Schizophrenia-Mimicking Layers Outperform Conventional Neural Network Layers
 Ryuta Mizutani1*
Ryuta Mizutani1*  Senta Noguchi1 Rino Saiga1
Senta Noguchi1 Rino Saiga1  Yuichi Yamashita2
Yuichi Yamashita2  Mitsuhiro Miyashita3
Mitsuhiro Miyashita3  Makoto Arai3
Makoto Arai3  Masanari Itokawa3,4
Masanari Itokawa3,4- 1Department of Applied Biochemistry, Tokai University, Hiratsuka, Japan
- 2Department of Information Medicine, National Institute of Neuroscience, National Center of Neurology and Psychiatry, Tokyo, Japan
- 3Department of Psychiatry and Behavioral Sciences, Tokyo Metropolitan Institute of Medical Science, Tokyo, Japan
- 4Department of Psychiatry, Tokyo Metropolitan Matsuzawa Hospital, Tokyo, Japan
We have reported nanometer-scale three-dimensional studies of brain networks of schizophrenia cases and found that their neurites are thin and tortuous when compared to healthy controls. This suggests that connections between distal neurons are suppressed in microcircuits of schizophrenia cases. In this study, we applied these biological findings to the design of a schizophrenia-mimicking artificial neural network to simulate the observed connection alteration in the disorder. Neural networks that have a “schizophrenia connection layer” in place of a fully connected layer were subjected to image classification tasks using the MNIST and CIFAR-10 datasets. The results revealed that the schizophrenia connection layer is tolerant to overfitting and outperforms a fully connected layer. The outperformance was observed only for networks using band matrices as weight windows, indicating that the shape of the weight matrix is relevant to the network performance. A schizophrenia convolution layer was also tested using the VGG configuration, showing that 60% of the kernel weights of the last three convolution layers can be eliminated without loss of accuracy. The schizophrenia layers can be used instead of conventional layers without any change in the network configuration and training procedures; hence, neural networks can easily take advantage of these layers. The results of this study suggest that the connection alteration found in schizophrenia is not a burden to the brain, but has functional roles in brain performance.
Introduction
Artificial neural networks were originally designed by modeling the information processing of the brain (Rosenblatt, 1958). The primate brain is subdivided into functionally different areas, such as the visual cortex of the occipital lobe and the auditory cortex of the temporary lobe (Brodmann, 1909; Amunts and Zilles, 2015). Studies on the visual cortex (Hubel and Wiesel, 1959) inspired the development of the convolutional neural network (Fukushima, 1980) that has evolved into a wide variety of network configurations (Simonyan and Zisserman, 2014; He et al., 2016). Structural analysis of human brain networks and incorporation of resultant biological knowledge into artificial intelligence algorithms have the potential to improve the performance of machine learning.
Analysis of not only healthy control cases but also cases with psychiatric disorders can provide clues to the design of new artificial neural networks. It has been reported that polygenic risk scores for schizophrenia and bipolar disorder were associated with membership in artistic societies and creative professions (Power et al., 2015). A higher incidence of psychiatric disorders was found in geniuses and their families than in the average population (Juda, 1949). This suggests that a possible distinguishing feature of neuronal networks of psychiatric cases can be exploited in the design of unconventional architectures for artificial intelligence.
We recently reported nanometer-scale three-dimensional studies of neuronal networks of schizophrenia cases and age/gender-matched controls by using synchrotron radiation nanotomography or nano-CT (Mizutani et al., 2019, 2021). The results indicated that the neurites of the schizophrenia cases are thin and tortuous, while those of the control cases are thick and straight. The nano-CT analysis also revealed that the diameters of the neurites are proportional to the diameters of the dendritic spines, which form synaptic connections between neurons. It has been reported that thinning of neurites or spines attenuates the firing efficiency of neurons (Spruston, 2008) and hence affects the activity of the areas to which they belong.
In this study, we incorporated these biological findings in artificial neural networks to delineate (1) how well the neuronal microcircuit tolerates the structural alterations observed in schizophrenia and (2) how we can incorporate those findings into an artificial neural network to improve its performance. The analyses were performed by using newly designed layers that mimic the connection alteration in schizophrenia. The obtained results indicated that the schizophrenia layers tolerate parameter reductions up to 80% of the weights and outperform conventional layers.
Materials and Methods
Design of Schizophrenia-Mimicking Layers
The etiology of schizophrenia has been discussed from neurodegenerative and neurodevelopmental standpoints (Allin and Murray, 2002; Gupta, 2010). The neurodegenerative hypothesis claims that schizophrenia is a disorder due to degeneration in the brain. Another neurodevelopmental hypothesis proposes that the brain network forms abnormally during the developmental process. The etiology of schizophrenia has also been discussed on the basis of the two-hit hypothesis (Maynard et al., 2001), wherein the “first hit” during early development primes the pathogenic response and “second hit” later in the life causes the disorder.
We translated these understandings of the disorder into two working models of artificial neural networks (Figure 1). The first one is a disorganized model. This model mimics neurodegeneration after the formation of the cerebral neuronal network. This can be simulated by training an artificial neural network in the usual manner and then disorganizing it so that a posteriori disorganization simulates neurodegeneration after the formation of the network. Another working model is the developmental model, in which we assume concurrent progress of neuropathological changes and brain development. This developmental model can be simulated by implementing a connection-modified layer in the neural network, which is trained under the modification. Analysis of these models should reveal how the intervention affects network performance.
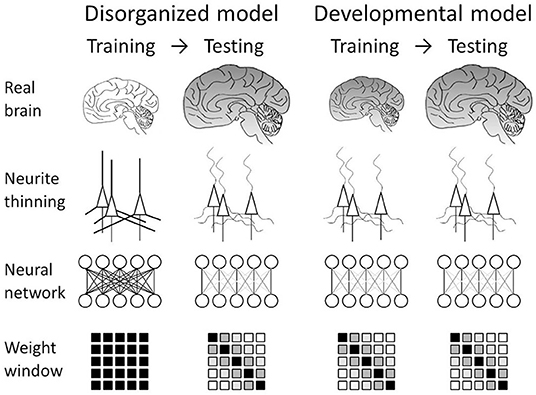
Figure 1. Neural network models mimicking schizophrenia. Our nanotomography study revealed that neurites become thin and tortuous in schizophrenia. We translated this finding into two models. In the disorganized model, the structural alteration is incorporated as neurodegeneration after the formation of the brain network. This can be simulated by training the network in the usual manner and then testing it while damping weights between distal nodes. The developmental model assumes concurrent progress of neuropathological changes and brain development. This can be simulated by using a connection-modified layer, in which distal connections are damped during both training and testing.
The thinning of neurites in schizophrenia (Mizutani et al., 2019, 2021) should hinder the transmission of the input potentials depending on the length of the neurite from the soma (Spruston, 2008). Therefore, distal synaptic connections should deteriorate more than proximal connections. This phenomenon can be reproduced in an artificial neural network by defining a distance measure between the nodes and by damping the connection parameters depending on the distance measure. Here, we assume a one-dimensional arrangement of nodes and define the distance dij of the connection between input node ix and output node jy as , where is the ratio of the number of nodes between the target and the preceding layers. This distance measure is equal to the Euclidean distance between an off-diagonal element and the diagonal in the weight matrix. Since this distance measure is defined in terms of the number of nodes, it is proportional to the neuronal soma size (typically 10–30 μm) and hence can be approximately converted into a real distance by multiplying it by the soma size. The window matrix was prepared by using the above distance measure to modify the weight matrix. Figure 2 shows examples of window matrixes having identical numbers of inputs and outputs. Diagonal connection alteration (Figure 2B) is performed by zeroing the weight parameters if their distances from the diagonal are larger than a threshold. This can be implemented by masking the weight matrix with a window matrix F = (fij), where elements fij distal to the diagonal are set to 0 and elements fij proximal to the diagonal are set to 1. A Gaussian window (Figure 2C) has matrix elements fij of a Gaussian form: , where σ represents the window width. Other window variations (Figures 2D–F) designed differently from the abovementioned distance idea were also used (Figure 2). The parameter reduction ratio was defined as the ratio between the sum of window elements and the total number of weights. The weight matrix was multiplied by the window matrix in an element-by-element manner and then normalized with the parameter reduction ratio so as to keep the sum of weights unchanged.

Figure 2. Schematic drawings of weight windows. These drawings assume a 5 × 5 square matrix of the weight. Each tiny box indicates an element of the matrix. Window values are represented with gray scale from 0 (white) to 1 (black). (A) Fully connected network. (B) Diagonal window representing connection alteration in schizophrenia. Weight elements indicated with black boxes were used for training and/or evaluation. Elements of open boxes were set to zero and were not used in the training and/or evaluation. (C) Gaussian window mimicking distance-dependent gradual decrease in the real neuronal connection. (D) Stripe window. (E) Centered window. (F) Random window.
Implementation and Examination of Schizophrenia Layers
The influences of these connection alterations on the neural network were examined using the MNIST handwritten digits dataset (LeCun et al., 1998) and the CIFAR-10 picture dataset (Krizhevsky, 2009). Hereafter, we call the fully connected layer masked with the schizophrenia window the “schizophrenia connection layer” and the convolution layer with the schizophrenia window the “schizophrenia convolution layer.” The network configurations used for the image classification tasks are summarized in Table 1 and fully described in Table S1. Simple 3- and 4-layer configurations (Table 1, networks A and B) were used in the MNIST classification tasks. Network A with one schizophrenia connection layer as a hidden layer was used for the analysis of the developmental model, in which the connection alteration was incorporated in the training and the evaluation. Network B was used for the analysis of the disorganized model, in which the connection alteration was incorporated only in the evaluation step. In network B, a pair of a fully connected layer and a schizophrenia connection layer with identical numbers of nodes was implemented as hidden layers to prepare square weight matrixes of different sizes, which were used to analyze the effect of the dimension of the weight matrix on the connection alteration. Convolutional networks C–E (Table 1) were used in the classification tasks run on the CIFAR-10 dataset. The configuration of networks C and D was taken from the Keras example code. These networks were used for testing the schizophrenia connection layer as top layers. Network C was used for the analysis of the developmental model and D for the disorganized model. Network E was used for testing the schizophrenia convolution layer along with the schizophrenia connection layer in the VGG16 configuration (Simonyan and Zisserman, 2014). The elements of the kernels of the convolution layers can be regarded as two-dimensional weight arrays, which were masked with the diagonal window. Batch normalization (Ioffe and Szegedy, 2015) and dropout (Srivastava et al., 2014) layers were also incorporated in network E (Table S1E).
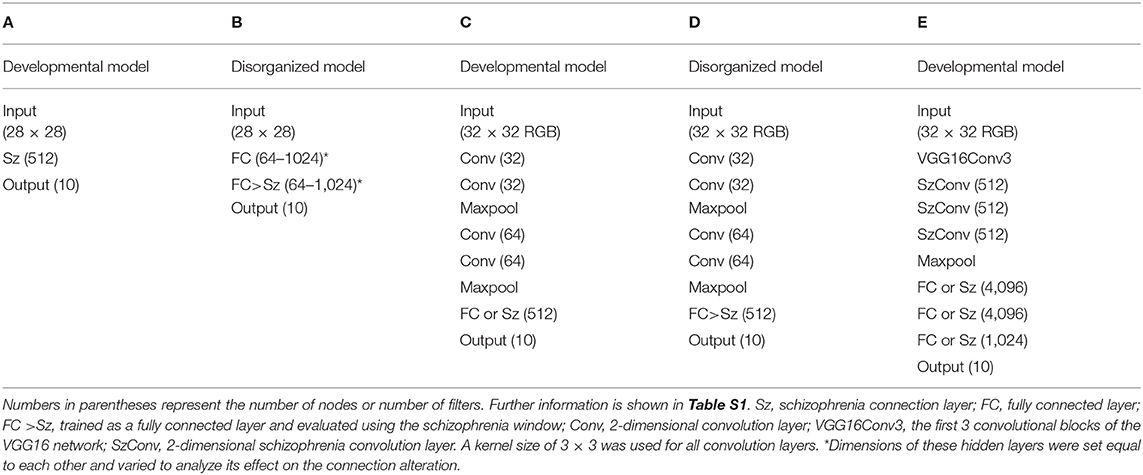
Table 1. Network configuration.
Computational Experiments
Training and evaluation of networks A–D were conducted using TensorFlow 2.3.0 and Keras 2.4.0 running on the c5a.xlarge (4 vCPUs of AMD EPYC processors operated at 2.8 GHz) or the c5a.2xlarge (8 vCPUs) instance of Amazon Web Service. Training and evaluation of network E were conducted using TensorFlow 2.7.0 and Keras 2.7.0 running on the same instances. The CPU time required for training and evaluating the networks using the schizophrenia layers was slightly shorter than those using the normal layers, though the incorporation of the Gaussian window required additional time to initialize its window elements. The Python codes used in this study are available from our GitHub repository (https://mizutanilab.github.io). Statistical analyses were conducted using R 3.4.3. Significance was defined as p < 0.05.
Biases were enabled in all layers, except for the schizophrenia layers in the disorganized model. This is because biases can be refined in the developmental model but cannot be modified according to the inter-node distance in the evaluation step. The Rectified Linear Unit (ReLU) activation function (Glorot et al., 2011) was used in all of the hidden layers, while softmax was used in the output layers. Hidden layers were initialized with He's method (He et al., 2015). Networks A, B, and E were trained using the Adam algorithm (Kingma and Ba, 2014). Networks A and B were trained with a learning rate of 1 × 10−3. Network E was trained with a learning rate of 5 × 10−4 first, and then with 1 × 10−4 after 150 epochs. Networks C and D were trained using the RMSprop algorithm (Tieleman and Hinton, 2012) with a learning rate of 1 × 10−4 and decay of 1 × 10−6. Batch sizes were set to 32 for networks A–D and 200 for network E. Data augmentation (Wong et al., 2016) was used in the training of network E.
Results
Disorganized Models
Figure 3 summarizes the relationships between the connection alteration and the classification error in the disorganized model, in which training precedes the alteration. Figure 3A shows the dependence on window shape in the MNIST classification tasks, which were conducted using a 4-layer network (Table 1, network B). Weight parameters between two hidden layers of identical numbers of nodes were modified after training in order to mimic neurodegeneration after the formation of the neuronal network. The resultant modified network was subjected to the evaluation using the validation dataset. The results indicated that network B can tolerate a parameter reduction of up to ~60% of the connections between the hidden layers (Figure 3A). The profiles showed little dependence on the window shape except for the centered window, indicating that the contribution of each weight element to the network performance is equivalent independently of their position in the weight matrix.
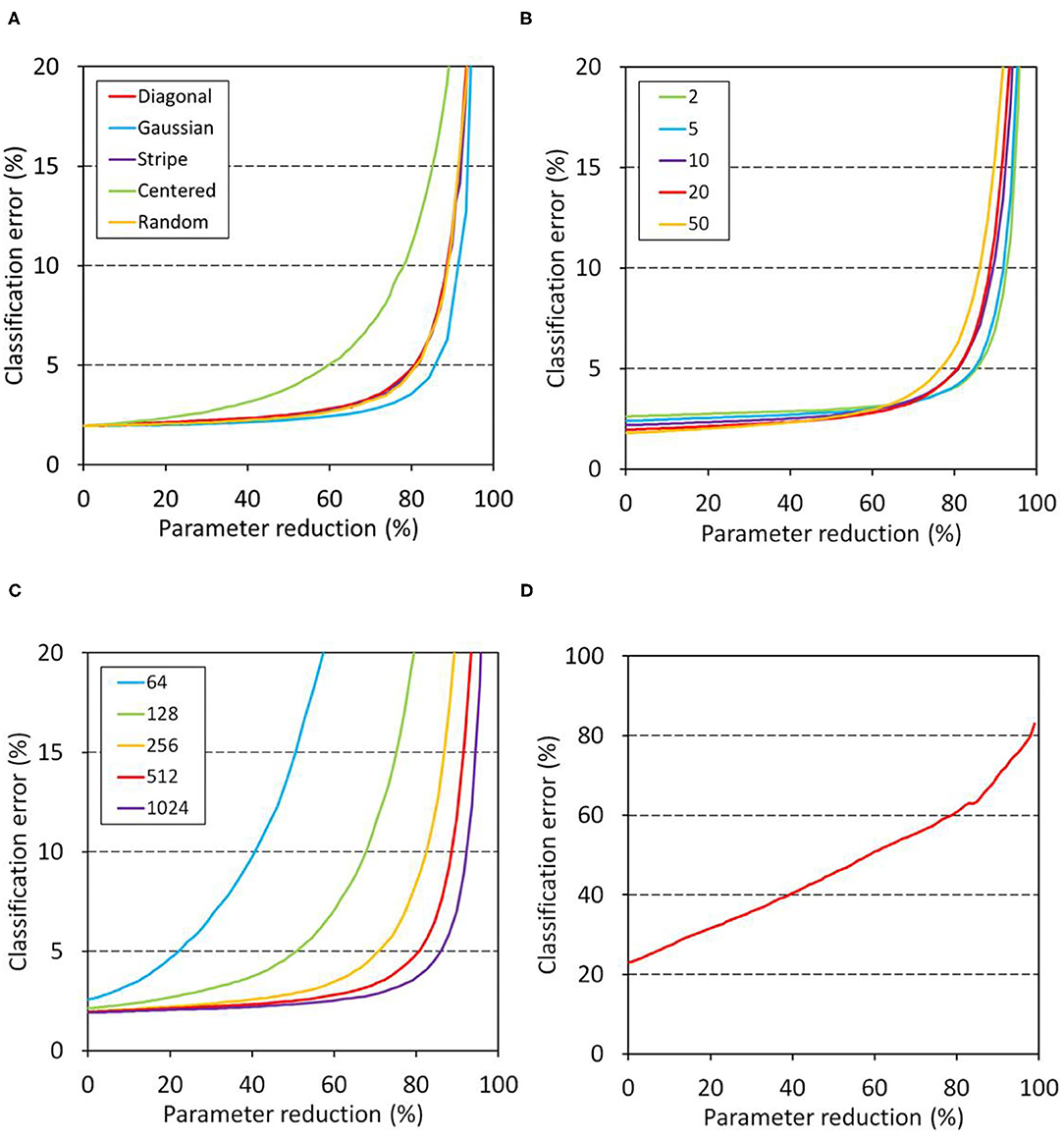
Figure 3. Relationship between classification error and parameter reduction in the disorganized model. Networks were trained first and then the weights of the target layers were masked with a window in the evaluation. The left intercept corresponds to a network with fully connected layers. (A–C) Show the results of MNIST classification. Unless otherwise stated, network B (Table 1) having 512 nodes in the two hidden layers was trained for 20 epochs and then its schizophrenia connection layer was masked using a diagonal window in the evaluation. The training and evaluation were repeated for 100 sessions and their mean errors were plotted. (A) Effect of window shape. (B) Dependence on training duration. (C) Dependence on hidden layer dimensions. (D) Results of CIFAR-10 classification. Network D (Table 1) was trained for 100 epochs, and its top layer was masked using a diagonal window. The training and evaluation were repeated for 30 sessions, and their mean errors are plotted.
Figure 3B shows the dependence on the number of epochs of the disorganized model on the MNIST tasks. The results indicated that the network became slightly more sensitive as the training became longer, suggesting that the redundancy of the weight matrix elements was decreased after a long training duration. Figure 3C shows the relation between the number of nodes and tolerance against connection alteration. The networks having 64 or 128 nodes in the hidden layers became prone to error due to the parameter reduction, while networks having 256 or more nodes in the hidden layers tolerated a parameter reduction up to 60–80% of the weights. These results indicate that the networks having 256 nodes or more have sufficient parameters to store the trained information. In contrast, the CIFAR-10 classification task using network D (Table 1) showed an increase in error that was nearly proportional to the parameter reduction (Figure 3D). This indicates that the information acquired during training is uniformly but not redundantly distributed in the top layer, resulting in the low tolerance of the network against the parameter reduction.
Developmental Models
The developmental model showed distinct features that were not observed in the disorganized models. Figure 4A shows the progress of training of the developmental model (Table 1, network C) on the CIFAR-10 classification tasks, in which the weights of the top layer were masked with a diagonal window throughout the training and evaluation. The task was performed using network C, which consisted of two blocks of convolution layers and one schizophrenia top layer. A network with the same configuration but having a fully connected top layer was used as a control. The obtained results revealed that the schizophrenia network outperformed the control network. The control network showed overfitting approximately after 75 epochs of training, whereas the schizophrenia network showed a continuous decline in error out to 200 epochs. The classification error of the schizophrenia network was significantly lower than that of the control even before the overfitting (p = 0.014 at 75 epochs, and p = 1.1 × 10−5 at 200 epochs, two-sided Wilcoxon test, n1 = n2 = 10). The overfitting of the control network was not suppressed by using the dropout method.
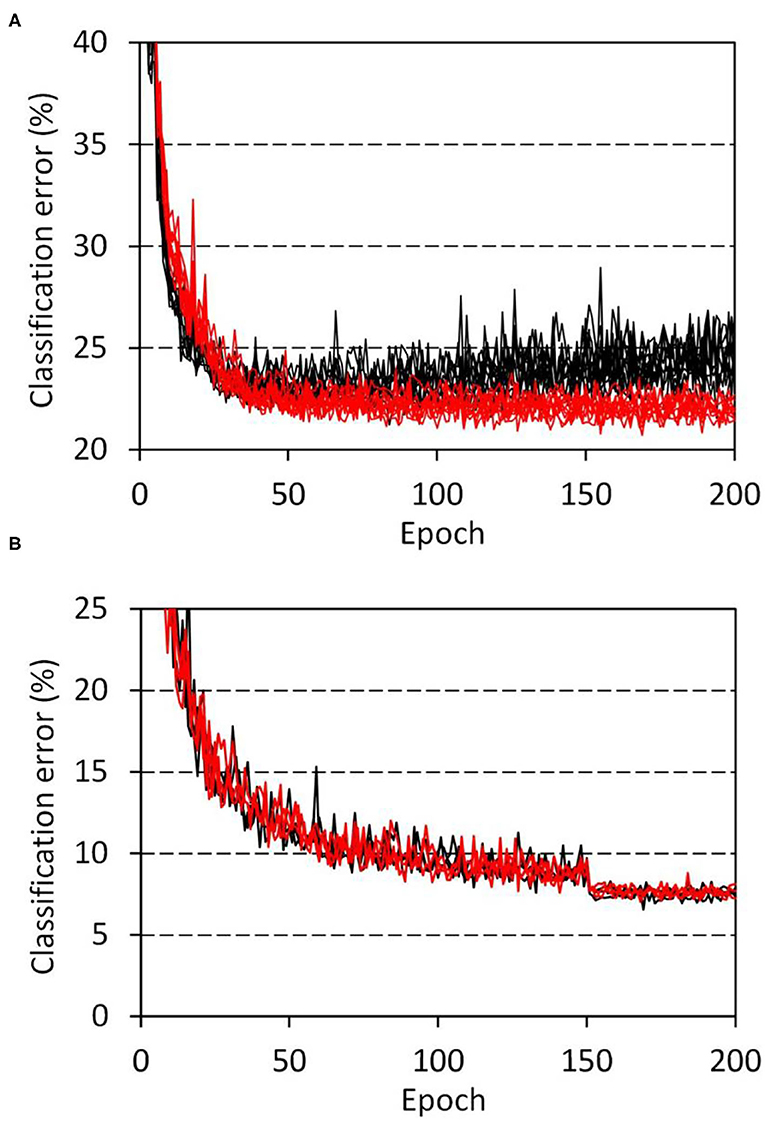
Figure 4. Progress of training in the CIFAR-10 classification tasks. (A) Network C (Table 1) with a schizophrenia connection layer was trained for 10 sessions, and the resultant errors are plotted in red. Parameter reduction in the schizophrenia layer was set to 50%. Errors of the control network with the same configuration but having a fully connected layer are plotted in black. (B) VGG network E (Table 1) with schizophrenia convolution layers was trained for 3 sessions, and the resultant errors are plotted. Results for the schizophrenia network with a 60% parameter reduction in the last three convolution layers are drawn in red, while those of a control network without the parameter reduction are drawn in black.
The connection alteration was also incorporated in the convolution layers by masking the kernel elements with the diagonal window. This schizophrenia convolution layer was implemented in the VGG16 configuration (Table 1, network E) to perform the CIFAR-10 classification tasks. Figure 4B shows the progress of training. The schizophrenia network with a 60% parameter reduction in the last three convolution layers was performed comparably to the control network. This result indicates that the convolution layers of this network contain parameter redundancy that can be eliminated by using the diagonal window. We further replaced the top layers of the VGG network with schizophrenia connection layers and examined the network's performance of the same CIFAR-10 classification task. The obtained results (Figure S1) indicated that half the top layer weights of the VGG network can be eliminated without loss of accuracy by using the schizophrenia connection top layers.
In order to visualize the response of the learned filters of the schizophrenia convolution layer, we replaced the first convolution layer of the VGG16 network (Table 1, network E) with a schizophrenia convolution layer and performed the same CIFAR-10 classification task. Over 40% of the weights of the first convolution layer were eliminated without loss of accuracy, as shown in Figure S2. The obtained responses of the learned filters are shown in Figure 5. These results illustrate that the learned filters of the schizophrenia convolution layer decompose image inputs into RGB channels. This is because the distance in the weight matrix of the schizophrenia convolution layer is defined along the channel dimensions so that the convolutional filters can decode information in a channel-wise manner. In contrast, the filters of the conventional convolution layer showed color-independent patterns due to the absence of restrictions on the weight matrix. Although each kernel of the schizophrenia convolution layer is mostly composed of three primary colors, the network accuracy was the same as that of the native VGG16 network (Figure S2), indicating that the RGB decomposition in the first convolution layer imposes no limitation on image recognition.

Figure 5. Learned filters of (A) schizophrenia convolution layer and (B) conventional convolution layer. In the schizophrenia network, the first convolution layer of the VGG16 network (Table 1, network E) was replaced with a schizophrenia convolution layer, in which 41.7% of the weights were eliminated with a diagonal window.
The relation between performance and the parameter reduction ratio in the developmental model was also examined. Figure 6A shows the results of the three-layer networks on the MNIST classification tasks (Table 1, network A). The classification error of the schizophrenia network was gradually decreased to below that of the control network as the parameter reduction was increased to 70%. The profiles obtained using diagonal and Gaussian windows were almost the same, though the Gaussian window showed stronger tolerance to the parameter reduction than the diagonal window. The stronger tolerance of the Gaussian window suggests that the bilateral tails of the Gaussian function allowed weak connections between distal nodes and mitigated weight masking with the window. In contrast, the network using a random window showed no decrease in error (Figure 6A), indicating that the shape of the diagonal or Gaussian window is relevant to the performance. Figure 6B shows the results of network C on the CIFAR-10 classification tasks. The relation between the error and the parameter reduction was similar to that observed in the MNIST tasks. The profiles shifted toward the lower right as the duration of training became longer, indicating that a schizophrenia connection layer with a larger parameter reduction performs better by training longer. We also examined the effect of conventional L1 regularization by using network C (Table 1). We replaced the schizophrenia top layer of network C with a fully connected layer and introduced conventional L1 regularization to that layer. This L1 regularized network showed virtually no improvement in error (Figure 6B), indicating again that the outperformance is ascribable to the schizophrenia layer.
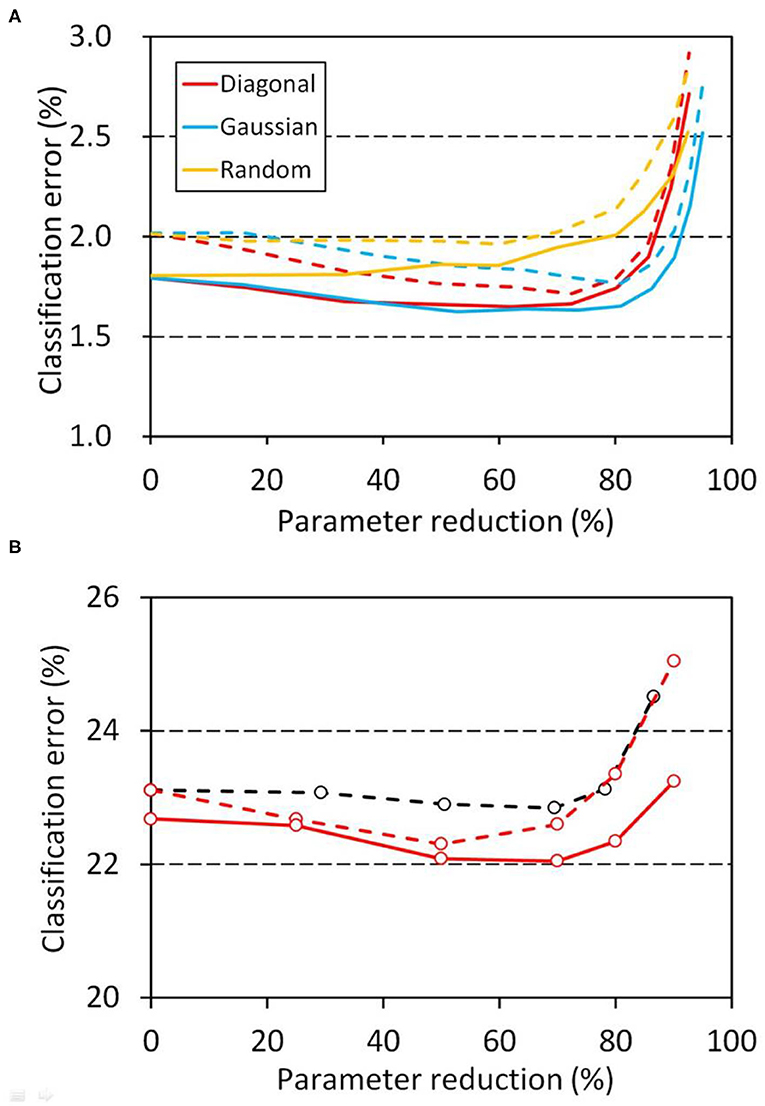
Figure 6. Relation between error and parameter reduction in the developmental model, in which the weights of the schizophrenia connection layers were masked with a window throughout the training and evaluation. The left intercepts correspond to a network with fully connected layers. (A) MNIST classification using network A (Table 1). Training and evaluation were repeated for 100 sessions, and their mean classification errors are plotted. Errors at 10 epochs are plotted with dashed lines and errors at 50 epochs with solid lines. (B) CIFAR-10 classification using network C (Table 1). Training and evaluation were repeated for 10 sessions, and their mean errors are plotted. A diagonal window was used in this task. Errors after 50 epochs are plotted with red dashed lines and errors after 75 epochs with red solid lines. The same classification task was also performed with conventional L1 regularization for 10 sessions, and the resultant mean errors after 50 epochs are plotted with black dashed lines. Weights less than 0.0001 were regarded as zero in the reduction ratio calculation.
Discussion
Related Works
Neural networks were first developed by incorporating biological findings, but until now, the structural aspects of neurons of patients with psychiatric disorders have not been incorporated in studies on artificial intelligence. This is probably because the neuropathology of psychiatric disorders had not been three-dimensionally delineated (Itokawa et al., 2020) before our recent reports regarding the nanometer-scale structure of neurons of schizophrenia cases (Mizutani et al., 2019, 2021). A method called “optimal brain damage” (Le Cun et al., 1990) has been proposed to remove unimportant weights to reduce the number of parameters, although its relation to biological findings, such as those regarding brain injuries, has not been explicitly described.
Parameter reduction and network pruning have been suggested as strategies to simplify the network. It has been reported that simultaneous regularization during training can reduce network connections while maintaining competitive performance (Scardapane et al., 2017). A method to regularize the network structure that includes the filter shapes and layer depth has been reported to allow the network to learn more compact structures without loss of accuracy (Wen et al., 2016). A study on network pruning has suggested that careful evaluations of the structured pruning method are needed (Liu et al., 2018). Elimination of zero weights after training has been proposed as a way to simplify the network (Yaguchi et al., 2018). Improvements in accuracy have been reported for regularized networks (Scardapane et al., 2017; Yaguchi et al., 2018), although these parameter reduction methods require dedicated algorithms or procedures to remove parameters during training.
Regularization on the basis of filter structure has been reported. The classification accuracy can be improved by using customized filter shapes in the convolution layer (Li et al., 2017). The shape of the filters can also be regularized from the symmetry in the filter matrix (Anselmi et al., 2016). It has been reported that a low-rank approximation can be used to regularize the weights of the convolution layers. (Yu et al., 2017; Idelbayev and Carreira-Perpiñán, 2020). Kernel-wise removal of weights has also been proposed as a regularization method for convolutional networks (Berthelier et al., 2020). These reports focus on the shape of the image dimensions, while the schizophrenia-mimicking modification of convolution layers proposed in this study is performed by masking the weight matrix with a band matrix defined along the channel dimensions but not along the image dimensions. This strategy allowed us to eliminate 60% of the weights of the last three convolution layers of the VGG16 network without loss of accuracy (Figure 4B). We suggest that the real human brain has already implemented this simple and efficient strategy in the process of its biological evolution.
Schizophrenia-Mimicking Neural Network
We translated recent findings on schizophrenia brain tissue into two schizophrenia-mimicking models: a disorganized model and a developmental model (Figure 1). The disorganized model mimics neurodegeneration after the formation of the neuronal network, which can be simulated by training an artificial neural network normally and then damping its weights with the schizophrenia window (Figure 2). The obtained results indicated that the network works even after the post-training intervention, though the alteration did not improve performance (Figure 3). The developmental model assumes concurrent progress of neuropathological changes and brain development. It was simulated by training and testing the neural network while masking the weight matrix with the schizophrenia window (Figure 2). The results indicated that the schizophrenia connection layer is tolerant to overfitting and outperforms a fully connected layer (Figure 4). The outperformance was only observed in the developmental model and is thus ascribed to the training using the schizophrenia window.
Parameter reduction in schizophrenia layers can be regarded as enforced and predefined L1 regularization. The schizophrenia connection layers using band matrixes as weight windows had the highest levels of performance (Figure 6A). This indicates that the shape of the weight matrix is relevant to the network performance. The convolution layers with a diagonal window performed comparably to the normal convolution layers, revealing that up to 60% of the parameters can be eliminated without a loss of accuracy by using the diagonal window. Training of the schizophrenia network requires no modification of the optimization algorithm, since its parameter reduction is arbitrarily configured a priori. Schizophrenia layers can be used instead of conventional layers without any changes in the network configuration. The advantages of schizophrenia layers therefore can be had by any kind of neural network simply by replacing the conventional layers with them.
The structure of the band window matrix of the schizophrenia layer indicates the importance of connecting all nodes, but at the same time, it indicates the importance of dividing them into groups so that each group can process information independently and integratively. The weight window restricts the output nodes to represent only a predefined part of the inputs. Although the random window defines the connections of each node depending on its randomness, the diagonal or the Gaussian window forces the output nodes to divvy up all the inputs, so that all of the input information is grouped and processed into the output nodes. The high performance of the diagonal or the Gaussian window is ascribable to this structural feature of the band matrix. The results shown in Figure 6 indicate that the performance optimum of the schizophrenia layer using the band matrix window is situated nearer to the grouping than to the integration. We recommend a 50–70% parameter reduction as a first choice to obtain the best result.
A wide variety of computational models have been reported for schizophrenia (Lanillos et al., 2020). Elimination of working memory connections in the recurrent network was proven to improve perceptual ability, while excess elimination causes output hallucinations under the absence of inputs (Hoffman and McGlashan, 1997). Although the present results indicated that the structural alteration of neurites observed in schizophrenia can affect network performance, its relation to schizophrenia symptoms remains to be clarified. Another limitation of this study is that the present analysis used only thousands of nodes per model and cannot represent the brain-wide disconnectivity observed in the diffusion tensor imaging of schizophrenia cases (Son et al., 2015).
The profiles shown in Figure 6 illustrate that the high level of performance of the schizophrenia layer goes hand in hand with the malfunction. The evolutionary process should be geared to finding the level of brain performance that maximizes the survivability of our species. The results of this study, along with the known relationship between creativity and psychosis (Power et al., 2015), suggest that the connection alteration during network development is not a burden to the brain, but has functional roles in cortical microcircuit performance. We suggest that the connection alteration found in schizophrenia cases (Mizutani et al., 2019, 2021) is rationally implemented in our brains in the process of evolution.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: GitHub, https://github.com/keras-team/keras/tree/master/keras/datasets.
Author Contributions
RM designed the study and prepared the figures. RM and SN performed the numerical experiments and analyzed the results. RM wrote the manuscript based on discussions with RS regarding the human neuronal network, with YY regarding the computational models of psychiatric disorders, and with MM, MA, and MI regarding psychiatric disorders. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by Grants-in-Aid for Scientific Research from the Japan Society for the Promotion of Science (Nos. 21611009, 25282250, 25610126, 18K07579, and 20H03608) and by the Japan Agency for Medical Research and Development under grant Nos. JP18dm0107088, JP19dm0107088, and JP20dm0107088.
Conflict of Interest
MM, MA, and MI declare a conflict of interest, being authors of several patents regarding therapeutic use of pyridoxamine for schizophrenia.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The structural analyses of human brain tissues were conducted at the SPring-8 synchrotron radiation facility under proposals of 2011A0034, 2014A1057, 2014B1083, 2015A1160, 2015B1101, 2016B1041, 2017A1143, 2018A1164, 2018B1187, 2019A1207, 2019B1087, 2020A0614, 2020A1163, 2021A1175, and 2021B 1258 and at the Advanced Photon Source of Argonne National Laboratory under General User Proposals of GUP-45781 and GUP-59766. The studies on brain tissues used resources of the Advanced Photon Source, a U.S. Department of Energy (DOE) Office of Science User Facility operated for the DOE Office of Science by Argonne National Laboratory under Contract No. DE-AC02-06CH11357.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnbot.2022.851471/full#supplementary-material
References
Allin, M. and Murray, R. (2002). Schizophrenia: a neurodevelopmental or neurodegenerative disorder? Curr. Opin. Psychiatry 15, 9–15. doi: 10.1097/00001504-200201000-00003
Amunts, K. and Zilles, K. (2015). Architectonic mapping of the human brain beyond Brodmann. Neuron 88, 1086–1107. doi: 10.1016/j.neuron.2015.12.001
Anselmi, F., Evangelopoulos, G., Rosasco, L. and Poggio, T. (2016). Symmetry Regularization. CBMM Memo No. 63.
Berthelier, A., Yan, Y., Chateau, T., Blanc, C., Duffner, S. and Garcia, C. (2020). “Learning sparse filters In deep convolutional neural networks with a l 1 /l 2 pseudo-norm,” in CADL 2020: Workshop on Computational Aspects of Deep Learning—ICPR 2020 (Cham: Springer).
Brodmann, K. (1909). Vergleichende Lokalisationslehre der Großhirnrinde in ihren Prinzipien dargestellt auf Grund des Zellenbaues, Leipzig: Johann Ambrosius Barth.
Fukushima, K. (1980). Neocognitron: a self organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 36, 193–202. doi: 10.1007/BF00344251
Glorot, X., Bordes, A. and Bengio, Y. (2011). “Deep sparse rectifier neural networks,” in Proc. Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Vol 15, p. 315–323.
Gupta, S. and Kulhara, P. (2010). What is schizophrenia: a neurodevelopmental or neurodegenerative disorder or a combination of both? A critical analysis. Indian J. Psychiatry 52, 21–27. doi: 10.4103/0019-5545.58891
He, K., Zhang, X., Ren, S. and Sun, J. (2015). Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. IEEE Int. Conf. Comput. Vis. 2015, 1026–1034. doi: 10.1109/ICCV.2015.123
He, K., Zhang, X., Ren, S. and Sun, J. (2016). “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Hoffman, R. E. and McGlashan, T. H. (1997). Synaptic elimination, neurodevelopment, and the mechanism of hallucinated “voices” in schizophrenia. Am. J. Psychiatry 154, 1683–1689. doi: 10.1176/ajp.154.12.1683
Hubel, D. H. and Wiesel, T. N. (1959). Receptive fields of single neurones in the cat's striate cortex. J. Physiol. 148, 574–591. doi: 10.1113/jphysiol.1959.sp006308
Idelbayev, Y. and Carreira-Perpiñán, M. A. (2020). “Low-rank compression of neural nets: Learning the rank of each layer,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Ioffe, S. and Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv. Available online at: https://arxiv.org/abs/1502.03167 (accessed January 1, 2022).
Itokawa, M., Oshima, K., Arai, M., Torii, Y., Kushima, I., et al. (2020). Cutting-edge morphological studies of post-mortem brains of patients with schizophrenia and potential applications of X-ray nanotomography (nano-CT). Psychiatry Clin. Neurosci. 74, 176–182. doi: 10.1111/pcn.12957
Juda, A. (1949). The relationship between highest mental capacity and psychic abnormalities. Am. J. Psychiatry 106, 296–307. doi: 10.1176/ajp.106.4.296
Kingma, D. P. and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv. Available online at: https://arxiv.org/abs/1412.6980 (accessed January 1, 2022).
Krizhevsky, A. (2009). Learning Multiple Layers of Features From Tiny Images. University of Toronto. Available online at: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed January 1, 2022).
Lanillos, P., Oliva, D., Philippsen, A., Yamashita, Y., Nagai, Y. and Cheng, G. (2020). A review on neural network models of schizophrenia and autism spectrum disorder. Neural Netw. 122, 338–363. doi: 10.1016/j.neunet.2019.10.014
Le Cun, Y., Denker, J. S. and Solla, S. A. (1990). Optimal brain damage. Adv. Neural Inf. Process. Syst. 2, 598–605.
LeCun, Y., Bottou, L., Bengio, Y. and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324. doi: 10.1109/5.726791
Li, X., Li, F., Fern, X. and Raich, R. (2017). “Filter shaping for convolutional neural networks,” in 5th International Conference on Learning Representations (ICLR2017).
Liu, Z., Sun, M., Zhou, T., Huang, G. and Darrell, T. (2018). Rethinking the value of network pruning. arXiv. Available online at: https://arxiv.org/abs/1810.05270 (accessed January 1, 2022).
Maynard, T. M., Sikich, L., Lieberman, J. A. and LaMantia, A. S. (2001). Neural development, cell-cell signaling, and the “two-hit” hypothesis of schizophrenia. Schizophr. Bull. 27, 457–476. doi: 10.1093/oxfordjournals.schbul.a006887
Mizutani, R., Saiga, R., Takeuchi, A., Uesugi, K., Terada, Y., Suzuki, Y., et al. (2019). Three-dimensional alteration of neurites in schizophrenia. Transl. Psychiatry 9, 85. doi: 10.1038/s41398-019-0427-4
Mizutani, R., Saiga, R., Yamamoto, Y., Uesugi, M., Takeuchi, A., Uesugi, K., et al. (2021). Structural diverseness of neurons between brain areas and between cases. Transl. Psychiatry 11, 49. doi: 10.1038/s41398-020-01173-x
Power, R. A., Steinberg, S., Bjornsdottir, G., Rietveld, C. A., Abdellaoui, A. and Nivard, M. M. (2015). Polygenic risk scores for schizophrenia and bipolar disorder predict creativity. Nat. Neurosci. 18, 953–955. doi: 10.1038/nn.4040
Rosenblatt, F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychol. Rev. 65, 386–408. doi: 10.1037/h0042519
Scardapane, S., Comminiello, D., Hussain, A. and Uncini, A. (2017). Group sparse regularization for deep neural networks. Neurocomputing 241, 81–89. doi: 10.1016/j.neucom.2017.02.029
Simonyan, K. and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv. Available online at: https://arxiv.org/abs/1409.1556 (accessed January 1, 2022).
Son, S., Kubota, M., Miyata, J., Fukuyama, H., Aso, T., Urayama, S., et al. (2015). Creativity and positive symptoms in schizophrenia revisited: structural connectivity analysis with diffusion tensor imaging. Schizophr. Res. 164, 221–226. doi: 10.1016/j.schres.2015.03.009
Spruston, N. (2008). Pyramidal neurons: dendritic structure and synaptic integration. Nat. Rev. Neurosci. 9, 206–221. doi: 10.1038/nrn2286
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. and Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res 15, 1929–1958. Available online at: https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
Tieleman, T. and Hinton, G. (2012). Lecture 6.5-rmsprop: divide the gradient by a running average of its recent magnitude. COURSERA: Neural Netw. Mach. Learn. 4, 26–31. Available online at: https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
Wen, W., Wu, C., Wang, Y., Chen, Y. and Li, H. (2016). “Learning structured sparsity in deep neural networks,” in 30th Conference on Neural Information Processing Systems.
Wong, S. C., Gatt, A., Stamatescu, V. and McDonnell, M. D. (2016). “Understanding data augmentation for classification: when to warp?” in International Conference on Digital Image Computing: Techniques and Applications (DICTA) 2016.
Yaguchi, A., Suzuki, T., Asano, W., Nitta, S., Sakata, Y. and Tanizawa, A. (2018). “Adam induces implicit weight sparsity in rectifier neural networks,” in 17th IEEE International Conference on Machine Learning and Applications (ICMLA).
Keywords: human brain, schizophrenia, neuronal network, weight window, parameter reduction
Citation: Mizutani R, Noguchi S, Saiga R, Yamashita Y, Miyashita M, Arai M and Itokawa M (2022) Schizophrenia-Mimicking Layers Outperform Conventional Neural Network Layers. Front. Neurorobot. 16:851471. doi: 10.3389/fnbot.2022.851471
Received: 09 January 2022; Accepted: 01 March 2022;
Published: 28 March 2022.
Edited by:
Xichuan Zhou, Chongqing University, ChinaReviewed by:
Xiang Liao, Chongqing University, ChinaShaista Hussain, Agency for Science, Technology and Research (A*STAR), Singapore
Copyright © 2022 Mizutani, Noguchi, Saiga, Yamashita, Miyashita, Arai and Itokawa. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ryuta Mizutani, mizutanilaboratory@gmail.com