dMM-PBSA: A New HADDOCK Scoring Function for Protein-Peptide Docking
 Dimitrios Spiliotopoulos1
Dimitrios Spiliotopoulos1  Panagiotis L. Kastritis2,3
Panagiotis L. Kastritis2,3  Adrien S. J. Melquiond2
Adrien S. J. Melquiond2  Alexandre M. J. J. Bonvin2
Alexandre M. J. J. Bonvin2  Giovanna Musco4
Giovanna Musco4  Walter Rocchia5
Walter Rocchia5  Andrea Spitaleri5*
Andrea Spitaleri5*- 1Department of Biochemistry, University of Zürich, Zürich, Switzerland
- 2Faculty of Science - Chemistry, Bijvoet Center, Utrecht University, Utrecht, Netherlands
- 3European Molecular Biology Laboratory Heidelberg, Heidelberg, Germany
- 4Biomolecular Nuclear Magnetic Resonance Unit, Ospedale S. Raffaele, Milan, Italy
- 5CONCEPT Lab, Istituto Italiano di Tecnologia, Genoa, Italy
Molecular-docking programs coupled with suitable scoring functions are now established and very useful tools enabling computational chemists to rapidly screen large chemical databases and thereby to identify promising candidate compounds for further experimental processing. In a broader scenario, predicting binding affinity is one of the most critical and challenging components of computer-aided structure-based drug design. The development of a molecular docking scoring function which in principle could combine both features, namely ranking putative poses and predicting complex affinity, would be of paramount importance. Here, we systematically investigated the performance of the MM-PBSA approach, using two different Poisson–Boltzmann solvers (APBS and DelPhi), in the currently rising field of protein-peptide interactions (PPIs), identifying the correct binding conformations of 19 different protein-peptide complexes and predicting their binding free energies. First, we scored the decoy structures from HADDOCK calculation via the MM-PBSA approach in order to assess the capability of retrieving near-native poses in the best-scoring clusters and of evaluating the corresponding free energies of binding. MM-PBSA behaves well in finding the poses corresponding to the lowest binding free energy, however the built-in HADDOCK score shows a better performance. In order to improve the MM-PBSA-based scoring function, we dampened the MM-PBSA solvation and coulombic terms by 0.2, as proposed in the HADDOCK score and LIE approaches. The new dampened MM-PBSA (dMM-PBSA) outperforms the original MM-PBSA and ranks the decoys structures as the HADDOCK score does. Second, we found a good correlation between the dMM-PBSA and HADDOCK scores for the near-native clusters of each system and the experimental binding energies, respectively. Therefore, we propose a new scoring function, dMM-PBSA, to be used together with the built-in HADDOCK score in the context of protein-peptide docking simulations.
Introduction
Molecular docking is a computational method that investigates the intermolecular complexes formed between two or more constituent molecules. It comprises the process of generating a model of a complex based on the known three-dimensional structures of its components, i.e., the target (protein, or nucleic acids) and the ligand (a peptide, a protein, a small organic molecule), free or bound to other species (Rognan, 2013). The docking procedure consists in the search for near-native ligand conformations and orientations (usually referred to as docking poses) with respect to a target protein, where the structure of the latter is known or modeled. Fast approximate mathematical expressions (so called scoring functions) are used to rank the docking poses based on estimates of the goodness of the conformations obtained for each putative binder and of the binding affinity estimate of the two interacting partners. Pioneered during the early 1980s (Kuntz et al., 1982), molecular docking is still a field of intensive research, as it represents a fundamental component in many drug discovery programs (Meng et al., 2011) and a primary tool for the virtual screening of large chemical libraries (Kitchen et al., 2004). The typical system considered in docking calculations includes the ligand, the receptor, and the solvent molecules. Because of the enormous number of degrees of freedom associated with the solvent, it is usually neglected in the calculations, or implicitly accounted for in the scoring functions. Despite some valuable improvements in the accuracy and efficiency of the molecular docking algorithms, there are still considerable drawbacks and limitations to face. Among these, the reliability of the scoring functions is probably one of the aspects deserving more attention, since discriminating native pose and obtaining a fair correlation between docking scores and experimental activity data remain difficult tasks. These limitations are responsible for the occurrence of false-positive and false-negative hits in the ranked lists resulting from the screenings performed with standard docking methods. Over the years, since the pioneering work of Kuntz et al. (1982), several scoring functions have been developed (Gilson and Zhou, 2007; Huang et al., 2010; Sarti et al., 2013), based on several terms. Despite empirical scoring functions are still widely used in drug discovery since they are faster and relatively accurate, first-principle methods for ranking decoy structures and for predicting affinity should be considered the first desirable choice in docking scoring stage.
Hence, it is a general opinion that molecular docking results may benefit from post-processing with more accurate tools, able to provide higher accuracy in energy scoring of the putative docked poses. Among several docking approaches, HADDOCK is one of the few computational docking programs that follow a data-driven strategy, using experimental data (generated either via NMR experiments, mutagenesis, or mass spectrometry) as pivotal information to generate docking poses (Dominguez et al., 2003). Moreover, the program allows the receptor to undergo small conformational changes upon association with the ligand, a feature that has been deemed as crucial in simulating the binding process (Spiliotopoulos and Caflisch, 2014). HADDOCK has been applied successfully to a plethora of biomolecular systems (Dominguez et al., 2003). Its reliability is highlighted by the excellent evaluations in the CAPRI experiments (van Dijk et al., 2005) and by the fact that more than 60 structures solved via HADDOCK docking have been deposited in the Protein Data Bank (Berman et al., 2000). Moreover, continuous efforts are devoted to integrate HADDOCK with experimental methodologies (Hennig et al., 2012) and other computational techniques (Kastritis et al., 2014) in order to improve its built-in scoring function. Among several other scoring approaches, Molecular Mechanics Poisson–Boltzmann Surface Area, MM-PBSA, is routinely used to evaluate the strength of the complex formation between protein and ligands. MM-PBSA represents a good trade-off between calculation efficiency and accuracy in binding energy calculations and it has been profitably exploited in virtual design since it allows a ranking in different docking runs and between different ligands (Graves et al., 2008; Venken et al., 2011; Yang et al., 2011; Barakat et al., 2012; Genheden and Ryde, 2015). Although MM-PBSA is one of the most used approximate methods for the estimate of binding free energies, it also presents weaknesses that should not be overlooked. In particular, a source of error can be represented by the entropy contribution, which is often neglected when relative binding free energies of similar molecules are computed. Furthermore, the quality of results depends on different computational factors, including the conformational sampled space, the force field, internal dielectric constant, and the set of atomic radii (Weis et al., 2006). Additional MM-PBSA limitations in the estimation of binding free energies are for highly polar molecules such as DNA and RNA (Kongsted et al., 2009), buried ligands (Singh and Warshel, 2010), and in presence of explicit water molecules that might contribute to the binding free energy (Homeyer and Gohlke, 2012). Therefore, several attempts have been made to improve accuracy and predictivity of the MM-PBSA method acting on the solvation term, including polar and non-polar terms. Expedients such as using different PB solvers (Feig et al., 2004), tuning the grid mesh (Harris et al., 2013), and/or the internal dielectric constant (Singh and Warshel, 2010; Hou et al., 2011; Genheden and Ryde, 2015), including crystallographic and/or specific water molecules (Treesuwan and Hannongbua, 2009; Liu et al., 2013; Maffucci and Contini, 2013), have allowed to successfully use MM-PBSA in the binding free energy calculations (Wang et al., 2001). However, there is still room for improvement to make MM-PBSA more efficient and reliable in the binding free energy calculations in different respects.
Here we focus our investigation on the field of protein-peptide interactions (PPIs), which are gaining large interest in the biological and pharmaceutical research (Scott et al., 2016). In fact, the inhibition of PPIs is of paramount importance in drug discovery and development. The main problem in the PPIs simulation is that the protein-peptide interface is large, shallow, and involving several contacts characterized by being weak, transient and non-specific. Therefore, not all the PPI interface contributes equally to the strength of the binding between the partners. PPIs are rather mediated by hot spots, small regions that give the largest contribution to the binding.
In the present study, we investigated the effectiveness of MM-PBSA on evaluating protein-peptide docked complexes using HADDOCK software in order to consider the possibility of exploiting this relatively fast approach as an additional scoring function. We show in the results section the performance of MM-PBSA as a scoring function for the 19 systems (Results—Section MM-PBSA As Scoring Function for Protein-Peptide Docking) and as binding affinity predictor for the systems where reliable experimental binding affinity data were available (Results—Section Correlation between Experimental Binding Free Energies and Scores).
Results and Discussion
MM-PBSA is an end-point method devised to estimate binding free energy (ΔGcomp) as the difference of the free energy of the complex and those of the unbound receptor and peptide (Massova and Kollman, 1999). Normally, it is performed from a set of snapshots obtained from Molecular Dynamics simulation (Hou et al., 2011). This method is significantly less computationally demanding than alternatives such as free energy perturbation (FEP) calculations and therefore it represents a possible alternative to FEP for virtual screening of large chemical libraries. It relies on the use of implicit solvent (for the PB part) and it requires energy calculations only on the endpoint (bound/unbound) states whereas other approaches require energy calculation along a reaction coordinate. MM-PBSA has already been used as a scoring function in the past with various outcomes (Kuhn et al., 2005; Thompson et al., 2008; Zhou et al., 2009; Genheden and Ryde, 2015) but to the best of our knowledge this is the first time it has been used for a set of PPIs obtained from docking calculations. Previous studies have shown that MM-PBSA is efficient to identify the correct binding poses and rank small molecules for a specific target (Thompson et al., 2008; Hou et al., 2011; Zhu et al., 2013). However, there is no systematic evaluation of the performance of MM-PBSA in identifying the correct docking poses in the protein-peptide context. As mentioned, the free energy of binding was calculated as the difference in free energy between the product state and the reactants state, that is, between the energy of the protein-peptide complex and the sum of the energies of the protein and the ligand in their unbound forms.
We investigated 19 protein-peptide complexes for which structural and thermodynamic data (binding free energy values ΔGbind) were available (Table 1). The final MM-PBSA values are calculated as the sum of two molecular mechanics terms (namely Coulomb and Lennard-Jones), which are calculated by HADDOCK, and two solvation terms, including polar and non-polar solvation contributions, which here were calculated using two different Poisson–Boltzmann equation solvers, APBS (Baker et al., 2001) and DelPhi (Rocchia et al., 2001, 2002) in combination with the NanoShaper program (Decherchi and Rocchia, 2013). We decide to use two different solvers to minimize the MM-PBSA aforementioned weakness and interestingly the binding free energy values from the two solvers were in good agreement in all case studies, indicating that the consistency of the approach. (Figure S1).
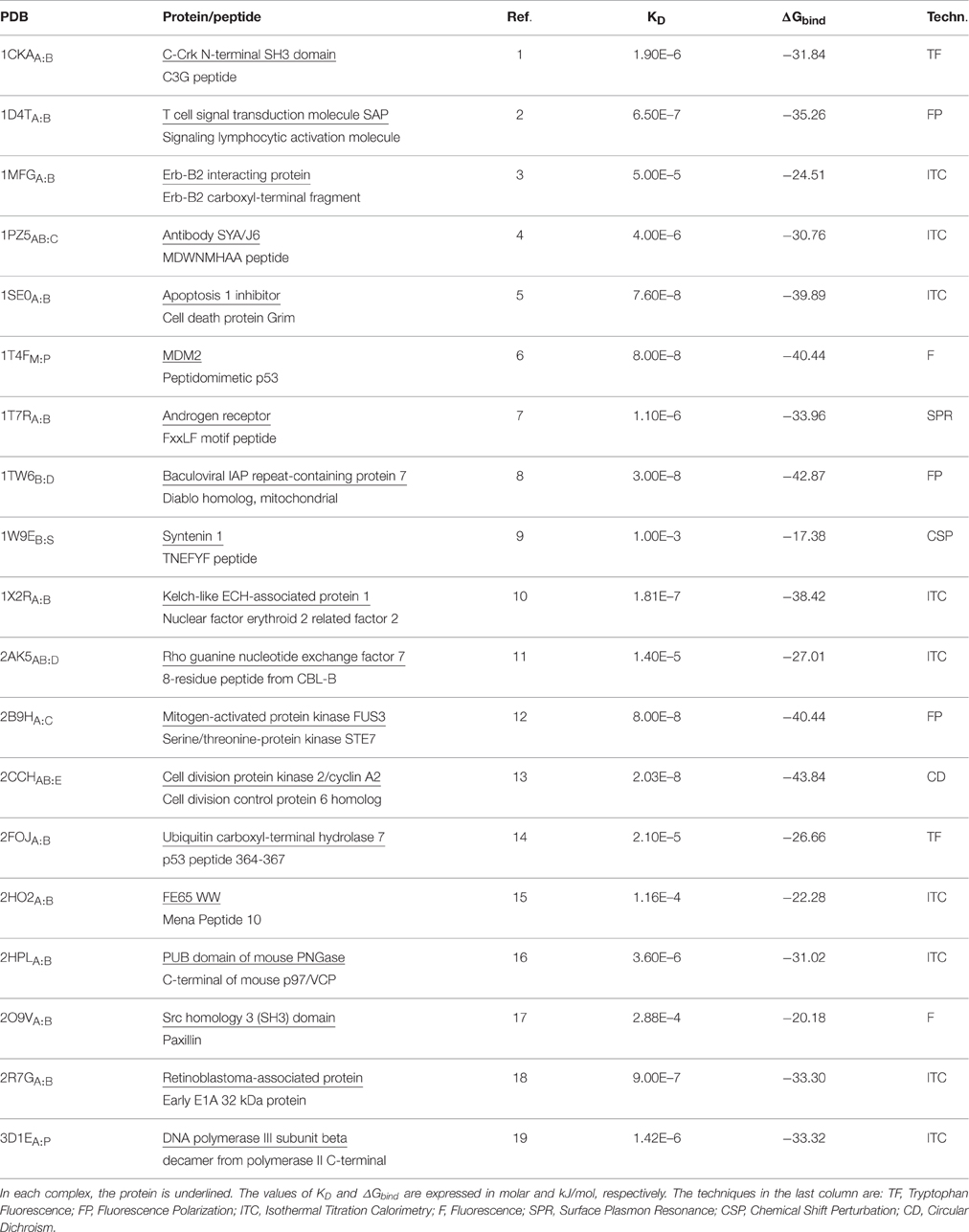
Table 1. Complexes investigated.
In our calculations, we observed that the computed binding free energies were larger than those obtained by experiments (Table 2), an overestimation that has been already observed in other systems. This behavior has been often ascribed to the omission of the entropic contribution, which is an approximation typical of these calculations (Gilson and Zhou, 2007; Spiliotopoulos et al., 2012).
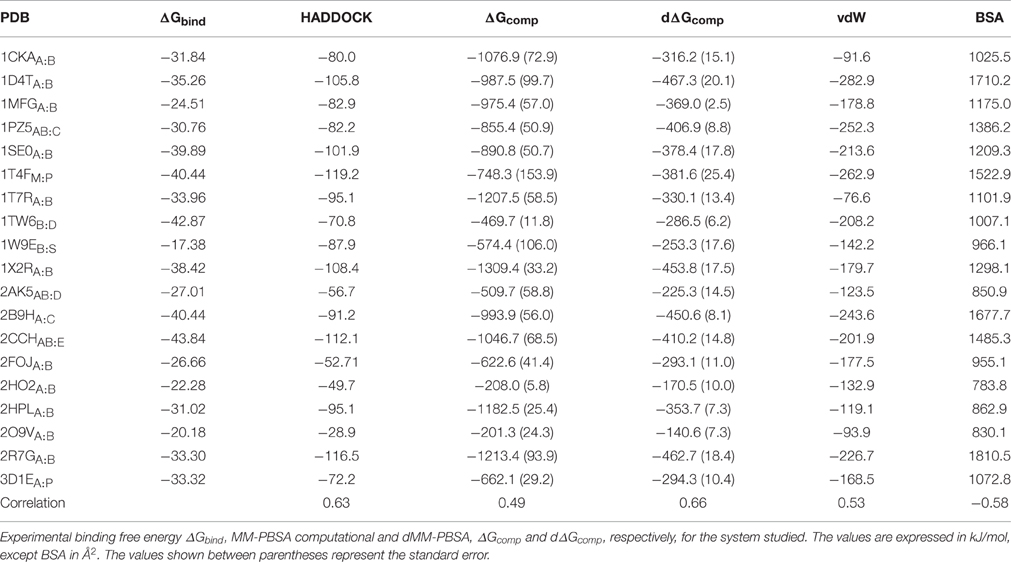
Table 2. Complexes investigated.
The constituents of each complex (i.e., protein and peptide) were separated and re-docked using HADDOCK. The HADDOCK scores and MM-PBSA binding free energies corresponding to 200 poses were calculated in each system with the HADDOCK's clustering-based approach. Similarly to HADDOCK score calculation, where coulombic interactions are scaled to a fifth, we also dampened MM-PBSA, i.e., the MM-PBSA energies were calculated multiplying both coulombic and polar solvation terms by 0.2. We will therefore compare three different scoring functions, including HADDOCK built-in, MM-PBSA, and dampened MM-PBSA, which we call dMM-PBSA. The two following sections show the performances of each scoring function in discriminating between the correctly and incorrectly docked peptide poses (Section MM-PBSA As Scoring Function for Protein-Peptide Docking) and in correlating with the experimental ΔGbind through the whole dataset (Section Correlation between Experimental Binding Free Energies and Scores).
MM-PBSA As Scoring Function for Protein-Peptide Docking
We sought to determine the correlation between the results of the identified scoring methods and the i-RMSD (interface RMSD, see Section Materials and Methods for details) values. The re-docked structures were clustered using the HADDOCK protocol based on i-RMSD values (de Vries et al., 2010). In the Poisson–Boltzmann equation (polar term in MM-PBSA), calculations were performed using ε equal to 2 and 80 for the solute and solvent, respectively. We then calculated the probability to find at least one near-native structure (i.e., displaying an i-RMSD lower than 2 Å) among the N top-ranking of the best 4 poses in each cluster (clustersBEST4) according to HADDOCK, MM-PBSA, or dampened MM-PBSA (dMM-PBSA), respectively. The percentage of systems with near-native pose vs. the number of clusters for each scoring function is shown in Figure 1. Overall, we observe that HADDOCK score is a valid scoring function by which the near-native pose is ranked within the first cluster in 8 out of 19 systems (about 40%) and within the top 3 clusters in 12 out of 19 (about 63%). MM-PBSA has a somehow worse performance, ranking the near-native pose within the first and the second cluster in 7 out of 19 (about 37%) and 8 out of 19 (about 43%) in the top 3 clusters. The modulation of the polar terms resulting from the MM-PBSA calculation proved able to improve the MM-PBSA performance. In fact, dMM-PBSA reaches similar performance to HADDOCK score in ranking the near-native pose in the first cluster and in the top 3 clusters (11 out of 19, about 58%).
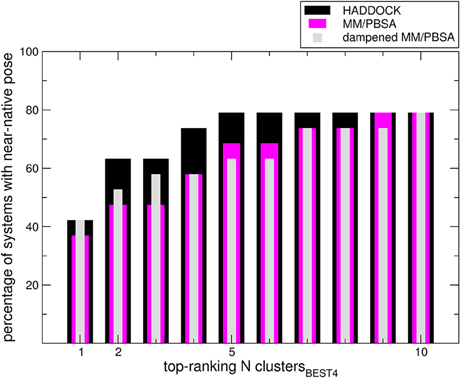
Figure 1. Bars indicate the percentage of systems in which at least a near-native pose could be found among the members of the N top-ranking (x-axis value) clustersBEST4. Note that in four cases no near-native pose could be found among the members of the clustersBEST4.
Correlation between Experimental Binding Free Energies and Scores
A further question of interest is whether scoring functions can reliably predict binding affinities when carried out on multiple structures. To address this question, we correlated the HADDOCK scores, MM-PBSA, and dMM-PBSA values of the clusterBEST4 displaying the lowest average i-RMSD obtained for each of the 19 systems and plotted against the experimental binding free energies. In Figure 2 it is shown the correlation for each scoring function. Despite the large absolute values, the correlation between the 19 experimental binding free energies and the HADDOCK scores is good (R = 0.63 p = 0.004, Figure 2, upper panel). The dampened MM-PBSA (Figure 2, lower panel) outperforms MM-PBSA (Figure 2, middle panel) and is better than HADDOCK score in terms of the correlation between experimental and computational binding free energies (R = 0.66, p = 0.002 and R = 0.49, p = 0.03, respectively).
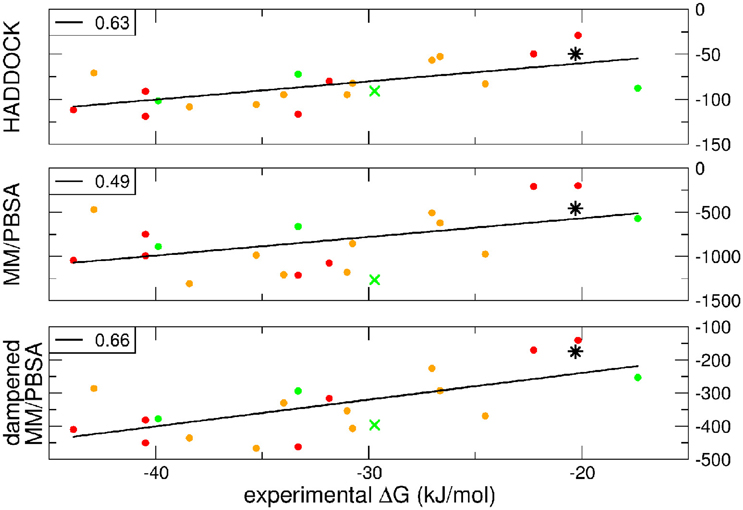
Figure 2. HADDOCK values are expressed in a.u. MM-PBSA and dampened MM-PBSA values are expressed in kJ/mol. In all graphs, the color code indicates the average i-RMSD of the clusterBEST4. Green, lower than 1.5 Å; orange, between 1.5 and 2 Å; red, >2 Å (none of which is greater than 2.7 Å). Data for AIRE-PHD1 and NPH1-SH3 are indicated with a green × (average i-RMSD: 0.87 Å) and a black star (unknown i-RMSD). The correlation between the different scoring functions and the experimental ΔGbind is shown in the left corner of each panel. The p-values for HADDOCK, MM-PBSA, and dMM-PBSA are 0.003, 0.03, and 0.002, respectively.
We wondered then whether the scores could be exploited to correctly predict the ΔGcomp of a new set of protein-peptides. Therefore, we performed a docking with HADDOCK for two additional protein-peptide systems:
1. AIRE-PHD1 complexed with the H3 histone peptide, both NMR structure (PDB 2KE1) and ΔGbind value available (Chignola et al., 2009).
2. NPHP1-SH3 domain in complex with a polyproline peptide, only ΔGbind available (Wodarczyk et al., 2010).
The latter system represents a real blind case study of PPIs since no experimental structural information was available for this system. Binding free energy obtained according to the MM-PBSA approach on the putative pose belonging to the top-ranking clusterBEST4 according to the HADDOCK score has been carried out and the calculated value correlated with experimental values (Figure 2, black star). The ΔGcomp of the AIRE and NPHP1-SH3 complexes lies close to the previously calculated regression line, suggesting that the scores can be reliably used to predict the correct pose of PPIs systems.
Breakdown of the binding free energy into its components, including van der Waals, electrostatic, polar solvation, and nonpolar solvation interaction energy terms, identified the factors dominating binding affinity for the whole dataset. We analyzed the correlation between either the Lennard-Jones terms (vdW) or the buried surface area (BSA) of the same clusterBEST4 and the experimental binding free energies. Data for vdW and BSA vs. experimental binding free energies along with i-RMSD values are plotted in Figure 3. The van der Waals and BSA terms are fairly correlated with the experimental binding free energies (R = 0.53, p = 0.02, Figure 3, upper panel, and R = −0.58, p = 0.009, Figure 3, lower panel, respectively). The anticorrelation between experimental ΔGbind values and BSA relies on the fact that larger BSA allows broader interactions between protein and peptide partners. In contrast, no correlation has been found between experimental data and the polar terms.
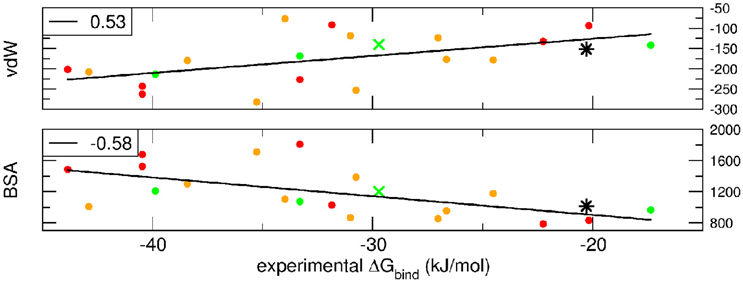
Figure 3. van der Waals term, expressed in kJ/mol, and BSA, expressed in Å2, terms as function of experimental ΔGbind. Data for AIRE-PHD1 and NPH1-SH3 are indicated with a green × (average i-RMSD: 0.87 Å) and a black star (unknown i-RMSD). The correlation between the different terms and the experimental ΔGbind is shown in the upper left corner of each panel.
One of the main advantages to use the MM-PBSA approach in the docking scoring is the ability to quickly perform the computational alanine scanning (CAS) on the best pose in order to evaluate the energetic contribution to the binding affinity of individual residues. Therefore, we carried out a small study of CAS on the AIRE-PHD1 system (five mutants) using the data published in Spiliotopoulos et al. (2012) and we decided to be in the best scenario possible, e.g., we used the NMR complex (Chignola et al., 2009) as starting structure for the CAS calculation. We also evaluated the HADDOCK score of each mutated AIRE-PHD1 complex by only performing the water refinement [i.e., by which the rigid body stage (it0) and the flexible refinement (it1) are turned off]. In agreement with the published data (Spiliotopoulos et al., 2012) we found a good correlation between both MM-PBSA (R = 0.88, p < 0.02) and dMM-PBSA (R = 0.86, p < 0.03) and the experimental data (Figure S3 middle and bottom), whereas HADDOCK score showed lower correlation with the experimental data (R = 0.60, p < 0.21) (Figure S3 top).
Conclusions
In this work, we made use of the MM-PBSA technique in docking scoring and in affinity prediction of protein-peptide complexes. We also compared the results with the HADDOCK built-in scoring function. Overall, HADDOCK and dMM-PBSA, a dampened MM-PBSA version, behaved similarly in ranking the near-native poses in the top 3 clusters, improving over the standard MM-PBSA version. The introduction of weights for the different MM-PBSA terms is not unprecedented in the literature (Zhou et al., 2009), but this approach has never been applied to PPIs. Notably, despite the fact that different experimental conditions (where the main difference regarded the type of buffer and the ionic strength, whereas as both pH and temperature were comparable) and techniques (Table 1) were used to determine the dissociation constants, we observed a good correlation between experimental and computational ΔG of binding using HADDOCK and dMM-PBSA scoring functions, 0.63 and 0.66 respectively. Interestingly, lack of modulation of the solvation MM-PBSA terms resulted in worse correlation between the experimental and simulated figures (r = 0.49).
Our findings were then validated on two additional systems, one with known structure and binding affinity and one for which only the ΔGbind has been reported. Both HADDOCK and dMM-PBSA methods perform remarkably well in ranking the two additional protein-peptide complexes, and lead to good correlation with experimentally measured ΔGbind.
In order to assess the presence of possible systematic errors in the binding free energy calculations, we used two different PB solvers, namely APBS (Baker et al., 2001) and DelPhi (Rocchia et al., 2001, 2002). No differences in term of correlation with experimental data were found using the two different solvers, except that in absolute ΔGcomp values (Figure S1) and in the calculation speed (see Section Materials and Methods). APBS provided a ΔGcomp larger than DelPhi. This could arise from different aspects, including the different approaches used to describe the dielectric interface, the approach used to estimate the reaction field energy, and/or how the different solvers treat cavities that are internal to the solute. The accuracy of the PB equation solution has been reported to be sensitive to the grid size, in favor of smaller grid spacing (Sørensen et al., 2015) However, decreasing the grid spacing increases the computational resources needed to perform the calculation, both in terms of physical memory, and the computational time required. We choose a grid size of 0.5 Å for both solvers since it represents a good trade-off between speed and accuracy. With lower grid resolution, APBS would have encountered problems in convergence in ΔGcomp calculation (see Figure 3.2 in Sørensen et al., 2015). Finally, the choice of the interior dielectric (εint) value in the PB calculation is not trivial since in the literature its value can be found spanning between 1 and 20. Higher εint (4–20) aims to effectively mimic polarization and local rearrangement effects, as well as transient penetration of water molecules into the solute interior. They should in principle be preferred when the PB calculation is performed on individual structures. On the other hand, lower εint (2–3) is preferred in order to mainly account for electronic polarization and it is commonly used on ensembles of structures, which explicitly account for conformational flexibility. In light of this, there is still no consensus on the most appropriate εint value. We decided to use εint = 2 in all cases, while being aware that scaling the polar contribution in dMM-PBSA is similar to considering a dielectric screening of the solute medium, accounting for polarization and rearrangement due to the reaction to the existing fields (Figure S2). This is also in agreement with previous studies where the rank-ordering performance for MM-PBSA improves with increasing dielectric constant (Wang et al., 2013). Simultaneously, this supports the relative importance of the non-polar components and results in better performance. In fact, the van der Waals and BSA terms, which are directly related to the MM-PBSA non-polar terms, correlated well with the experimental data and they provided the main contribution to the final score. These factors might explain the better performance of the dampened MM-PBSA. Finally, we analyzed the calculated data from HADDOCK and MM-PBSA in order to evaluate the reproducibility of the results in terms of scoring and final correlation with the experimental data. First of all, for a given complex, with the corresponding MM energy terms provided by HADDOCK, the only variations in the final results could arise from the PB calculations since it depends on many parameters, including the grid spacing, the atomic radii, and the dielectric interior. For this reason, we used two different PB solvers, APBS and DelPhi, using identical parameters. In Figures S1, S2 it is shown the good agreement in the MM-PBSA and dMM-PBSA calculations with the two PB solvers, indicating that the calculations are quite robust. Second, we calculated the correlations between the experimental and calculated binding free energy using different MM-PBSA values from the clusterBEST4 and not the average value. The final correlations R were in a range of 0.39–0.49 for MM-PBSA and 0.60–0.67 for dMM-PBSA, indicating that in principle the MM-PBSA could be performed on a single pose with less computational effort. Finally, the calculated standard error for each clusterBEST4 reported in Table 2 represent the MM-PBSA limit when we try to compare the binding affinities of different complexes, mainly when dealing with docking since the conformational sampling is poor with respect to performing MM-PBSA from molecular dynamics simulations (Spiliotopoulos et al., 2012). Nevertheless, in case of AIRE-PHD1 mutants, the MM-PBSA and dMM-PBSA uncertainty over the NMR structure bundle (20 structures) reduces, leading to an average standard error of 34 and 7 kJ/mol, respectively, indicating that dMM-PBSA is fairly reliable in predicting protein-peptide interface alanine mutations. Moreover, the CAS dMM-PBSA of AIRE-PHD1 error range values are fairly in agreement with the CAS MM-PBSA error range (ca. 4 kJ/mol) shown in Spiliotopoulos et al., in which the sampling was carried out by molecular dynamics simulations (Spiliotopoulos et al., 2012). This result indicates that dMM-PBSA carried out on a small number of structures (e.g., 20) behaves similarly to MM-PBSA from molecular dynamics, in which the sampling is more extended. In fact, the modulation of the polar terms in MM-PBSA is probably taking into account the possible local rearrangement similarly to what is done via a higher internal dielectric, indicating that dMM-PBSA represents a simple and promising approach in evaluating alanine mutations from single structure, either from docking or from X-Ray or from NMR.
We believe that in parallel with the recently developed optimization of the HADDOCK score for PPIs inhibitors (Kastritis et al., 2014), the combination of HADDOCK score and modified MM-PBSA binding free energy might lay the groundwork for novel approaches to study in silico PPIs inhibitors in a quick and automatic fashion. The advantage of using MM-PBSA as scoring function is threefold. First, MM-PBSA is versatile. It provides estimates of the equilibrium averages over the solvent degrees of freedom, permitting the post-processing of solute representative snapshots from docking poses. Since MM-PBSA estimates binding free energy, it represents a valuable alternative since it is in principle transferable between different docking runs and can be used to score both intra-ligand and inter-ligand poses, saving individual validation for each system under study. This makes MM-PBSA more suitable for novel problems with limited experimental data as we demonstrated in the case study of NPHP1-SH3. Second, MM-PBSA can be used to quantify the thermodynamical strength of the putative poses. In particular, our dMM-PBSA is a reliable scoring function in the protein-peptide field showing good a correlation with experimental data. Therefore, the advantage to use dMM-PBSA with respect to MM-PBSA relies on the possibility to modulate the polar terms without rerunning the Poisson–Boltzmann calculations at different internal dielectric values. Finally, MM-PBSA could better allow to disclose atomistic details of protein-peptide binding, supporting the rational design of bioactive compounds. In fact, post-processing task such as CAS approach has been very recently applied to MD simulations for successfully evaluating the importance of key residues in the protein-peptide binding complex (Spiliotopoulos et al., 2012). Therefore, MM-PBSA can be used to calculate the ΔΔG, defined as ΔGwt − ΔGmutALA, on the protein-peptide best docked poses in order to identify residues for which mutation to alanine strongly attenuates binding. The latter behavior occurred in our short CAS study of AIRE-PHD1 mutants (Figure S3), by which an acceptable correlation of R = 0.86/0.88 between the experimental and the calculated binding energies of the mutants demonstrated the possibility to use MM-PBSA as a promising tool at low computational cost to evaluate the hot-spots in the PPIs field with respect to the HADDOCK score.
Finally, structural prediction of protein-peptide complexes remains challenging due to two major obstacles: peptides are highly flexible and they often interact weakly with their substrate, underlining their importance in signal transduction or regulation which often relies on transient processes. This leaves flexible docking as one of the few amenable computational techniques to model these complexes (Verkhivker et al., 2000; Hetényi and van der Spoel, 2002; Niv and Weinstein, 2005; Raveh et al., 2010, 2011; Trellet et al., 2013). In our study, we are considering the two interacting partners, protein and peptide, already in the bound conformation, which represents a strong assumption in term of binding mechanism and also the best scenario for a docking calculation, especially in the PPIs field. This undoubtedly increases the success rate in the native pose determination and it reduces the error in the binding affinity calculations since in our MM-PBSA approach we are neglecting most of the solute entropic contribution (i.e., under this assumption the estimate of ΔS = SComplex − (Sprotein − Speptide) can be poor). Recent work have highlighted the efforts to improve HADDOCK protocol in the field of protein-peptide (Trellet et al., 2013) but still predicting large conformational changes remains a challenge as indicated by several failure to accurately predict cases where the protein undergoes large conformational changes upon binding (Trellet et al., 2013). In this case, even the more accurate and reliable scoring function and binding free energy methods will struggle in discriminating the correct binding mode due to both hard and soft docking failure (Verkhivker et al., 2000).
In conclusion, in contrast to other scoring functions and approximate binding free energy calculation methods such as the linear interaction energy (LIE) method, MM-PBSA contains less empirical parameters and, thus, it is more likely to be useful in determining the relative free energies of binding of quite different compounds and systems for which there is more limited experimental data, although a protein structure of the target is, of course, required.
Materials and Methods
Data Set
Particular attention should be paid to the choice of the data set exploited as a benchmark in the binding free energy computational estimation. First of all, binding affinity greatly depends on temperature, pH, and salt concentration (Acampora and Hermans, 1967) and these parameters are difficult to incorporate in the docking calculation. Second, experimental binding data present in the literature are determined with different experimental techniques and they are from different research laboratories. This could significantly impact on the reliability and comparability of the results. Therefore, it should be desirable to rely as much as possible on homogenous data, in terms of research laboratory, experimental technique, and experimental conditions. Along this line, we used a subset of the London's benchmark (http://www.weizmann.ac.il/Organic_Chemistry/London/) for which there were available free forms of the proteins and binding affinity data. The data set consists of 19 complexes the structures of which have been determined by X-ray crystallography, as shown in Table 1. In addition to this data set, two protein-peptide systems, including AIRE-PHD1 (NMR structure, PDB ID 2KE1) (Chignola et al., 2009) and NPHP1-SH3 (Wodarczyk et al., 2010), were used in order to establish the predictive ability of the three different scoring functions. In case of NPHP1-SH3 only experimental binding free energy data were available.
Generation of Binding Poses
We used the experimental data (chemical shift mapping and mutagenesis) to generate the decoy structures of the 19 cases study and for both AIRE-PHD and NPHP1-SH3 using the HADDOCK strategy. The HADDOCK protocol proceeds through three steps (rigid docking, semi-flexible docking, and water refinement) (de Vries et al., 2007). Non-bonded interactions were calculated with the OPLS force field using a cutoff of 8.5 Å. The electrostatic energy (Eelec) was calculated using a shift function while a switching function (between 6.5 and 8.5 Å) was used for the van der Waals energy (Evdw). This procedure generated 200 models for each complex, starting from different random velocities. As per default of the HADDOCK protocol, the average score of the top 4 models was considered. The HADDOCK score is defined as a weighted sum of the following four terms:
where Eelec is the electrostatic energy, Evdw is the van der Waals energy, Edesolvation is the desolvation energy and EAIR restraints (i.e., distance) violation energies.
The different docking parameter settings and cluster analysis were selected according to the protocol reported in de Vries et al. (2010). BSA is defined as SASAComplex − (SASAProtein + SASAPeptide) and it is calculated directly by HADDOCK. All calculations were performed with HADDOCK, version 2.1/CNS, version 1.2, through the refinement interface of the HADDOCK web server (de Vries et al., 2010).
Binding Free Energy Calculation MM-PBSA
A modified version of the recently published GMXPBSA tool (Paissoni et al., 2014), named HADDOCKPBSA was used to perform the MM-PBSA calculations for the systems. Similarly to the previous version of the scripts, the calculations are organized in an automatic fashion that can be run in parallel in a PBS queue system and the scripts are extensively commented to facilitate their customization. Improving the previous version, HADDOCKPBSA facilitates the interface between HADDOCK and Poisson–Boltzmann Surface Area (PBSA) calculations.
The method for determining the binding free energy following the MM-PBSA approach has been described previously (Massova and Kollman, 1999). The binding free energy of MM-PBSA was estimated as following:
This average over each term, i.e., using a set of snapshots, is required since the Poisson–Boltzmann method to calculate Gsol averages only over the degrees of freedom of the solvent and not of the solute, i.e., protein, peptide, and ligands.
The energetic term EMM is defined as:
where Eint indicates bond, angle, and torsional angle energies, and Ecoul and ELJ denote the intramolecular electrostatic and van der Waals energies, respectively. Equation (3) is normally approximated to Ecoul + ELJ since Eint will zero out upon binding (ΔEint = − ( + )) if the same conformations are considered for the free and bound forms. The solvation term Gsolv in Equation (4) is split into polar Gpolar and non-polar contributions, Gnonpolar:
Equation (2) can therefore be rewritten as:
where:
where α is a parameter allowing to reduce the polar contribution to the <G> values. Here, the polar contribution Gpolar was calculated with two different PB solvers: APBS (Adaptive Poisson–Boltzmann Solver) (Baker et al., 2001) and DelPhi (Rocchia et al., 2001, 2002) programs. The polar contribution Gpolar refers to the energy required to transfer the solute from a continuum medium with a low dielectric constant (ε = 2) to a continuum medium with the dielectric constant of water (ε = 80). Gpolar was calculated using the nonlinear Poisson Boltzmann equation. The grid spacing was automatically set to 0.5 Å. The temperature was set to 296 K, and the salt concentration was 0.15 M. The non-polar contribution Gnonpolar was calculated with two different approaches: APBS internal routine and using the NanoShaper program (Decherchi and Rocchia, 2013). This term was considered proportional to the solvent accessible surface area (SASA):
where γ = 0.0227 kJ mol−1 Å2 and β = 0 kJ mol−1 (Spiliotopoulos et al., 2012). The dielectric boundary was defined using a probe radius of 1.4 Å.
The binding free energy of a protein molecule to a peptide molecule in a solution was then defined as:
where <Gi > is calculated as the average of the best 4 poses of each cluster. The computational determination of the free energy of binding requires the calculation of the entropic contributions to complex formation, including conformational changes in rotational, translational and vibrational degrees of freedom of the solute. Solute entropic contributions are usually estimated by either the quasi-harmonic approach (e.g., Schlitter equation) or by normal mode analysis (Gohlke and Case, 2004). Entropy calculations would require a full sampling of the free energy landscape, an extremely computationally demanding step, which can result in unreliable results (Brown and Muchmore, 2009) with standard errors usually one order of magnitude larger than those associated with the other energetic components (Kar et al., 2011). In addition, the normal mode analysis estimation is often extremely qualitative (Cheatham et al., 1998) and the configuration entropy estimate on a short dynamic time range can be non-significant (Majumdar et al., 2011). Based on these considerations, we decided to neglect the entropic term in our calculations, leading to a one-parameter model:
where with α = 1 is the canonical MM-PBSA method, α = 0.2 is the new dMM-PBSA method discussed in this work. The standard error (SE) is calculated as follows:
where σ is the standard deviation and N is the number of averaged structures (N = 4).
Briefly, the protocol obtains the Molecular Mechanics (MM) terms, including intermolecular van der Waals and coulombic terms, for each complex from the HADDOCK output file energies.disp. Then, the get_average.inp protocol file is modified in order to re-generate the complexes file inserting the partial charges and radii according to the PQR format.
The same PQR files were used for the Poisson–Boltzmann calculations (Gsolv), in order to ensure consistency across the two solvers APBS and DelPhi. Preserving partial charges and intrinsic PB radii is important, as they might significantly affect the outcomes. Notably, each program returns results in different energy units; APBS reports in kJ/mol, and DelPhi reports in kT. All results in this paper are converted to kJ/mol to ease comparison. In APBS six calculations are performed, one for each component in either solvent or “dry” (uniform dielectric εext = εint = 2) environment. The energy (Gsolv) is reported in the “elecEnergy” term and the ΔGsolv is then calculated again by subtracting the receptor and ligand from the complex in each environment and then subtracting the values from the dry environment from those of the solvated environment (εext = 80). For DelPhi, six calculations are performed, one for each component both in the presence or absence of salt/ions. The energy ΔGsolv term used is the difference in “corrected reaction field energy” from the calculations without salt, as well as the difference in the “total grid” energies calculated with and without salt. Surface Area is calculated using the apbs built-in function in APBS and NanoShaper functionalities for DelPhi.
Subsequently, the structures of the complex, the protein and the peptide are used to perform the PBSA calculations. HADDOCKPBSA then generates a grid suitable for the calculations for all the structures: the coordinate extremes of the complexes in each dimension are extracted, and 20 and 10 Å are added to each value to set the limits of the coarse and fine grids, respectively. The tool then automatically calculates the number of grid points that is feasible for APBS and DelPhi calculations and builds a mesh finer than 0.5 Å. When all calculations are completed, the final MM-PBSA value is calculated as the sum of the van der Waals and coulombic terms (calculated by HADDOCK) and the polar and non-polar solvation terms (calculated by APBS and DelPhi). HADDOCKPBSA can also extract the HADDOCK scores values and conveniently generate output files that ease the comparison with the MM-PBSA values. HADDOCKPBSA tool is a set of bash script interfacing HADDOCK output with both APBS and DelPhi Poisson–Boltzmann solvers, which need to be installed on their own. HADDOCPBSA is available on the HADDOCK GitHub repository (https://github.com/haddocking).
Computation Time
The PBSA terms were calculated with the two different programs, APBS and DelPhi/NanoShaper. Calculations were carried out on a personal computer with CPU i7 dual-quad core and 16 GB of memory. The time-averaged calculation of the MM part relies on the HADDOCK calculations, which are performed on the clusters. The post-processing time-averaged calculation of the PBSA terms is different depending on the program used. APBS program allows to calculate all-in-once, including PB and SA terms, using the apbs tool and it requires ~120 s per complex (about 1000–1500 atoms on average), whereas DelPhi and NanoShaper requires ~12.5 s per complex. Each system comprises 200 putative poses, for a total of 4200 structures analyzed. The performance of the DelPhi solver benefits from the specific approach it uses to estimate the reaction field energy. As described in Rocchia et al. (2001, 2002) the procedure is kept analytical as far as possible. The polarization charge in each grid cube at the boundary between high and low dielectric constant is calculated via Gauss law, then its position is relocated by projecting it over the analytical expression of the Connolly molecular surface. This permits, on one side, to avoid double PBE solution using different dielectric constant values, and, on the other, to get results which are particularly robust regarding position and orientation of the system with respect to the grid. Robustness and efficiency are further enhanced by coupling DelPhi solver with NanoShaper, as shown in Decherchi and Rocchia (2013).
Statistical Treatment of the Derived Data
Linear correlation between calculated and experimental binding affinities was evaluated via the Pearson product-moment correlation coefficient (R). p-values from two-tailed Gaussian probability were determined for each data set using the R, and the sample size information, assuming that correlations are statistically significant if p < 0.05. Due to the relatively small size of the samples, we preliminarily performed the Shapiro-Wilk normality test. This test indicated that our data can be modeled according to the normal distribution, (W parameter of 0.96, >0.90, which represents the threshold for 5% significance level). Moreover, the associated p-value is 0.63, much greater than 0.05, which is the common accepted threshold to consider a distribution normal. The standard error is calculated as σ/√N, where σ is the standard deviation and N the number of structures (i.e., N = 4 for each clusterBEST4).
Author Contributions
DS, designed research, ran experiments, analyzed results, wrote the paper; PK designed research, ran experiments, analyzed results; AM designed research, ran experiments, analyzed results; AB designed research, analyzed results; GM designed research, analyzed results, wrote the paper; WR analyzed results, wrote the paper; AS, designed research, ran experiments, analyzed results, wrote the paper.
Funding
The research leading to these results has received funding under the Horizon 2020 Program, FET-Open: PROSEQO, Grant Agreement n. [687089]. AS acknowledges funding from AIRC (Associazione Italiana Ricerca sul Cancro) through grant MFAG11899. The development of HADDOCK is supported by grants from the Netherlands Organization for Scientific Research (NWO) (TOP-PUNT grant no. 718.015.001) and by European H2020 e-Infrastructure grants (EGI-Engage, grant no. 654142; INDIGO-DataCloud, grant no. 653549; West-Life grant no. 675858 and BioExcel grant no. 675728). The EGI infrastructure and DIRAC4EGI service with the dedicated support of CESNET-MetaCloud, INFN-PADOVA, NCG-INGRID-PT, RAL-LCG2, TW-NCHC, SURFsara and NIKHEF, and the additional support of the national GRID Initiatives of Belgium, France, Italy, Germany, the Netherlands, Poland, Portugal, Spain, UK, South Africa, Malaysia, Taiwan and the US Open Science Grid are acknowledged.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/article/10.3389/fmolb.2016.00046
Figure S1. Representative of MM-PBSA values of the 200 poses of 1CKA system calculated using APBS (x-axis) vs. DelPhi (y-axis) solvers. The other cases study show similar behavior plot.
Figure S2. Representative of dMM-PBSA (εsolute = 2 and α = 0.2) values vs. MM-PBSA using εsolute = 5 and α = 1 of the 200 poses of 1CKA system calculated using DelPhi solver. There is a good correlation between calculating ΔGcomp with high εsolute and α, i.e., standard MM-PBSA, and low εsolute and α (dMM-PBSA). Both approaches reduce the ΔGpolar term favoring better correlation with experimental data.
Figure S3. HADDOCK score (top), MM-PBSA (middle), and dMM-PBSA (bottom) calculations of native and mutant AIRE-PHD1/H3K4me0 complexes plotted vs. the experimental binding free energy.
References
Acampora, G., and Hermans, J. (1967). Reversible denaturation of sperm whale myoglobin. I. Dependence on temperature, pH, and composition. J. Am. Chem. Soc. 89, 1543–1547. doi: 10.1021/ja00983a001
Baker, N. A., Sept, D., Joseph, S., Holst, M. J., and McCammon, J. A. (2001). Electrostatics of nanosystems: Application to microtubules and the ribosome. Proc. Natl. Acad. Sci. U.S.A. 98, 10037–10041. doi: 10.1073/pnas.181342398
Barakat, K. H., Jordheim, L. P., Perez-Pineiro, R., Wishart, D., Dumontet, C., and Tuszynski, J. A. (2012). Virtual screening and biological evaluation of inhibitors targeting the XPA-ERCC1 interaction. PLoS ONE 7:e51329. doi: 10.1371/journal.pone.0051329
Berman, H. M., Westbrook, J., Feng, Z., Gilliland, G., Bhat, T. N., Weissig, H., et al. (2000). The Protein Data Bank. Nucleic Acids Res. 28, 235–242. doi: 10.1093/nar/28.1.235
Brown, S. P., and Muchmore, S. W. (2009). Large-scale application of high-throughput molecular mechanics with Poisson-Boltzmann surface area for routine physics-based scoring of protein-ligand complexes. J. Med. Chem. 52, 3159–3165. doi: 10.1021/jm801444x
Cheatham, T. E., Srinivasan, J., Case, D. A., and Kollman, P. A. (1998). Molecular dynamics and continuum solvent studies of the stability of PolyG-PolyC and PolyA-PolyT DNA Duplexes in Solution. J. Biomol. Struct. Dyn. 16, 265–280. doi: 10.1080/07391102.1998.10508245
Chignola, F., Gaetani, M., Rebane, A., Org, T., Mollica, L., Zucchelli, C., et al. (2009). The solution structure of the first PHD finger of autoimmune regulator in complex with non-modified histone H3 tail reveals the antagonistic role of H3R2 methylation. Nucleic Acids Res. 37, 2951–2961. doi: 10.1093/nar/gkp166
Decherchi, S., and Rocchia, W. (2013). A general and robust ray-casting-based algorithm for triangulating surfaces at the nanoscale. PLoS ONE 8:e59744. doi: 10.1371/journal.pone.0059744
de Vries, S. J., van Dijk, A. D. J., Krzeminski, M., van Dijk, M., Thureau, A., Hsu, V., et al. (2007). HADDOCK versus HADDOCK: New features and performance of HADDOCK2.0 on the CAPRI targets. Proteins 69, 726–733. doi: 10.1002/prot.21723
de Vries, S. J., van Dijk, M., and Bonvin, A. M. J. J. (2010). The HADDOCK web server for data-driven biomolecular docking. Nat. Protoc. 5, 883–897. doi: 10.1038/nprot.2010.32
Dominguez, C., Boelens, R., and Bonvin, A. M. J. J. (2003). HADDOCK: a protein−protein docking approach based on biochemical or biophysical information. J. Am. Chem. Soc. 125, 1731–1737. doi: 10.1021/ja026939x
Feig, M., Onufriev, A., Lee, M. S., Im, W., Case, D. A., and Brooks, C. L. (2004). Performance comparison of generalized born and Poisson methods in the calculation of electrostatic solvation energies for protein structures. J. Comput. Chem. 25, 265–284. doi: 10.1002/jcc.10378
Genheden, S., and Ryde, U. (2015). The MM/PBSA and MM/GBSA methods to estimate ligand-binding affinities. Expert Opin. Drug Discov. 10, 449–461. doi: 10.1517/17460441.2015.1032936
Gilson, M. K., and Zhou, H.-X. (2007). Calculation of protein-ligand binding affinities. Annu. Rev. Biophys. Biomol. Struct. 36, 21–42. doi: 10.1146/annurev.biophys.36.040306.132550
Gohlke, H., and Case, D. A. (2004). Converging free energy estimates: MM-PB(GB)SA studies on the protein-protein complex Ras-Raf. J. Comput. Chem. 25, 238–250. doi: 10.1002/jcc.10379
Graves, A. P., Shivakumar, D. M., Boyce, S. E., Jacobson, M. P., Case, D. A., and Shoichet, B. K. (2008). Rescoring docking hit lists for model cavity sites: predictions and experimental testing. J. Mol. Biol. 377, 914–934. doi: 10.1016/j.jmb.2008.01.049
Harris, R. C., Boschitsch, A. H., and Fenley, M. O. (2013). Influence of grid spacing in poisson-boltzmann equation binding energy estimation. J. Chem. Theory Comput. 9, 3677–3685. doi: 10.1021/ct300765w
Hennig, J., de Vries, S. J., Hennig, K. D. M., Randles, L., Walters, K. J., Sunnerhagen, M., et al. (2012). MTMDAT-HADDOCK: high-throughput, protein complex structure modeling based on limited proteolysis and mass spectrometry. BMC Struct. Biol. 12:29. doi: 10.1186/1472-6807-12-29
Hetényi, C., and van der Spoel, D. (2002). Efficient docking of peptides to proteins without prior knowledge of the binding site. Protein Sci. 11, 1729–1737. doi: 10.1110/ps.0202302
Homeyer, N., and Gohlke, H. (2012). Free energy calculations by the molecular mechanics Poisson−Boltzmann surface area method. Mol. Inform. 31, 114–122. doi: 10.1002/minf.201100135
Hou, T., Wang, J., Li, Y., and Wang, W. (2011). Assessing the performance of the MM / PBSA and MM / GBSA methods. I. The accuracy of binding free energy calculations based on molecular dynamics simulations. J. Chem. Inf. Model. 51, 69–82. doi: 10.1021/ci100275a
Huang, S.-Y., Grinter, S. Z., and Zou, X. (2010). Scoring functions and their evaluation methods for protein-ligand docking: recent advances and future directions. Phys. Chem. Chem. Phys. 12, 12899–12908. doi: 10.1039/C0CP00151A
Kar, P., Lipowsky, R., and Knecht, V. (2011). Importance of polar solvation for cross-reactivity of antibody and its variants with steroids. J. Phys. Chem. B 115, 7661–7669. doi: 10.1021/jp201538t
Kastritis, P. L., Rodrigues, J. P. G. L. M., and Bonvin, A. M. J. J. (2014). HADDOCK2P2I: a biophysical model for predicting the binding affinity of protein–protein interaction inhibitors. J. Chem. Inf. Model. 54, 826–836. doi: 10.1021/ci4005332
Kitchen, D. B., Decornez, H., Furr, J. R., and Bajorath, J. (2004). Docking and scoring in virtual screening for drug discovery: methods and applications. Nat. Rev. Drug Discov. 3, 935–949. doi: 10.1038/nrd1549
Kongsted, J., Söderhjelm, P., and Ryde, U. (2009). How accurate are continuum solvation models for drug-like molecules? J. Comput. Aided Mol. Des. 23, 395–409. doi: 10.1007/s10822-009-9271-6
Kuhn, B., Gerber, P., Schulz-Gasch, T., and Stahl, M. (2005). Validation and use of the MM-PBSA approach for drug discovery. J. Med. Chem. 48, 4040–4048. doi: 10.1021/jm049081q
Kuntz, I. D., Blaney, J. M., Oatley, S. J., Langridge, R., and Ferrin, T. E. (1982). A geometric approach to macromolecule-ligand interactions. J. Mol. Biol. 161, 269–288.
Liu, J., He, X., and Zhang, J. Z. H. (2013). Improving the scoring of protein–ligand binding affinity by including the effects of structural water and electronic polarization. J. Chem. Inf. Model. 53, 1306–1314. doi: 10.1021/ci400067c
Maffucci, I., and Contini, A. (2013). Explicit ligand hydration shells improve the correlation between MM-PB/GBSA binding energies and experimental activities. J. Chem. Theory Comput. 9, 2706–2717. doi: 10.1021/ct400045d
Majumdar, R., Railkar, R., and Dighe, R. R. (2011). Docking and free energy simulations to predict conformational domains involved in hCG–LH receptor interactions using recombinant antibodies. Proteins 79, 3108–3122. doi: 10.1002/prot.23138
Massova, I., and Kollman, P. A. (1999). Computational alanine scanning to probe protein−protein interactions: a novel approach to evaluate binding free energies. J. Am. Chem. Soc. 121, 8133–8143. doi: 10.1021/ja990935j
Meng, X.-Y., Zhang, H.-X., Mezei, M., and Cui, M. (2011). Molecular docking: a powerful approach for structure-based drug discovery. Curr. Comput. Aided Drug Des. 7, 146–157. doi: 10.2174/157340911795677602
Niv, M. Y., and Weinstein, H. (2005). A flexible docking procedure for the exploration of peptide binding selectivity to known structures and homology models of PDZ domains. J. Am. Chem. Soc. 127, 14072–14079. doi: 10.1021/ja054195s
Paissoni, C., Spiliotopoulos, D., Musco, G., and Spitaleri, A. (2014). GMXPBSA 2.0: A GROMACS tool to perform MM/PBSA and computational alanine scanning. Comput. Phys. Commun. 185, 2920–2929. doi: 10.1016/j.cpc.2014.06.019
Raveh, B., London, N., and Schueler-Furman, O. (2010). Sub-angstrom modeling of complexes between flexible peptides and globular proteins. Proteins 78, 2029–2040. doi: 10.1002/prot.22716
Raveh, B., London, N., Zimmerman, L., and Schueler-Furman, O. (2011). Rosetta FlexPepDock ab-initio: simultaneous folding, docking and refinement of peptides onto their receptors. PLoS ONE 6:e18934. doi: 10.1371/journal.pone.0018934
Rocchia, W., Alexov, E., and Honig, B. (2001). Extending the applicability of the nonlinear poisson−boltzmann equation: multiple dielectric constants and multivalent ions. J. Phys. Chem. B 105, 6507–6514. doi: 10.1021/jp010454y
Rocchia, W., Sridharan, S., Nicholls, A., Alexov, E., Chiabrera, A., and Honig, B. (2002). Rapid grid-based construction of the molecular surface and the use of induced surface charge to calculate reaction field energies: applications to the molecular systems and geometric objects. J. Comput. Chem. 23, 128–137. doi: 10.1002/jcc.1161
Rognan, D. (2013). Proteome-scale docking: myth and reality. Drug Discov. Today Technol. 10, e403–409. doi: 10.1016/j.ddtec.2013.01.003
Sarti, E., Zamuner, S., Cossio, P., Laio, A., Seno, F., and Trovato, A. (2013). BACHSCORE. A tool for evaluating efficiently and reliably the quality of large sets of protein structures. Comput. Phys. Commun. 184, 2860–2865. doi: 10.1016/j.cpc.2013.07.019
Scott, D. E., Bayly, A. R., Abell, C., and Skidmore, J. (2016). Small molecules, big targets: drug discovery faces the protein-protein interaction challenge. Nat. Rev. Drug Discov. 15, 533–550. doi: 10.1038/nrd.2016.29
Singh, N., and Warshel, A. (2010). Absolute binding free energy calculations: on the accuracy of computational scoring of protein–ligand interactions. Proteins 78, 1705–1723. doi: 10.1002/prot.22687
Sørensen, J., Fenley, M. O., and Amaro, R. E. (2015). “A comprehensive exploration of physical and numerical parameters in the Poisson–Boltzmann equation for applications to receptor–ligand binding,” in Computational Electrostatics for Biological Applications: Geometric and Numerical Approaches to the Description of Electrostatic Interaction Between Macromolecules, eds W. Rocchia and M. Spagnuolo (Cham: Springer International Publishing), 39–71.
Spiliotopoulos, D., and Caflisch, A. (2014). Molecular dynamics simulations of bromodomains reveal binding-site flexibility and multiple binding modes of the natural ligand acetyl-lysine. Isr. J. Chem. 54, 1084–1092. doi: 10.1002/ijch.201400009
Spiliotopoulos, D., Spitaleri, A., and Musco, G. (2012). Exploring PHD fingers and H3K4me0 interactions with molecular dynamics simulations and binding free energy calculations: AIRE-PHD1, a comparative study. PLoS ONE 7:e46902. doi: 10.1371/journal.pone.0046902
Thompson, D. C., Humblet, C., and Joseph-McCarthy, D. (2008). Investigation of MM-PBSA rescoring of docking poses. J. Chem. Inf. Model. 48, 1081–1091. doi: 10.1021/ci700470c
Treesuwan, W., and Hannongbua, S. (2009). Bridge water mediates nevirapine binding to wild type and Y181C HIV-1 reverse transcriptase—Evidence from molecular dynamics simulations and MM-PBSA calculations. J. Mol. Graph. Model. 27, 921–929. doi: 10.1016/j.jmgm.2009.02.007
Trellet, M., Melquiond, A. S. J., and Bonvin, A. M. J. J. (2013). A unified conformational selection and induced fit approach to protein-peptide docking. PLoS ONE 8:e58769. doi: 10.1371/journal.pone.0058769
van Dijk, A. D. J., de Vries, S. J., Dominguez, C., Chen, H., Zhou, H. X., and Bonvin, A. M. J. J. (2005). Data-driven docking: HADDOCK's adventures in CAPRI. Proteins 60, 232–238. doi: 10.1002/prot.20563
Venken, T., Krnavek, D., Münch, J., Kirchhoff, F., Henklein, P., De Maeyer, M., et al. (2011). An optimized MM/PBSA virtual screening approach applied to an HIV-1 gp41 fusion peptide inhibitor. Proteins 79, 3221–3235. doi: 10.1002/prot.23158
Verkhivker, G. M., Bouzida, D., Gehlhaar, D. K., Rejto, P. A., Arthurs, S., Colson, A. B., et al. (2000). Deciphering common failures in molecular docking of ligand-protein complexes. J. Comput. Aided Mol. Des. 14, 731–751. doi: 10.1023/A:1008158231558
Wang, B., Li, L., Hurley, T. D., and Meroueh, S. O. (2013). Molecular recognition in a diverse set of protein-ligand interactions studied with molecular dynamics simulations and end-point free energy calculations. J. Chem. Inf. Model. 53, 2659–2670. doi: 10.1021/ci400312v
Wang, J., Morin, P., Wang, W., and Kollman, P. A. (2001). Use of MM-PBSA in reproducing the binding free energies to HIV-1 RT of TIBO derivatives and predicting the binding mode to HIV-1 RT of efavirenz by docking and MM-PBSA. J. Am. Chem. Soc. 123, 5221–5230. doi: 10.1021/ja003834q
Weis, A., Katebzadeh, K., Söderhjelm, P., Nilsson, I., and Ryde, U. (2006). Ligand affinities predicted with the MM/PBSA method: dependence on the simulation method and the force field. J. Med. Chem. 49, 6596–6606. doi: 10.1021/jm0608210
Wodarczyk, C., Distefano, G., Rowe, I., Gaetani, M., Bricoli, B., Muorah, M., et al. (2010). Nephrocystin-1 forms a complex with Polycystin-1 via a polyproline Motif/SH3 domain interaction and regulates the apoptotic response in mammals. PLoS ONE 5:e12719. doi: 10.1371/journal.pone.0012719
Yang, T., Wu, J. C., Yan, C., Wang, Y., Luo, R., Gonzales, M. B., et al. (2011). Virtual screening using molecular simulations. Proteins 79, 1940–1951. doi: 10.1002/prot.23018
Zhou, Z., Wang, Y., and Bryant, S. H. (2009). Computational analysis of the cathepsin B inhibitors activities through LR-MMPBSA binding affinity calculation based on docked complex. J. Comput. Chem. 30, 2165–2175. doi: 10.1002/jcc.21214
Keywords: MM-PBSA, scoring function, binding free energies, haddock, protein-peptide interaction
Citation: Spiliotopoulos D, Kastritis PL, Melquiond ASJ, Bonvin AMJJ, Musco G, Rocchia W and Spitaleri A (2016) dMM-PBSA: A New HADDOCK Scoring Function for Protein-Peptide Docking. Front. Mol. Biosci. 3:46. doi: 10.3389/fmolb.2016.00046
Received: 04 July 2016; Accepted: 16 August 2016;
Published: 31 August 2016.
Edited by:
Matthias Buck, Case Western Reserve University, USAReviewed by:
Alemayehu A. Gorfe, University of Texas Health Science Center at Houston, USAMichael Garton, University of Toronto, Canada
Copyright © 2016 Spiliotopoulos, Kastritis, Melquiond, Bonvin, Musco, Rocchia and Spitaleri. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Andrea Spitaleri, andrea.spitaleri@iit.it