Regularization by the Linear Functional Strategy with Multiple Kernels
 Sergei V. Pereverzyev
Sergei V. Pereverzyev Pavlo Tkachenko
Pavlo Tkachenko- Johann Radon Institute for Computational and Applied Mathematics, Linz, Austria
The choice of the kernel is known to be a challenging and central problem of kernel based supervised learning. Recent applications and significant amount of literature have shown that using multiple kernels (the so-called Multiple Kernel Learning (MKL)) instead of a single one can enhance the interpretability of the learned function and improve performances. However, a comparison of existing MKL-algorithms shows that though there may not be large differences in terms of accuracy, there is difference between MKL-algorithms in complexity as given by the training time, for example. In this paper we present a promising approach for training the MKL-machine by the linear functional strategy, which is either faster or more accurate than previously known ones.
1. Introduction
In this paper we are concerned with the so-called “supervised learning” or “learning from examples” problem, which refer to the task of predicting an output, say v ∈ V ⊂ ℝ, of a system under study from a previously unseen input u ∈ U ⊂ ℝd on the basis of the set of training examples, that is a set of input-output pairs zi = (ui, vi), i = 1, 2, …, m, observed in the same system.
A kernel based algorithm consists in learning a function x : U → ℝ in some Reproducing Kernel Hilbert Space (RKHS) X = XK generated by a suitable Mercer (continuous, symmetric and positive semidefinite) kernel K : U × U → ℝ that assigns to each input u ∈ U an output x(u). The prediction error is measured by the value of a chosen loss function l(v, x(u)), say square-loss l(v, x(u)) = (v − x(u))2.
In the context of kernel based supervised learning a regularization is a compromise between the attempt to fit given data and the desire to reduce the complexity of a data fitter x ∈ XK. For example, a Tikhonov-type kernel based learning algorithm in its rather general form defines a predictor x(u) = xz(u) = x(K; u) ∈ XK as the minimizer of the sum:
where the complexity is measured by the norm ||·||XK in RKHS generated by a kernel K, and the above-mentioned compromise is governed by the value of the regularization parameter α.
As it has been mentioned in Michelli and Pontil [1], a challenging and central problem of kernel based learning is the choice of the kernel K itself. Recent applications (see [2, 3]) have shown that using multiple kernels instead of a single one can enhance the interpretability of the predictor x(u) = x(K; u) and improve performances. In such cases, a convenient approach is to consider that the kernel K is actually a combination of predefined basis kernels:
where each basis kernel Kj may either use the full set of variables (u1, u2, …, ud) describing the input u = (u1, u2, …, ud) ∈ ℝd or subsets of variables stemming from different data sources. Defining both the minimizer x(K; u) of Tα, z(x; K) and the weights Equation (2), dj, j = 1, 2, …, p, in a single optimization problem is known as the Multiple Kernel Learning (MKL).
A generalized representer theorem by Schölkopf et al. [4] tells us that a large class of optimization problems Equation (1) with RKHS have solutions expressed as kernel expansions in terms of the training data z. More precisely, for each K = Kj, j = 1, 2, …, p, the minimizer x(Kj; u) belongs to the finite-dimensional linear subspace spanned by the functions Kj(u, ui), i = 1, 2, …, m. Therefore, MKL-predictor xz(u) can be written as:
There is a significant amount of work in the MKL-literature. For example, the survey [5] reviews a total of 96 references. A comparison of existing MKL-algorithms performed in that survey shows that through there may not be large differences in terms of accuracy, there is difference between MKL-algorithms in complexity as given by the training time, for example.
Similar accuracies of different MKL-algorithms can be, at least partially, explained by the fact that all minimizers xj(Kj; ·) of Equation (1) for K = Kj, j = 1, 2, …, p belong to the direct sum XK+ of RKHS XKj, j = 1, 2, …, p, and a classical result [6] says that XK+ is a RKHS generated by the kernel K+ = K1 + K2 + … +Kp.
The differences in training time originate from different optimization algorithms used for learning the weights dj, j = 1, 2, …, p. The so-called one-step methods calculate both the combination weights dj, j = 1, 2, …, p and the parameters of the minimizer x(K; u) in a single run. However, these methods use optimization approaches, such as semi-definite programming (SDP) [7], second order conic programming (SOCP) [8], or quadratically constrained quadratic programming (QCQP) [9], which have high computational complexity especially for large number of samples.
Two-step, or wrapper methods address the MKL-problem by iteratively solving a single learning problem, such as Equation (1), for a fixed combination of basis kernels, and then update the kernel weights. Such methods run usually much faster than the one-step methods and therefore there is a rich variety of them. Just to mention some of them we refer to Semi-Infinite Linear Program (SILP) approach [10], SimpleMKL method [11] performing a reduced gradient descent on the kernel weights, LevelMKL algorithm [12], HessianMKL [13], replacing the gradient descent in SimpleMKL by the Newton update, and some others [1, 14].
The time complexity of these two-step methods depends on the number of iterations of an algorithm until the stopping criterion is fulfilled. In this context our idea is to use the so-called Linear Functional Strategy (LFS) [15], originally proposed for single-kernel ranking learning, allowing to find the coefficients of the linear combination in one step by using the given training set. In this paper we extend this idea to the MKL setting, namely we analyze the linear functional strategy for combining the xj(Kj; u) ∈ XKj into a new predictor.
The paper is organized as follows: in the next section we present the main theoretical results. Then, we compare the proposed method with two other MKL-learning approaches, namely SimpleMKL and SpicyMKL [16]. Finally, we discuss some open questions and further research directions.
2. Main Results
If we accept the basic statistical learning assumptions, namely that the inputs u and the outputs v are assumed to be related by a conditional probability distribution ρ(v|u) of v given u, and the input u is also assumed to be random and governed by an unknown marginal probability ρU on U so that there is an unknown probability distribution ρ(u, v) = ρU(u)ρ(v|u) on the sample space U × V from which the data forming the training set are drawn independently, then the “ideal predictor” x† is assumed to belong to the space X = L2(U, ρU) of square integrable functions with respect to ρU and can be defined as the element minimizing the expected prediction risk:
Moreover, in such set-up x† can be written explicitly in the form:
As one can see from the above formula, x† cannot be used in practice, since the conditional probability ρ(v|u) is not assumed to be known.
Our idea is to construct a MKL-predictor Equation (3) in the form:
where cj are the unknown coefficients. It is clear that the best choice of the coefficient vector should minimize the distance:
and it is easy to see that such solves the following linear system of equations:
with the Gram matrix and the right-hand-side vector . Clearly, the right-hand side g is inaccessible due to the involvement of the unknown predictor x†. Furthermore, the components of the matrix G are not accessible, since the measure ρU is also unknown.
To simplify further discussion, we assume that , which is not a big restriction if at least one of Kj is the so-called universal kernel [17], and consider the inclusion operator I+ of XK+ into L2(U, ρU) and the sampling operator defined by . Then under rather general assumptions (see 18) with high probability 1 − η we have:
where , are adjoints of Sz and I+; v = (v1, v2, …, vm) is the vector of the outputs used for training; c1, c2 are certain multipliers which do not depend on m, η.
With the use of Equation (7) we can approximate the components of the vector g and the Gram matrix G as:
In view of these relations, we state the main result of this section through the following theorem:
Theorem 1. Let and Kj(u, u) ≤ c, u ∈ U, j = 1, 2, …, p. Consider
and assume that is invertible. Then for MKL-approximant:
with confidence 1 − η it holds:
where a coefficient implicit in O-symbol does not depend on m.
Proof. Formulas (8, 9) tells us that with confidence 1 − η it holds:
If exists then in view of (11) it is natural to assume that for sufficiently large m with confidence 1 − η we have:
This assumption allows the application of the well-known Banach theorem on inverse operators (see 19, V. 4.5), which tells that:
Consider the vectors . Then from (11) to (13) it follows that:
and
Moreover, since xj(Kj; ·) is the minimizer of Equation (1) for K = Kj and l(v, x(u)) = (v − x(u))2, from Proposition 4.1 [20] it follows that ||xj(Kj; ·)||L2(U, ρU) are uniformly bounded such that for α from the range of interest, i.e., for α ≥ m−1, we have , where and does not depend on m, j.
Then the statement of the theorem follows from (14) to (15). □
Remark 1. In Theorem 1 the Gram matrix is supposed to be well-conditioned. In principle, one may control this by excluding those members of the family {xj(Kj; u), j = 1, 2, …, p} that are close to be linear dependent of others. A preconditioning method for such a control has been discussed, for example, in Chen et al. [21] (see Remark 3.1 there).
Theorem 1 tells us that the effectively constructed linear combination of the candidates xj(Kj; ·), j = 1, 2, …, p, is almost as accurate as the best linear aggregator of them.
A simple algorithmic sketch of such almost the best aggregator is provided below:

Algorithm of the Linear Functional Strategy for MKL
In the next Section we present some numerical experiments illustrating the performance of the proposed algorithm. We will denote the MKL-predictor Equations (4), (10) constructed via linear functional strategy (LFS) in the above mentioned way by MKL-LFS.
3. Numerical Illustrations
It is interesting to compare MKL-LFS with the other two MKL-algorithms, named SimpleMKL and SpicyMKL, that have been proposed respectively in Rakotomamonjy et al. [11] and Suzuki and Tomioka [16]. We choose the first one, SimpleMKL, for comparison, because the experimental results reported in Rakotomamonjy et al. [11] show that this algorithm converges rapidly and that its efficiency compares favorably to other MKL algorithms. It is also important that a SimpleMKL toolbox based on Matlab code is available at http://www.mloss.org and, therefore, we are able to put MKL-LFS and SimpleMKL side by side. Moreover, the second competitor, SpicyMKL, uses SimpleMKL on the set-up stage.
The second algorithm, SpicyMKL, has been chosen because it is reported to be the fastest one among all other algorithms, and in particular, much faster than SimpleMKL.
To perform the comparison of SimpleMKL and SpicyMKL with MKL-LFS, we use the same experimental set-up as in Rakotomamonjy et al. [11]. More precisely, the performance evaluation is made on five data sets from the UC Irvine Machine Learning Repository: Liver, Wpbc, Ionosphere, Pima, Sonar. For each data set, the compared algorithms were run 20 times with train and test sets selected differently for each run by SimpleMKL toolbox (70% of the data set for training and 30% for testing the performance).
The SpicyMKL algorithm has been tuned in order to run its fastest version, namely with the logistic regression loss and elastic net regularization. The tuning parameters were taken the same as suggested in Suzuki and Tomioka [16].
The candidate kernels Kj, j = 1, 2, …, p are the Gaussian kernels with 10 different bandwidths, on all variables u = (u1, u2, …, ud) and in each single variable uj, j = 1, 2, …, d; these kernels are accompanied by the polynomial kernels of degree 1–3, again on all and on each single variable. So, the number p of kernel candidates depends on the dimension d of the input variable u = (u1, u2, …, ud). For each of the considered data sets the value p is indicated in Table 1.
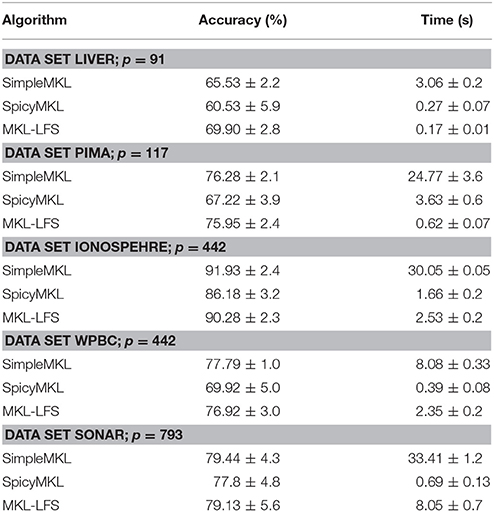
Table 1. Average performance measures for SimpleMKL, SpicyMKL, and MKL-LFS.
The table also reports the average values of the training time and the accuracy over 20 runs of the compared algorithms.
Since the above mentioned five data sets are associated with the classification learning task (i.e., vi = ±1), the algorithms accuracy is measured by the percentage of the correctly classified examples (i.e., when sign(x(u)) = sign(v)) from the part of the data set that has not been used for training.
Table 1 shows that SimpleMKL and MKL-LFS are nearly identical in the performance accuracy, while SpicyMKL is less effective against this criterion. If we look at the computation time reported in Table 1, clearly, on all data sets MKL-LFS is much fasted than SimpleMKL. On the other hand, SpicyMKL is faster than two other algorithms on the sets, where the number of kernels is large, but the size of the training set is moderate. The same feature was observed in Suzuki and Tomioka [16]: the algorithm SpicaMKL is efficient when the number of unknown variables is much larger than the number of samples. It should be noted that the MKL-LFS does not suffer from this restriction.
4. Discussion
For the purpose of comparing we follow [11] and put SimpleMKL and MKL-LFS side by side for a fixed value of the so-called hyperparameter C = 100, that corresponds to α = 1/2C = 0.005 in Equation (1). Moreover, for SpicyMKL two regularization parameters need to be selected (in our tests they are fixed as proposed in [16]). At the same time, we expect that the accuracy of MKL-LFS may be improved by combining in Equation (4) the minimizers xj(Kj; ·) of Equation (1) corresponding to different α = α(Kj), which are properly chosen for each K = Kj, j = 1, 2, …, p. We will derive such an algorithm in the near future end expect that the speed gain observed in Table 1 for MKL-LFS allows us to implement such a posteriori choice of α effectively in time.
Moreover, our method, in principle, is not restricted to Tikhonov-type regularizations only, which is known to be affected by saturation [22]. One may potentially use any of the regularization methods, such as Landweber iteration, for example, for computing the predictors xj(Kj, ·). In view of this, we plan to develop in the near future the MKL algorithm based on the so-called general regularization framework for learning [20].
Author Contributions
All authors listed, have made substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
The authors gratefully acknowledge the support of the Austrian Science Fund (FWF), project I1669, and of the consortium AMMODIT funded within EU H2020-MSCA-RICE.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1. Michelli CA, Pontil M. Learning the kernel function via regularization. J Mach Learn Res. (2005) 6:1099–1125.
2. Lanckriet GRG, De Bie T, Cristianini N, Jordan MI, Noble WS. A statistical framework for genomic data fusion. Bioinformatics (2004) 20:2626–35. doi: 10.1093/bioinformatics/bth294
3. Wu Q, Ying Y, Zhou DX. Multi-kernel regularized classifiers. J Complex. (2007) 23:108–34. doi: 10.1016/j.jco.2006.06.007
4. Schölkopf B, Herbrich R, Smola AJ. A Generalized Representer Theorem. Comput Learn Theory Lect Notes Comput Sci. (2001) 2111:416–26. doi: 10.1007/3-540-44581-1_27
6. Aronszajn N. Theory of reproducing kernels. Trans Am Math Soc. (1950) 68:337–404. doi: 10.1090/S0002-9947-1950-0051437-7
7. Lanckriet GRG, Cristianini N, Bartlett P, Ghaoui LE, Jordan MI. Learning the kernel matrix with semidefinite programming. J Mach Learn Res. (2004) 5:27–72.
8. Bach FR, Lanckriet GRG, Jordan MI. Multiple kernel learning, conic duality, and the SMO algorithm. In: Proceedings of the Twenty-first International Conference on Machine Learning. ICML '04. New York, NY: ACM (2004). p. 6. Available online at: http://doi.acm.org/10.1145/1015330.1015424
9. Conforti D, Guido R. Kernel based support vector machine via semidefinite programming: application to medical diagnosis. Comput Oper Res. (2010) 37:1389–94. doi: 10.1016/j.cor.2009.02.018
10. Sonnenburg S, Rätsch G, Schäfer C, Schölkopf B. Large scale multiple kernel learning. J Mach Learn Res. (2006) 7:1531–65.
12. Xu Z, Jin R, King I, Lyu MR. An extended level method for efficient multiple kernel learning. In: Proceedings of the 21st International Conference on Neural Information Processing Systems. NIPS'08. Curran Associates Inc. (2008). p. 1825–32. Available online at: http://dl.acm.org/citation.cfm?id=2981780.2982009
13. Chapelle O, Rakotomamonjy A. Second order optimization of kernel parameters. In: Kernel Learning Workshop: Automatic Selection of Optimal Kernels. (2008). Available online at: http://www.cs.nyu.edu/learning_kernels/abstracts/nips_wshp.pdf
14. Naumova V, Pereverzyev SV, Sivananthan S. Extrapolation in variable RKHSs with application to blood glucose reading. Inverse Prob. (2011) 27:13. doi: 10.1088/0266-5611/27/7/075010
15. Kriukova G, Panasiuk O, Pereverzyev SV, Tkachenko P. A linear functional strategy for regularized ranking. Neural Netw. (2016) 73:26–35. doi: 10.1016/j.neunet.2015.08.012
16. Suzuki T, Tomioka R. SpicyMKL: a fast algorithm for Multiple Kernel Learning with thousands of kernels. Mach Learn. (2011) 85:77–108. doi: 10.1007/s10994-011-5252-9
18. Vito ED, Rosasco L, Caponnetto A, Giovannini UD, Odone F, Vito D, et al. Learning from examples as an inverse problem. J Mach Learn Res. (2005) 6:883–904.
20. Lu S, Pereverzyev SV. Regularization Theory for Ill-Posed Problems–Selected Topics. Berlin; Boston: Walter de Gruyter GmbH (2013).
21. Chen J, Pereverzyev SS, Xu Y. Aggregation of regularized solutions from multiple observation models. Inverse Prob. (2015) 31:075005. doi: 10.1088/0266-5611/31/7/075005
Keywords: linear functional strategy, Multiple Kernel Learning, regularization, supervised learning, kernel learning
Citation: Pereverzyev SV and Tkachenko P (2017) Regularization by the Linear Functional Strategy with Multiple Kernels. Front. Appl. Math. Stat. 3:1. doi: 10.3389/fams.2017.00001
Received: 14 December 2016; Accepted: 20 January 2017;
Published: 03 February 2017.
Edited by:
Ding-Xuan Zhou, City University of Hong Kong, ChinaCopyright © 2017 Pereverzyev and Tkachenko. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sergei V. Pereverzyev, sergei.pereverzyev@oeaw.ac.at