 Qing Pan
Qing Pan- Department of Statistics, The George Washington University, Washington, DC, USA
We review and compare multiple hypothesis testing procedures used in clinical trials and those in genomic studies. Clinical trials often employ global tests, which draw an overall conclusion for all the hypotheses, such as SUM test, Two-Step test, Approximate Likelihood Ratio test (ALRT), Intersection-Union Test (IUT), and MAX test. The SUM and Two-Step tests are most powerful under homogeneous treatment effects, while the ALRT and MAX test are robust in cases with non-homogeneous treatment effects. Furthermore, the ALRT is robust to unequal sample sizes in testing different hypotheses. In genomic studies, stepwise procedures are used to draw marker-specific conclusions and control family wise error rate (FWER) or false discovery rate (FDR). FDR refers to the percent of false positives among all significant results and is preferred over FWER in screening high-dimensional genomic markers due to its interpretability. In cases where correlations between test statistics cannot be ignored, Westfall-Young resampling method generates the joint distribution of P-values under the null and maintains their correlation structure. Finally, the GWAS data from a clinical trial searching for SNPs associated with nephropathy among Type 1 diabetic patients are used to illustrate various procedures.
1. Introduction
When more than one hypotheses are tested at the same time, it is well known that the family wise type I error rate (FWER), that is, the probability of reporting at least one significant finding when the null hypotheses are true, will be inflated. Take J independent test statistics as an example. When each test controls its type I error rate at α level, the FWER is 1 − (1 − α)J. Table 1 lists the FWERs for different combinations of J and α. When J = 10 and α = 0.05, FWER goes up to 0.401. In cases of 100 or more simultaneous tests, it is almost sure to get false positive results.

Table 1. FWER versus number of tests and the size of individual tests.
Multiple hypotheses testing arises frequently both in clinical trials and in genomic studies. The different goals in these two settings result in different strategies. First, the hypotheses in clinical trials are often considered as a whole while those in genomic studies are more independent from each other. In clinic trials, multiple hypotheses are often considered jointly with a coherent theme. A few examples are given as follows. The symptoms of a complex disease often show up in different parts of the body or in different forms, such as different types of cancer. Multiple laboratory measurements monitor the underlying disease process, such as the viral loads and CD4 cell counts in HIV positive subjects. A treatment might have different responses in different patient sub-populations. On the other hand, multiple hypotheses in genomic studies arise because a large number of candidate markers are tested at the same time. Based on the number of tests carried out in the procedure, the multiple testing adjustment approaches can be grouped into global tests and stepwise procedures (1). Global tests summarize information from all endpoints/measurements/strata in one test statistic, while stepwise procedures carry out one test for each hypothesis. Therefore global tests are employed frequently in clinical trials while genomic studies almost always employ stepwise procedures. Second, the hypotheses in clinical trials are usually more specific with abundant prior information. In testing a specific treatment, with knowledge on the direction of the effects, directional tests with higher power can be employed. On the other hand, the genomic, epigenomic, transcriptomic, and proteomic network is much more complicated and often researchers screen for any signal, without knowing its direction or relationship to other markers. Third, the numbers of hypothesis in clinical trials are on a much smaller scale compared to the numbers in genomic studies – the numbers in clinical trials are usually less than ten, while the numbers of potential markers in genomic studies are sometimes over a million. In this manuscript, common procedures of multiple hypotheses adjustment in the two different settings are reviewed and compared.
The effects of interests are usually inferred from regression coefficients. In linear regression for normally distributed outcomes, the coefficient represents the difference in the outcome values between the groups being compared. In generalized linear models with logit link for binary outcomes, the coefficient equals the logarithm of the odds ratio of the outcome in the treatment group relative to the control group. In Cox proportional hazards models for partially censored failure time data, the exponentiated coefficient represents the hazards ratio. This review focuses on the choice of proper multiple testing adjustment method after the estimation procedures. Hence, we assume that appropriate models are chosen for different data configurations and parameters and covariance matrix are consistently estimated. Suppose there are J hypotheses in total. Let β and denote the two J × 1 vectors of regression coefficients and their estimates, respectively, one element for each hypothesis. Furthermore, βj = 0 corresponds to the jth null hypothesis, j = 1, …, J.
2. Multiple Testing Procedures in Clinical Trials
2.1. SUM Test
O’Brien (2) proposed a test derived from the generalized least squares principle
where J is an J × 1 vector of 1’s and Σ is the covariance matrix of . When elements of are independent from each other, the O’Brien test statistic reduces to a linear combination of where each is weighted by inverse of its variances. Tests employing linear combinations of with different weights have been proposed (3–6), among which the SUM test is especially popular (7). The SUM test statistic has a simple sum form
Under the null hypothesis , E(SUM) = 0. The SUM test is found to maximize the minimum power (maxmin test) for alternatives where all elements of β have the same sign (8, 9).
2.2. Two-Step
When homogeneous effects are of interests, a two-step procedure is commonly used. In the first step, we test versus Ha: at least one pair for j ≠ j′ through Breslow-Day test or likelihood ratio test (LRT) (10, 11). Under the null, the LRT test statistic follows a Chi-square distribution with J − 1 degree of freedom asymptotically. If the null hypothesis of homogeneous treatment effects is not rejected, we proceed to the second step where data from different endpoints are pooled and an overall treatment effect is estimated and tested against zero with a Wald test. The second test is carried out conditionally on the acceptance of the null in the first step. When the type I error rates in the two steps, α1 and α2, both equal 0.05, the marginal probability that the Two-Step procedure concludes homogeneous non-zero treatment effects under H0 is 95% × 5% = 4.75%, while the probability of concluding non-zero treatment effect in at least one endpoint under H0 is 95% × 5% + 5% = 9.75%. Lachin and Wei (12) proposed to adjust α1 and α2 so that the overall type I error rate is α1 + α2(1 − α1) = 0.05.
2.3. Approximate Likelihood Ratio Test
The Hotelling’s T test examines whether the vector β is a vector of zero
Here n is the sample size in testing each hypothesis. Under H0, the Hotelling’s T test statistic has an asymptotic Chi-square distribution. Follmann (13) modified Hotelling’s T test for one-sided alternatives. His procedure rejects the null when the p-value of the Hotelling’s T test is less than twice its nominal level and the sum of the treatment effects is in the desired direction (positive or negative). Tang et al. (14) proposed an approximate likelihood ratio test (ALRT) for one-sided alternative hypotheses. A J × J matrix A which satisfies A′A = Σ−1 and AΣA′ = I is calculated, where I denotes the identity matrix. Define where the vector is mapped into a new vector z with independent components zj, j = 1, …, J. For Ha: at least one βj > 0, the ALRT statistic is calculated as
where negative zj values contribute zero. Hence the absolute magnitude of negative zj has no impact on ALRT. The ALRT statistic follows a mixed Chi-square distribution under H0.
2.4. MAX Test
Another type of global tests employ the maximum of the standardized test statistics (15). The test statistic goes as follows
where is the standard deviation of . Given the one-to-one relationship between and its p-value, an equivalent test statistic is the minimum of the P-values. The MAX test is powerful to detect alternatives where the treatment effects are non-zero in at least one endpoint/measurement/stratum.
2.5. Intersection-Union Test
Establishment of bioequivalency is required by the U.S. Food and Drug Administration (FDA) in approving generic drugs. The brand-name drug and its generic version are considered indifferent for the jth outcome if , where the indifferent range εj is decided clinically. FDA is interested in whether the generic drug is superior in at least one aspect while non-inferior in all aspects. Therefore, the alternative of interest goes as follows Ha: {max(β1, β2, …, βk) > 0} ∩ {min(β1+ε1, β2+ε2, …, βk+εk) > 0} where ∩ denotes intersection. The intersection-union test (IUT) (16–18) is most frequently used in these settings. It is a closed procedure which rejects the overall null hypothesis if and only if all null hypotheses included in the procedure are rejected. The ALRT is used to test against the alternative max (β1, β2, …, βk) > 0. Non-inferiority in the jth endpoint is tested by
Because the overall rejection region is the intersection of all rejection regions, the overall type I error will not exceed α if the type I error rates of individual tests are set at α. Although more than one tests are carried out in IUT, it is included in the category of global tests because it draws an overall conclusion, not multiple hypothesis-specific conclusions. The five global tests are summarized in Table 2.

Table 2. Comparison. of five global test statistics.
2.6. Comparison of Rejection Regions of the Global Tests
We take the special example with two coefficient estimates , which are are bivariate normal with mean (0, 0), variance 1 and 2 respectively, and correlation coefficient 0.3. The null and alternative hypotheses are H0: (β1 = 0) ∩ (β2 = 0) versus Ha: (β1 > 0) ∩ (β2 > 0). The rejection regions of the five global tests are shown in Figure 1, when α = 0.05 in each individual test. The five rejection regions imply that each test has optimal power against different alternatives. The Wei-Lachin SUM test rejects outside a straight line with slope –1 which represents a constant sum. The rejection region of the Two-Step test can be viewed as removing two sides from the rejection region of the SUM test. The MAX test and ALRT reject points with a large positive value in at least one dimension. The rejection region of the IUT eliminates points with negative or close to zero values in any endpoint compared to the rejection region of ALRT.
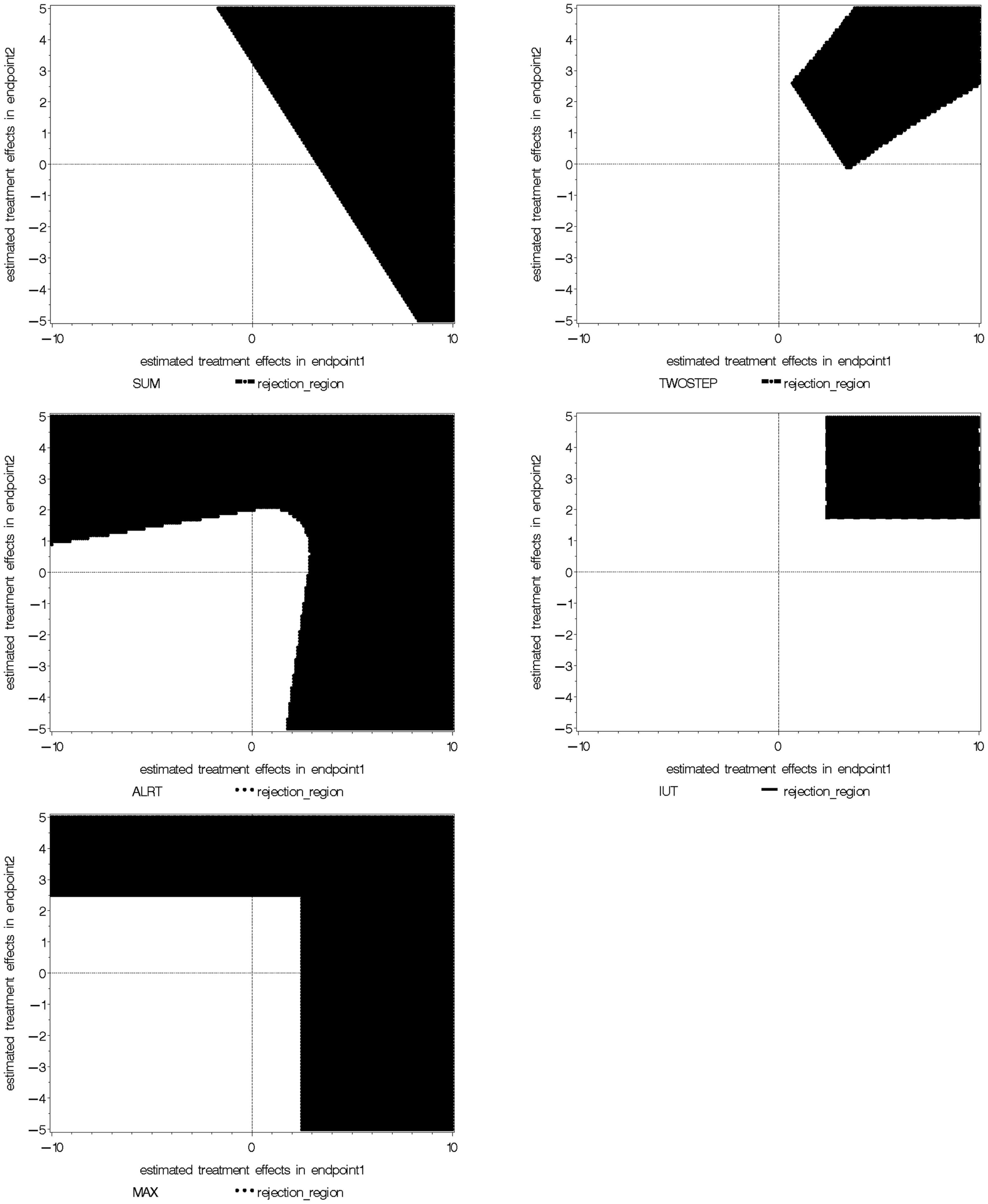
Figure 1. Comparison of rejection regions of five global tests.
3. Simulation Studies
We simulate binary data following a logistic model to illustrate the global tests. Two different scenarios are examined – correlated multiple outcomes and independent stratified data. For correlated outcomes, each subject i has two endpoints. The independent data are from two strata. Two independent covariates are generated: a binomial variable X1 ij with equal probability to be zero or one and a normal variable X2 ij with mean 0 and standard deviation 5. The outcomes Yij follow Bernoulli distribution specified by logit{p(Yij = 1)} = ηj + βjX1 ij + θX2 ij. Note the effects of the treatment X1 ij is reflected by two endpoint-specific regression coefficients, β1 and β2. Correlated binary outcomes are generated following Park, Park, and Shin method (19). The intercepts for endpoint 1 and 2 are η1 = 0.5, η2 = 0.2, and the coefficient for X2 ij is θ = 0.1 for both endpoints. In simulating the independent binary data, θ = 0.02. In case of unequal sample sizes in the two endpoints, observations in the endpoint with less subjects are missing completely at random. Maximum likelihood estimator for β1 and β2, as well as the covariance matrix are calculated through generalized estimating equations (20). One-sided alternatives Ha: (β1 > 0)∩(β2 > 0) are tested. Test statistics are calculated using , . Each setup is repeated 1000 times. In each iteration, all the test statistics are calculated using the same dataset. We examine and compare the powers and Type I error rates of all five tests for different true values (Table 3), different levels of correlations (Table 4), and different sample sizes at each endpoint (Table 5).
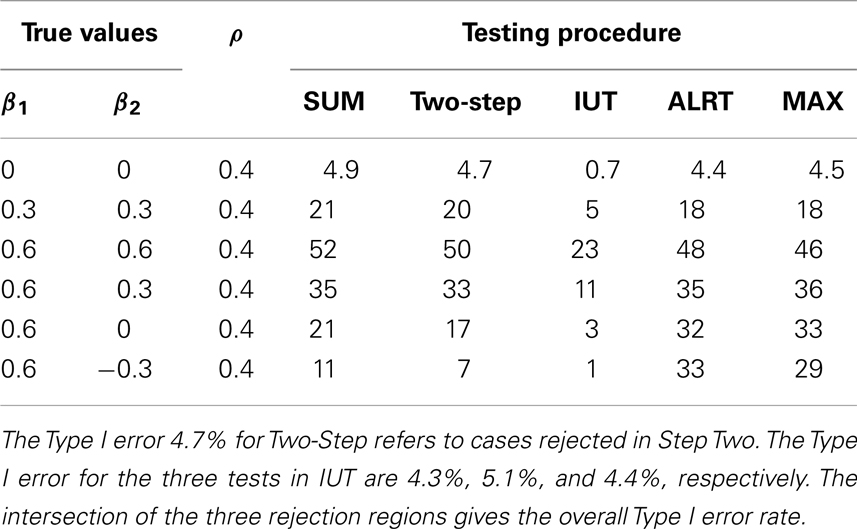
Table 3. Simulation results: size and power (%) with different true value positions.
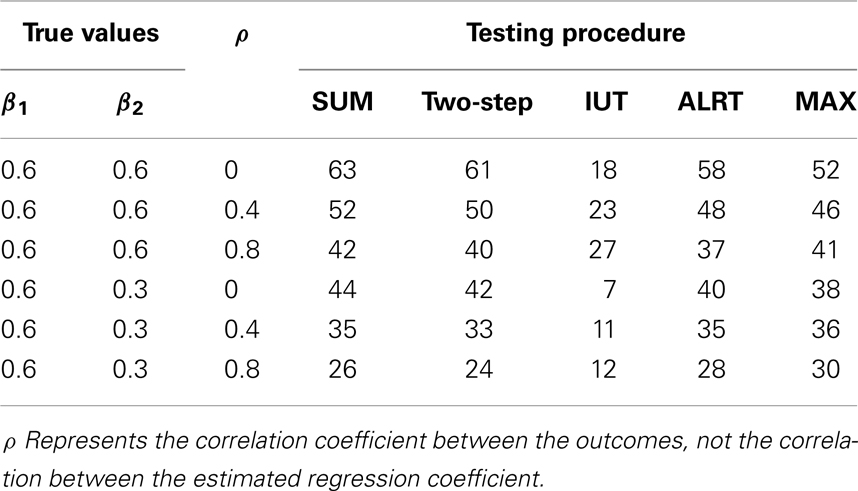
Table 4. Simulation results: power (%) under different correlation between outcomes.
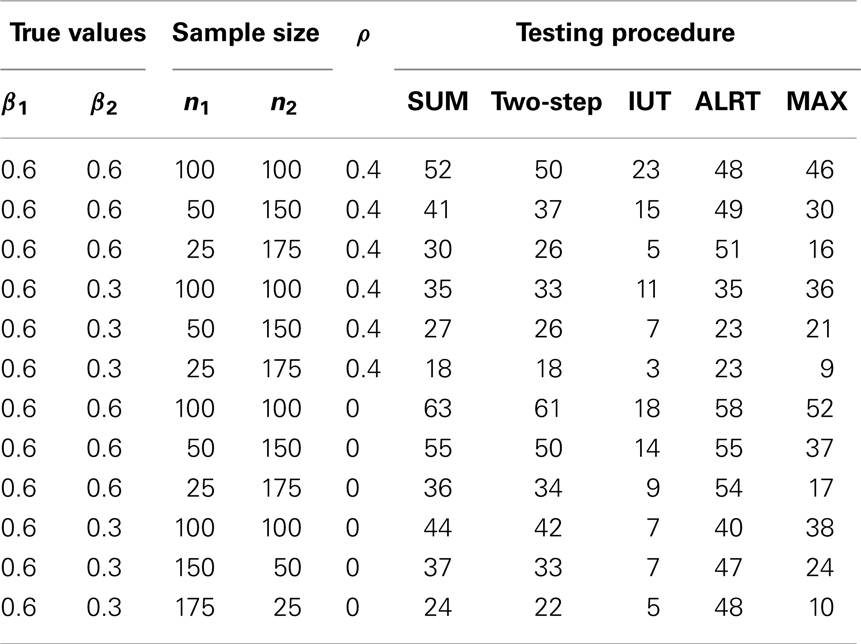
Table 5. Simulation results: power (%) with different sample sizes.
The powers and Type I error rates for different (β1, β2) values are listed in Table 3. The correlation between Y i1 and Y i2 is set to be 0.4 and each endpoint has 100 observations. All tests except the IUT maintain the Type I error rates close to the nominal level 0.05. Without prior knowledge of the indifference range, we set the most restrictive indifference range where εj = 0 for every endpoint which is equivalent to requiring all treatment effects to be positive, leading to low overall type I error rate and power. IUT tends to be more conservative than other methods because FDA is more concerned with false positives and only approves new treatment when there is significant evidence supporting its superiority. The procedures can be divided into two groups according to how the power changes when the difference between β1 and β2 gets larger. The first group includes Wei-Lachin SUM and Two-Step. They are more powerful than the other group when β1 = β2, but sensitive to non-homogeneous treatment effects. The power of the Wei-Lachin SUM test drops from 52 to 21% when β2 drops from 0.6 to 0 while β1 remains 0.6. The decreasing trend is even more obvious with the Two-Step. The second group includes ALRT and the MAX test. They are robust to non-homogeneous treatment effects.
In Table 4, 100 correlated pairs (Yi1, Yi2) are generated with various correlation coefficients. All the methods incorporate information from both endpoints. When two outcomes are highly correlated, the treatment effects estimated from both endpoints, and , tend to be similar and provide less information compared to the independent case, hence lower power. However, the IUT has a reversed pattern because with higher positive correlation, the non-inferiority tests on the two endpoints tend to agree more, leading to higher overall rejection rates.
Table 5 lists the different performance of the tests with unequal sample sizes for the two endpoints. When sample sizes are not balanced between the two endpoints, most tests have reduced power because the test statistics combine information from all endpoints and a large variance in one endpoint leads to large variance of the overall test statistic. ALRT is robust to unequal sample sizes. If treatment effects are equal in both endpoints (β1 = β2 = 0.6), the power of ALRT does not change with the distribution of samples into each two endpoints as long as the total sample size remains the same. When the treatment effects differ in the two endpoint (β1 = 0.6, β2 = 0.3), the power of ALRT could either increase or decrease depending on which endpoint has more subjects. If the endpoint with a larger treatment effects has a larger sample size, ALRT has higher power. If the endpoint with a smaller treatment effect gets more samples, the power decreases.
4. Controlling FWER/FDR in Genomic Studies
4.1. Stepwise Procedures and FDR
Stepwise procedures are classified into one-step procedures and multi-step procedures. One-step procedures set a uniform threshold for all the unadjusted P-values while multi-step procedures set different thresholds for different hypotheses depending on the order of the unadjusted P-values. Multi-step procedures can be carried out step-down or step-up (21, 22). In step-down procedures, the hypothesis with the smallest P-value is tested first. And as long as one hypothesis fails to be rejected, all the hypotheses with larger unadjusted P-values will fail to be rejected. On the contrary, step-up procedures start from the largest unadjusted P-value and reject all smaller unadjusted P-values after the first one is rejected.
In this manuscript, the FWER is preserved at nominal level in a strong sense, that is, FWER is no larger than the nominal level for testing any subset of the hypotheses set. Given the large number of hypotheses, researchers are often more interested in a more interpretable quantity, the FDR (23). FDR is the rate that the rejected or significant features are truly null. The numbers of true and false positives can be calculated directly from FDR. FDR helps to avoid a flood of false positives when most of the hypotheses are truly null or missing out significant features when the number of true alternative hypotheses is large. FDR can be estimated as
where m is the total number of hypotheses being tested, π0 is the percent of true null among them, I is the indicator for a true statement in the bracket, and t is the cutoff value of p-values to call a feature significant. Although π0 is unknown, it can be estimated from the distribution of P-values. Benjamini and Hochberg (24) developed a step-up procedure to control FDR at level q*. For ordered unadjusted P-values P(1), P(2), …, P( J), we reject the first j hypotheses with the smallest j P-values if .
4.2. Resampling Method
Westfall and Young (25) and Troendle (26) developed resampling procedures which simulate the joint distributions of the P-values under the null while maintaining their correlation structure. The procedure starts with bootstrap or permutation under the null from the original sample. Then hypothesis-specific pivotal test statistics and the corresponding P-values are calculated on the simulated data. The steps are repeated a large number of times to achieve an empirical distribution of (P1, P2, …, PJ) under the null which maintains the correlation structure. The unadjusted P-values for the jth hypothesis is the percent of times the jth imputed test statistic is larger than or equal to the jth test statistic from the original data. Step-down or step-up procedures can be carried out on the unadjusted P-values based on resampling. There is a resampling option in SAS “multtest” procedure for several tests including the two-sample t-test, Cochran-Armitage test and Fisher’s exact test. However, this procedure does not allow covariate adjustments and can not be used in multiple comparisons in regressions.
4.3. Bonferroni Adjustment
The Bonferroni adjustment is a one-step procedure which rejects the jth null hypothesis H0 j when the p-value in testing the jth hypothesis . The FWER in the Bonferroni procedure is conserved at α level because
where ∪ denotes union. Alternatively, researchers may compute adjusted P-values as and compare to the nominal level α. The Bonferroni adjustment is computationally straight forward because the threshold for significant P-values in each hypothesis is just the FWER divided by the number of hypotheses. However, Bonferroni procedure is conservative with low power.
Wiens (27) and Huque and Alosh (28) modified the Bonferroni procedure with fixed testing sequence procedure. It allocates the overall Type I error rate sequentially and controls FWER at the nominal level. Let the sequence of hypotheses be . Assign type I error rate αj to each of the null hypothesis such that . Furthermore, if the first hypothesis is not rejected, its portion of the type I error α1 will be passed onto the second hypothesis. That is, the type I error rate for the second hypothesis becomes α1 + α2 conditional on that fails to be rejected. On the contrary, if is rejected, the type I error rate of remains α2. In summary, the type I error rates of unrejected hypotheses accumulate and are passed onto the next hypotheses until a hypothesis is rejected or the last hypothesis .
4.4. Holm, Sidak, and Simes Procedures
Holm method is a step-down procedure (29). First, it ranks all the observed p-values from smallest to largest P(1), P(2), …, P( J) Compare each Pj to starting from the smallest P(1). Let the first occurrence of be the kth ordered p-value. Then hypotheses corresponding to the first k − 1 p-values P( 1 ), …, P( k −1) will be rejected and the hypotheses from the kth one on corresponding to P( k), …, P( J) will not be rejected. Alternatively, researchers can also compute the Holm’s adjusted p-values and compare them to α. The adjusted p-values is based on the ordered p-values P(1), P(2), …, P( J) and where ∧ denotes taking the minimum. The adjusted p-values are capped at 1 by taking the minimum of and 1. Besides, the jth adjusted p-value is the maximum in the first j values, resulting in non-decreasing sequence of adjusted P-values.
The Sidak (30) correction assumes that the J test statistics are mutually independent and replaces the element-wise p-value cutoff α/J by . It is less conservative than the Bonferroni correction because for n ≥ 1. Another set of thresholds combining the Holm threshold and Sidak correction, , also maintains FWER at α.
Simes (31) procedure is also a step down procedure that rejects H0 j when . Here P(1), P(2), …, P( J) are the ordered P-values from smallest to largest. Hochberg and Liberman (32) extended the Simes procedure by allocating different weights to the P-values depending on prior information on each hypothesis.
5. A Real Case: Genomic Studies Based on a Clinical Trial
We illustrate the stepwise procedures using the Genome Wide Association Study (GWAS) from the Diabetes Control and Complications Trial (DCCT) and Epidemiology of Diabetes Intervention and Complication (EDIC) trial. DCCT and EDIC are two clinical trials based on the same type 1 diabetes cohort in different time periods. The survival rate and life expectancy of type 1 diabetic patients have been improved greatly in recent years. However, chronic hyperglycemia status leads to deleterious changes in blood vessels. Cardiovascular diseases and microvascular complications are major threats to the long-term quality of life of type 1 diabetic patients. This study focuses on microvascular complications among type 1 diabetic patients. In EDIC, 1441 Type 1 diabetic patients enrolled from 1983 to 1989. They were randomized to either the intensive or conventional therapies, where participants in the intensive group monitored and regulated their blood glucose level constantly. DCCT ended in 1993 when significant reduction in the risk of microvascluar complications was found in the intensive therapy group (33). Of the 1441 DCCT participants, 1394 continued to the EDIC trial, where everyone receives the intensive therapy.
The abnormalities in the capillaries lead to symptoms in different parts of the body – nephropathy, retinopathy, and neuropathy. The goal of this analysis is to validate fourteen SNPs associated with severe nephropathy and persistent microalbuminuria in Al-Kateb et al. (34). Urine glomerular filtration rates (GFR), which is an important clinical index of diabetic nephropathy, have been recorded annually in the DCCT/EDIC cohort. Log-transformed GFR values are employed as our main outcome. Linear regressions of the last GFR observation versus each of the fourteen SNPs are fitted, adjusting for age at randomization, gender and duration of diabetes at enrollment, stratified by the treatment group. Different SNP coefficients are assumed in the intensive and conventional treatment groups because patients under the two treatments were in quite different biophysical and metabolic statuses and the intensive control of the glucose level might suppress or activate SNP effects. Among the global tests for SNP effects in different strata, the SUM test is employed as the effects for each SNP are expected to be in the same direction across the two strata and the SUM test is the maxmin test under such conditions.
Fourteen raw P-values are generated from the SUM tests, one for each SNP. To maintain the family wise Type I error rate or false discovery rate, four different stepwise procedures are performed – Bonferroni, Sidak, Hochberg, and FDR. All four procedures are directly available in SAS package “multtest.” P-values of various procedures are listed in Table 6. We can see that although some raw P-values are <0.05, none of the adjusted P-values remain significant. That is, after FWER is controlled, the seemingly significant results are not actually significant any more. Among the procedures controlling FWER, the Sidak and Hochberg procedures give smaller adjusted P-values and therefore are more powerful than the Bonferroni adjustment. Although researchers usually require the FWER no larger than 0.05, they might set higher cutoff value of FDR depending on the context of the research problem.
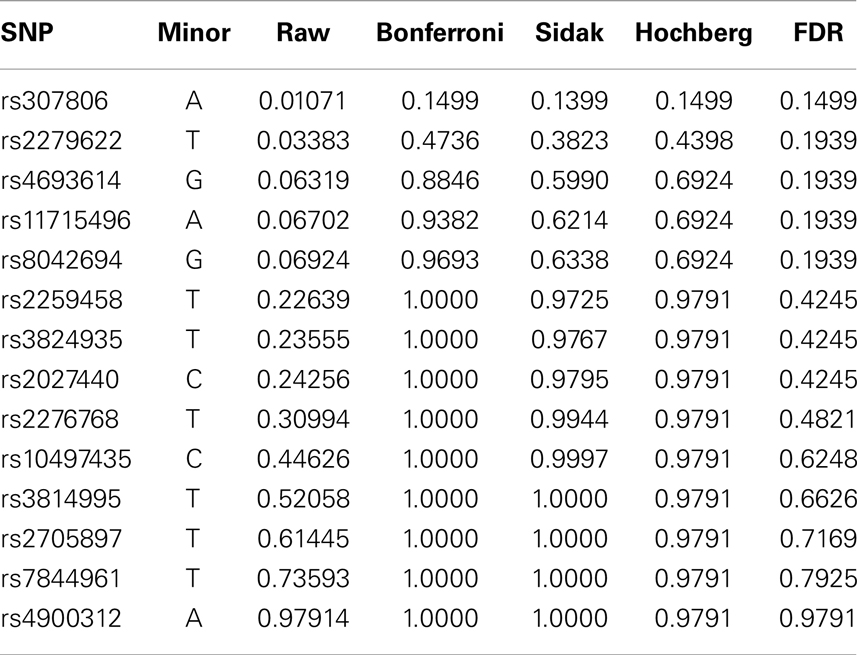
Table 6. Real data analysis: association between log(GFR) and 14 SNPs.
6. Discussion
This manuscript reviews methods for the multiple hypothesis testing problem. Five global tests widely used in clinical trials are reviewed: SUM test, Two-Step test, ALRT, IUT, and the MAX Test. The plots of the rejection regions illustrate the different alternatives to which the tests are directed. The SUM and Two-Step tests are powerful for alternatives with homogeneous effects. Two-Step test can be viewed as a modification of the SUM test that incorporates information on how different the treatment effects are and thus more sensitive to non-homogeneous treatment effects. ALRT is robust to not only unequal treatment effects but also unequal sample sizes from the endpoints. MAX test is also robust for non-homogeneous treatment effects. IUT provides information about the overall superiority and individual non-inferiority. In genomic studies, specific conclusions on individual hypotheses are desired and stepwise procedures are commonly used to control FWER or FDR. The Westfall and Young’s resampling method generates the joint distribution of P-values under the null and maintains the correlation structure between them. A selected SNP dataset from a clinical trial is used to illustrate the stepwise procedures. Finally, among the hundreds of papers on multiple hypothesis testing topic, only a selected few commonly used multiple hypothesis testing adjustment methods are reviewed here. Our goal is to introduce the classical methods and present the ideas behind them. They serve as the basis on which researchers may choose and develop their own method with careful consideration of the particular research setup and clinical questions.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The author thanks Professor John Lachin and Professor Joseph Gastwirth for many helpful discussions. We also wish to thank the EDIC research group for access to the GFR and GWAS data. This publication was supported by Award Numbers UL1TR000075 and KL2TR000076 from the NIH National Center for Advancing Translational Sciences. Its contents are solely the responsibility of the authors and do not necessarily represent the official views of the National Center for Advancing Translational Sciences or the National Institutes of Health. This study was approved by the IRB office at George Washington University.
References
1. Logan BR, Tamhane AC. Combined global and marginal tests to compare two treatments on multiple endpoints. Biomed J (2001) 43:591–604. doi: 10.1002/1521-4036(200109)43:5<591::AID-BIMJ591>3.0.CO;2-F
2. O’Brien PC. Procedures for comparing samples with multiple endpoints. Biometrics (1984) 40:1079–87. doi:10.2307/2531158
3. Tang DI, Geller NL, Pocock SJ. On the design and analysis of randomized clinical trials with multiple endpoints. Biometrics (1993) 49:23–30. doi:10.2307/2532599
4. Lauter J, Glimm E, Kropf S. New multivariate tests for data with an inherent structure. Biomed J (1996) 37:5–23.
5. Bregenzer T, Lehmacher W. Directional tests for the analysis of clinical trials with multiple endpoints allowing for incomplete data. Biomed J (1998) 40:911–28. doi:10.1002/(SICI)1521-4036(199812)40:8<911::AID-BIMJ911>3.0.CO;2-W
6. Gastwirth JL. The use of maximum efficiency robust tests in combining contingency tables and survival analysis. J Am Stat Assoc (1985) 80:380–4. doi:10.1080/01621459.1985.10478127
7. Wei LJ, Lachin JM. Two-sample asymptotically distribution free tests for incomplete multivariate observations. J Am Stat Assoc (1984) 79:653–61. doi:10.1080/01621459.1984.10478093
8. Pocock SJ, Geller NL, Tsiatis AA. The analysis of multiple endpoints in clinical trials. Biometrics (1987) 43(2):487–98. doi:10.2307/2531989
9. Frick H. A maximum linear test of normal means and its application to Lachin’s data. Comm Stat Theor Meth (1994) 23(4):1021–9. doi:10.1080/03610929408831302
10. Breslow N, Day NE. The analysis of case-control studies. Statistical Methods in Cancer Research (Vol. 1), Lyon: France, IARC Scientific Publications (1980).
11. Legler JM, Lefkopoulou M, Ryan LM. Efficiency and power of tests for multiple binary outcomes. J Am Stat Assoc (1995) 90:680–93. doi:10.1080/01621459.1995.10476562
12. Lachin JM, Wei LJ. Estimators and tests in the analysis of multiple nonindependent 2x2 tables with partially missing observations. Biometrics (1988) 44:513–28. doi:10.2307/2531864
13. Follmann D. A simple multivariate test for one-sided alternatives. J Am Stat Assoc (1996) 91:854–61. doi:10.1080/01621459.1996.10476953
14. Tang DI, Gnecco C, Geller NL. An approximate likelihood ratio test for a normal mean vector with nonnegative components with application to clinical trials. Biometrika (1989) 76:577–83. doi:10.1002/bimj.200900203
15. Tarone RE. On the distribution of the maximum of the log-rank statistics and the modified Wilcoxon statistics. Biometrics (1981) 37:79–85. doi:10.2307/2530524
16. Bloch DA, Lai TL, Tubert-Britter P. One-sided tests in clinical trials with multiple endpoints. Biometrics (2001) 57:1039–47. doi:10.1111/j.0006-341X.2001.01039.x
17. Perlman MD, Wu L. A note on one-sided tests with multiple endpoints. Biometrics (2004) 60:276–80. doi:10.1111/j.0006-341X.2004.00159.x
18. Chen JJ, Wang SJ. Testing for treatment effects on subsets of endpoints. Biomed J (2002) 44:541–57. doi:10.1002/1521-4036(200207)44:5<541::AID-BIMJ541>3.0.CO;2-0
19. Park CG, Park T, Shin DW. A simple method for generating correlated binary variates. Am Stat (1996) 50:306–10. doi:10.1080/00031305.1996.10473557
20. Zeger SL, Liang KY. Longitudinal data analysis using generalized linear models. Biometrika (1986) 73:13–22. doi:10.1093/biomet/73.1.13
21. Dunnett CW, Tamhane AC. A step-up multiple test procedure. J Am Stat Assoc (1982) 87:162–70. doi:10.1080/01621459.1992.10475188
22. Lehmacher W, Wassmer G, Reitmeir P. Procedures for two-sample comparisons with multiple endpoints controlling the experimentwise error rate. Biometrics (1991) 47:511–21. doi:10.2307/2532142
23. Storey JD, Tibshirani R. Statistical significance for genomewide studies. Proc Natl Acad Sci U S A (2003) 100(16):9440–5. doi:10.1073/pnas.1530509100
24. Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc Series B (1995) 57:289–300.
26. Troendle JF. A stepwise resampling method of multiple hypothesis testing. J Am Stat Assoc (1995) 90:370–8. doi:10.1080/01621459.1995.10476522
27. Wiens BL. A fixed sequence Bonferroni procedure for testing multiple endpoints. Pharm Stat (2003) 2:211–5. doi:10.1002/pst.64
28. Huque MF, Alosh M. A flexible fixed-sequence testing method for hierarchically ordered correlated multiple endpoints in clinical trials. J Stat Plan Inference (2008) 138:321–35. doi:10.1016/j.jspi.2007.06.009
29. Holm S. A simple sequentially rejective multiple test procedure. Scand J Stat (1979) 6(2):65–70.
30. Sidak ZK. Rectangular confidence regions for the means of multivariate normal distributions. J Am Stat Assoc (1967) 62(318):626–33. doi:10.1080/01621459.1967.10482935
31. Simes RJ. An improved Bonferroni procedure for multiple tests of significance. Biometrika (1986) 73:751–4. doi:10.1093/biomet/73.3.751
32. Hochberg Y, Liberman U. An extended Simes test. Stat Probab Lett (1994) 21:101–5. doi:10.1016/0167-7152(94)90216-X
33. The DCCT Research Group. The effect of intensive treatment of diabetes on the development and progression of long-term complications in insulin-dependent diabetes mellitus. N Engl J Med (1993) 329:977–86. doi:10.1056/NEJM199309303291401
34. Al-Kateb H, Boright AP, Mirea L, Xie X, Sutradhar R, Mowjoodi A, et al. Multiple superoxide dismutase 1/splicing factor serine alanine 15 variants are associated with the development and progression of diabetes nephropathy: the diabetes control and complications trial/epidemiology of diabetes interventions and complications genetic study. Diabetes (2008) 57:218–28. doi:10.2337/db07-1059
Keywords: false discovery rate, family wise error rate, global test, multiple hypotheses testing, resampling method, stepwise procedure
Citation: Pan Q (2013) Multiple hypotheses testing procedures in clinical trials and genomic studies. Front. Public Health 1:63. doi: 10.3389/fpubh.2013.00063
Received: 08 November 2013; Accepted: 15 November 2013;
Published online: 09 December 2013.
Edited by:
Zhiwei Zhang, Food and Drug Administration, USACopyright: © 2013 Pan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qing Pan, Department of Statistics, The George Washington University, 801 22nd Street NW, Rome Hall 665, Washington, DC 20052, USA e-mail: qpan@gwu.edu