.
To summarize, Bayesian estimation can be a recommended approach to MI analyses when (1) small differences between groups are expected and the size of those differences should be estimated, and (2) when structural parameters are of interest (e.g., factor covariances) and a researcher would like to be provided with easy to interpret credibility intervals for such parameters.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgment
This research was supported in part by a grant from the Research Council of Norway (Yggdrasil programme 2012, project number 210845).
Supplementary Material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fpsyg.2014.00984/abstract
References
Anić, P. (2014). Hedonic and eudaimonic motives for favourite leisure activities. Primenjena Psihologija 7, 5–21.
Asano, R., Igarashi, T., and Tsukamoto, S. (2014). Hedonic and eudaimonic motives for activities (HEMA) in Japan: the pursuit of well-being. Jpn. J. Psychol. 85, 69–79. doi: 10.4992/jjpsy.85.69
Bauer, D. J., and Hussong, A. M. (2009). Psychometric approaches for developing commensurate measures across independent studies: traditional and new models. Psychol. Methods 14, 101–125. doi: 10.1037/a0015583
Bauer, J., Park, S., Montoya, R. M., and Wayment, H. (2014). Growth motivation toward two paths of eudaimonic self-development. J. Happiness Stud. doi: 10.1007/s10902-014-9504-9. [Epub ahead of print].
Berridge, K., and Kringelbach, M. (2011). Building a neuroscience of pleasure and well-being. Psychol. Well Being 1:3. doi: 10.1186/2211-1522-1-3
Brannick, M. T. (1995). Critical comments on applying covariance structure modeling. J. Organ. Behav. 16, 201–213. doi: 10.1002/job.4030160303
Brown, T. A. (2006). Confirmatory Factor Analysis for Applied Research. New York, NY: The Guilford Press.
Byrne, B. (2012). Structural Equation Modeling with Mplus: Basic Concepts, Applications, and Programming. New York, NY: Taylor & Francis Group.
Byrne, B., Shavelson, R., and Muthén, B. (1989). Testing for the equivalence of factor covariance and mean structures: the issue of partial measurement invariance. Psychol. Bull. 105, 456–466. doi: 10.1037/0033-2909.105.3.456
Byrne, B., and van de Vijver, F. J. R. (2010). Testing for measurement and structural equivalence in large-scale cross-cultural studies: addressing the issue of nonequivalence. Int. J. Test. 10, 107–132. doi: 10.1080/15305051003637306
Cabanac, M. (2010). The Fifth Influence: Or, The Dialectics of Pleasure. Bloomington, IN: iUniverse.
Cieciuch, J., Davidov, E., Schmidt, P., Algesheimer, R., and Schwartz, S. H. (2014). Comparing results of an exact versus an approximate (Bayesian) measurement invariance test: a cross-country illustration with a new scale to measure 19 human values. Front. Psychol. 5:982. doi: 10.3389/fpsyg.2014.00982
Deci, E. L., and Ryan, R. M. (2008). Hedonia, eudaimonia, and well-being: an introduction. J. Happiness Stud. 9, 1–11. doi: 10.1007/s10902-006-9018-1
Diener, E. (1984). Subjective well-being. Psychol. Bull. 95, 542–575. doi: 10.1037/0033-2909.95.3.542
Diener, E. (2000). Subjective well-being: the science of happiness and a proposal for a national index. Am. Psychol. 55, 34–43. doi: 10.1037/0003-066X.55.1.34
Diener, E., Scollon, C. N., and Lucas, R. E. (2009). “The evolving concept of subjective well-being: the multifaceted nature of happiness,” in Assessing Well-being: The Collected Works of Ed Diener, ed E. Diener (Dordrecht, NL: Springer), 67–100.
Elliot, A. J. (2008). Handbook of Approach and Avoidance Motivation. New York, NY: Psychology Press.
Feldman, F. (2004). Pleasure and the Good Life: Concerning the Nature, Varieties, and Plausibility of Hedonism. Oxford, UK: Clarendon Press.
Gelman, A., and Rubin, D. (1992). Inference from iterative simulation using multiple sequences. Stat. Sci. 7, 457–472. doi: 10.1214/ss/1177011136
Golay, P., Reverte, I., Rossier, J., Favez, N., and Lecerf, T. (2013). Further insights on the French WISC-IV factor structure through Bayesian structural equation modeling. Psychol. Assess. 25, 496–508. doi: 10.1037/a0030676
Henderson, L. W., Knight, T., and Richardson, B. (2013). An exploration of the well-being benefits of hedonic and eudaimonic behaviour. J. Posit. Psychol. 8, 322–336. doi: 10.1080/17439760.2013.803596
Huta, V. (2013). “Eudaimonia,” in The Oxford Handbook of Happiness, eds S. David, I. Boniwell, and A. C. Ayers (Oxford, UK: Oxford University Press), 201–213.
Huta, V., and Ryan, R. M. (2010). Pursuing pleasure or virtue: the differential and overlapping well-being benefits of hedonic and eudaimonic motives. J. Happiness Stud. 11, 735–762. doi: 10.1007/s10902-009-9171-4
Huta, V., and Waterman, A. (2013). Eudaimonia and its distinction from hedonia: developing a classification and terminology for understanding conceptual and operational definitions. J. Happiness Stud. doi: 10.1007/s10902-013-9485-0. [Epub ahead of print].
Kaczmarek, L. D., Kashdan, T. B., Kleiman, E. M., Baczkowski, B., Enko, J., Siebers, A., et al. (2013). Who self-initiates gratitude interventions in daily life? An examination of intentions, curiosity, depressive symptoms, and life satisfaction. Pers. Individ. Diff. 55, 805–810. doi: 10.1016/j.paid.2013.06.013
Kahneman, D. (1999). “Objective happiness,” in Well-being: The Foundations of Hedonic Psychology, eds D. Kahneman, E. Diener, and N. Schwarz (New York, NY: Russell Sage Foundation), 3–25.
Kahneman, D. (2000). “Experienced utility and objective happiness: a moment-based approach,” in Choices, Values and Frames, eds D. Kahneman and A. Tversky (New York, NY: Cambridge University Press and the Russell Sage Foundation), 673–692.
Keyes, C., Shmotkin, D., and Ryff, C. (2002). Optimizing well-being: the empirical encounter of two traditions. J. Pers. Soc. Psychol. 82, 1007–1022. doi: 10.1037//0022-3514.82.6.1007
Keyes, C. L. M., and Annas, J. (2009). Feeling good and functioning well: distinctive concepts in ancient philosophy and contemporary science. J. Posit. Psychol. 4, 197–201. doi: 10.1080/17439760902844228
Kopperud, K. H., and Vittersø, J. (2008). Distinctions between hedonic and eudaimonic well-being: results from a day reconstruction study among Norwegian jobholders. J. Posit. Psychol. 3, 174–181. doi: 10.1080/17439760801999420
Meredith, W., and Teresi, J. A. (2006). An essay on measurement and factorial invariance. Med. Care 44(11 Suppl. 3), S69–S77. doi: 10.1097/01.mlr.0000245438.73837.89
Millsap, R. E., and Kwok, O. M. (2004). Evaluating the impact of partial factorial invariance on selection in two populations. Psychol. Methods 9, 93–115. doi: 10.1037/1082-989X.9.1.93
Muthén, B., and Asparouhov, T. (2012). Bayesian structural equation modeling: a more flexible representation of substantive theory. Psychol. Methods 17, 313–335. doi: 10.1037/a0026802
Muthén, B., and Asparouhov, T. (2013). BSEM Measurement Invariance Analysis. Mplus Web Notes: No. 17. Available online at: www.statmodel.com
Muthén, B., and Asparouhov, T. (2014). IRT studies of many groups: the alignment method. Front. Psychol. 5:978. doi: 10.3389/fpsyg.2014.00978
Muthén, L. K., and Muthén, B. (1998–2012). Mplus User's Guide. 7th Edn. Los Angeles, CA: Muthén and Muthén.
Oishi, S., Graham, J., Kesebir, S., and Galinha, I. C. (2013). Concepts of happiness across time and cultures. Pers. Soc. Psychol. Bull. 39, 559–577. doi: 10.1177/0146167213480042
Proctor, C., Tweed, R., and Morris, D. (2014). The naturally emerging structure of well-being among young adults: “Big Two” or other framework? J. Happiness Stud. doi: 10.1007/s10902-014-9507-6. [Epub ahead of print].
Raykov, T., Marcoulides, G. A., and Li, C.-H. (2012). Measurement invariance for latent constructs in multiple populations: a critical view and refocus. Educ. Psychol. Meas. 72, 954–974. doi: 10.1177/0013164412441607
Ryan, R. M., and Deci, E. D. (2001). On happiness and human potentials: a review of research on hedonic and eudaimonic well-being. Annu. Rev. Psychol. 52, 141–166. doi: 10.1146/annurev.psych.52.1.141
Ryan, R. M., Huta, V., and Deci, E. L. (2013). “Living well: a self-determination theory perspective on eudaimonia,” in The Exploration of Happiness: Present and Future Perspectives, ed A. Delle Fave (New York, NY: Springer Science), 117–139.
Ryff, C. D. (1989). Happiness is everything, or is it? Explorations on the meaning of psychological well-being. J. Pers. Soc. Psychol. 57, 1069–1081. doi: 10.1037/0022-3514.57.6.1069
Schmitt, N., and Kuljanin, G. (2008). Measurement invariance: review of practice and implications. Hum. Resource Manag. Rev. 18, 210–222. doi: 10.1016/j.hrmr.2008.03.003
Schweizer, K. (2010). Some guidelines concerning the modeling of traits and abilities in test construction. Eur. J. Psychol. Assess. 26, 1–2. doi: 10.1027/1015-5759/a000001
Scitovsky, T. (1976). The Joyless Economy: The Psychology of Human Satisfaction. New York, NY: Oxford University Press.
Selig, J. P., Card, N. A., and Little, T. D. (2008). “Latent variable structural equation modeling in cross-cultural research: multigroup and multilevel approaches,” in Multilevel Analysis of Individuals and Cultures, eds. J. R. van de Vijver, D. A. van Hemert, Y. H. Poortinga (New York, NY: Taylor & Francis), 93–119.
Spiegelhalter, D. J., Best, N. G., Carlin, B. P., and van der Linde, A. (2002). Bayesian measures of model complexity and fit. J. R. Stat. Soc. Ser. B 64, 583–639. doi: 10.1111/1467-9868.00353
Tatarkiewicz, W. (1976). Analysis of Happiness. The Hague: M. Nijhoff and Polish Scientific Publishers.
Uchida, Y., Takahashi, Y., and Kawahara, K. (2014). Changes in hedonic and eudaimonic well-being after a severe nationwide disaster: the case of the great east Japan earthquake. J. Happiness Stud. 15, 207–221. doi: 10.1007/s10902-013-9463-6
van de Schoot, R., Kaplan, D., Denissen, J., Asendorpf, J. B., Neyer, F. J., and van Aken, M. A. G. (2013a). A gentle introduction to Bayesian analysis: applications to developmental research. Child Dev. 85, 842–860. doi: 10.1111/cdev.12169
van de Schoot, R., Kluytmans, A., Tummers, L., Lugtig, P., Hox, J., and Muthén, B. (2013b). Facing off with Scylla and Charybdis: a comparison of scalar, partial, and the novel possibility of approximate measurement invariance. Front. Psychol. 4:770. doi: 10.3389/fpsyg.2013.00770
van de Schoot, R., Lugtig, P., and Hox, J. (2012). A checklist for testing measurement invariance. Eur. J. Dev. Psychol. 9, 486–492. doi: 10.1080/17405629.2012.686740
Vittersø, J. (2013). “Functional well-being: happiness as feelings, evaluations and functioning,” in The Oxford Handbook of Happiness, eds S. David, I. Boniwell, and A. C. Ayers (Oxford, UK: Oxford University Press), 227–244
Waterman, A. S. (1993). Two conceptions of happiness: contrasts of personal expressiveness (eudaimonia) and hedonic enjoyment. J. Pers. Soc. Psychol. 64, 678–691. doi: 10.1037/0022-3514.64.4.678
Waterman, A. S., Schwartz, S. J., Zamboanga, B. L., Ravert, R. D., Williams, M. K., Agocha, V. B., et al. (2010). The Questionnaire for eudaimonic Well-Being: psychometric properties, demographic comparisons, and evidence of validity. J. Posit. Psychol. 5, 41–61. doi: 10.1080/17439760903435208
Wierzbicka, A. (2004). “Happiness” in cross-linguistic and cross-cultural perspective. Daedalus 34, 34–43. doi: 10.1162/001152604323049370
Yoon, M., and Millsap, R. E. (2007). Detecting violations of factorial invariance using data- based specification searches: a Monte Carlo study. Struct. Equ. Model. 14, 435–463. doi: 10.1080/10705510701301677
Keywords: hedonia, eudaimonia, well-being, Bayesian structural equation modeling, measurement invariance
Citation: Bujacz A, Vittersø J, Huta V and Kaczmarek LD (2014) Measuring hedonia and eudaimonia as motives for activities: cross-national investigation through traditional and Bayesian structural equation modeling. Front. Psychol. 5:984. doi: 10.3389/fpsyg.2014.00984
Received: 30 April 2014; Accepted: 19 August 2014;
Published online: 08 September 2014.
Edited by:
Rens Van De Schoot, Utrecht University, NetherlandsReviewed by:
Jan Cieciuch, Cardinal Stefan Wyszynski University in Warsaw, PolandSebastiaan Rothmann, North-West University, South Africa
Copyright © 2014 Bujacz, Vittersø, Huta and Kaczmarek. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Aleksandra Bujacz, Faculty of Social Sciences, Institute of Psychology, Adam Mickiewicz University, ul. Szamarzewskiego 89AB, Poznań 60-568, Poland e-mail: aleksandra.bujacz@amu.edu.pl