Tracking replicability as a method of post-publication open evaluation
- Department of Psychology, Harvard University, Cambridge, MA, USA
Recent reports have suggested that many published results are unreliable. To increase the reliability and accuracy of published papers, multiple changes have been proposed, such as changes in statistical methods. We support such reforms. However, we believe that the incentive structure of scientific publishing must change for such reforms to be successful. Under the current system, the quality of individual scientists is judged on the basis of their number of publications and citations, with journals similarly judged via numbers of citations. Neither of these measures takes into account the replicability of the published findings, as false or controversial results are often particularly widely cited. We propose tracking replications as a means of post-publication evaluation, both to help researchers identify reliable findings and to incentivize the publication of reliable results. Tracking replications requires a database linking published studies that replicate one another. As any such database is limited by the number of replication attempts published, we propose establishing an open-access journal dedicated to publishing replication attempts. Data quality of both the database and the affiliated journal would be ensured through a combination of crowd-sourcing and peer review. As reports in the database are aggregated, ultimately it will be possible to calculate replicability scores, which may be used alongside citation counts to evaluate the quality of work published in individual journals. In this paper, we lay out a detailed description of how this system could be implemented, including mechanisms for compiling the information, ensuring data quality, and incentivizing the research community to participate.
Improving the Quality of Published Research
The current system of conducting, reviewing, and publishing scientific findings – while enormously successful – is by no means perfect. Peer review, the primary vetting procedure for publication, is often slow, contentious, and uneven (Mahoney, 1977; Cole et al., 1981; Peters and Ceci, 1982; Eysenck and Eysenck, 1992; Newton, 2010). Incorrect use of inferential statistics leads to publication of spurious findings (Saxe et al., 2006; Baayen et al., 2008; Jaeger, 2008; Kriegeskorte et al., 2009; Vul et al., 2009; Wagenmakers et al., 2011). Publication biases, such as the bias against publishing null results (e.g., Easterbrook et al., 1991; Ioannidis, 2005b; Boffetta et al., 2008), lead to distortions in the published record, hampering both informal reviews and formal meta-analyses. Numerous valuable proposals have been offered as to how to improve the system in order to enable researchers to better identify high-quality research, including those in the present special issue.
There are many considerations that go into determining research quality, but perhaps the most fundamental is replicability. Recently, numerous reports have suggested that many published results across a range of scientific disciplines do not replicate (Ioannidis et al., 2001; Jennions and Møller, 2002b; Lohmueller et al., 2003; Ioannidis, 2005a; Boffetta et al., 2008; Ferguson and Kilburn, 2010). However, because replication attempts are not tracked and are often not reported, there is no systematic way for researchers to know which results in the literature have been replicated.
In the present paper, we first discuss evidence that the rate of replicability of published studies is low, including novel data from a survey of researchers in psychology and related fields. We propose that this low replicability stems from the current incentive structure, in which replicability is not systematically considered in measuring paper, researcher, and journal quality. As a result, the current incentive structure rewards the publication of non-replicable findings, complicating the adoption of needed reforms. Thus, we outline a proposal for tracking replications as a form of post-publication evaluation, and using these evaluations to calculate a metric of replicability. In doing so, we aim not only to enable researchers to easily find and identify reliable results, but also to improve the incentive structure of the current system of scientific publishing, leading to widespread improvements in scientific practice and increased replicability of published work.
Why Might We Expect Low Replicability?
Many aspects of current accepted practice in psychology, neuroscience, and other fields necessarily decrease replicability. Some of the most common issues include a lack of documentation of null findings; a tendency to conduct low-powered studies; failure to account for multiple comparisons; data-peeking (with continuation of data collection contingent on current significance level); and a publication bias in favor of surprising (“newsworthy”) results.
Lack of Publication or Documentation of Null Findings
Null results are less likely to be published than statistically significant findings. This has been extensively documented in the medical literature (Dickersin et al., 1987, 1992; Easterbrook et al., 1991; Callaham et al., 1998; Misakian and Bero, 1998; Olson et al., 2002; Dwan et al., 2008; Sena et al., 2010), with additional reports in political science (Gerberg et al., 2001), ecology and evolution (Jennions and Møller, 2002a), and clinical psychology (Coursol and Wagner, 1986; Cuijpers et al., 2010). There appear to be fewer comprehensive studies of publication bias in non-clinical psychology, although evidence of this bias has been documented in a few specific literatures (Field et al., 2009; Ferguson and Kilburn, 2010).
Preferential publication of significant effects necessarily biases the record. Consider cases in which multiple labs all test the same question, or in which the same lab repeatedly tests the same question while iteratively refining the method. By chance alone, some of the experiments will result in publishable statistically significant effects; the likelihood that a finding may be spurious is masked by the fact that the null results are not published.
The significance-bias also leads to the overestimation of real effects. Measurement is probabilistic: the measured effect size in a given experiment is a function of the true effect size plus some random error. In some experiments, the measured effect will be larger than the true effect, and in some it will be smaller. Suppose the statistical power of the experiment is 0.8 (a particularly high level of power for studies in psychology; see below). This means that the effect will be statistically significant only if it is in the top 80% of its sampling distribution. Twenty percent of the time, when the effect is – by chance – relatively small, the results will be non-significant. Thus, given that an effect was significant, the measured effect size is probably larger than the actual effect size, and subsequent measurements will find smaller effects due to the familiar phenomenon of regression to the mean. The lower the statistical power, the more the effect size will be inflated.
Low-Power, Small Effect Size
A number of findings suggest that the statistical power in psychology and neuroscience experiments is typically low. According to multiple meta-analyses, the statistical power of a typical psychology or neuroscience study to detect a medium-sized effect (defined variously as r = 0.3, r = 0.4, or d = 0.5) is approximately 0.5 or below (Cohen, 1962; Sedlmeier and Gigerenzer, 1989; Kosciulek and Szymanski, 1993; Bezeau and Graves, 2001). In applied psychology, power for medium effects is closer to 0.7, though it remains low for small effects (Chase and Chase, 1976; Mone et al., 1996; Shen et al., 2011). Nonetheless, many effects of interest in psychology are small and thus typical statistical power may be quite low. Field et al. (2009) report an average power of 0.2 in a meta-analysis of 68 studies of craving in addicts and attentional bias. In a heroic meta-analysis of 322 meta-analyses in social psychology, Richard et al. (2003) report that the average effect size was r = 0.21. To achieve power of 0.8 would require the average study to have 173 participants (in terms of medians: r =0.18, N = 237), already far larger than typical sample size. Nearly 1/3 of the effect sizes reported were r = 0.1 or less, requiring N = 772 to achieve power of 0.8.
All else being equal, low statistical power would increase the proportion of significant results that are spurious. For instance, suppose researchers are investigating a hypothesis that is equally likely to be true or false (the prior likelihood of the null hypothesis is 50%), using methods with statistical power = 0.8. In this case, 6% of significant results will be false positives (True positives: 0.5 × 0.8 = 0.4; False positives: 0.5 × 0.05 = 0.025; Ratio: 0.025/0.425 = 0.059). If Power = 0.2, this increases to 20%. If the prior likelihood of the null hypothesis is 90% (i.e., if an effect would be surprising, or when data-mining), the false positive rate will be 69% (for additional discussion, see Yarkoni, 2009; for other problems associated with small power, see Tversky and Kahneman, 1971).
Failure to Account for Multiple Comparisons
If one tests for 10 different possible effects in each experiment, the chance of finding at least one significant at the p = 0.05 level even when no effect actually exists is 1 − 0.9510 = 0.4. Since experiments with large numbers of comparisons are often entirely exploratory, where there is no strong a priori reason to believe that any of the investigated effects exist, the false positive rate may approach 100% for data-mining studies with large datasets.
Data-Peeking and Contingent Stopping of Data Collection
Many researchers compile and analyze data prior to testing a full complement of subjects. There is nothing wrong with this, so long as the decision to stop data collection is made independent of the results of these preliminary analyses, or so long as the final result is then replicated with the same number of subjects. Unfortunately, the temptation to stop running participants once significance is reached – or to run additional participants if it has not been reached – is difficult to resist. This data-peeking and contingent stopping has the potential to significantly increase the false positive rate (Feller, 1940; Armitage et al., 1969; Yarkoni and Braver, 2010). Even if the null hypothesis is true, a researcher who tests for significance after every participant has a 25% chance of finding a significant result with 20 or fewer participants (if the underlying distribution is normal; the analogous numbers are 19.5% for exponential distributions and 11% for binomial distributions; Armitage et al., 1969). This issue may be mitigated by use of alternative statistical tests, such as Bayesian statistics (Edwards et al., 1963), but such statistics have not been widely adopted.
Newsworthiness Bias
Researchers are more likely to submit – and editors more likely to accept – “newsworthy” or surprising results. Spurious results are likely to be surprising, and thus are likely to be over-represented in published reports. Consistent with this claim, there is some evidence that highly cited papers are less likely to replicate (Ioannidis, 2005a) and that publication bias affects high-impact journals more severely (Ioannidis, 2005a; Munafò et al., 2009).
How Replicable are Published Studies?
Several studies have found low rates of replicability across multiple scientific fields. Ioannidis (2005a) found that of 34 highly cited clinical research studies for which replication attempts had been published, seven (20%) did not replicate. Boffetta et al. (2008) report a number of cases in which reports of significant cancer risk factors did not replicate. Recent studies have reported that relatively few genetic association links can be replicated (Ioannidis et al., 2001, 2003; Hirschhorn et al., 2002; Lohmueller et al., 2003; Trikalinos et al., 2004).
Likewise, several studies have found that initial reports of effect size are often exaggerated. This has been noted in medicine (Ioannidis et al., 2001, 2003; Trikalinos et al., 2004; Ioannidis, 2005a; but see Gehr et al., 2006), with similar declines in effect size reported in ecological and evolutionary biology (Jennions and Møller, 2002a,b). In the most extreme example, Dewald et al. (1986) reanalyzed the datasets underlying published studies in economics and were unable to fully replicate the analyses for seven of nine (78%).
Less is known about replication rates in psychology and neuroscience. In a series of five meta-analyses of fMRI studies, Wager and colleagues estimated that between 10 and 40% of activation peaks are false positives (Wager et al., 2007, 2009). While there seem to be few systematic surveys within psychology, some published effects are known not to replicate, such as the initial finding that violent video games increase violent behavior (Ferguson and Kilburn, 2010), various claims about the relationship between birth order and personality (Ernst and Angst, 1983; Harris, 1998; but see: Kristensen and Bjerkedal, 2007; Hartshorne et al., 2009), and a range of gene/environment interactions (Flint and Munafo, 2009).
In order to add to our knowledge of replicability rates in psychology and related disciplines, we surveyed 49 researchers in these disciplines, who reported a total of 257 attempted replications of published studies (for details, see Appendix). Only 127 (49%) fully replicated the original findings. This low rate was not driven by a small number of researchers attempting a large number of poor quality replications: both the mean and median replication success rates were 50%, with 77% of researchers reporting at least one attempted replication. Thus, the results of this survey suggest that replication rates within psychology and related disciplines are undesirably low, in accordance with the low rates of replicability found in many other fields.
Incentives in Publication
As reviewed above, a number of factors promote low replicability rates across a range of fields. These problems are reasonably well known, and in many cases solutions have been proposed, such as use of different statistical methods and self-replication prior to publication. However, in spite of these solutions, evidence suggests that replicability remains low and thus that the proposed solutions have not been widely adopted. Why would this be the case? We propose that the incentive structure of the current system diminishes the ability and tendency of researchers to adopt these solutions. Namely, current methods of judging paper, researcher, and journal quality fail to take replicability into account, and in effect incentivize publishing spurious results.
Quantifying Research Quality
There are three primary quantitative criteria by which researchers are judged: their number of publications, the impact factor of the journals in which the publications appear, and the number of citations those papers receive. These quantitative values are a major consideration in the awarding of grants, hiring, and tenure. Journals are similarly judged in terms of citation counts, which are compiled to calculate journal impact factors. Unfortunately, these metrics of quality tend to disincentivize taking additional steps to ensure the reliability of published findings, for several reasons.
Firstly, eliminating false positives means publishing fewer papers, since null results are difficult to publish. Second, ensuring that effect sizes are not inflated means reporting results with smaller effect sizes, which may be seen as less interesting or less believable. Third, as discussed above, spurious results are more likely to be surprising and newsworthy. Thus, eliminating spurious results disproportionately eliminates publications that would be widely cited and published in top journals.
These drawbacks are compounded by the fact that many of the improved practices that ensure replicability take time and resources. Learning to use new statistical methods often requires substantial effort. Increasing an experiment’s statistical power may require testing more participants. Eliminating stopping of data collection contingent on significance level (data-peeking) also means erring on the side of testing more participants. Perhaps the best insurance against false positives is pre-publication replication by the authors. All these strategies take time.
In addition, there is relatively little cost associated with publishing unreliable results, as failures to replicate are rarely published and not systematically tracked. As a result, knowledge of the replicability of results mainly travels via word-of-mouth, through specific personal interactions at conferences and meetings. There are obvious concerns about the reliability of such a system, and there is little evidence that this system is particularly effective. We are aware of several cases in which a researcher invested months or years into unsuccessfully following up on a well-publicized effect from a neighboring subfield, only to later be told that it is “well-known” that the effect does not replicate.
Moreover, even when a failure-to-replicate is published, the results often go unnoticed. For example, a meta-analysis by Maraganore et al. (2004) concluded that UCHL1 is a risk-factor for Parkinson’s Disease. Subsequent more highly powered meta-analyses overturned this result (Healy et al., 2006). Nonetheless, Maraganore et al. (2004) has been cited 70 times since 2007 (Google Scholar, May 10, 2011), much to the dismay of the senior author of the study (Ioannidis, 2011). Even papers retracted by the authors remain in circulation. In 2001, two papers were retracted by Karen Ruggiero (Ruggiero and Marx, 1999; Ruggiero et al., 2000). Nonetheless, 10 of the 22 citations to these papers were made in 2003 or later (Google Scholar, April 25, 2011). Similarly, though Lerner requested the retraction of Lerner and Gonzalez (2005) in 2008, the paper has been cited five times in 2010–2011 (Google Scholar, April 25, 2011).
It follows that researchers who take additional steps to ensure the quality of their data will ultimately spend more time and resources on each publication and, all else equal, will end up with fewer, less-often-cited papers in lower-quality journals. In the same way, journals that adopt more stringent publication standards may drive away submissions, particularly of the surprising, newsworthy findings that are likely to be widely cited. Certainly, the vast majority of researchers and editors are internally motivated to publish real, reliable results. However, we also cannot continue practicing science without jobs, grants, and tenure. This situation sets up a classic Tragedy of the Commons (Hardin, 1968): While it is in everyone’s collective interest to adopt strategies to improve replicability, the incentives for any individual researcher run the other direction.
Escaping the Tragedy of the Commons
Individuals can solve the Tragedy of the Commons by adopting common rules or changing incentive structures. To give a recent example, Jaeger (2008), Baayen et al. (2008), and others convinced many language processing researchers to switch from ANOVAs to mixed effects models, in part by convincing editors and reviewers to insist on it. In this case, collective action motivated widespread adoption of an improved method of analysis.
In a similar way, collective action is needed to solve the problem of low replicability: Because the incentive structure of the current system penalizes any member of the community who is an early adopter of reforms, an organized community change is needed. Instead of maintaining a system in which individual incentives (publish as often as possible) run counter to the goals of the group (maintain the integrity of the scientific literature), we can change the incentives by placing value on replicability directly. To do this, we propose tracking the replicability of published studies, and evaluating the quality of work post-publication partly on this basis. By tracking replicability, we hope to provide concrete incentives for improvements in research practice, thus allowing the widespread adoption of these improved practices.
Replication Tracker: A Proposal
Below, we lay out a proposal for how replications might be tracked via an online open-access system tentatively named Replication Tracker. The proposed system is not yet constructed; our aim in this proposal is to spur necessary discussion on the implementation of such a system. We first describe the core components of such a system. We then discuss in more depth issues that arise, such as motivating participation, aggregating information, and ensuring data quality.
Core Elements of the Replication Tracker
In a system such as Google Scholar, each paper’s reference is presented alongside the number of times that paper has been cited, and each paper is linked to a list of the papers citing that target paper. Replication Tracker would function in a similar manner, except that it would be additionally indexed by specialized citations that link papers based on one attempting to replicate the other. Thus, each paper’s reference would appear alongside not only a citation count, but an attempted replication count and information about the paper’s replicability.
Replication Tracker’s attempted replication citations are termed Replication Links (henceforth RepLinks). Each RepLink is tagged with metadata, answering the question: To what extent are these findings strong evidence that the target paper does or does not replicate? This metadata takes the form of two numerical ratings: a Type of Finding Score, running from +2 (fully replicated) to −2 (fully failed to replicate); and a Strength of Evidence Score, running from 1 (weak evidence) to 5 (strong evidence). These ratings, as well as the RepLinks themselves, could be produced through a variety of methods; we suggest crowd-sourcing from the scientific community, as outlined below.
For replications to be tracked, they must be reported. As discussed above, many replication attempts remain unpublished. Thus, Replication Tracker would be paired with an online, open-access journal devoted to publishing Brief Reports of replication attempts. After a streamlined peer review process, these Brief Reports would be published and connected to the papers they replicate via RepLinks in the Replication Tracker.
This system will ultimately form a rich dataset, consisting of RepLinks between attempted replications and the original findings. Each RepLink’s ratings would indicate the type and strength of evidence of the findings. These ratings would be aggregated, and used to compute statistics on replicability. For instance, the system could summarize the data for each paper in terms of a Replicability Score [e.g., 15 attempted replications, Replicability Score: +1.7 (Partial Replication), Strength of Evidence: 4 (Strong)], much as citation indices score papers based on citation counts (e.g., cited by 15). These numbers would allow researchers to both get an initial impression of a finding’s replicability at a glance, and quickly click through to the original sources for further detail. In addition, Replicability Scores could be aggregated for each journal, which could be used alongside the existing Impact Factor to evaluate the quality of journals.
Structure and Content of RepLiNKs
RepLinks must, minimally, link a replication attempt with its target paper, note whether the finding was replication or non-replication, and note the strength of evidence for this finding.
There are many factors that enter into these decisions. For instance, a particular attempted replication may have investigated all of the findings in the target paper, or may have only attempted to replicate some subset. The findings may be more similar or less similar as well: All effects may have successfully replicated, or none; or some findings may have replicated while others did not. In addition, whether a replication serves as strong evidence of the replicability or non-replicability of the original finding depends on the extent of similarity of the methods used, and whether the attempt had high or low statistical power.
We propose capturing these issues in two ratings. The first rating, termed the Type of Finding rating, would take into account two factors: Whether all or only a subset of the target papers’ findings were investigated; and whether all, none, or some of the attempted replications were successful. On this Type of Finding scale, −2 would denote a total non-replication (all findings investigated; none replicated); −1 a partial non-replication (some subset of findings investigated; none of those investigated replicated); 0 would denote mixed results (of the findings investigated, some replicated, and others did not); 1 a partial replication (some subset of findings investigated; all of those investigated replicated); and 2 a total replication (all findings investigated; all replicated).
The second rating would be a Strength of Evidence rating, scored on a 1–5 scale. This rating would take into account the remaining two factors: the extent to which the methods are similar between the target paper and the RepLinked paper, and the power of the replication attempt. Thus a score of 5 reflects a high-powered attempt with as-close-as-possible methods, while 1 reflects a low-powered attempt with relatively dissimilar methods. When a replication attempt is extremely low-power or uses substantially different methods, it would not be assigned a RepLink at all.
Who Creates and Rates Replinks?
The ratings described above involve a number of difficult determinations. Given that no two studies can have exactly identical methods, how similar is similar enough? How does one determine whether a study has sufficient statistical power, given that the effect’s size is itself under investigation?
To make these determinations, we turn to those individuals most qualified to make them: researchers in the field. Crowd-sourcing has proven a highly effective mechanism of making empirical determinations in a variety of domains (Giles, 2005; Law et al., 2007; von Ahn and Dabbish, 2008; von Ahn et al., 2008; Bederson et al., 2010; Yan et al., 2010; Doan et al., 2011; Franklin et al., 2011). Researchers would form the user base of the system, and any user could submit a RepLink, as well as a Type of Finding and Strength of Evidence score for a RepLink. When submitting these materials, users could also optionally comment on each RepLink, providing a more detailed description of how the methods or results of the RepLinked paper differed from the target paper, or offering interpretations of discrepancies. These comments would be optionally displayed alongside each users’ individual ratings, for readers looking for additional detail (Figure 4).
The system also utilizes multiple moderators. These moderators would take joint responsibility for tending the RepLinks and Brief Reports (see below) on papers in their subfields. Moderators would be scientists, and could be invited (e.g., by the founding members), although anyone with publications in the field could apply to be a moderator.
In submitting and rating RepLinks, researchers may disagree with one another as to the correct Type of Finding or Strength of Evidence ratings for a given RepLink, or may disagree as to whether two papers are sufficiently similar as to qualify as a replication attempt. Users who agree with an existing rating may easily second it with a thumbs-up, while users who disagree with the existing ratings may submit their own additional ratings. Users who believe that the papers in question do not qualify as replications may flag the RepLink as irrelevant (RepLinks that have been flagged a sufficient number of times would no longer be used to calculate Replicability Scores, though these suppressed RepLinks would be visible under certain search options). These ratings would be combined together using crowd-sourcing techniques to determine the aggregate Type of Finding and Strength of Evidence scores for a given RepLink (see below).
Aggregation, Authority, and Machine Learning
Data must be aggregated by this system at multiple levels. First, multiple ratings for a given RepLink must be combined into aggregate Type of Finding and Strength of Evidence ratings for that RepLink. Second, where a single target paper has been the subject of multiple replication attempts, the different RepLinks must be aggregated into a single Replicability Score and Strength Score for that target paper. In the same way, scores may be combined across multiple papers to determine aggregate replicability across a literature, an individual researcher’s publications, or a journal.
Aggregates need not be mere averages. How to best aggregate ratings across multiple raters is an active area of research in machine learning (Albert and Dodd, 2004; Adamic et al., 2008; Snow et al., 2008; Callison-Burch, 2009; Welinder et al., 2010). Type of Finding ratings for an individual RepLink may be weighted by their associated Strength of Evidence scores, as well as how many thumbs-up they have received.
In addition, ratings from certain users would be weighted more heavily than others, as is done in many rating aggregation algorithms (e.g., Snow et al., 2008). There are many mechanisms for doing so, such as downgrading the authority of users whose RepLinks are frequently flagged as irrelevant, and assigning greater authority to moderators. The best system of weighting and aggregating RepLinks is an interesting empirical question. We see no reason it must be set in stone from the outset; the best algorithms may be determined through new research in machine learning. To that end, the raw rating dataset would be made available to those working in machine learning and related fields.
A Note on Converging Results
Only strict replications, not convergent data from different methods, will be tracked in the proposed system. This may seem counter-intuitive, since tracking converging results is crucial for determining which theories are most predictive. However, the goal of the proposed system is not to directly evaluate which theories are right, but to determine which results are right – that is, which patterns of data are reliable. Consider that while converging results may suggest that the original finding replicates, diverging results may only indicate that the differences in the methodologies were meaningful. For this reason, we focus solely on tracking strict replications. We believe that evaluating the complex theoretical implications of a large body of data is best handled by researchers themselves (i.e., when writing review papers), and is likely not feasible with an automated system.
Authentication and Labeling of Authors’ Ratings and Comments
Registering for the system and submitting RepLinks would not require authenticating one’s identity. However, authors of papers could choose to have their identities authenticated in order to have comments on their own papers be marked as author commentaries (many RepLinks will almost certainly be submitted by authors, as they are most invested in the issues involved in replication of their own studies).
Identity authentication could be accomplished in multiple ways. For instance, a moderator could use the departmental website to verify the author’s email address and send a unique link to that email address. Clicking on that link would enable the user to set up an authenticated account under the users’ own name. Moderator’s identities could be authenticated in a similar manner.
Selection of Moderators
Although any user can contribute to Replication Tracker, moderators play several additional key roles. First, they evaluate submitted Brief Reports, and submit the initial RepLinks for any accepted Brief Report. Similarly, when new RepLinks are submitted, moderators are notified and can flag irrelevant RepLinks or submit their own ratings. Thus, it is important that (a) there are enough moderators, and (b) the moderators are sufficiently qualified. In the case of moderator error, the Replication Tracker contains numerous ways by which other moderators and users can override the erroneous submission (submitting additional RepLink scores; flagging the erroneous RepLink, etc.). In order to recruit a sufficient number of moderators, we suggest allowing existing moderators to invite additional moderators as well as allowing researchers to apply to be moderators. Moderators could be selected based on objective considerations (number of publications, years of service, etc.), subjective considerations (by a vote of existing moderators), or both.
Retractions
The Replication Tracker system is also ideally suited to tracking retractions. Retractions may be submitted by users as a specially marked type of RepLink, which would require moderator approval before posting. Retracted studies would appear with the tag RETRACTED in any search results, and automatically be excluded from calculations of Replicability Scores. As a safeguard against incorrect flags, any time a study is flagged as retracted, all other moderators would be notified, and the flag could be revoked if found inaccurate.
Brief Reports
The efficacy of Replication Tracker is limited by the number of published replication attempts. As discussed above, both successful replications and null results are difficult to publish, and often remain undocumented. Thus, we propose launching an open-access journal that publishes all and any replication attempts of suitable quality.
Unlike full papers elsewhere, these Brief Reports would consist of the method and results section only. This greatly reduces the cost of either writing or reviewing the report. The Brief Report must also be submitted with one or more RepLinks, specifying what exactly is being replicated. Particularly for non-replications, authors of Brief Reports can use the comments on the RepLinks to discuss why they think the replication failed (low-power in the original study, etc.).
Review of Brief Reports would be handled by moderators. When a Brief Report is submitted, all moderators of that subfield would be automatically emailed with a request to review the proposed post. The review could then be “claimed” by any moderator. If no one claims the post for review within a week, the system would then automatically choose one of the relevant moderators, and ask if they would accept the request to review; if they decline, further requests would be made until someone agreed to review. Authors would not be able to be the sole moderator/reviewer for replications of their own work. As in the PLoS model, the moderator could evaluate the Brief Report alone or solicit outside review(s).
The presumption of the review process would be acceptance. Brief Reports would be returned for revision when appropriate, as in the case of using inappropriate statistical tests; but would only be rejected if the paper does not actually qualify as a replication attempt (based on the criteria discussed above). In the latter case, authors of Brief Reports could appeal the decision, which would then be reviewed by two other moderators. On acceptance, the Brief Report would be published online in static form with a DOI, much like any other publication, and thus be part of the citable, peer reviewed record. The appropriate RepLinks would be likewise added to Replication Tracker. As with any RepLink, these could be suppressed if flagged as irrelevant a sufficient number of times (see above). Thus, while publication in Brief Reports is permanent (barring retractions), incorporation into Replication Tracker is always potentially in flux – as is appropriate for a post-review evaluation process.
The Experience of Using Replication Tracker: A Step-by-Step Guide
As in any literature database, users would begin by using a search function (either simple or advanced) to locate a paper of interest (Figure 1). This search would bring up a list of references, in a format similar to Google Scholar. However, in addition to the citation count provided by Google Scholar, the system would provide three additional values: The number of replication attempts documented, the paper’s Replicability Score, and the Strength of Evidence score (Figure 2). As described above, the Replicability Score would hold a value from −2 to +2, with negative values denoting evidence of non-replication, zero denoting mixed findings, and positive values evidence of successful replication.
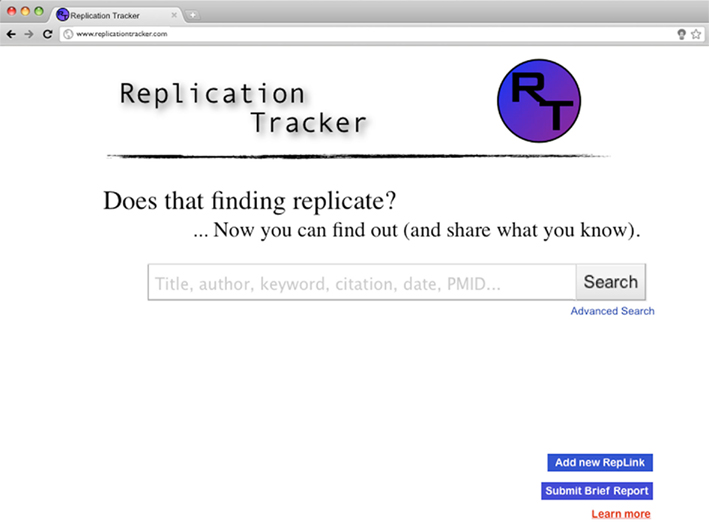
Figure 1. Replication tracker: search window. Much like any other paper index, Replication Tracker would allow the user to search for papers by author, keyword, and other typical search terms.
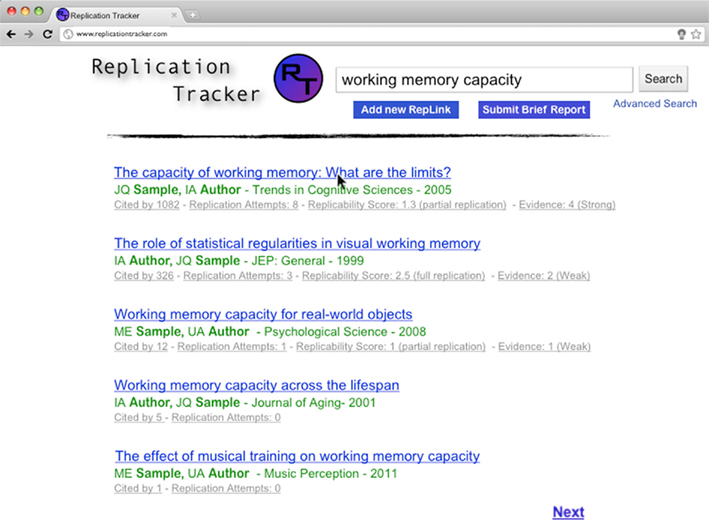
Figure 2. Replication tracker: example search results. Results of a search query list relevant papers, along with number of citations and information about the paper’s replicability. This information consists of the number of attempted replications reported to the system, a summary statistic of whether the finding successfully replicates or fails to replicate (“Replicability Score”), and a summary statistic of the strength of the evidence. These numbers are derived from RepLinks, data which is crowd-sourced from users and moderators (Figure 3).
The user would then click on a reference from the list to bring up more detailed information about that target paper (Figure 3). The target paper’s reference would appear at the top of the page, along with the number of attempted replications documented, Replicability Score for that paper, and the Strength of Evidence score. Below these aggregate measures would be a list of the RepLinks, represented by a citation of the RepLinked paper, the aggregate Type of Finding score and Strength of Evidence score for that RepLink, and the number of users who have rated that RepLink. An additional button would allow users to add their own ratings or flag the RepLink as irrelevant.
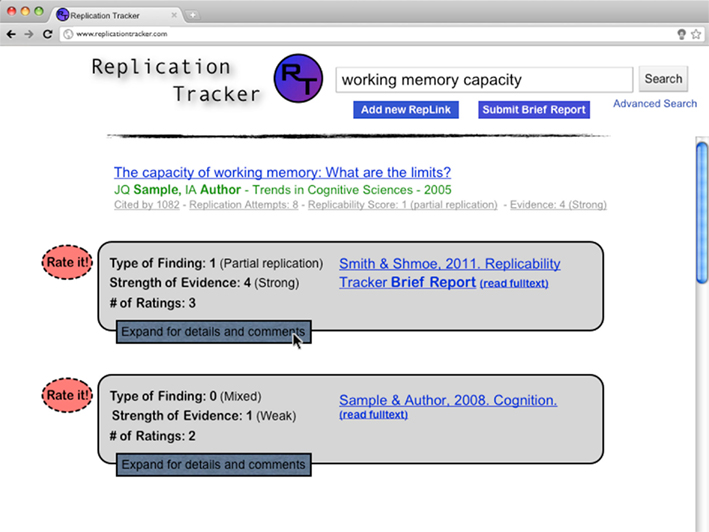
Figure 3. Replication tracker: search results expansion, showing RepLinks for a target paper. Each RepLink represents an attempted replication. Again, the degree of success of the replication (“replication type”) and strength of the evidence is noted. These are determined by aggregating determinations made by individual users (Figure 4).
Information about each RepLink could be expanded, to show each individual rating along with that users’ associated comments, if any (Figure 4). Users could agree with an existing rating via a thumbs-up button. Ratings and comments would be labeled with the username of the poster; for authenticated accounts, they could optionally be labeled with the individuals’ real name. Comments by authors who have chosen to authenticate their account under their real names would be labeled as such.
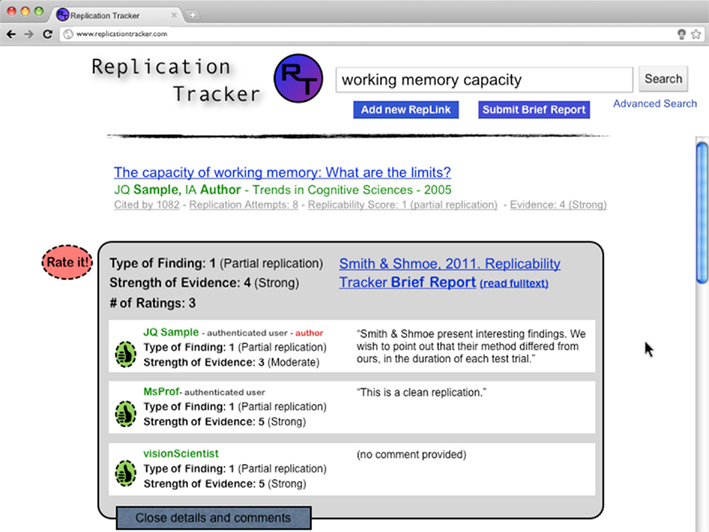
Figure 4. Replication tracker: expansion of a RepLink, showing ratings by individual readers, which are summarized in Figure 3. Users are also able to add comments, explaining their determinations, or flag posts as irrelevant, prompting review by moderators.
Issues for Further Discussion
The Replication Tracker would serve several functions. First, it would enable a new way of navigating the literature. Second, we believe it would motivate researchers to conduct and report attempted replications, helping correct biases in the literature such as the file-drawer problem. Third, it will vastly improve access to and communication regarding replication attempts. Perhaps most importantly, it would help incentivize and reward costly efforts to ensure replicability pre-publication, helping to mitigate a Tragedy of the Commons in scientific publishing.
However, in addition to these potential benefits, tracking, and publishing replication attempts raises non-trivial issues, and has the potential for unintended consequences. We consider several such concerns below and discuss how these concerns may be addressed or allayed.
Getting the System Off the Ground
The usefulness of the database for tracking replicability will be a function of the amount of replication information added to it in the form of RepLinks, metadata information, and Brief Reports. This will require considerable participation by a broad swath of the research community. Because researchers are more likely to contribute to a system that they already find useful, an important determiner of success will be the ability to achieve a critical mass of such information. We have considered several ways of increasing the likelihood that the system quickly reaches critical mass.
First, there should be a considerable number of founding members, so that a wide range of researchers are engaged in the project prior to launch. This will not only help with division of labor, but will also help clarify the many design decisions that go into creating the details of the system. The more diverse the founding group is, the more likely the final system will be acceptable to researchers in multiple fields and disciplines. This paper serves as a first step in starting the needed dialog.
Second, we suggest concentrating on first reaching critical mass for a few select subfields of psychology and neuroscience, instead of simultaneously attempting to obtain critical mass in all fields of science at once. In order to reach critical mass within the first few subfields, we suggest that prior to the public launch of Replication Tracker, founding members conduct targeted replicability reviews of specific literatures within those subfields, writing RepLinks and soliciting Brief Reports during the process. These data would be used to write review papers, which would be published in traditional journals. These review papers would be useful publications in and of themselves and would help demonstrate the empirical value of tracking replications. This would help recruit additional founders, moderators and funding – all while major components are added to the database. Only once enough coverage of the literatures within those subfields has been achieved would Replication Tracker be publically launched.
In addition to tracking published replications, the proposed system attempts to ameliorate the file-drawer problem by allowing researchers to submit Brief Reports of attempted replications. Several previous attempts have been made to publish null results and replication attempts (e.g., Journal of Articles in Support of the Null Hypothesis; Journal of Negative Results in Biomedicine) often with low rates of participation (JASNH has published 32 papers since its launch in 2002). Nonetheless, we believe several aspects of our system would motivate increased participation. Firstly, the format of Brief Reports significantly decreases the time commitment of preparation, as the Reports consist of the method and results section only. Second, these Brief Reports will not only be citable, but will also be highly findable, as they will be RepLinked to the relevant published papers. Thus we expect these Reports to have some value, perhaps equivalent to a conference paper or poster. We believe that the combination of lesser time investment and increased value will lead to increased rates of submission.
What is the Right Unit of Analysis?
Because each paper may include multiple findings that differ in replicability, there is a good argument to be made that what should be tracked is the replicability of a given result. We propose tracking the replicability of papers instead, for several reasons.
The first reason is one of feasibility. We believe that tracking each finding separately would be infeasible, as what counts as an individual finding may be subjective, and the vast number of units of analysis even within a single paper becomes prohibitive. An intermediate level would be to track individual experiments. However, publication formats do not always include separate headings for each individual experiment (e.g., Nature, Current Biology), and even a single experiment may include multiple components with differences in replicability.
Secondly, even organizing the system at the level of experiment will not allow an aggregated replicability score to capture every nuance of the scientific literature. It will always be necessary for the reader to examine written information for more detail, including the full text of the RepLinked papers. For these detail-oriented readers, the proposed system provides a novel way to navigate through published work (by following RepLinks to find and read papers with attempted replications) and an efficient way to view comments on each of these papers (Figure 4). Such a system is most intuitive and navigable when organized at the level of the paper itself.
Are Sufficient Numbers of Replications Conducted?
The rate of published replications appears to be low: For instance, over a 20-year period, only 5.3% of 701 publications in nine management journals included attempts to replicate previous findings (Hubbard et al., 1998). While we believe Replication Tracker would lead to increased numbers of published replications, we must consider whether Replication Tracker would be useful if the number of published replications remains low. Certainly, many papers will simply never be replicated, and many others will only have one reported replication attempt.
We do not believe these issues undermine the utility of Replication Tracker for several reasons. First, the findings which are of broadest interest to the community are likely the very same findings for which the most replications are attempted. Thus, while many low-impact papers may lack replication data, the system will be most useful for the papers where it is most needed. Secondly, even low numbers of replications are often sufficient: because spurious results are unlikely to replicate, even only a handful of successful replications significantly increases the likelihood that a given finding is real (Moonesinghe et al., 2007). Finally, we note that even sparse replicability data is useful when aggregating over large numbers of papers, for instance, when producing aggregate Replicability Scores for journals. Similarly, it would be possible to aggregate across studies within individual literatures or using particular methods. For these aggregate scores, sparse data does not present a problem.
Would Tracking Replicability Stifle Novel Scientific Fields?
Commenters on the present paper have suggested that since new fields may still be designing the details of their methods, and may be less sure of what aspects of the method are necessary to correctly measure the effects under investigation, their initial results may appear less replicable. In this case, using replicability scores as a measure of paper, researcher, and journal quality – one of our explicit aims – could potentially stifle new fields of enquiry.
This is an important concern if true. We do not know of any systematic empirical data that would adjudicate the issue. However, we suspect that other factors may systematically increase replicability in new lines of inquiry. For example, young fields may focus on larger effects, with established fields focusing on increasingly subtle effects over time (cf Taubes and Mann, 1995). Additionally, in the case that subtle methodological differences prevent replication of results, Replication Tracker may actually aid researchers in identifying the relevant issues more quickly, spurring growth of the novel field.
We additionally note that it is not our intention that replicability become the sole criteria by which research quality is measured, nor do we think that is likely to happen. New fields are likely to generate excitement and citations, which will produce their own momentum. The goal is that replicability rates be considered in addition.
Would Replication Tracker Underestimate Replicability?
Commenters on the present paper have also suggested several ways in which Replication Tracker might underestimate replicability. Underestimating the replicability of a field could undermine both scientists’ and the public’s confidence in the field, leading to decreased interest and funding.
Null effect bias
Researchers may be more motivated to submit non-replications to the system as Brief Reports, while successful replications would languish in file-drawers. We suspect that this problem would disappear as the system gains popularity: Researchers typically attempt replications of effects that are crucial to their own line of work and will find it useful to report those replications in order to have their own work embedded in a well-supported framework. Moreover, many replication attempts are conducted by the authors of the original study, who will be intrinsically motivated to report successful replications in support of their own work. Nonetheless, this is an issue that should be evaluated and monitored as Replication Tracker is introduced, so that adjustments can be made as necessary.
Unskilled replicators
Another concern is that if on average the researchers that tend to conduct large numbers of strict replications are less skilled than the original researchers, this could lead to non-replications due to unknown errors. If this is the case, this issue could be compensated for in two ways. First, as Replication Tracker and Brief Reports raise the profile of replication, more skilled researchers may begin to conduct and report more replications. Second, as discussed above, there are numerous machine learning techniques to identify the most reliable sources of information. These techniques could be applied to mitigate this issue, by discounting replication data from users that have not been reliable sources of information in the past.
Spurious non-replications
Since the statistical power to detect an effect is never 1.0, even true effects sometimes do not replicate. High-profile papers in particular will be much more likely to be subject to replication attempts; since some replications even of real effects will fail, high-profile papers may be unfairly denigrated. This issue is compounded if typical statistical power in that literature is low, making replication improbable.
These issues can be dealt with directly in Replication Tracker, by appropriately weighing this probabilistic information. Recall that Replication Tracker provides both a Replicability Score, indicating whether existing evidence suggests that the target paper replicates, as well as a Strength of Evidence Score. A single non-replication – particularly one with only mid-sized power – is not strong evidence for non-replicability, and this should be reflected in the Strength Score. Replication attempts with low-power should not be RepLinked at all. If 8 of 10 replication attempts succeed – consistent with statistical power of 0.8 – that should be counted as strong evidence of replicability.
Will Type II Error Increase?
Finally, we must consider whether the changes people will make to their work will actually lead to an increased d′ (ability to detect true effects) or whether these changes will simply result in a tradeoff: researchers may eliminate some false positives (Type I error) only at the expense of increasing the false negative rate (Type II error). It is an open question whether fields like psychology and neuroscience are currently at an optimal balance between Type I and Type II error, and Replication Tracker would help provide data to adjudicate this issue. Moreover, some of the potential reforms would almost certainly increase d′, like conducting studies with greater statistical power.
Limitations to Evaluation by Tracking Replications
Replicability is a crucial measure of research quality; however, certain types of errors cannot be detected in by such a system. For instance, data may be misinterpreted, or a flawed method of analysis may be repeatedly used. Thus, while tracking replicability is an important component of post-publication assessment, it is not the only one needed. We have suggested presenting replicability metrics side-by-side with citation counts (Figure 2). Similarly, other post-publication evaluations, such as those described within other papers in this Special Topic, could be presented alongside these quantitative metrics.
While it is tempting to try to build a single system to track multiple aspects of research quality, we believe that constructing such a system will be extremely difficult, as different data structures are required to track each aspect of research quality. The Replication Tracker system, as currently envisioned, is optimized for tracking replications: The basic data structure is the RepLink, a connection between a published paper and a replication attempt of its findings. In contrast, to determine the truth value of a particular idea or theory, papers should be rated on how well the results justify the conclusions and linked to one another on the basis of theoretical similarity, not just strict methodological similarity. As such, we think that such information is likely best tracked by an independent system, which can be optimized accordingly. Ultimately, results from these multiple systems may then be aggregated and presented together on a single webpage for ease of navigation.
Conclusion
In conclusion, we propose tracking replication attempts as a key method of identifying high-quality research post-publication. We argue that tracking and incentivizing replicability directly would allow researchers to escape the current Tragedy of the Commons in scientific publishing, thus helping to speed the adoption of reforms. In addition, by tracking replicability, we will be able to determine whether any adopted reforms have successfully increased replicability.
No measure of research quality can be perfect; instead, we aim to create a measure that is robust enough to be useful. Citation counts have proven very useful in spite of the metrics’ many flaws as measures of a paper’s quality (for instance, papers which are widely criticized in subsequent literature will be highly cited). We do not propose replacing citation counts with replicability measures, but rather augmenting the one with the other. Tracking replicability and tracking citations have complementary strengths and weaknesses: Influential results may not be replicable. Replicable results may not be influential. Other post-publication evaluations, such as those described within other papers in this Special Topic, could be presented alongside these quantitative metrics. Assembling replicability data alongside other metrics in an open-access Web system should allow users to identify results that are both influential and replicable, thus more accurately identifying high-quality empirical work.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The first author was supported through the National Defense Science and Engineering Graduate Fellowship (NDSEG) Program. Many thanks to Tim O’Donnell, Manizeh Khan, Tim Brady, Roman Feiman, Jesse Snedeker, and Susan Carey for discussion and feedback.
References
Adamic, L. A., Zhang, J., Bakshy, E., and Ackerman, M. S. (2008). “Knowledge sharing and yahoo answers: everyone knows something,” in Proceedings of the 17th International Conference on World Wide Web, Beijing.
Albert, P. S., and Dodd, L. E. (2004). A cautionary note on the robustness of latent class models for estimating diagnostic error without a gold standard. Biometrics 60, 427–435.
Armitage, P., McPherson, C. K., and Rowe, B. C. (1969). Repeated significance tests on accumulating data. J. R. Stat. Soc. Ser. A Stat. Soc. 132, 235–244.
Baayen, R. H., Davidson, D. J., and Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 59, 390–412.
Bederson, B. B., Hu, C., and Resnik, P. (2010). “Translation by interactive collaboration between monolingual users,” in Proceedings of Graphics Interface, Ottawa, 39–46.
Bezeau, S., and Graves, R. (2001). Statistical power and effect sizes of clinical neuropsychology research. J. Clin. Exp. Neuropsychol. 23, 399–406.
Boffetta, P., Mclaughlin, J. K., Vecchia, C. L., Tarone, R. E., Lipworth, L., and Blot, W. J. (2008). False-positive results in cancer epidemiology: a plea for epistemological modesty. J. Natl. Cancer Inst. 100, 988–995.
Callaham, M. L., Wears, R. L., Weber, E. J., Barton, C., and Young, G. (1998). Positive-outcome bias and other limitations in the outcome of research abstracts submitted to a scientific meeting. JAMA 280, 254–257.
Callison-Burch, C. (2009). “Fast, cheap, and creative: evaluating translation quality using Amazon’s mechanical turk,” in Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 286–295.
Chase, L. J., and Chase, R. B. (1976). A statistical power analysis of applied psychological research. J. Appl. Psychol. 61, 234–237.
Cohen, J. (1962). The statistical power of abnormal-social psychological research. J. Abnorm. Soc. Psychol. 65, 145–153.
Cole, S. Jr., Cole, J. R., and Simon, G. A. (1981). Chance and consensus in peer review. Science 214, 881–886.
Coursol, A., and Wagner, E. E. (1986). Effect of positive findings on submission and acceptance rates: a note on meta-analysis bias. Prof. Psychol. Res. Pr. 17, 136–137.
Cuijpers, P., Smit, F., Bohlmeijer, E., Hollon, S. D., and Andersson, G. (2010). Efficacy of cognitive-behavioral therapy and other psychological treatments for adult depression: meta-analytic study of publication bias. Br. J. Psychiatry 196, 173–178.
Dewald, W. G., Thursby, J. G., and Anderson, R. G. (1986). Replication in empirical economics: the journal of money, credit and banking project. Am. Econ. Rev. 76, 587–603.
Dickersin, K., Chan, S., Chalmers, T. C., Sacks, H. S., and Smith, H. (1987). Publication bias and clinical trials. Control. Clin. Trials 8, 343–353.
Dickersin, K., Min, Y.-I., and Meinert, C. L. (1992). Factors influencing publication of research results: follow-up of applications submitted to two institutional review boards. J. Am. Med. Assoc. 267, 374–378.
Doan, A., Ramakrishnan, R., and Halevy, A. Y. (2011). Crowdsourcing systems on the world-wide web. Commun. ACM 54, 86–96.
Dwan, K., Altman, D. G., Arnaiz, J. A., Bloom, J., Chan, A.-W., Cronin, E., Decullier, E., Easterbrook, P. J., Von Elm, E., Gamble, C., Ghersi, D., Ioannidis, J. P., Simes, J., and Williamson, P. R. (2008). Systematic review of the empirical evidence of study publication bias and outcome reporting bias. PLoS ONE 3, e3081. doi:10.1371/journal.pone.0003081
Easterbrook, P. J., Berlin, J. A., Gopalan, R., and Matthews, D. R. (1991). Publication bias in clinical research. Lancet 337, 867–872.
Edwards, W., Lindman, H., and Savage, L. J. (1963). Bayesian statistical inference for psychological research. Psychol. Rev. 70, 193–242.
Ernst, C., and Angst, J. (1983). Birth Order: Its Influence on Personality. New York: Springer-Verlag.
Eysenck, H. J., and Eysenck, S. B. (1992). Peer review: advice to referees and contributors. Pers. Individ. Dif. 13, 393–399.
Ferguson, C. J., and Kilburn, J. (2010). Much ado about nothing: the misestimation and overinterpretation of violent video game effects in eastern and western nations: comment on Anderson et al. (2010). Psychol. Bull. 136, 174–178.
Field, M., Munafo, M. R., and Franken, I. H. A. (2009). A meta-analytic investigation of the relationship between attentional bias and subjective craving in substance abuse. Psychol. Bull. 135, 589–607.
Flint, J., and Munafo, M. R. (2009). Replication and heterogeneity in gene x environment interaction studies. Int. J. Neuropsychopharmacol. 12, 727–729.
Franklin, M., Kossmann, D., Kraska, T., Ramesh, S., and Xin, R. (2011). CrowdDB: answering queries with crowdsourcing. Paper Presented at the SIGMOD 2011, Athens.
Gehr, B. T., Weiss, C., and Porzsolt, F. (2006). The fading of reported effectiveness. A meta-analysis of randomised controlled trials. BMC Med. Res. Methodol. 6, 25. doi:10.1186/1471-2288-6-25
Gerberg, A. S., Green, D. P., and Nickerson, D. (2001). Testing for publication bias in political science. Polit. Anal. 9, 385–392.
Harris, J. R. (1998). The Nurture Assumption: Why Children Turn out the Way That They Do. New York: Free Press.
Hartshorne, J. K., Salem-Hartshorne, N., and Hartshorne, T. S. (2009). Birth order effects in the formation of long-term relationships. J. Individ. Psychol. 65, 156–176.
Healy, D. G., Abou-Sleiman, P. M., Casas, J. P., Ahmadi, K. R., Lynch, T., Gandhi, S., Muqit, M. M., Foltynie, T., Barker, T., Bhatia, K. P., Quinn, N. P., Lees, A. J., Gibson, J. M., Holton, J. L., Revesz, T., Goldstein, D. B., and Wood, N. W. (2006). UCHL1 is not a Parksinon’s disease susceptibility gene. Ann. Neurol. 59, 627–633.
Hirschhorn, J. N., Lohmueller, K. E., Byrne, E., and Hirschhorn, K. (2002). A comprehensive review of genetic association studies. Genet. Med. 4, 45–61.
Hubbard, R., Vetter, D. E., and Little, E. L. (1998). Replication in strategic management: scientific testing for validity, generalizability, and usefulness. Strateg. Manage. J. 19, 243–254.
Ioannidis, J. P. A. (2005a). Contradicted and initially stronger effects in highly cited clinical research. J. Am. Med. Assoc. 294, 218–228.
Ioannidis, J. P. A. (2005b). Why most published research findings are false. PLoS Med. 2, e124. doi:10.1371/journal.pmed.0020124
Ioannidis, J. P. A. (2011). Meta-research: the art of getting it wrong. Res. Syn. Methods 1, 169–184.
Ioannidis, J. P. A., Ntzani, E. E., Trikalinos, T. A., and Contopoulos-Ioannidis, D. G. (2001). Replication validity of genetic association studies. Nat. Genet. 29, 306–309.
Ioannidis, J. P. A., Trikalinos, T. A., Ntzani, E. E., and Contopoulos-Ioannidis, D. G. (2003). Genetic associations in large versus small studies: an empirical assessment. Lancet 361, 567–571.
Jaeger, T. F. (2008). Categorical data analysis: away from ANOVAs (transformation or not) and towards logit mixed models. J. Mem. Lang. 59, 434–446.
Jennions, M. D., and Møller, A. P. (2002a). Publication bias in ecology and evolution: an empirical assessment using the “trim and fill” method. Biol. Rev. Camb. Philos. Soc. 77, 211–222.
Jennions, M. D., and Møller, A. P. (2002b). Relationships fade with time: a meta-analysis of temporal trends in publication in ecology and evolution. Proc. Biol. Sci. 269, 43–48.
Kosciulek, J. F., and Szymanski, E. M. (1993). Statistical power analysis of rehabilitation counseling research. Rehabil. Couns. Bull. 36, 212–219.
Kriegeskorte, N., Simmons, W. K., Bellgowan, P. S. F., and Baker, C. I. (2009). Circular analysis in systems neuroscience: the dangers of double dipping. Nat. Neurosci. 12, 535–540.
Kristensen, P., and Bjerkedal, T. (2007). Explaining the relation between birth order and intelligence. Science 316, 1717.
Law, E., von Ahn, L., Dannenberg, R., and Crawford, M. (2007). TagATune: a game for sound and music annotation. Paper Presented at the ISMIR, Vienna.
Lerner, J. S., and Gonzalez, R. M. (2005). Forecasting one’s future based on fleeting subjective experiences. Pers. Soc. Psychol. B. 31, 454–466.
Lohmueller, K. E., Pearce, C. L., Pike, M., Lander, E. S., and Hirschhorn, J. N. (2003). Meta-analysis of genetic association studies supports a contribution of common variants to susceptibility to common disease. Nat. Genet. 33, 177–182.
Mahoney, M. J. (1977). Publication prejudices: an experimental study of confirmatory bias in the peer review system. Cognit. Ther. Res. 1, 161–175.
Maraganore, D. M., Lesnick, T. G., Elbaz, A., Chartier-Harlin, M.-C., Gasser, T., Kruger, R., Hattori, N., Mellick, G. K., Quattrone, A., Satoh, J.-I., Toda, T., Wang, J., Ioannidis, J. P. A., de Andrade, M., Rocca, W. A., ad the UCHL1 Global Genetics Consortium. (2004). UCHL1 is a Parkinson’s disease susceptibility gene. Ann. Neurol. 55, 512–521.
Misakian, A. L., and Bero, L. A. (1998). On passive smoking: comparison of published and unpublished studies. J. Am. Med. Assoc. 280, 250–253.
Mone, M. A., Mueller, G. C., and Mauland, W. (1996). The perceptions and usage of statistical power in applied psychology and management research. Pers. Psychol. 49, 103–120.
Moonesinghe, R., Khoury, M. J., and Janssens, C. J. W. (2007). Most published research findings are false-but a little replication goes a long way. PLoS Med. 4, e28. doi:10.1371/journal.pmed.0040028
Munafò, M. R., Stothart, G., and Flint, J. (2009). Bias in genetic association studies and impact factor. Mol. Psychiatry 14, 119–120.
Newton, D. P. (2010). Quality and peer review of research: an adjudicating role for editors. Account. Res. 17, 130–145.
Olson, C. M., Rennie, D., Cook, D., Dickersin, K., Flanagin, A., Hogan, J. W., Zhu, Q., Reiling, J., and Pace, B. (2002). Publication bias in editorial decision making. JAMA 287, 2825–2828.
Peters, D. P., and Ceci, S. J. (1982). Peer-review practices of psychological journals: the fate of published articles, submitted again. Behav. Brain Sci. 5, 187–195.
Richard, F. D., Bond, C. F. Jr., and Stokes-Zoota, J. J. (2003). One hundred years of social psychology quantitatively described. Rev. Gen. Psychol. 7, 331–363.
Ruggiero, K. M., and Marx, D. M. (1999). Less pain and more to gain: why high-status group members blame their failure on discrimination. J. Pers. Soc. Psychol. 77, 774–784.
Ruggiero, K. M., Steele, J., Hwang, A., and Marx, D. M. (2000). Why did I get a ‘D’? The effects of social comparisons on women’s attributions to discrimination. Pers. Soc. Psychol. B. 26, 1271–1283.
Saxe, R., Brett, M., and Kanwisher, N. (2006). Divide and conquer: a defense of functional localizers. Neuroimage 30, 1088–1096.
Sedlmeier, P., and Gigerenzer, G. (1989). Do studies of statistical power have an effects on the power of studies? Psychol. Bull. 105, 309–316.
Sena, E. S., Worp, H. B. V. D., Bath, P. M. W., Howells, D. W., and Macleod, M. R. (2010). Publication bias in reports of animal stroke studies leads to major overstatement of efficacy. PLoS Biol. 8, e1000344. doi:10.1371/journal.pbio.1000344
Shen, W., Kiger, T. B., Davies, S. E., Rasch, R. L., Simon, K. M., and Ones, D. S. (2011). Samples in applied psychology: over a decade of research in a review. J. Appl. Psychol. 96, 1055–1064.
Snow, R., O’Conner, B., Jurafsky, D., and Ng, A. Y. (2008). “Cheap and fast – but is it good? Evaluating non-expert annotations for natural language tasks,” in Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing Edinburgh, 254–263.
Trikalinos, T. A., Ntzani, E. E., Contopoulos-Ioannidis, D. G., and Ioannidis, J. P. A. (2004). Establishment of genetic associations for complex diseases is independent of early study findings. Eur. J. Hum. Genet. 12, 762–769.
Tversky, A., and Kahneman, D. (1971). Belief in the law of small numbers. Psychol. Bull. 76, 105–110.
von Ahn, L., and Dabbish, L. (2008). General techniques for designing games with a purpose. Commun. ACM 51, 58–67.
von Ahn, L., Maurer, B., McMillen, C., Abraham, D., and Blum, M. (2008). reCAPTCHA: human-based character recognition via web security measures. Science 321, 1465–1468.
Vul, E., Harris, C., Winkielman, P., and Pashler, H. (2009). Puzzlingly high correlations in fMRI studies of emotion, personality, and social cognition. Perspect. Psychol. Sci. 4, 274–290.
Wagenmakers, E.-J., Wetzels, R., Borsboom, D., and van der Maas, H. L. (2011). Why psychologists must change the way they analyze their data: the case of psi: Comment on Bem, 2011. J. Pers. Soc. Psychol. 100, 426–432.
Wager, T. D., Lindquist, M., and Kaplan, L. (2007). Meta-analysis of functional neuroimaging data: current and future directions. Soc. Cogn. Affect. Neurosci. 2, 150–158.
Wager, T. D., Lindquist, M. A., Nichols, T. E., Kober, H., and van Snellenberg, J. X. (2009). Evaluating the consistency and specificity of neuroimaging data using meta-analysis. Neuroimage 45, S210–S221.
Welinder, P., Branson, S., Belongie, S., and Perona, P. (2010). The multidimensional wisdom of the crowds. Paper Presented at the Advances in Neural Information Processing Systems 2010, Vancouver.
Yan, T., Kumar, V., and Ganesan, D. (2010). “Crowdsearch: exploiting crowds for accurate real-time image search on mobile phones,” in Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, San Francisco.
Yarkoni, T. (2009). Big correlations in little studies: inflated fmri correlations reflect low statistical power-commentary on Vul et al. (2009). Perspect. Psychol. Sci. 4, 294–298.
Yarkoni, T., and Braver, T. S. (2010). “Cognitive neuroscience approaches to individual differences in working memory and executive control: conceptual and methodological issues,” in Handbook of Individual Differences in Cognition: Attention, Memory, and Executive Control, eds A. Gruzka, G. Matthews, and B. Szymura (New York: Springer), 87–108.
Appendix
Survey Methods and Results
We contacted 100 colleagues directly as part of an anonymous Web-based survey. Colleagues of the authors from different institutions were invited to participate, as well as the entire faculty of one research university and one liberal arts college. Forty-nine individuals completed the survey: 26 faculty members, 9 post-docs, and 14 graduate students. Thirty-eight of these participants worked at national research universities. Respondents represented a wide range of sub-disciplines: clinical psychology (2), cognitive psychology (11), cognitive neuroscience (5), developmental psychology (10), social psychology (6), school psychology (2), and various inter-subdisciplinary areas.
The survey was presented using Google Forms. Participants filled out the survey at their leisure during a single session. The full text of the survey, along with summaries of the results, is included below. All research was approved by the Harvard University Committee on the Use of Human Subjects, and informed consent was obtained.
Part 1: Demographics
Your research position: graduate student, post-doc, faculty, other (26 faculty, 9 post-docs, and 14 graduate students).
Your institution: national university, regional university, small liberal arts college, other (38 national university, 4 regional university, 5 small liberal arts college, 2 other).
Your subfield (cognitive, social, developmental, etc.; There is no standard set of subfields. Use your own favorite label): ________
(11 cognitive psychology, 10 developmental psychology, 6 social psychology, 5 cognitive neuroscience, 2 school psychology, 2 clinical psychology, 13 multiple/other).
Part 2: Completed replications
In this section, you will be asked about your attempts to replicate published findings. When we say “replication,” we mean:
-a study in which the methods are designed to be as similar as possible to a previously published study. There may be minor differences in the method so long as they are not expected to matter under any existing theory. However, a study which uses a different method to make a similar or convergent theoretical point would be more than a replication. If you attempted to replicate the same finding several times, each attempt should be counted separately.
Given this definition…
1) Approximately how many times have you attempted to replicate a published study? Please count only completed attempts – that is, those with at least as many subjects as the original study. ________
Total: 257; Mean: 6; Median: 2; SD: 11
(3 excluded: “NA,” “too many to count,” “50+”)
2) How many of these attempts *fully* replicated the original findings? ____
Excluding those excluded in (1):
Total: 127; Mean: 4; Median: 1; SD: 7
3) How many of these attempts *partially* replicated the original findings? ____
Excluding those excluded in (1):
Total: 77; Mean: 2; Median: 1; SD: 5
4) How many of these attempts failed to replicate any of the original findings? ___
Excluding those excluded in (1):
Total: 79; Mean: 2; Median: 1; SD: 4
5) Please add any comments about this section here: _____
[comments]
Part 3: Aborted replications
In this section, you will be asked about attempted replications that you did not complete (e.g., tested fewer participants than were tested in the original study).
1) Approximately how many times have you started an attempted replication but stopped before collecting data from a full sample of participants? ____
Total: 48; Mean: 1; Median: 0; SD: 3
[3 excluded: “a few,” “countless,” (lengthy discussion)]
2) Of these attempts, how many were stopped because the data thus far failed to replicate the original findings? ____
Excluding those excluded in (1):
Total: 38; Mean: 2; Median: 0.5; SD = 4
3) Of these attempts, how many were stopped for another reasons (please explain)? ___
[comments]
4) Please add any comments about this section here.
[comments]
Part 4: File-drawers
1) Approximately how many experiments have you completed (collected the full dataset) but, at this point, do not expect to publish? ____
Total: 1312 (one participant reported “1000”); Mean: 31; Median: 3.5; SD: 154
(6 excluded: “many,” “ton,” “countless,” “30–50%?” 2 unreadable/corrupted responses)
2) Of these, how many are not being published because they did not obtain any statistically significant findings (that is, they were null results)? ___
Excluding those excluded in (1):
Total: 656 (one participant reported “500”); Mean: 17; Median: 2; SD: 81
3) Please add any comments about this section here: ___
[comments]
Keywords: replication, replicability, post-publication evaluation, open evaluation
Citation: Hartshorne JK and Schachner A (2012) Tracking replicability as a method of post-publication open evaluation. Front. Comput. Neurosci. 6:8. doi: 10.3389/fncom.2012.00008
Received: 30 May 2011;
Paper pending published: 10 October 2011;
Accepted: 30 January 2012;
Published online: 05 March 2012.
Edited by:
Nikolaus Kriegeskorte, Medical Research Council Cognition and Brain Sciences Unit, UKReviewed by:
Nikolaus Kriegeskorte, Medical Research Council Cognition and Brain Sciences Unit, UKAlexander Walther, Medical Research Council Cognition and Brain Sciences Unit, UK
Copyright: © 2012 Hartshorne and Schachner. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Joshua K. Hartshorne, Department of Psychology, Harvard University, 33 Kirkland Street, Cambridge, MA 02138, USA. e-mail: jharts@wjh.harvard.edu