 Oksana Lukjancenko
Oksana Lukjancenko David W. Ussery
David W. Ussery- 1Department of Systems Biology, Center for Biological Sequence Analysis, Technical University of Denmark, Lyngby, Denmark
- 2Comparative Genomics Group, Oak Ridge National Laboratory, Biosciences Division, Oak Ridge, TN, USA
We have compared chromosome-specific genes in a set of 18 finished Vibrio genomes, and, in addition, also calculated the pan- and core-genomes from a data set of more than 250 draft Vibrio genome sequences. These genomes come from 9 known species and 2 unknown species. Within the finished chromosomes, we find a core set of 1269 encoded protein families for chromosome 1, and a core of 252 encoded protein families for chromosome 2. Many of these core proteins are also found in the draft genomes (although which chromosome they are located on is unknown.) Of the chromosome specific core protein families, 1169 and 153 are uniquely found in chromosomes 1 and 2, respectively. Gene ontology (GO) terms for each of the protein families were determined, and the different sets for each chromosome were compared. A total of 363 different “Molecular Function” GO categories were found for chromosome 1 specific protein families, and these include several broad activities: pyridoxine 5' phosphate synthetase, glucosylceramidase, heme transport, DNA ligase, amino acid binding, and ribosomal components; in contrast, chromosome 2 specific protein families have only 66 Molecular Function GO terms and include many membrane-associated activities, such as ion channels, transmembrane transporters, and electron transport chain proteins. Thus, it appears that whilst there are many “housekeeping systems” encoded in chromosome 1, there are far fewer core functions found in chromosome 2. However, the presence of many membrane-associated encoded proteins in chromosome 2 is surprising.
Introduction
The Vibrio genus represents a large subgroup of Gamma subdivision of Proteobacteria, which are abundant, fast growers that can be highly variable. These bacteria have the ability to form biofilm on biotic and abiotic surfaces and are ubiquitous in marine and estuarine environments at notably high densities in fish, corals, shrimps, plankton, and mammals (Thompson et al., 2004; Reen et al., 2006; Froelich et al., 2013). Currently, the Vibrio genus contains more than 60 different species, although complete genome sequences are available for only 10 of them. Several species are known to be pathogenic for humans, fishes, and marine invertebrates, and are well studied. V. cholerae can act as the causative agent of the severe and sometimes lethal disease, cholera, and is probably the most sequenced and clinically important member of Vibrio species (Heidelberg et al., 2000; Egan and Waldor, 2003). V. vulnificus causes septicemia in wound infections; however, despite its high fatality rate, human infections of V. vulnificus are rare (Matsuoka et al., 2013; Tsao et al., 2013). V. parahaemolyticus and V. furnissii infections may lead to gastroenteritis in humans via consumption of raw seafood (Tanabe et al., 2011; Xiang et al., 2013). Strains of V. anguillarum species are life threatening to many economically important fish, including Atlantic salmon, seabass, cod, and rainbow trout (Wiik et al., 1995). V. fischeri participates in beneficial symbioses with many marine organisms, especially squids (Verma and Miyashiro, 2013). V. harveyi causes luminous vibriosis, which infects prawns, oysters, and lobsters (Yu et al., 2013). Finally, V. splendidus is known as an extensive bivalve pathogen (Tanguy et al., 2013).
All known Vibrios have two chromosomes; the presence of two chromosomes in V. cholerae was first documented in 1998 (Trucksis et al., 1998). Chromosome 1 is usually larger, with a relatively constant size of about 3 million base pairs, encoding around 2700 proteins that represent many essential functions. In contrast, chromosome 2 is smaller, about 1 million base pairs encoding roughly a thousand proteins, and contains a highly variable “super-integron” (Rowe-Magnus et al., 1999). Vibrio genomes contain many genomic islands, which can contain functions allowing adaptation to specific environments and, perhaps, can even represent speciation events (Vesth et al., 2010).
The existence of two chromosomes in all Vibrio genomes, and variance of chromosome 2, has been the main point of many investigations worldwide and has been the subject of multiple discussions about the purpose and origin of smaller chromosomes. It has been proposed that chromosome 2 originated as a megaplasmid, although later Heidelberg et al. have suggested that it may play an important role in the organism and could help optimize the fast replication rate (Okada et al., 2005; Reen et al., 2006; Kirkup et al., 2010; Dikow and Smith, 2013).
The aim of this study is to compare Vibrio chromosome specific genes, as well as the conserved core-genome and pan-genomes, across more than 300 strains of the Vibrio genus, both complete and available draft genomes, as well as to focus on distribution of functional proteins and available Gene Ontology information between two chromosomes.
Materials and Methods
Selection and Characteristics of Bacterial Strains
A set of all publically available Vibrio strains was selected for this study and downloaded from the NCBI web pages (July 2012). The initial set included 368 genomes, 18 of them were complete and 350 were retrieved as Illumina raw reads from the NCBI Sequence Read Archive (SRA). Of these, 188 genomes were sequenced using a HiSeq 2000 sequencer and the remaining 162 were sequenced with an Illumina Genome Analyzer II.
Protein encoding gene predictions were carried out using the gene-finding tool Prodigal (Hyatt et al., 2010). 16S ribosomal RNA sequences were extracted for both the complete and the draft Vibrio genomes using RNAmmer (Lagesen et al., 2007). For each assembled genome, the number of fragments (contiguous pieces), protein coding genes, and the mean gene length were calculated; strains with an average gene length below 700 bp were excluded from further analysis. The resulting set consisted of 18 complete genomes, (Table 1), and 284 draft sequences (Table S1). The distribution of these characteristics for each genome is shown in Figure 1. Note that on average there are about 7 or 8 rRNA operons per complete Vibrio genome, although in most draft genomes only one copy is given.
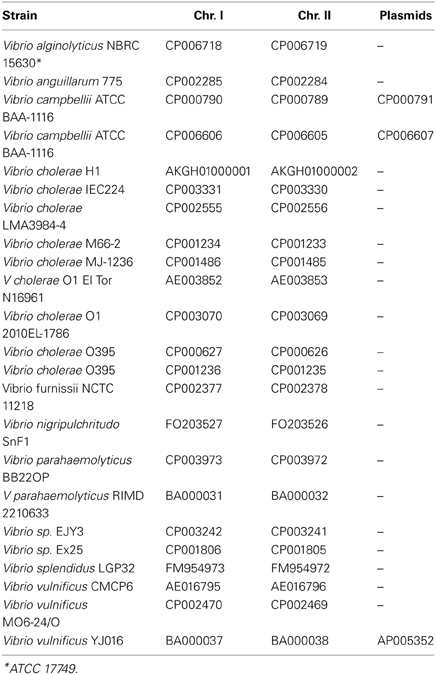
Table 1. List of species used in the study.
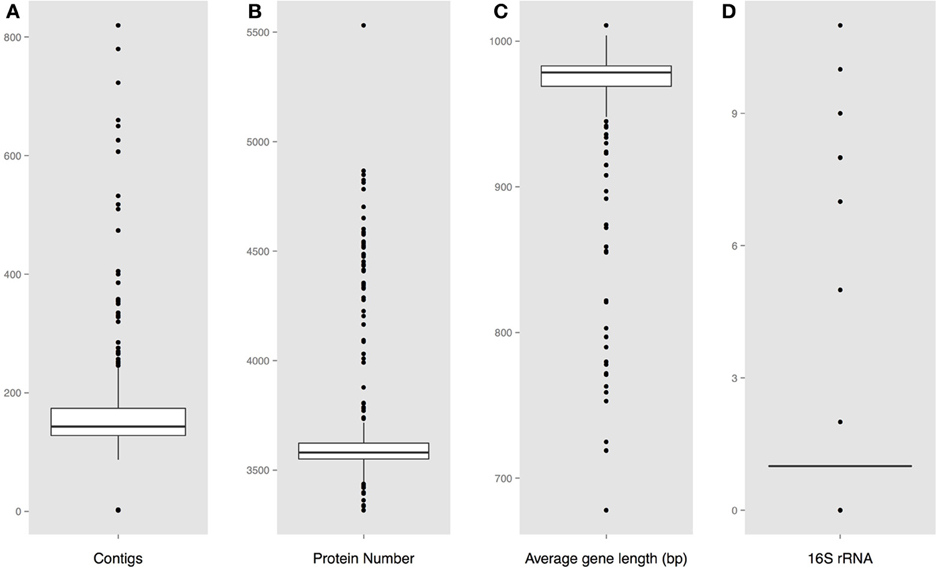
Figure 1. Predicted genome characteristics (A). Distribution of the number of contiguous pieces (B). Distribution of the protein number per genome (C). Distribution of the average protein coding gene length per genome (D). Number of predicted 16S rRNA sequences.
Proteome Comparison
Proteome comparison was performed with the PanFunPro tool (Lukjancenko et al., 2013). Briefly, protein-encoding sequences from each genome were extracted and annotated as described by Lukjancenko et al. (2013) and grouped into protein families. Results of pan- and core-genome analysis for chromosomes 1 and 2 were visualized as an accumulative pan-/core-plot and a pairwise comparison matrix.
The distribution of unique functional profiles between the chromosomes 1 and 2 was examined, followed by a brief investigation of available GO functional categories, specific for each of the chromosomes.
One representative proteome for each species was chosen from the pool of complete genomes and interspecies analysis of specific-genomes was performed between each pair of species. The results were visualized as a specific-matrix.
Results and Discussion
The Vibrio dataset consisted of 302 genomes, representing 9 known and 2 unknown Vibrio species. A list of the species and accession numbers for the complete genomes is shown in Table 1, and a similar list for all 302 genomes is given in Table S1. Only 18 of the strains were completely finished, and for those independent proteomes for both chromosomes 1 and 2 were extracted. However, most of the genomes (284) were draft and partially assembled into several large pieces of continuous chromosomal DNA, although information concerning which protein belongs to which chromosome was not available. Thus, it was decided to build analysis around 2 sets: the finished genomes (18 genomes) and the whole dataset, including the WGS draft genomes (302 genomes).
The calculated basic features for each analyzed genome is shown in Figure 1, including the number of contiguous pieces, predicted protein coding genes, average gene lengths, and predicted 16S rRNAs. A large fraction of the assembled genomes contain between 150 and 190 contiguous pieces (contigs) of chromosomal DNA, with a group of outlier strains showing more than 200 pieces per genome. An obvious correlation can be seen between the number of contigs and the amount of predicted rRNAs and genes, followed by a shorter than average gene length in assembled genomes with higher numbers of contiguous sequences.
Vibrio cholerae Chromosome 1 and Chromosome 2 Comparison
The Vibrio cholerae chromosome 1 is larger (about 3 Mbp) and is more stable, carrying many essential protein coding genes, whereas chromosome 2 is smaller (about 1 Mbp), contains a large genomic island (the “superintegron”), is more variable, and has fewer essential genes. A pairwise comparison of set of 18 genomes for both chromosomes is shown in Figure 2. Chromosomes 1 and 2 share a bit more than 10% of their protein families. Within chromosome 1 the range is 55 to 96%, and for chromosome 2 it is 25 to 95%. Since there are multiple genome sequences for several different strains available for the V. cholerae species, a high similarity within chromosomes can be found with confidence, although on average only 10% of the proteins are shared between chromosomes 1 and 2.

Figure 2. Vibrio chromosome comparison. Comparison was performed for set of 18 genomes. The blue and green square boxes represent chromosomes 1 and 2, respectively. The red-colored box in the middle of the figure indicates inter-chromosomal comparison of V. cholerae species, and the black-colored triangles highlight similarities within the same chromosome of the species.
The core-genome of complete strains contains 1269 conserved protein families shared within chromosome 1, and 252 core families shared within chromosome 2; only 104 functional profiles are shared between the two chromosomes. When additional draft genomes were included, the numbers for both chromosome 1 and 2 dropped to 673 core-genomes and 140 protein families, followed by a decrease of shared functional profiles for a total number of 96. The core- and pan-genome summary results are shown in Table 2 and conserved profiles and their functions in Table S2.
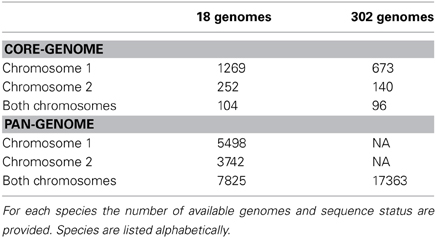
Table 2. List of species analyzed in this study.
The pan genome for chromosome 1 (~5500 gene families) is about twice the number of genes encoded in a single copy of chromosome 1 (e.g., 2650 genes in V. cholerae strain M66-2), whilst the pan-genome for chromosome 2 (~3740 gene families) is more than three times the size found encoded in a single copy of chromosome 2 (e.g., 1043 genes for V. cholerae strain M66-2). Many of these additional gene families are likely to be found in the super-integron, which is a known variable region of chromosome 2.
A closer look at the distribution of functions within the core-genomes of two chromosomes showed that all of the shared proteins are found in the PfamA database (Figure S1) and most of them are involved in biological processes or molecular function (Figure 3). The presence of proteins involved in essential metabolic and regulatory processes in the shared genomic pool of both chromosomes is consistent with the claim that the smaller chromosome is not a plasmid, but is fundamental for growth and biological activity.
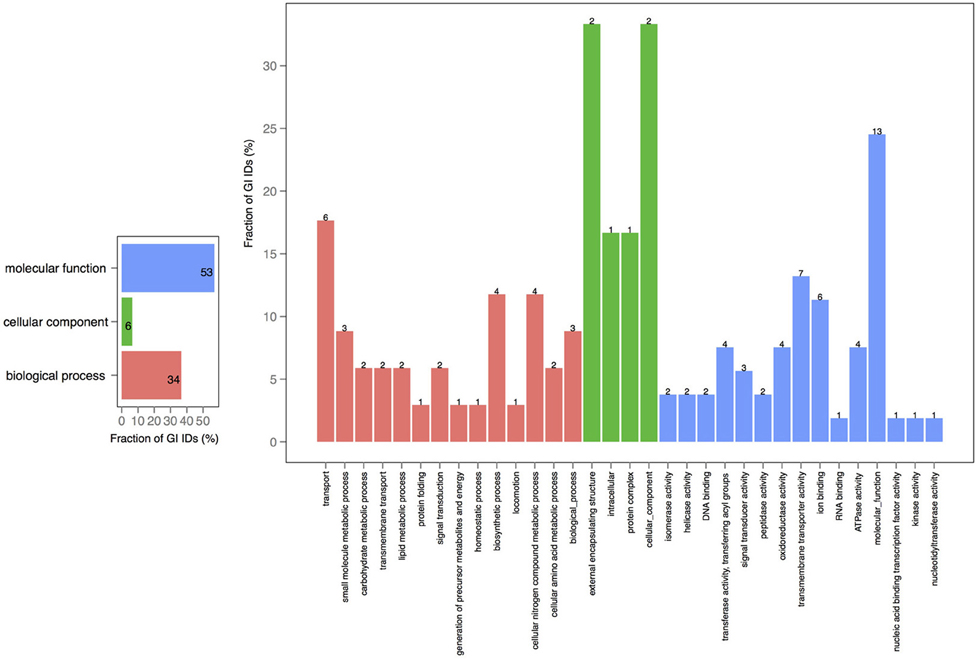
Figure 3. GO term analysis in proteins shared by chromosomes 1 and 2. The distribution is shared both as percentage on the axis and the absolute number above the bar. The absolute number reflects the amount of GO IDs that were connected to the pathway. The color code is as follows: red is the biological process, green is the cellular component, and blue is the molecular function.
In order to explore the overlap between the core genes in chromosomes 1 and 2, we extracted the core proteins for each chromosome and then examined the overlap with the core of the other chromosome (Figures 4, 5). A total number of 639 GO IDs could be extracted for the chromosome 1 core-specific profiles (1169 profiles). 438 of these were involved in biological processes, 53 in cellular component functions, and 363 in molecular functions. Equivalent analysis of chromosome 2 core-specific profiles yielded, in total, 109 GO IDs (of 153 profiles). 57 of the IDs were involved in biological processes, 10 in cellular components, and 66 in molecular functions. It is not surprising that whilst the core of chromosome 1 carries more proteins that are essential to sustain life and to reproduce, the specific core of chromosome 2 contains proteins involved in metabolic processes and enzyme and membrane associated activity. The addition of 284 draft genomes slightly reduced the number of specific proteins and specific pathway groups in chromosome 1, leaving 265 GO terms involved in the biological process, 39 in cellular component functions, and 197 in molecular functions (Figure S2). In contrast, chromosome 2 contained 15 GO terms in biological processes, 4 in cellular components, and 14 in molecular functions (Figure S3).
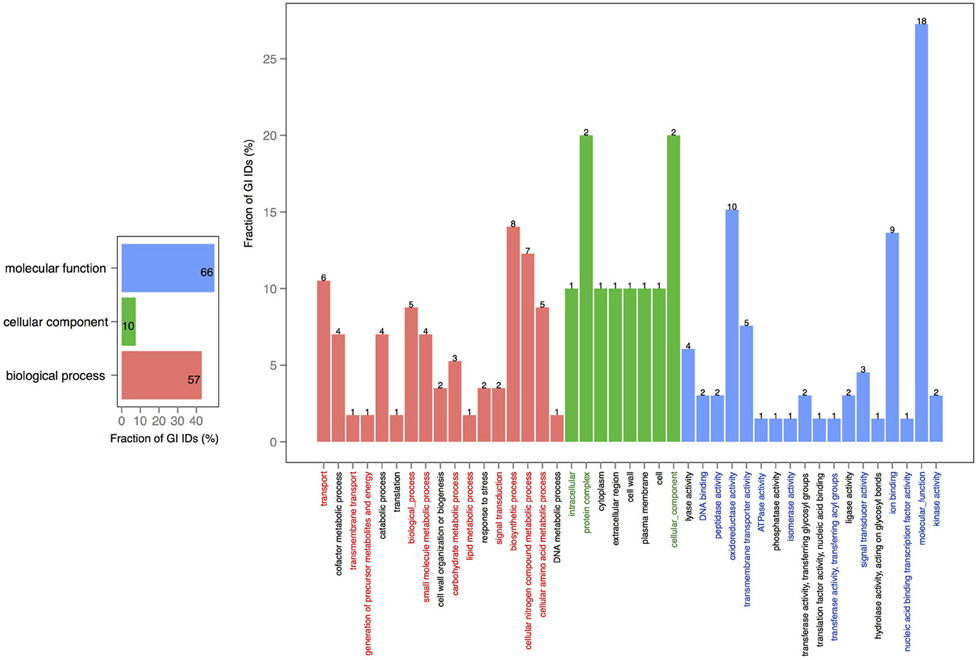
Figure 4. GO term analysis in protein coding genes shared within chromosome 1 and missing in the core of chromosome 2. The distribution is shared both as percentage on the axis and the absolute number above the bar. The absolute number shows the amount of GO IDs that were connected to the pathway. The color code is as follows: red is the biological process, green is the cellular component, and blue is the molecular function.
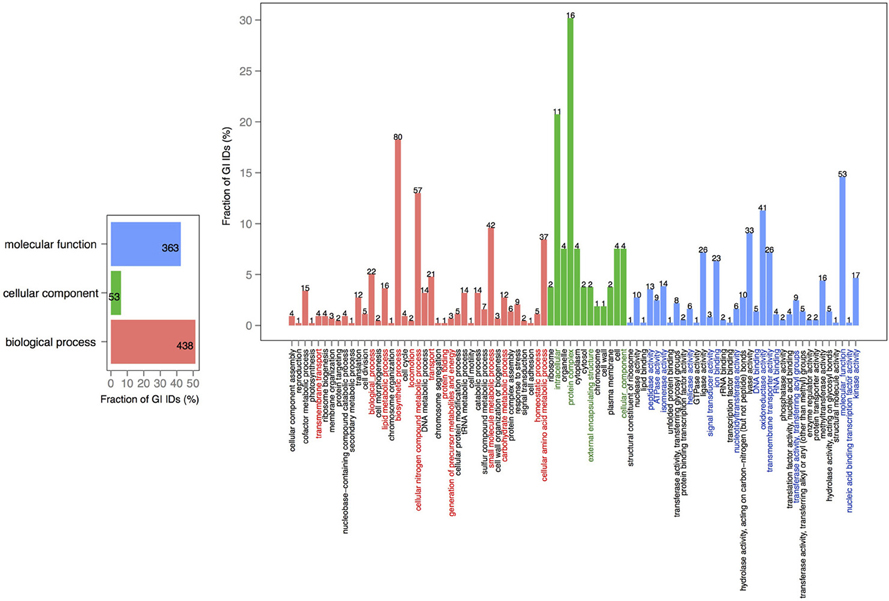
Figure 5. GO term analysis in protein coding genes shared within chromosome 2 and missing in the core of chromosome 1. The distribution is shared both as percentage on the axis and the absolute number above the bar. The absolute number shows the amount of GO IDs that were connected to the pathway. The color code is as follows: red is the biological process, green is the cellular component, and blue is the molecular function.
Species Comparison
The genus Vibrio is comprised of a diverse group of bacteria, which can be either pathogenic or symbiotic to mammals and organisms of marine environments. Species-specific genomes may contain proteins responsible for pathogenicity or they may be crucial for survival in a given environment. To demonstrate the level of specificity between species of the same chromosome, 9 strains representing 7 known and 2 unknown species, a pairwise comparison of specific-genomes, was performed. Within chromosome 1, the fraction of unique proteomes varies from 18 to 33% (Figure 6A), whereas genomes of chromosome 2 differ in a greater portion of proteins, ranging from 18 to 64% (Figure 6B).
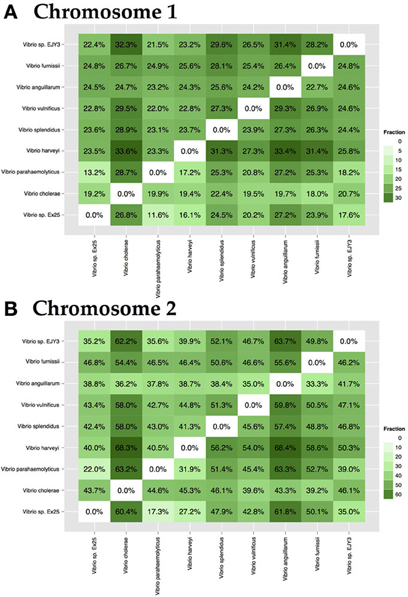
Figure 6. Pairwise interspecies-specific genome comparison for chromosome 1 (A) and chromosome 2 (B). Analysis included a single representation of 7 known and 2 unknown species. The resulting percentage shows the ratio between the amount of species-specific families and the size of the total proteome. On average, each species contained between 18 and 33% specific protein families. Color intensity indicates the level of specificity.
Vibrio cholerae spp. are known pathogens in humans and were chosen to examine for genome specific differences in gene content. Representative strains of V. cholerae species were compared to other strains, as shown in Figure S4. Chromosomes 1 and 2 contained a similar amount of specific profiles, 190, and 192, respectively. Most of them were CD-HIT clustering-based, however, 79 and 44 were annotated by PfamA and TIGRFAM collections. A complete list of profiles and corresponding functions are listed in Table S3.
Proteomes of V. cholerae Draft Genomes
V. cholerae is one of the most important, highly documented, and most sequenced species of Vibrios. Our dataset included 279 V. cholerae strains, 8 completely sequenced and 271 draft genomes. For the draft genomes, chromosome specific genes could not be calculated. However, starting with the known core genomes from the finished genomes, it is possible to look for the presence of the known chromosome core genes across the draft genomes. Thus, core-genome analysis of 279 V. cholerae strains yielded in 776, 250, and 182 protein families, in large, small, and both of the chromosomes, respectively. Further, we examined the pan-genomes of both chromosomes within a set of 18 genomes. The distribution of the total number of 8325 functional profiles is as follows: 2333, 341 and 73 families assigned to PfamA, Superfamily, and TIGRFAM databases, respectively (Figure 7). We estimate that the 271 newly sequenced V. cholerae strains brings at least 2000 possible profile combinations to the pool of previously known functions that represent more than 70 different GO functional categories (Figure 8).
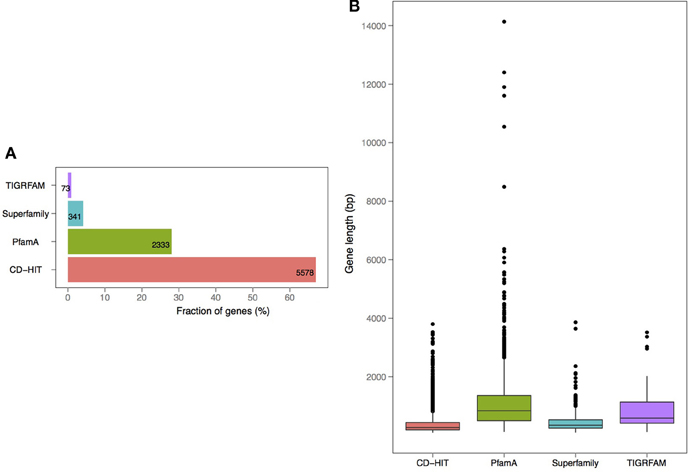
Figure 7. Annotation and length distribution of proteins within specific-proteomes in draft genomes of V. cholerae (A). Distribution of profiles by assignment source: PfamA, Superfamily, TIGRFAM, and CD-HIT clustering (B). Protein coding gene length distribution by each profile type.
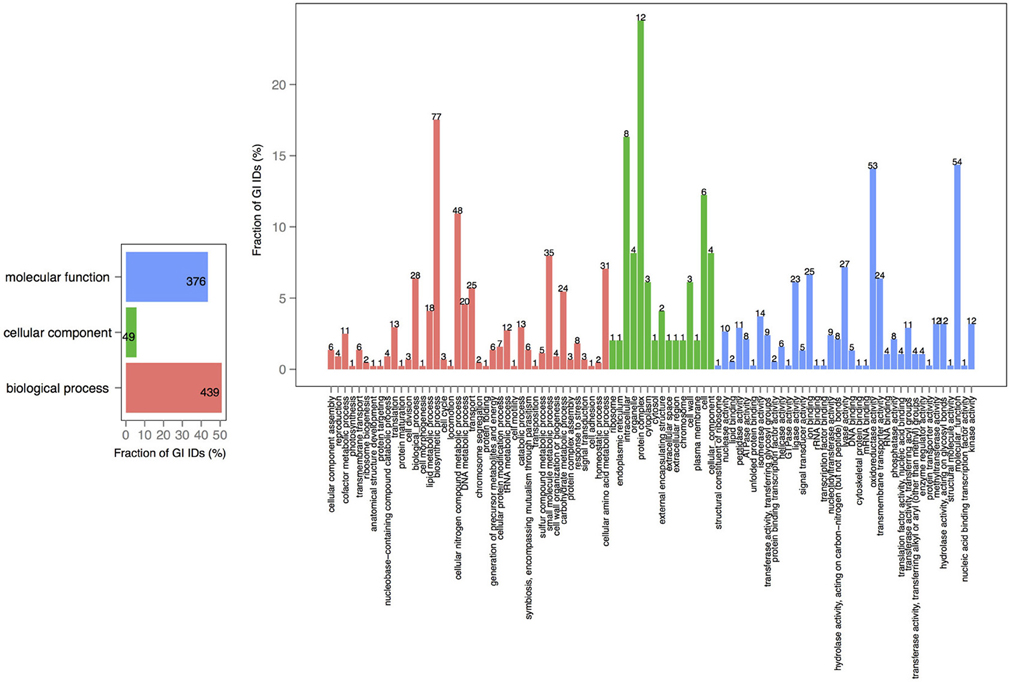
Figure 8. GO term analysis in proteins, specific to V. cholerae draft genomes. Distribution is shared both as the percentage on the axis and the absolute number above the bar. The absolute number shows the amount of GO IDs that were connected to the pathway. The color code is as follows: red is the biological process, green is the cellular component, and blue is the molecular function.
In conclusion, the Vibrio pan-genome can be quite large, with more than 17,000 gene families, although, any one Vibrio genome will contain only about 3500 genes, or about one-fifth of the size of the pan-genome. There is considerably more variability in chromosome 2 than in chromosome 1.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors are grateful to all research groups that have submitted their genome sequences to public databases, without which this analysis would not have been possible. The authors are in part supported by the Center for Genomic Epidemiology at the Technical University of Denmark; part of this work was funded by grant 09-067103/DSF from the Danish Council for Strategic Research.
Supplementary Material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fmicb.2014.00073/abstract
Figure S1 | Annotation and length distribution of proteins within core-genome of small and large chromosomes (A). Distribution of profiles by assignment source: PfamA, Superfamily, TIGRFAM, and CD-HIT clustering (B). Protein coding gene length distribution by each profile type.
Figure S2 | GO term analysis in proteins shared within chromosome 1 and missing in the core of chromosome 2 in set_302 genomes. Distribution is shared both as percentage on the axis and absolute number above the bar. Absolute number shows the amount of GO IDs that were connected to the pathway. Color code is as follows: red is biological process, green is cellular component, and blue is molecular function.
Figure S3 | GO term analysis in proteins shared within chromosome 2 and missing in the core of chromosome 1 in set_302 genomes. Distribution is shared both as percentage on the axis and absolute number above the bar. Absolute number shows the amount of GO IDs that were connected to the pathway. Color code is as follows: red is biological process, green is cellular component, and blue is molecular function.
Figure S4 | Annotation and length distribution of proteins within V. cholerae species-specific proteomes for chromosome 1 (A) and chromosome 2 (B). Annotation of profiles and protein coding gene length distribution are visualized by assignment source: PfamA, Superfamily, TIGRFAM, and CD-HIT clustering.
Table S1 | List of Sequence Read Archive (SRA) genomes used in the study.
Table S2 | Conserved functional profiles within genomes of set_18. Whether profile consists of more than 1 domain, function is shown for each domain.
Table S3 | Profiles, specific for V. cholerae species., in chromosome I and chromosome II. Whether profile consists of more than 1 domain, function is shown for each domain.
References
Dikow, R. B., and Smith, W. L. (2013). Genome-level homology and phylogeny of Vibrionaceae (Gammaproteobacteria: Vibrionales) with three new complete genome sequences. BMC Microbiol. 13:80. doi: 10.1186/1471-2180-13-80
Egan, E. S., and Waldor, M. K. (2003). Distinct replication requirements for the two Vibrio cholerae chromosomes. Cell 114, 521–530. doi: 10.1016/S0092-8674(03)00611-1
Froelich, B., Bowen, J., Gonzalez, R., Snedeker, A., and Noble, R. (2013). Mechanistic and statistical models of total Vibrio abundance in the Neuse River Estuary. Water Res. 47, 5783–5793. doi: 10.1016/j.watres.2013.06.050
Heidelberg, J. F., Eisen, J. A., Nelson, W. C., Clayton, R. A., Gwinn, M. L., Dodson, R. J., et al. (2000). DNA sequence of both chromosomes of the cholera pathogen Vibrio cholerae. Nature 406, 477–483. doi: 10.1038/35020000
Hyatt, D., Chen, G.-L., Locascio, P. F., Land, M. L., Larimer, F. W., and Hauser, L. J. (2010). Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC Bioinformatics 11:119. doi: 10.1186/1471-2105-11-119
Kirkup, B. C., Chang, L., Chang, S., Gevers, D., and Polz, M. F. (2010). Vibrio chromosomes share common history. BMC Microbiol. 10:137. doi: 10.1186/1471-2180-10-137
Lagesen, K., Hallin, P., Rødland, E. A., Staerfeldt, H.-H., Rognes, T., and Ussery, D. W. (2007). RNAmmer: consistent and rapid annotation of ribosomal RNA genes. Nucleic Acids Res. 35, 3100–3108. doi: 10.1093/nar/gkm160
Lukjancenko, O. Thomsen, M. C., Voldby Larsen, M., and Ussery, D. W. (2013). PanFunPro: PAN-genome analysis based on FUNctional PROfiles. F1000Research 2. doi: 10.12688/f1000research.2-265.v1
Matsuoka, Y., Nakayama, Y., Yamada, T., Nakagawachi, A., Matsumoto, K., Nakamura, K., et al. (2013). Accurate diagnosis and treat- ment of Vibrio vulnificus infection: a retrospective study of 12 cases. Braz. J. Infect. Dis. 17, 7–12. doi: 10.1016/j.bjid.2012.07.017
Okada, K., Iida, T., Kita-Tsukamoto, K., and Honda, T. (2005). Vibrios commonly possess two chromosomes. J. Bacteriol. 187, 752–757. doi: 10.1128/JB.187.2.752-757.2005
Reen, F. J., Almagro-Moreno, S., Ussery, D., and Boyd, E. F. (2006). The genomic code: inferring Vibrionaceae niche specialization. Nat. Rev. Microbiol. 4, 697–704. doi: 10.1038/nrmicro1476
Rowe-Magnus, D. A., Guérout, A. M., and Mazel, D. (1999). Super-integrons. Res. Microbiol. 150, 641–651. doi: 10.1016/S0923-2508(99)00127-8
Tanabe, T., Funahashi, T., Miyamoto, K., Tsujibo, H., and Yamamoto, S. (2011). Identification of genes, desR and desA, required for utilization of desferrioxamine B as a xenosiderophore in Vibrio furnissii. Biol. Pharm. Bull. 34, 570–574. doi: 10.1248/bpb.34.570
Tanguy, M., McKenna, P., Gauthier-Clerc, S., Pellerin, J., Danger, J.-M., and Siah, A. (2013). Func- tional and molecular responses in Mytilus edulis hemocytes exposed to bacteria, Vibrio splendidus. Dev. Comp. Immunol. 39, 419–429. doi: 10.1016/j.dci.2012.10.015
Thompson, F. L., Iida, T., and Swings, J. (2004). Biodiversity of vibrios. Microbiol. Mol. Biol. Rev. 68, 403–431. table of content, doi: 10.1128/MMBR.68.3.403-431.2004
Trucksis, M., Michalski, J., Deng, Y. K., and Kaper, J. B. (1998). The Vibrio cholerae genome con- tains two unique circular chromosomes. Proc. Natl. Acad. Sci. U.S.A. 95, 14464–14469. doi: 10.1073/pnas.95.24.14464
Tsao, C.-H., Chen, C.-C., Tsai, S.-J., Li, C.-R., Chao, W.-N., Chan, K.-S., et al. (2013). Seasonality, clinical types and prognostic factors of Vibrio vulnificus infection. J. Infect. Dev. Ctries. 7, 533–540. doi: 10.3855/jidc.3008
Verma, S. C., and Miyashiro, T. (2013). Quorum sensing in the squid-Vibrio symbiosis. Int. J. Mol. Sci. 14, 16386–16401. doi: 10.3390/ijms140816386
Vesth, T., Wassenaar, T. M., Hallin, P. F., Snipen, L., Lagesen, K., and Ussery, D. W. (2010). On the origins of a Vibrio species. Microb. Ecol. 59, 1–13. doi: 10.1007/s00248-009-9596-7
Wiik, R., Stackebrandt, E., Valle, O., Daae, F. L., Rødseth, O. M., and Andersen, K. (1995). Classi- fication of fish-pathogenic vibrios based on comparative 16S rRNA analysis. Int. J. Syst. Bacteriol. 45, 421–428. doi: 10.1099/00207713-45-3-421
Xiang, G., Pu, X., Jiang, D., Liu, L., Liu, C., and Liu, X. (2013). Development of a real-time resistance measurement for vibrio parahaemolyticus detection by the lecithin-dependent hemolysin gene. PLoS ONE 8:e72342. doi: 10.1371/journal.pone.0072342
Keywords: Vibrio pan-genome, chromosome-specific genes, Vibrio comparative genomics, Vibrio core-genome, comparative genomics
Citation: Lukjancenko O and Ussery DW (2014) Vibrio chromosome-specific families. Front. Microbiol. 5:73. doi: 10.3389/fmicb.2014.00073
Received: 01 October 2013; Accepted: 10 February 2014;
Published online: 18 March 2014.
Edited by:
Rita R. Colwell, University of Maryland, USAReviewed by:
Martin G. Klotz, University of North Carolina at Charlotte, USAVincent Burrus, Université de Sherbrooke, Canada
Copyright © 2014 Lukjancenko and Ussery. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: David W. Ussery, Department of Systems Biology, Center for Biological Sequence Analysis, Technical University of Denmark, Kemitorvet, Building 208, 2800 Kgs. Lyngby, Denmark e-mail: dave@cbs.dtu.dk