 Séverine Casalis
Séverine Casalis Pauline Quémart
Pauline Quémart Lynne G. Duncan
Lynne G. Duncan- 1SCALab, Université de Lille and Centre National de la Recherche Scientifique, Villeneuve d'Ascq, France
- 2University of Poitiers and Centre National de la Recherche Scientifique, Poitiers, France
- 3School of Psychology, University of Dundee, Dundee, UK
Developing readers have been shown to rely on morphemes in visual word recognition across several naming, lexical decision and priming experiments. However, the impact of morphology in reading is not consistent across studies with differing results emerging not only between but also within writing systems. Here, we report a cross-language experiment involving the English and French languages, which aims to compare directly the impact of morphology in word recognition in the two languages. Monolingual French-speaking and English-speaking children matched for grade level (Part 1) and for age (Part 2) participated in the study. Two lexical decision tasks (one in French, one in English) featured words and pseudowords with exactly the same structure in each language. The presence of a root (R+) and a suffix ending (S+) was manipulated orthogonally, leading to four possible combinations in words (R+S+: e.g., postal; R+S−: e.g., turnip; R−S+: e.g., rascal; and R-S-: e.g., bishop) and in pseudowords (R+S+: e.g., pondal; R+S−: e.g., curlip; R−S+: e.g., vosnal; and R−S−: e.g., hethop). Results indicate that the presence of morphemes facilitates children's recognition of words and impedes their ability to reject pseudowords in both languages. Nevertheless, effects extend across accuracy and latencies in French but are restricted to accuracy in English, suggesting a higher degree of morphological processing efficiency in French. We argue that the inconsistencies found between languages emphasize the need for developmental models of word recognition to integrate a morpheme level whose elaboration is tuned by the productivity and transparency of the derivational system.
Introduction
In a recent paper, Frost (2012) has put forward a case for a universal model of reading. As it is not certain that, as a cultural product, written language should be subject to a universal form of processing (Coltheart and Crain, 2012), it seems important to consider whether variations in language properties constrain the use of particular language units. Deacon (2012) rightly pointed out the relevance of the developmental approach to deal with this issue since a key aspect of developmental studies is that they tell us which skills drive reading acquisition and which are the product of reading. In other words, developmental cross language studies should help to disentangle which aspects of reading acquisition are universal and which depend on language properties. Therefore, the aim of the present paper is to compare how English-speaking and French-speaking developing readers make use of one of the fundamental units of reading development, namely, morphemes.
Research conducted over three decades has documented the importance of phonological coding in the earliest phases of learning to read an alphabetic script (Goswami and Bryant, 1990; Muter et al., 2004; Melby-Lervåg et al., 2012). The key unit relevant for phonological coding in alphabetic scripts is the grapheme and its oral counterpart, the phoneme. However, spelling-to-sound consistency varies across orthographies (Frost et al., 1987) and alphabetic orthographies are distinguished along a continuum from transparent to opaque. In some orthographies, grapheme-phoneme correspondences (hereafter, GPC) are transparent, with individual graphemes always pronounced in the same way (e.g., Finnish, Italian). In other orthographies, GPC are highly opaque, meaning that the same grapheme can be pronounced in different ways (e.g., English). The French orthography is opaque in terms of spelling, indeed similar to English in this respect, but more transparent when it comes to reading.
Orthographic transparency has an impact on the ease with which children learn to read across countries, and reading achievement at the end of the first year clearly depends on the consistency of the GPC (Seymour et al., 2003; Duncan et al., 2013). Learning to read is particularly difficult for English-speaking children, who perform at a much lower level than children learning to read in other languages. This delay is observed when reading both familiar words and pseudowords in the initial phases of reading acquisition (Seymour et al., 2003). The Psycholinguistic Grain-Size theory (PGST, Ziegler and Goswami, 2005) has been proposed to account for the effects of such cross-language differences in orthographic depth on reading acquisition (Ziegler et al., 2001; Ziegler and Goswami, 2006). This model suggests that reading development across alphabetic scripts may display some variation in the grain size that children utilize as a function of the availability of units in oral language and the consistency of the links between these units of speech and written orthographic symbols. Even though the PGST focuses on reading aloud, some features may generalize to other aspects of reading such as silent visual word recognition. Equally, other written units such as morphemes, which are not included in this model may come to play a role during literacy acquisition, particularly if these units are available in language and resolve irregularity within the orthography (Ziegler et al., 1997).
The role of morphology in learning to read alphabetic scripts has received increased attention over the past two decades due to a number of factors: (1) most alphabetic writing systems are morphophonemic, in that they represent both phonemic and morphemic units; (2) the majority of new words that children encounter in print are morphologically complex (Nagy and Anderson, 1984), which means that decomposing complex words into smaller constituents during visual word recognition should be particularly relevant when learning to read these words; and (3) developing readers have acquired morphological awareness of spoken language and represent morphological information within their lexicon (Duncan et al., 2009), so given the “intimate relationship between spoken and written language skills” (Hulme and Snowling, 2013, p. 1), word reading is likely to draw upon this ability, particularly in the case of morphologically complex words.
The role of morphology in children's visual word processing has been examined across several languages. In English, children name derived words (e.g., dancer) more accurately than pseudoderived words (e.g., dinner) as early as Grade 2 (Laxon et al., 1992; Carlisle and Stone, 2005). This effect depends on family size, i.e. the number of derived forms (Carlisle and Katz, 2006), and on base word frequency for reading accuracy (Mann and Singson, 2003; Carlisle and Stone, 2005) and reading speed (Deacon et al., 2011). In Italian, third and fifth graders read pseudowords made up of morphemes (e.g., donnista) faster than control pseudowords (e.g., donnosto) (Burani et al., 2002, 2008). In relation to words, Italian children read derived words faster than non-derived words but this effect is limited to low frequency words (Marcolini et al., 2011). Finally, the presence of a base and/or a suffix facilitates visual word recognition in the French language (Quémart et al., 2012). When combined, such units also slow down lexical decisions, give rise to a high false alarm rate (Quémart et al., 2012) and enhance speed and accuracy of pseudoword naming (Colé et al., 2012).
Together, these results strongly support the importance of morphemes for developing readers when reading and/or accessing the lexicon but fail to provide a unified picture of the conditions under which this facilitation occurs, since the effects of morphological structure were not consistent. First, morphological structure significantly influenced both accuracy and latencies in French but was significant for accuracy only in English. Second, morphemes affected reading and lexical access when embedded in words and pseudowords in French, whereas such effects were observed only when morphemes were located within words in English and within pseudowords in Italian, except when words were low in frequency. Third, grade level or age of the participants was not constant across studies and there is reason to believe that the contribution of morphology to word processing is not the same during the first steps of reading acquisition as it is later when decoding mechanisms are well developed and more automatic. Finally, at least two different tasks have been used in previous studies, naming and lexical decision, complicating comparisons. Thus, to shed light on how language affects the use of morphology, cross-language studies using equivalent stimuli, a similar procedure and children at comparable grade or age levels are necessary.
To achieve this goal, the present study compares sensitivity to morphemes during visual word recognition among children speaking French vs. English. The French language is acknowledged as a morphologically rich language, with approximately 75% of French words being morphologically complex (Rey-Debove, 1984), while in English, morphologically complex (derived) forms account for 55% of the lemmas in the CELEX English database. Compounding is more prevalent in English than French, and is not especially productive in French especially in colloquial speech, thus word formation relies far more on derivation than compounding (Clark, 1998; Bauer, 2003). Indeed, French children perform higher in derived form production than English children (Duncan et al., 2009). In the present study, therefore, two effects may act in opposing directions on the outcome: first, the higher prevalence of affixes in French may make French readers more sensitive to this unit; and second, the depth of the English orthography, which makes GPC less reliable, may in turn favor the use of morphemes to increase the efficiency of English reading.
A key aspect of our study was to provide direct comparisons of how language and orthography impose variations in the use of morphemes in word recognition. This would contribute information about linguistic variation that would be useful in extending reading acquisition models to the morphological level. Our participants are typical readers in Grades 3 and 4, in other words, children who have already established early decoding in learning to read and who are expected to show morphemic effects on the basis of previous literature. However, we expect a degree of disparity between the groups due to cross-linguistic differences in relevant factors. The nature of these differences should help in understanding the impact of linguistic variation. We expect that orthographic depth and morphological productivity/transparency will both be influential. More use of morphemes would therefore be expected among the French group on the basis of morphological prevalence/ transparency but the question of whether the utility of morphemes in resolving the greater inconsistency in English will increase morphemic sensitivity in the English group beyond the level expected by the influence of morphological productivity/transparency has still to be resolved. In sum, if the presence of morphemes facilitates children's word recognition and if cognitive processing adapts to properties of environment stimuli, our first hypothesis is that children will rely on morphemic units when they process words and pseudowords, and our second hypothesis is that such morphological effects will be greater in the French language.
Method
Participants
Participants were 40 fourth graders from Scotland in the UK and 32 fourth graders from France. Both groups came from a similar middle income socioeconomic intake. The schools that we chose had middle-class catchment areas, according to national statistics in each country. Informed consent was obtained for each child. Mean age in the UK group was 8.41 years and mean age in the French group was 9.83 years. The difference was significant in terms of age (see Table 1) and not in terms of schooling because UK children start primary school 1 year before French children. A group of 32 French third graders matched for chronological age with the UK children was also recruited (see Table 1).

Table 1. Characteristics of the participants: mean chronological and reading age in years(range in brackets).
Background Measures
To ensure that the two groups of fourth graders were comparable in terms of language abilities, we assessed receptive vocabulary in each group using the British Picture Vocabulary Scale in the United Kingdom (Dunn et al., 1997) and the Echelle de Vocabulaire en Images Peabody in France (Dunn et al., 1993). All children performed within the normal range (percentiles 25–90). Reading skills were assessed using the British Ability Scales Word Reading subtest (Elliott et al., 1983) in the United Kingdom and the Alouette Test (Lefavrais, 1967) in France. All children performed within the normal range (percentiles 25–90). The UK group displayed a reading age greater than their chronological age (see Table 1).
Stimuli
A lexical decision task (LDT) was constructed following the same principles in both languages with close matching of stimuli for frequency, length and suffixes. We used the French Manulex database (Lété et al., 2004) and the English Children's Printed Word Database (CPWD, Masterson et al., 2003). There were four categories of words resulting from the presence or absence of a root and a suffix: (i) R+S+ [root and suffix, e.g., farmer (English), fermier [farmer] (French)]; (ii) R+S− [root but no suffix, e.g., window (English), boutique [shop] (French)]; (iii) R−S+ [no root but an (orthographic) suffix, e.g., murder (English), ménage [household] (French)]; and (iv) R−S− [no root and no suffix, e.g., narrow (English), pédale [pedal] (French)]. The items in condition (i) were the only real derivations. Pseudowords were formed from a similar principle resulting in four matched categories: (i) R+S+ [e.g., gifter (English), rosage (French)]; (ii) R+S− [e.g., puffow (English), lionque (French)]; (iii) R−S+ [e.g., gopter (English), mivage (French)]; and (iv) R−S− [e.g., ferbow (English), beadle (French)].
There were 29 items per condition in each language (see Appendix in Supplementary Material). Stimuli characteristics are presented in Table 2. There were 232 items in total. No fillers were added due to the length of the list. While this could potentially lead to an overestimation of the presence of embedded morphemes, our own assessment of the written language encountered by French children (via the Manulex database) indicates a high proportion of morpheme-like units. Due to differences in language characteristics, the roots in English derived words are nearly always complete, while roots are often truncated in French derived words. For example, the English word farmer contains the whole word root farm, while in the French word fermier [farmer], the final e of the root ferme has been removed. In our stimulus list, the whole lexical form of the root is truncated in 17 English words (10 in the R+S+ condition, 7 in the R+S− condition) and in 33 French words (22 in the R+S+ condition, 11 in the R+S- condition). In addition, in English, the base word is sometimes modified in the derived form by doubling the consonant. This is a peculiarity of English that complicates the orthographic definitions. However, given that this feature is quite common, it was also included as it was considered important to choose examples that were representative of the two languages in order to avoid concerns that our list of stimuli might be artificial in composition.
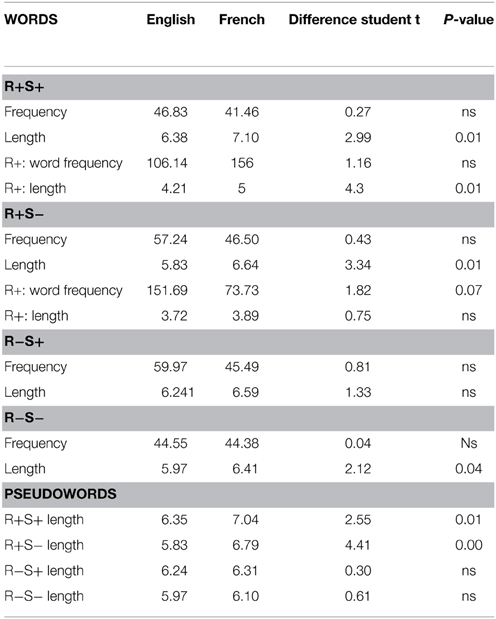
Table 2. Stimuli characteristics in English and French languages.
Procedure
The lexical decision task was administered using Cognitive Workshop software (Seymour, 1994–1999) in the UK and E-prime Software, Version 1.0 (Schneider et al., 2002). Items were presented centrally in lower case Courier New font, size 25. The participants were required to press the “YES” key (using their dominant hand) if the string was a real word, and a “NO” key (using the non-dominant hand) if the string was not a real word. A trial consisted of a fixation cross during 1500 ms and the target remained on the screen until the participant responded or for a maximum of 5000 ms. Reaction times were recorded via the keyboard. There were two counterbalanced sessions with 6 practice items. Items were presented in a randomized order for each participant. All items categories were mixed within one list. A short pause was introduced after every 20 items.
Results Part I: Grade-Level Matched Comparison
Data Analysis
Due to differences in the age of schooling, UK children in Grade 4 were a year younger than their French counterparts. Therefore, we decided to conduct the analyses in two parts. We first compared the performances of the UK group to those of the French children matched for grade, and then we compared the performances of the UK group to those of the French group matched for age.
Analyses of variance were performed on percentages of correct responses (accuracy) and reaction times to correct responses, with root (R+, R−) and suffix (S+, S−) as within-subjects factors and language group (UK, French) as between−subjects factors. Only responses longer than 400 ms and shorter than 5000 ms were considered in the analysis (0.2% of the data were discarded from the analysis). We conducted analyses by participants (F1) and by items (F2) and for the sake of clarity, only significant (or marginally non-significant) effects—at least on F1 analyses—are reported.
Word Condition
Accuracy
Figure 1 presents the mean percentages of correct responses for word stimuli. French children performed more accurately than English children (95.61 and 75.97%, respectively), F1(1, 71) = 49.41, p < 0.001, η2p = 0.41, F2(1, 224) = 119.74, p < 0.001, η2p = 0.35. There was a main effect of suffix, F1(1, 71) = 23.00, p < 0.001, η2p = 0.25, F2(1, 224) = 3.77, p = 0.05, η2p = 0.02, and a root by suffix interaction in the analysis by participants only, F1(1, 71) = 3.35, p = 0.04, η2p = 0.06, F2(1, 224) = 2.50, p = 0.11. As the root by suffix by language interaction was also significant (marginally so, by items), F1(1, 71) = 18.51, p < 0.001, η2p = 0.21, F2(1, 224) = 3.20, p = 0.07, η2p = 0.02, we examined this interaction in each group separately.
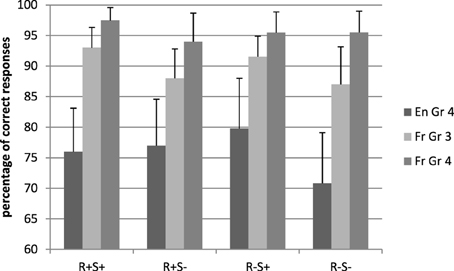
Figure 1. Mean percentage of correct responses in the lexical decision task, real word conditions. En, English; Fr, French; Gr, grade; R+S+, Root present, suffix present; R+S−, Root present, suffix absent; R−S+, Root absent, suffix present; R−S−, Root absent, suffix absent.
In the UK group, the root by suffix interaction was significant (marginally so, by items), F1(1, 39) = 18.19, p < 0.001, η2p = 0.34, F2(1, 112) = 2.88, p = 0.08 η2p = 0.03, indicating that while the presence of a suffix had no impact on accuracy when a root was present (R+S+: 76.03%, R+S−: 77.23%), it improved accuracy when there was no root (R−S+: 79.81%, R−S−: 70.81%). The effects were not significant in French.
Latencies
The mean latences for word stimuli.are reported in Figure 2. The French children responded faster than the English children [respectively, 1217 and 1415 ms, F1(1, 71) = 4.71, p = 0.03, η2p = 0.06, F2(1, 224) = 42.90, p < 0.001, η2p = 0.16]. There was a main effect of root [respectively, 1350 vs. 1317 ms, F1(1, 71) = 3.94, p = 0.05, η2p = 0.05 F2(1, 224) = 4.32, p = 0.04, η2p = 0.02. In addition, the root by language interaction was significant F1(1, 71) = 9.56, p = 0.003, η2p = 0.05, F2(1, 224) = 4.32, p = 0.04, η2p = 0.02]. Comparison showed a significant effect in English only, with the presence of a root slowing down latencies [R+: 1449 ms, R−: 1381 ms, F1(1, 71) = 12.32, p = 0.001, η2p = 0.23, F2(1, 112) = 6.28, p = 0.01, η2p = 0.05].
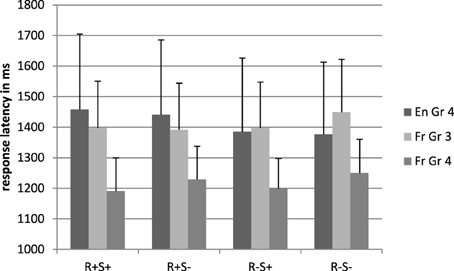
Figure 2. Response latencies in the lexical decision task, real word conditions. En, English; Fr, French; Gr, grade; R+S+, Root present, suffix present; R+S−, Root present, suffix absent; R−S+, Root absent, suffix present; R−S−, Root absent, suffix absent.
The suffix by language interaction was marginally significant by participants and non-significant by items, F1(1, 71) = 3.33, p = 0.07, η2p = 0.05, F2(1, 224) = 2.19, p = 0.14, η2p = 0.01. The presence of a suffix speeded up word recognition in French [1195 vs. 1239 ms, F1(1, 29) = 4.42, p = 0.04, η2p = 0.13, F2(1, 112) = 3.22, p = 0.07, η2p = 0.03] but not in English (1421 vs. 1409 ms), although it should be noted that this finding did not generalize across items.
Pseudoword Condition
Accuracy
The mean percentages of correct responses are displayed in Figure 3. French children responded more accurately than UK children [respectively, 98.8 and 64% correct, F1(1, 71) = 31.22, p < 0.001, η2p = 0.31, F2(1, 224) = 38.80, p < 0.001, η2p = 0.28]. There was a main effect of root, F1(1, 71) = 40.58, p < 0.001, η2p = 0.36, F2(1, 224) = 24.24, p < 0.001, η2p = 0.10, and an interaction between suffix and language, F1(1, 71) = 35.35, p < 0.001, η2p = 0.33, F2(1, 224) = 3.80, p = 0.05, η2p = 0.02. The root by suffix by language interaction was also significant by participants but not by items, F1(1, 71) = 39.12, p < 0.001, η2p = 0.36, F2 < 1. For completeness, simple effects were used to investigate the interaction by participants further but it should be noted that the interaction did not generalize across items.
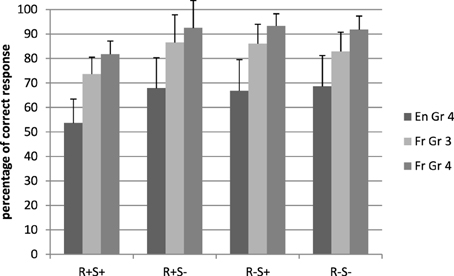
Figure 3. Mean percentage of correct responses in the lexical decision task, pseudoword conditions. En, English; Fr, French; Gr, grade; R+S+, Root present, suffix present; R+S−, Root present, suffix absent; R−S+, Root absent, suffix present; R−S−, Root absent, suffix absent.
For the UK children, there were significant main effects of root, F1(1, 42) = 27.16, p < 0.001, η2p = 0.39, F2(1, 112) = 11.52, p < 0.001, η2p = 0.09, and suffix, F1(1, 42) = 25.80, p < 0.001, η2p = 0.38, F2(1, 112) = 19.60, p < 0.001, η2p = 0.15. There was also a root by suffix interaction, F1(1, 42) = 22.95, p < 0.001, η2p = 0.35, F2(1, 112) = 7.40, p = 0.008, η2p = 0.06, revealing that the effect of root was significant only when there was also a suffix present, with this combination of root plus suffix reducing pseudoword accuracy.
For French children, there were main effects of root, F1(1, 39) = 16.95, p < 0.001, η2p = 0.37, F2(1, 112) = 13.27, p < 0.001, η2p = 0.11 and suffix, F1(1, 39) = 15.82, p < 0.001, η2p = 0.35, F2(1, 112) = 9.46, p = 0.003, η2p = 0.08. The root by suffix interaction was significant, F1(1, 39) = 17.71, p < 0.001, η2p = 0.38, F2(1, 112) = 16.93, p < 0.001, η2p = 0.13, and, as for the UK group, the negative effect of the root only occurred when there was also a suffix present.
In all, the morphemic effects are similar in both languages but this interaction indicates that the effects (by participants) appear stronger in the UK children.
Latencies
Figure 4 shows the mean latencies for the pseudoword conditions. There was a main effect of root, F1(1, 71) = 6.37, p = 0.014, η2p = 0.08, F2(1, 224) = 13.96, p < 0.001, η2p = 0.06, and this effect interacted significantly with language, F1(1, 71) = 5.18, p = 0.03, η2p = 0.07, F2(1, 224) = 6.08, p = 0.01, η2p = 0.04. The negative impact of the root was present in French only [1727 vs. 1619 ms, F1(1, 29) = 9.34, p = 0.005, η2p = 0.24, F2(1, 112) = 16.60, p < 0.001, η2p = 0.13].
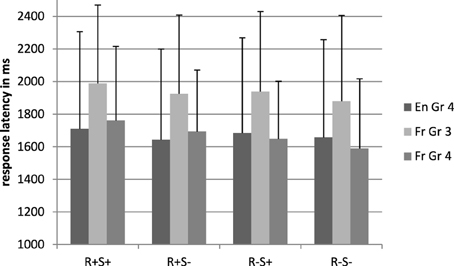
Figure 4. Response latencies in the lexical decision task, pseudoword conditions. En, English; Fr, French; Gr, grade; R+S+, Root present, suffix present; R+S−, Root present, suffix absent; R−S+, Root absent, suffix present; R−S−, Root absent, suffix absent.
The suffix by language interaction was also significant by participants only, F1(1, 71) = 7.03, p = 0.01, η2p = 0.09, F2(1, 224) = 1.21, p = 0.27, η2p = 0.02. Across participants, this indicated that the presence of suffixes slowed down responses in the French group only [respectively, 1705 and 1681 ms, F1(1, 29) = 4.64, p = 0.04, η2p = 0.14, F2(1, 112) = 4.17, p = 0.04, η2p = 0.04].
Summary of Main Results, Part 1
In sum, sensitivity to morpheme units differed across languages in processing words, while patterns of response were more comparable for pseudoword processing.
Concerning words, the presence of a root slowed word recognition in English only. The presence of a suffix was only beneficial for English accuracy in the absence of a root. In French, the pattern was different: the presence of a suffix led to faster word recognition.
In pseudoword processing, across languages, reduced accuracy was observed when a pseudoword contained both a root and a suffix, although this effect was somewhat stronger in English. Only the French children showed latency effects, with the presence of either a root or a suffix leading to slower responses.
As the French children were younger than the UK children, a second analysis was conducted to match chronological age rather than school level.
Results Part II: Chronological Age Matched Comparison
The results of the chronological age matched children are displayed in Figures 1–4.
Word Condition
Accuracy
The French children performed more accurately than the UK children [respectively, 89.99 vs. 75.97%, F1(1, 71) = 23.12, p < 0.001, η2p = 0.78, F2(1, 224) = 261.90, p < 0.001, η2p = 0.70], in spite of having received a year less of schooling. There was a main effect of suffix, F1(1, 71) = 34.60, p < 0.001, η2p = 0.33, F2(1, 224) = 6.07, p = 0.01, η2p = 0.03, a suffix by root interaction (marginal by items), F1(1, 71) = 8.01, p = 0.006, η2p = 0.10, F2(1, 224) = 2.85, p = 0.09, and the root by suffix by language interaction was significant by participants only, F1(1, 71) = 11.37, p < 0.001, η2p = 0.14, F2(1, 224) = 1.48, p = 0.23. For completeness, the interaction by participants was followed up using simple effects for each language group separately, although it should be noted that the interaction does not generalize across items.
The UK group showed a main effect of suffix in the analysis by participants, F1(1, 41) = 21.70, p < 0.001, η2p = 0.34, F2(1, 112) = 2.09, p = 0.15 and an interaction between suffix and root (marginal by items), F1(1, 41) = 18.19, p < 0.001, η2p = 0.30, F2(1, 112) = 3.54, p = 0.07, η2p = 0.07, indicating that suffixes improved word recognition accuracy only when there was no root.
For the French group, only the main effect of suffix was significant, F1(1, 29) = 13.54, p < 0.001, η2p = 0.32, F2(1, 112) = 4.63, p = 0.03, η2p = 0.04: words with a suffix were recognized more accurately than words without suffix (92.20 vs. 87.50%, respectively).
Latencies
There was no main effect of language but the root by language interaction was significant, F1(1, 71) = 11.43, p = 0.001, η2p = 0.14, F2(1, 224) = 2.82, p = 0.03, η2p = 0.14: roots increased response latencies in the UK group only, F1(1, 41) = 12.32, p = 0.001, η2p = 0.23, F2(1, 112) = 6.28, p = 0.01, η2p = 0.05.
Pseudoword Condition
Accuracy
French children were more accurate than UK children [82.30 vs. 64% correct, respectively, F1(1, 71) = 14.17, p = 0.01, η2p = 0.17, F2(1, 224) = 8.96, p = 0.003, η2p = 0.04]. While there was no main suffix effect, the suffix by language interaction was significant by participants only, F1(1, 71) = 33.16, p < 0.001, η2p = 0.32. The root by suffix by language interaction was also significant only in the analysis by participants, F1(1, 71) = 52.12, p < 0.001, η2p = 0.42. Although this effect does not generalize across items, simple effects were used to understand the interaction by participants.
In the UK group, there were main effects of root, F1(1, 42) = 27.16, p < 0.001, η2p = 0.39, F2(1, 112) = 11.52, p < 0.001, η2p = 0.09, and suffix, F1(1, 42) = 25.80, p < 0.001, η2p = 0.38, F2(1, 112) = 19.60, p < 0.001, η2p = 0.15, and an interaction between root and suffix, F1(1, 42) = 22.95, p < 0.001, η2p = 0.35, F2(1, 112) = 7.80, p = 0.008, η2p = 0.06, indicating that the combination of a root and a suffix decreased accuracy relative to other pseudowords.
In the French group, main effects of root, F1(1, 29) = 12.17, p = 0.002, η2p = 0.30, F2(1, 112) = 3.68, p = 0.05, η2p = 0.04, and suffix, F1(1, 29) = 11.64, p < 0.001, η2p = 0.29, F2(1, 112) = 4.85, p = 0.03, η2p = 0.04, were also observed, as well as an interaction between root and suffix, F1(1, 29) = 30.17, p < 0.001, η2p = 0.51, F2(1, 112) = 11.42, p < 0.001, η2p = 0.09. The interaction revealed reduced accuracy for the combination of a root and a suffix compared to other pseudowords.
This inspection of the data reveals that the suffix by root by group interaction (by participants) reflects the fact that the effects were stronger in French than in English.
Latencies
UK children responded faster than French children [respectively, 1674 and 1934 ms, F1(1, 71) = 6.77, p = 0.04, η2p = 0.06, F2(1, 224) = 146.08, p < 0.001, η2p = 0.40]. Across groups, response latencies were longer when a suffix was present [respectively, 1831 and 1777 ms, F1(1, 71) = 6.87, p = 0.011, η2p = 0.09, F2(1, 224) = 7.31, p = 0.007, η2p = 0.03].
Summary of Main Results, Part II
As in the comparison by grade level, there was indication of differential group sensitivity to morpheme units in word recognition but a similar pattern of pseudoword processing across languages.
For word recognition, only the UK children showed increased latencies when a root was present. Accuracy among the French children showed a higher degree of sensitivity to suffixes (regardless of whether a root was present or not).
For pseudoword processing, the effects were the same across languages: the presence of a suffix in a pseudoword slowed responses and the combination of a root plus a suffix reduced accuracy.
Discussion
Current models of reading development highlight cross-linguistic variation in naming accuracy in relation to early orthographic decoding (e.g., Ziegler and Goswami, 2005). However, these models do not offer an account of whether or not cross-linguistic effects operate on morphological processing during visual word recognition. The present study examined the extent to which morphemic effects in lexical access are universal or whether such effects can be modulated by language specificities during development.
For this purpose two comparable sets of lexical decision stimuli that manipulated the presence of component morphemes were presented to groups of French- and English-speaking children. As schooling starts 1 year earlier in the UK as compared to France, performance was first compared using a schooling match (Grades 4 in France and the UK), and in a second comparison, a chronological age match (Grade 3 in France and Grade 4 in the UK; both aged 8 years).
The data clearly indicate the importance of roots and suffixes for both language groups. Although the precise pattern differed, both groups were sensitive to the presence a suffix within words—either a genuine suffix or a suffix-like ending—which is consistent with the importance of suffixes as orthographic patterns. For pseudowords, the combination of a root with a suffix interfered with accurate processing in both languages. A tendency to slower responses was also observed when a pseudoword contained only a suffix, although this effect was clearer in French and present from Grade 3 onwards.
Cross-linguistic differences were also apparent, although some interaction effects were significant in the by-participants analysis only. In English, the presence of roots slowed down visual word recognition. Specific attention was given to the R+S+ vs. R+S- comparison, as these correspond respectively to the morphological and orthographic control conditions that are typically used in the literature on morphological decomposition in visual word recognition (see for example, Feldman et al., 2002; Casalis et al., 2009, for developmental studies). Interestingly, faster word recognition was observed when a suffix was present in the French analysis but not in the English analysis. This suggests a more specifically morphological sensitivity in French, whereas the results indicated sensitivity to embedded words in English, since roots were mostly free-standing words.
In English, suffixes only affected the accuracy of word recognition in the absence of a root; whereas, in French, suffixes generally led to faster word recognition and, for the older Grade 4 group, improved accuracy only when combined with a root (i.e., the R+S+ real derivations, e.g., farmer). This latter effect of school grade in French suggests that reading skills and/or language proficiency has an impact on suffix processing.
A detrimental effect of the root was observed in English only. This effect was not apparent in French as the impact of the root produced only facilitation effects among French children. This cross-language discrepancy may derive from the fact that, in most cases, roots corresponded to whole words in English (41 out 58 items), whereas this was less true of French (25 out 58 items). This would be consistent with Nation and Cocksey's (2009) finding of an automatic semantic activation of embedded words among English-speaking 7-year-olds. Therefore, the inhibition effect observed in the present study may reflect processing costs associated with identification of the root and competition with whole word processing. Indeed, a striking finding is that the inhibition effect in English is observed in both R+S− words, which may be considered to be orthographic control items, and R+S+, which are derived forms. Morphological priming studies report only facilitation effects, both among skilled readers of English (e.g., Rastle and Davis, 2008) and developing readers of French (Quémart et al., 2011). Minimally, then the inhibition effects observed here indicate that young English-speaking readers are sensitive to embedded word units in visual word recognition. While higher frequency embedded words in English might have favored an inhibition effect in English, the languages did not differ significantly in this respect in either the R+S+ or R+S = conditions although it should be noted that the outcome was marginal (p = 0.07) in the R+S− condition. While French and English stimuli were statistically matched in terms of frequency, French words tended to be slightly longer than English words. Although the difference was less than 1 letter on average, this could potentially have led French children to show more reliance on a decomposition strategy for word processing. Another source of difference lies in the fact that some suffixes have been repeated, leading potentially to an increased sensitivity to morphological decomposition. Note that slightly more repetition occurred in English (-er) than French.
Strong effects of morpheme units were found in pseudoword processing where the combination of both root and suffix led to an increasing rate of errors. This result is in line with previous research, suggesting that young readers rely on morpheme units when they have to process an unknown word (Burani et al., 2002; Quémart et al., 2012). At the same time, linguistic variation also came into play as the beneficial effects of suffixes, in particular, were stronger in French pseudoword processing.
A methodological difficulty when comparing children from different countries is that such a comparison goes beyond differences in native language. A first issue is that schooling starts during the fifth year in UK while it starts during the sixth year in France. This was dealt with by performing two separates analyses: one based on a school-level matched design, with French children being older than UK children; and the other based on a chronological-age matched design, with the UK children having experienced a year more of schooling. It was not possible to achieve a perfect matching between the groups as the English-speaking children were less accurate than the French children regardless of the method of matching groups. In contrast, the UK children exhibited slower latencies in word processing than the older Grade 4 French children in the first analysis but were faster at pseudoword processing than the Grade 3 French children in the second analysis. A second issue is connected to the school curriculum, particularly in relation to the teaching of reading and morphology. Across languages, our participants all came from schools adopting a mixed method approach to reading instruction: whole-word and phonics. In France, morphological structure is explicitly taught at Grade 4 and, in the Scottish education system that the UK children experienced, intensive instruction about derivational affixes begins in Grades 3 or 4 as part of spelling instruction. Further studies should address instructional issues in a more systematic way. Our study was a first attempt to directly compare the use of morphological units across languages. It will therefore be necessary to extend this work to larger samples as well as other languages.
In terms of group differences in word processing, French children were always more accurate, and were faster only when they were older (schooling matching); in pseudoword processing, French children again always responded more accurately, but responded more slowly when they were matched on age (with less schooling). Note that the difference may be explained by the fact that the French pseudowords were almost one letter longer than the English pseudowords. However, it is possible that the additional year of schooling experienced by the UK children may also have contributed to their faster pseudoword reaction times. Beyond these group differences, both analyses yielded quite similar patterns of results. However, the slight differences that emerged between Part 1 and Part 2 reveal that morphological processing develops during schooling. More specifically, the presence of a root slowed down latencies for fourth graders only (UK), and there were more indication of a suffix benefit among French fourth graders than French third graders.
Thus, our study demonstrates that developing readers make use of morphology when recognizing familiar words and when processing new words. In a previous study, Duncan et al. (2009) compared English and French morphological awareness in relation to derivation with suffixes. The results clearly showed that the UK children were outperformed by the French children when they had to manipulate morpheme units explicitly. Note that sensitivity to morphemes, as assessed by a relational judgment task, was found to be similar in both groups. These results were interpreted with reference to the importance of morphological structure in French. It is therefore interesting to note that, in the present study, UK children make use of morphemes during lexical access, even though overall they were less accurate at this than French children and were less sensitive to true derivations (R+S+ words). This outcome aligns with two conclusions: first, morphemes may be used in word and pseudoword processing regardless of GPC transparency; and second, when confronted with a rich morphological system, children may develop morphological knowledge faster and acquire a more finely-tuned sensitivity to written morphology.
In conclusion, research on reading acquisition reflects a growing interest in morphological processing, as once children have completed the first phases of reading acquisition they are confronted by a growing number of long and derived words. Previous research on phonological coding in reading aloud has pointed to the importance of cross-language variation in the nature and speed of acquisition of GPC, and was formalized in the PGST. Our intention was to begin the process of examining morphological processing in visual word recognition within a similar framework. The languages under investigation differed in terms of orthographic depth, with English being more opaque than French, and morphological productivity, with French being morphologically richer than English. The first aim was to examine whether morphology was generally used by developing readers in Grades 3 and 4. A main result was that children make use of morphemic information in both languages confirming our first hypothesis of the relevance of morphology in reading development in both opaque and more transparent alphabetic orthographies. The second aim was to assess the importance of two factors expected to be influential, namely, orthographic depth and morphological prevalence/transparency. Both aspects could be contrasted in English and French in opposing directions, with the English orthography being more opaque and French morphology being richer. One key question was therefore whether the utility of morphemes in resolving the greater inconsistency in English increased sensitivity in this group beyond the level expected by the influence of morphological productivity/transparency. Results indicated stronger morphological effects in French, confirming our hypothesis that morphological richness will outweigh orthographic depth at least in alphabetic writing systems.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This research was completed while the first author was a doctoral student, funded by the French Ministry of Research and Technology, and the third author was a visiting lecturer, both at the University of Lille, France. This project was supported by the grant LECT MORPHO from the National Agency for Research (ANR) award to SC and the grant from the French Research Agency ANR−11-EQPX-0023, FEDER SCV-IRDIVE and University Lille 3. We also thank Marion Janiot and Elaine Gray for help with participant recruitment and testing.
Supplementary Material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fpsyg.2015.00452/abstract
References
Bauer, L. (2003). Introducing Linguistic Morphology, 2nd Edn. Edinbourg: Edinburgh University Press.
Burani, C., Marcolini, S., and Stella, G. (2002). How early does morpholexical reading develop in readers of a shallow orthography? Brain Lang. 81, 568–586. doi: 10.1006/brln.2001.2548
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Burani, C., Marcolini, S., De Luca, M., and Zoccolotti, P. (2008). Morpheme-based reading aloud: evidence from dyslexic and skilled Italian readers. Cognition 108, 243–262. doi: 10.1016/j.cognition.2007.12.010
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Carlisle, J. F., and Katz, L. (2006). Effects of word and morpheme familiarity on reading of derived words. Read. Writ. 19, 669–693. doi: 10.1007/s11145-005-5766-2
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Carlisle, J. F., and Stone, C. A. (2005). Exploring the role of morphemes in word reading. Read. Res. Q. 40, 428–449. doi: 10.1598/RRQ.40.4.3
Casalis, S., Dusautoir, M., Colé, P., and Ducrot, S. (2009). Morphological relationship to children word reading: a priming study in fourth graders. Br. J. Dev. Psychol. 27, 761–766. doi: 10.1348/026151008X389575
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Clark, E. V. (1998). Lexical creativity in French-speaking children. Cahiers de Psychologie Cognitive 17, 513–30.
Colé, P., Bouton, S., Leuwers, C., Casalis, S., and Sprenger-Charolles, L. (2012). Stem and derivational-suffix processing during reading by French second and third graders. Appl. Psycholinguist. 33, 97–120. doi: 10.1017/S0142716411000282
Coltheart, M., and Crain, S. (2012). Are there universals of reading? We don't believe so. Behav. Brain Sci. 35, 282–283. doi: 10.1017/S0140525X12000155
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Deacon, S. H. (2012). Bringing development into a universal model of reading. Behav. Brain Sci. 35, 284–284. doi: 10.1017/S0140525X12000040
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Deacon, S. H., Whalen, R., and Kirby, J. R. (2011). Do children see the danger in dangerous? Grade 4, 6, and 8 children's reading of morphologically complex words. Appl. Psycholinguist. 32, 467–481. doi: 10.1017/S0142716411000166
Duncan, L. G., Casalis, S., and Colé, P. (2009). Early meta-linguistic awareness of derivational morphology: some observations from a comparison of English and French. Appl. Psycholinguist. 30, 405–440. doi: 10.1017/S0142716409090213
Duncan, L. G., Castro, S. L., Defior, S., Seymour, P. H. K., Baillie, S., Leybaert, J., et al. (2013). Phonological development in relation to native language and literacy. variations on a theme in six alphabetic orthographies. Cognition 127, 398–419.
Dunn, L. M., Dunn, L. M., Whetton, C., and Burley, J. (1997). British Picture Vocabulary Scale II. Windsor: NFER-Nelson.
Dunn, L. M., Theriault-Whalen, C. M., and Dunn, L. M. (1993). Echelle de Vocabulaire en Images Peabody, Adaptation Française. Toronto, ON: Psycan.
Elliott, C. D., Murray, D. J., and Pearson, L. S. (1983). British Ability Scales. Windsor: NFER Nelson.
Feldman, L. B., Rueckl, J., DiLiberto, K., Pastizzo, M. J., and Vellutino, F. R. (2002). Morphological analysis by child readers as revealed by the fragment completion task. Psychon. Bull. Rev. 9, 529–535. doi: 10.3758/BF03196309
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Frost, R. (2012). Towards a universal model of reading. Behav. Brain Sci. 35, 263–279. doi: 10.1017/S0140525X11001841
Frost, R., Katz, L., and Bentin, S. (1987). Strategies for visual word recognition and orthographical depth: a multilingual comparison. J. Exp. Psychol. Hum. Percept. Perform. 13, 104–115. doi: 10.1037/0096-1523.13.1.104
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Hulme, C., and Snowling, M. J. (2013). The interface between spoken and written language: developmental disorders. Philos. Trans. R. Soc. Lond. B Biol. Sci. 369:20120395. doi: 10.1098/rstb.2012.0395
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Laxon, V., Rickard, M., and Coltheart, V. (1992). Children read affixed words and non-words. Br. J. Psychol. 83, 407. doi: 10.1111/j.2044-8295.1992.tb02450.x
Lefavrais, P. (1967). Test de l'Alouette (the Alouette test). Paris: Editions du Centre de Psychologie Appliquée.
Lété, B., Sprenger-Charolles, L., and Colé, P. (2004). MANULEX: a grade-level lexical database from French elementary school readers. Behav. Res. Methods Instr. Comput. 36, 156–166. doi: 10.3758/BF03195560
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Mann, V., and Singson, M. (2003). “Linking morphological knowledge to English decoding ability: large effects of little suffixes” in Reading Complex Words: Cross-Languages Studies, eds E. M. H. Assink and D. Sandra (New York, NY: Kluwer Academic), 1–26.
Marcolini, S., Traficante, D., Zoccolotti, P., and Burani, C. (2011). Word frequency modulates morpheme-based reading in poor and skilled Italian readers. Appl. Psycholinguist. 32, 513–532. doi: 10.1017/S0142716411000191
Masterson, J., Stuart, M., Dixon, M., and Lovejoy, S. (2003). The Children's Printed Word Database. Available online at: www.essex.ac.uk/psychology/cpwd
Melby-Lervåg, M., Lyster, S. A., and Hulme, C. (2012). Phonological skills and their role in learning to read: a meta-analytic review. Psychol. Bull. 138, 322–352. doi: 10.1037/a0026744
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Muter, V., Hulme, C., Snowling, M. J., and Stevenson, J. (2004). Phonemes, rimes, vocabulary, and grammatical skills as foundations of early reading development: evidence from a longitudinal study. Dev. Psychol. 40, 665–681. doi: 10.1037/0012-1649.40.5.665
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Nagy, W. E., and Anderson, R. C. (1984). How many words are there in printed school in English? Read. Res. Q. 19, 304–330. doi: 10.2307/747823
Nation, K., and Cocksey, J. (2009). Beginning readers activate semantics from sub-word orthography. Cognition 110, 273–278. doi: 10.1016/j.cognition.2008.11.004
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Quémart, P., Casalis, S., and Colé, P. (2011). The role of form and meaning in the processing of written morphology: A priming study in French developing readers. J. Exp. Child Psychol. 109, 478–496. doi: 10.1016/j.jecp.2011.02.008
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Quémart, P., Casalis, S., and Duncan, L. G. (2012). Exploring the role of bases and suffixes when reading familiar and unfamiliar words: evidence from French young readers. Sci. Stud. Read. 16, 424–442. doi: 10.1080/10888438.2011.584333
Rastle, K., and Davis, M. H. (2008). Morphological decomposition based on the analysis of orthography. Lang. Cogn. Process. 23, 942–971. doi: 10.1080/01690960802069730
Rey-Debove, J. (1984). Le domaine de la morphologie lexicale [The domain of lexical morphology]. Cahiers de Lexicologie 45, 3–19.
Schneider, W., Eschmann, A., and Zuccolotto, A. (2002). E-Prime Reference Guide. Pittsburgh, PA: Psychology Software Tools.
Seymour, P. H. K. (1994–1999). Cognitive Workshop Software. Developed at the School of Psychology, University of Dundee by Software Interventions Ltd. in cooperation with The Child Research Centre at the University of Jyväskylä, Finland.
Seymour, P. H. K., Aro, M., and Erskine, J. M. (2003). Foundation literacy acquisition in European orthographies. Br. J. Psychol. 94, 143–174. doi: 10.1348/000712603321661859
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Ziegler, J. C., and Goswami, U. (2005). Reading acquisition, developmental dyslexia, and skilled reading across languages: a psycholinguistic grain size theory. Psychol. Bull. 131, 3–29. doi: 10.1037/0033-2909.131.1.3
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Ziegler, J. C., and Goswami, U. (2006). Becoming literate in different languages: similar problems, different solutions. Dev. Sci. 9, 429–436. doi: 10.1111/j.1467-7687.2006.00509.x
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Ziegler, J. C., Perry, C., Jacobs, A. M., and Braun, M. (2001). Identical words are read differently in different languages. Psychol. Sci. 12, 379–384. doi: 10.1111/1467-9280.00370
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Keywords: morphology, reading acquisition, cross language comparison, visual word recognition, lexical decision task
Citation: Casalis S, Quémart P and Duncan LG (2015) How language affects children's use of derivational morphology in visual word and pseudoword processing: evidence from a cross-language study. Front. Psychol. 6:452. doi: 10.3389/fpsyg.2015.00452
Received: 01 September 2014; Accepted: 30 March 2015;
Published: 16 April 2015.
Edited by:
Simona Amenta, University of Milano-Bicocca, ItalyReviewed by:
Cristina Burani, Institute of Cognitive Sciences and Technologies-Consiglio Nazionale delle Ricerche, ItalyJohn Kirby, Queen's University, Canada
Copyright © 2015 Casalis, Quémart and Duncan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Séverine Casalis, SCALab, Université de Lille and Centre National de la Recherche Scientifique, (UMR 9193), Rue du barreau, 59653 Villeneuve d'Ascq, France severine.casalis@univ-lille3.fr