Decoupling the scholarly journal
- School of Information and Library Science, University of North Carolina at Chapel Hill, Chapel Hill, NC, USA
Although many observers have advocated the reform of the scholarly publishing system, improvements to functions like peer review have been adopted sluggishly. We argue that this is due to the tight coupling of the journal system: the system's essential functions of archiving, registration, dissemination, and certification are bundled together and siloed into tens of thousands of individual journals. This tight coupling makes it difficult to change any one aspect of the system, choking out innovation. We suggest that the solution is the “decoupled journal (DcJ).” In this system, the functions are unbundled and performed as services, able to compete for patronage and evolve in response to the market. For instance, a scholar might deposit an article in her institutional repository, have it copyedited and typeset by one company, indexed for search by several others, self-marketed over her own social networks, and peer reviewed by one or more stamping agencies that connect her paper to external reviewers. The DcJ brings publishing out of its current seventeenth-century paradigm, and creates a Web-like environment of loosely joined pieces—a marketplace of tools that, like the Web, evolves quickly in response to new technologies and users' needs. Importantly, this system is able to evolve from the current one, requiring only the continued development of bolt-on services external to the journal, particularly for peer review.
Introduction
Why have we failed to reform peer review? It is certainly not for lack of trying; the last few decades have seen growing awareness of the institution's glaring weaknesses, and a plethora of alternatives suggested. We suggest that there are two reasons reform has been lacking:
- Changes to peer review are just patches on a fundamentally broken scholarly journal system.
- Proposals offer no smooth transitions from the present system.
In this paper, we suggest a reform of peer review that is built atop a reform of the entire publishing system. Importantly, though, we also argue that this new system can evolve in incremental steps, each viable on its own, from the present one. To guide us, we borrow the idea of “refactoring.”
Refactoring is a programming practice in which we look at a computer system, identify parts that are confusing, inefficient, or redundant, and then systematically improve them—all while making sure that the functions of the program do not change (Hendler, 2007; Ding et al., 2009). We propose a refactoring of the scholarly journal system. This starts with an analysis of the current system, which we will do in the next section. We then proceed to suggest a better system, the “decoupled journal (DcJ).” After reviewing similar solutions proposed by others, we describe the DcJ in detail, and give some examples of what it would look like in practice. We close by considering advantages of our proposal, particularly how scholars can smoothly transition to it from the current model.
The Current Scholarly Journal System
Functions of the Journal
Our first step in analyzing the scholarly journal system is to determine its functions. These are our constraints: whatever we change about the system, we must make sure that it can still perform these functions. Next we examine how the functions are currently being performed—the structure of the system. Finally we look for ways in which the current structure seems inefficient or redundant, and propose improvements
An authoritative list of functions is well beyond our scope. However, over the decades a consensus has emerged in the literature that journals have four “traditional functions” (Rowland, 2002):
- Archiving: permanently storing scholarship for later access.
- Registration: time-stamping authors' contributions to establish precedence.
- Dissemination: getting scholarly products out to scholars who want to read them.
- Certification: assessing contributions and giving “stamps of approval.”
Over the years many authors have suggested additional or alternate functions (many are listed in Table 1). We will base our analysis on the traditional functions, since they are as close to an authoritative list as is available. However, observing that several proposed functions seem to be sub-functions of the traditional four, we incorporate them as well. We also add a few observed sub-functions of our own, finally giving us the more detailed model of the journal's functions show in Figure 1. This model honors the consensus around the traditional four functions, while at the same time allowing us to examine the diverse functions of the journal in greater detail.
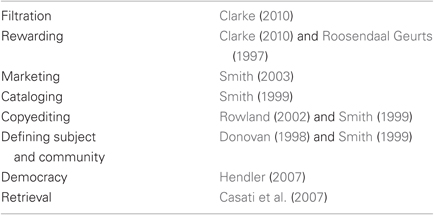
Table 1. Functions of the journal outside the traditional four.

Figure 1. Functions of the journal. Three of the four traditional functions are split into sub-functions. Registration is considered a by-product of proper archiving.
We note that certification, for example, does not just consist of giving out seals of approval to worthy work—the feedback that authors get from reviews is also a valuable function. Dissemination has the greatest number of sub-functions; it requires some form of manuscript preparation (copyediting and typesetting), marketing, and provision for search, in addition to the actual publication. Archiving necessitates both persistent storage and identification. We break a bit with tradition by collapsing the registration function with archiving, as it seems clear that any system meeting the needs of the latter will fulfill the function of the former as well. Likewise, we omit proposed functions like “rewarding” that are supported by the journal system, but not actually one of its functions (the reward proper comes from one's peers, university or granting agency).
Structure of the Journal
Our next step is to examine the structure of the journal system to see how well it supports the performance of its functions. Again, a full-scale analysis, such as Ware and Mabe's (2009) is well out of our scope. However, three particularly maladaptive features of the current structure are readily apparent:
- The market is split into around 25,000 individual journals (Ware and Mabe, 2009), each one performing all four functions more or less in isolation as seen in Figure 2 (van de Sompel et al., 2004).
- The business model is dominated by the selling of content to readers, and consequently tends to value secrecy and closedness.
- Peer review, the lynchpin of the entire system, shows remarkably little variation or innovation in practice—despite a troubling opacity, observed bias (Peters and Ceci, 1982; Wenneras and Wold, 2008), inefficiency, and lack of empirical support (Jefferson et al., 2007).
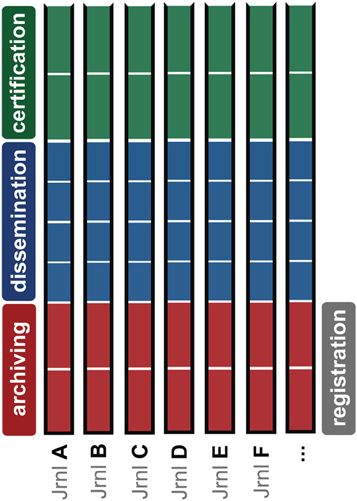
Figure 2. The current structure performing the four functions. There are thousands of journals, each a self-contained silo that performs all of the functions on its own.
The last two of these problems have seen sustained and high-profile attention from policy-makers, thought leaders, and a growing percentage of the academy's rank and file. However, we argue that while it might not be apparent at first glance, the first problem is actually the most serious, and in fact leads to the other two.
The Balkanization of the scholarly literature was not planned; indeed, the journal was supposed to be a cure for just this problem. Oldenburg, creator of the first scientific journal in 1665, realized that instead of mailing letters to one another, as was the contemporary practice, scientists could communicate more efficiently by mailing to a central location and then disseminating all the letters together. Scholars today still care much less about the journal than what it contains, and this sense grows as they increasingly access literature through vast, flat indexes like PubMed and Google Scholar. Ultimately, there is just one journal: the scholarly literature (Gordon and Poulin, 2008), a conceptual space we dub the metajournal.
The persistent fragmentation of the metajournal leads to appalling diseconomies of scale. Perversely in this age of ever-growing academic specialization, we have a system of journals that are still technical generalists—an archipelago of self-sufficient islands, each blithely performing all four functions in splendid isolation. Journals as they now exist are jacks of all the communication trades, but consequently masters of none.
More seriously, the bundling together of all the functions in a single entity has stifled innovation by making it hard to experiment with individual functions—like peer review, or open access—without the expense and risk of creating whole new journals. I can choose a journal to publish in or read, but I cannot in most cases ask the journal for a particular kind of review. Bundling the functions together insulates any one function from the market, allowing poor implementations to flourish and preventing good ones from being directly rewarded. This explains the slow change in business models and peer review models that have perplexed many forward-thinking academics and publishers (Greaves et al., 2006; Gotzsche et al., 2010; Schriger et al., 2011). We suggest that no amount of activism or innovation aiming to correct closed publishing models or broken certification models will succeed in the current system that closely bundles all the functions together.
There is a good analogy here to another concept in programming: that of separation of concerns (SoC) (Reade, 1989). Concerns are the different sorts of things a program does: presenting output, receiving commands, communicating over the network, and so on. The idea is that if each of the concerns is handled in relative isolation from the others, it is much easier to maintain, repair, and improve its handling, because doing so doesn't disturb the rest of the system. If, on the other hand, SoC is violated, improving a single feature requires modifying or even rewriting the entire system. This is exactly the current problem facing scholarly communication: the journal system has fused the functions together in such a way that consumers have little choice regarding individual functions, and innovators must tackle the entire system in order to change a few pieces.
The Decoupled Journal: Proposition and History
The Decoupled Journal
Borrowing another programming term, we suggest that any solution to the problems of publishing must start with decoupling (Stevens et al., 1974). In software this means making the pieces of the systems as small, distinct, and modular as possible. This can be done for the journal, as well. We know the functions of the scholarly journal. Let's make communication services that pick just one of those functions; then, do it well. The basic providers of scholarly publishing should not be publishers or journals, but smaller, more specialized, more modular services. This will let us assess different segments' performance more clearly, spot inefficiencies more quickly, and correctly them more easily. The central virtue of a DcJ is, as in the case of a decoupled program, the system's ability to adapt to change quickly and relatively painlessly, because any given piece is as can easily be replaced.
To use a metaphor outside computing, the current journal system is like a fixed-price menu, in which a few sets of courses are selected for diners in advance, and ordered as one item. This has the benefit of simplicity. But its inflexibility means that diners don't get to exercise their creativity, and the chef may never realize that the risotto isn't any good—you just can't get the quail without it. We advocate scholarly communication à la carte—letting diners combine courses as they please so they get the meal that is most satisfying at the best price. Our goal is not to change the functions of the journal, but to remix (or rather, un-mix) them, taking advantage of profound technological change in the centuries since the system was developed.
Previous Implementations
There are several publishing paradigms that partly decouple the journal, and these deserve a closer look. Of these, we will examine overlay journals, PLoS One, post-publication review services, and Smith's (1999) proposed Deconstructed Journal.
Overlay journals
Overlay journals, as first suggested by Ginsparg (1997) are journals that only perform the certification function; they peer review material already published, archived, and registered in an external repository, and publish a simple link for each accepted article (Moyle and Lewis, 2008; Brown, 2010). Repositories can be institutional repositories (IRs) or subject-area repositories like the ArXiv.
There have been several interesting prototypes of tools for creating and managing overlay journals, as well as a number of function examples in the wild. The RIOJA project (Moyle and Lewis, 2008) created an overlay journal system based on Open Journal Systems, a popular application for managing open access journals (Willinsky, 2003). Also in the UK, the Overlay Journal Infrastructure for the Meteorological Sciences project created a demo overlay journal. Rodriguez et al. (2006) created an interesting prototype of an overlay journal system that uses the co-authorship graph to automatically select appropriate reviewers for articles in distributed repositories, then adds review information as metadata using The Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). In addition to these demonstration projects, Table 2 lists examples of real journals that have actually implemented the overlay model.
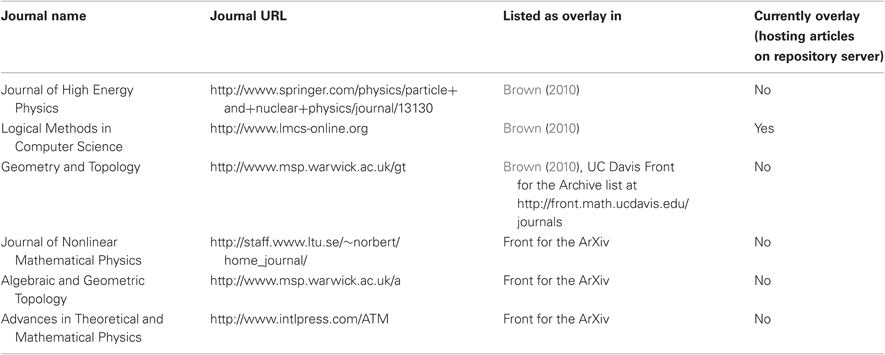
Table 2. Overlay journals in the wild.
Overlay journals are promising because they could allow experimentation in peer review and other functions without the burden of managing entirely new journals. By offloading responsibility for archiving, dissemination, and registration to external repositories, overlay journals demonstrate that scholarly journals can indeed be decoupled and still succeed. However, the history of the overlay journal is not particularly encouraging for proponents of decoupling. The idea has existed some time, and has apparently failed to ignite the imaginations of potential publishers. Indeed, all but one of the journals in Table 2 have abandoned the overlay model and returned to traditional, highly coupled publishing.
What accounts for this disappointing reaction? It is impossible to know for sure, and it would be interesting to pursue research asking editors of journals who had switched to traditional publishing their reasons. However, one reason might be technical: until recently, the available tools were optimized for traditional journals; simply archiving and publishing authors' work as a conventional journal may have been easier than managing an overlay infrastructure, especially given the low cost of electronic storage. However, perhaps a deeper problem is that overlay journals do not pursue the decoupling idea far enough: they split the roles of the journal it two, but perhaps it needs to be split yet further.
Plos one
Another approach partly decoupling the journal comes from the journal PLoS One. This is an unconventional title that publishes work from any scientific discipline, provides free access for readers, and uses a relatively novel approach to peer review: reviewers are specifically told not to consider a work's significance or potential impact, but only whether the work is methodologically sound.
PLoS have decoupled two functions traditionally bundled together in the same journal. Specifically, they separate the assess-significance part of certification from the assess-soundness part. Methods and formal rigor are assessed conventionally. But the assess-significance component is done in a novel way, after publication, by tracking a variety of “Article-level metrics” including social bookmarking, blogging, and citation at the article level, then displaying this with the article. This innovative approach to part of assessment is only possible because PLoS One uncoupled two certification sub-functions from one another, allowing the functions to be performed by different structures.
PLoS One also decouples the copyediting function; its author guidelines page warns that manuscripts “will not be subject to detailed copyediting. Obtaining this service is the responsibility of the author.” But PLoS does not simply assume articles will be perfectly edited; instead, the guidelines give a list of 21 external services that perform this function for a fee. As in the case of certification for importance, PLoS treats copyediting as a module than can be decoupled and run independently.
This approach has been very successful for PLoS One; according to figures available on their website, they published over 5000 articles in 2010, and the rate at which new articles are published continues to grow. It has also been profitable, as authors (or their funders) pay a publication fee of US$1350 per article. This success has not gone unnoticed by other publishers, who—despite early criticism (Butler, 2008)—have introduced similar “inclusive journals” (Wager, 2011) like BMJ Open, Scientific Reports, and Sage Open. However, this model still clings to some of the flaws in the traditional journal structure. First, publishing in PLoS One is exclusive; authors publish there, and only there. Neither do authors have choices about what kind of review they will receive. They may wonder if they could get better value for their money, as PLoS publishes an article for $1350, while the ArXiv, which performs a much more limited editorial review, spends about $7; as Poynder (2011) asks, “is the additional work undertaken by PLoS One 193 times more costly than ArXiv's moderation process?” Finally, one wonders whether a future scholarly journal ecosystem dominated by a few inclusive megajournals will not become as hidebound and oligarchic as the current system, dominated by a few publishers. Again we must wonder: what if we started here and then decoupled even more?
Post-publication review services
A third scholarly communication structure that that suggests the potential of the DcJ is the post-publication review service. There are several of these in existence, but for the sake of space we will focus on two: Faculty of 1000 and Mathematics Reviews.
Faculty of 1000 (F1000), according its website:
… identifies and evaluates the most important articles in biology and medical research publications. The selection process comprises a peer-nominated global “Faculty” of the world's leading scientists and clinicians who rate the best of the articles they read and explain their importance.
The goal of the service is to provide an additional filter, after classical peer review, to help researchers manage their growing reading lists. In doing so, they provide another example of a successful decoupled certification module. While some have argued that F1000 ranking correlate strongly with Thomson's Journal Impact Factor (JIF) and are thereby of little value (Nature Neuroscience, 2005), Allen et al. (2009) show that F1000 does indeed spot valuable research overlooked by high-profile journals.
Mathematics Review is an abstracting service, but one that is occasionally called into service as a post-publication peer review venue when the traditional journals fail in their role as certifiers. In this case, abstracters may abandon objectivity and attack papers and their reviewers directly. As Kuperberg (2002) describes:
The community is often angry with the referees of [papers that should not have passed review], but anonymity protects them from the readers rather than the authors. Typically the Math Review sets the record straight.
In this way, Mathematics Review acts as certification's second line of defense, a failsafe against the inevitable failures of the primary system.
These services and others like them are the most successful at decoupling the certification layer, because they do only that—unlike PLoS One or even the overlay journals, they make few if any attempts to perform other dissemination functions like marketing, search, or manuscript preparation. However, they cannot replace the current certification layer because they fail to sufficiently provide the indirect function of rewarding authors; again in Kuperberg's (2002) words, “they are not designed to substitute for journal names in the author's list of publications” (264). That is, they have decoupled part of the certification function, but not enough to fulfill it entirely.
The deconstructed journal
This last example of decoupling is different from the other three because it has not actually been implemented as a working system. However, the Deconstructed Journal (Smith, 1999) is important to discuss because it remains the most complete description of the DcJ. Indeed, we see the DcJ as a way to implement Smith's earlier vision, making a few modifications and taking advantage of advances in information technology over the last 12 years.
The Deconstructed Journal (DJ) is based on “three insights”:
- We shouldn't confuse the means (the journal) with the function.
- Any replacement to journals must “satisfy the same needs” as current system.
- This can be achieved by cooperating agencies; there's no need for a central publisher.
The DJ decouples most of the functions of the journal, except those gathered in a “Subject Focal Point” (SFP), which brings together relevant literature and serves to as a portal for a community of readers. Archiving, preparation, and certification are all handled by specialist services. The SFP manages marketing and serves as a focal point for community-defining. This is a remarkably prescient vision, as it predates widespread adoption of many technologies that would greatly facilitate the DJ. Development of DOIs, OAI-PMH, IRs, social media, and other technologies makes this a significantly more practical and attractive framework, as Smith points out in a 2003 follow-up article.
van de Sompel et al. (2004) suggest many of the same ideas as Smith, using the ecosystem around the ArXiv subject repository as an example of a publishing value chain that is already partly “decomposed” (van de Sompel, 2000). They point out that a “loosely coupled” system has three major advantages: it encourages innovation, adapts well to changing scholarly practices, and democratizes the largely monopolized scholarly communication market.
However, the DJ and decomposed models do still have some weaknesses. Neither Smith's nor van de Sompel's proposals take into account the power of social media to convey scholarship. Today we can imagine collections of more diffuse social media communities, like the ones that form around Twitter hashtags, replacing Smith's central SFPs. Second, and most importantly, neither Smith nor van de Sompel et al. spend much time laying out plans to gradually change from the present system to the ones they propose. This is entirely appropriate for these early proposals, which are quite revolutionary in scope. However, without next steps, the DJ will remain just a good idea.
The Functions of the Decoupled Journal
The DcJ (to distinguish it from Smith's DJ), is an updating of Smith's DJ, also incorporating similar suggestions from others including (Ginsparg, 2004; van de Sompel et al., 2004; Casati et al., 2007; Hendler, 2007; Cassella and Calvi, 2010). It takes full advantage of the Web's growing power and pervasiveness to give authors and readers complete control over the scholarly objects they produce and consume, and gives service providers unprecedented freedom to specialize, mutate, and innovate.
The base unit of the DcJ is the scholarly object, which can be anything from a dataset or annotation to an article or monograph—anything scholars produce that they want to share. Instead of simply landing in one of thousands of vertical journal bins, this object ricochets around a rich ecosystem of modular services, acquiring new metadata, comments, stamps, links, citations, annotations, and edits as it goes. It is safely preserved and identified in long-term storage, mirrored all over the planet. It is indexed in general and specialized search engines and pushed to specialist readers eager for its specific content. It, and millions like it, forms a universal journal, but not one with any central publisher. This is a metajournal; like the web, it defines the smallest possible set of central structures and standards, then opens the floodgates to the creativity and productiveness of thousands of service providers and millions of users.
The best way to describe the DcJ, though, is to recall that in refactoring, we must make sure the system continues to perform all the functions it did before. So in this section, we will go through the functions of the journal one by one, describing its provision in the DcJ. First are the functions of archiving: persistent storage and persistent identification. Because these are all done at the same level, we will also discuss publication here. This is followed by a discussion of other journal functions, including preparation, search, marketing, and certification. We will replace this final term with “assessment,” reflecting that quality judgments in the DcJ will be subtler than simple binary yes/no stamps.
Figures 3 and 4 describe the structure of the DcJ. In Figure 3, we see that the vertical silos have been replaced by horizontal bands of services, each performed by one or more independent service organizations. Figure 4 gives an example of one way a given article might navigate this system.
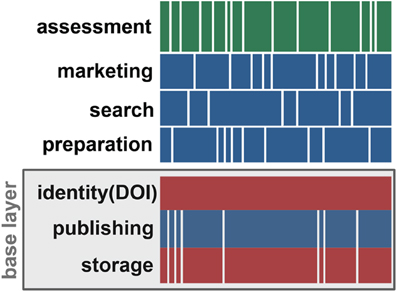
Figure 3. The decoupled journal. Although some vertical integration remains in the base layer, most of the functions are performed independently by a diverse ecosystem of service providers.
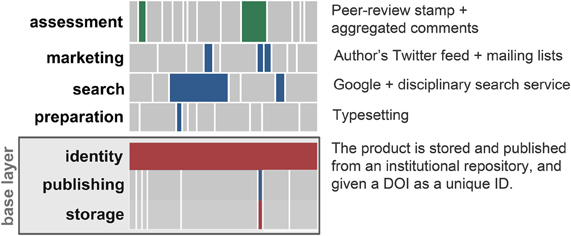
Figure 4. An example of a single article's view of the decoupled journal. Here we see one of many possible paths for an article in the decoupled journal. Authors and funders select which services and providers are best for a given article.
The Base Layer: Persistent Storage, Persistent Identification, and Publishing
Definition: A permanent, open, web-accessible home for all scholarly products.
Description: This module is special, because as the base layer, all the others depend on it. In the DcJ, using a base layer service is the least possible action a scholar can take toward in sharing her work. The base layer is also special because it couples three functions into a single service. This is because refactoring is not about blindly decoupling every function in sight; rather, it is meant to reduce coupling as far as practical but no further. Long-term storage without persistent IDs means there is no sure way to find the item again: it's not storage, it's disposal. Similarly, there is no point in long-term identifiers if the identified object goes away. Finally, in this age of cheap and widespread connectivity, it is scarcely harder to store something online than off. Moreover, making stored information objects networked is necessary for making mirrored backups at other sites, a crucial practice to safeguard data.
So the base layer publishes work, but we should not mistake this for “publishing” as the term is used today: reaching the end of a long submission, revision, and review process, then registering and disseminating an article in a journal. The DcJ turns that model on its head, making publication the first step in the process. It is a trivial step as easy as clicking a button, but one required to make further progress in meaningfully communicating a result of scholarly work.
Who does it now: Today, commercial and non-profit publishers handle storage and provision of a Document Object Identifier (DOI), a persistent identifier. Libraries may provide distributed backup storage in the form of paper copies, although this practice, at any volume, is certainly coming to an end. Publishers handle the electronic distribution of articles, and libraries (for now) distribute dead-tree copies. Growing number of articles are stored in freely accessible institutional and subject-area repositories.
Options in the future: In the future, authors will be able to choose where to deposit their work. In most cases, they will likely chose free online repositories to store and publish their work, since these will are reliable, easy, and support the important other functions as well as their for-pay counterparts. They may even have an institutional mandate (Bosc and Harnad, 2005) to do so. However, if fee-based repository services can offer useful additional functions, these may emerge as well. For instance, a repository could support comprehensive versioning and “forking” of papers, making publishing more like open-source software development (Casati et al., 2007). Identification will probably continue, at least in the medium term, to be provided by the DOI system, which has shown itself to be scalable and effective. The biggest change in these functions is that authors will choose to deposit a larger variety of materials as upstream services evolve to add value to them. So, products like datasets, reviews, comments, notes, blog posts, and even tweets will all find their way into being persistently locatable and available on the Web.
Transitional stages: There is almost no transitional work needed for services of this kind; hundreds of institutional and subject-area repositories already exist, and continue to fill with articles. One change is that many of these do not mint DOIs, although they do provide relatively permanent identification with a URI. Another change is that authors will need convincing to deposit non-article items in repositories; this is already beginning to happen with products like datasets. Once non-article items can be peer reviewed by external modules, this process will diversify and accelerate.
Preparation
Definition: Changing the format of a work to make it more suitable for a given (human or electronic) audience.
Description: There are many ways in which work needs to be transformed for dissemination. It may need copyediting, typesetting, or migration to alternate file formats. Datasets may need annotation or conversion to standard representations. Metadata may need to be added. Authors may want semantic markup to represent claims in machine-readable terms (Buckingham et al., 2000; Groth et al., 2010). In all these cases, the content of the work is unchanged, or nearly so; the representation is what is altered.
Who does it now: There are numerous companies that sell copyediting as a service to individual authors. However, preparation is still primarily the responsibility of the publishing journal, with authors expected to meet base guidelines. Although many journals outsource these tasks to specialists, saving money over doing conversions in-house, authors (or more often today, subscribers) do not get a say in whether that money is well-spent. What if, as an author, I want to pay to have my publication marked up entirely in RDF? Why should I pay for conversion to PDF if I think my readers only want HTML? Authors should be able to choose, based on their funding and desire, the forms their works will have.
Options in the future: In the DcL, authors will select the representations they prefer. An open market for these services, purchased à la carte, will drive down prices and reward the most valuable. Meanwhile, the open intellectual market will provide incentive for scholars to patronize preparation services whose work consistently broadens audiences and boost impact.
Transitional stages: PLoS One's policy of unloading copyediting to authors is a key precedent, and a step toward decoupling all preparation tasks from the other functions the metajournal. If more journals can be convinced to follow their lead, a market for preparation services of various types will continue to grow and diversify. As the cohesion and coupling of the scholarly communication ecosystem crumbles, this marketplace will be ready to accept the volume of papers and other products published by the metajournal.
Search
Definition: Connecting users to scholarly objects that meet their immediate information needs.
Description: To the best of our knowledge, search has not been suggested as one of the functions of the scholarly journal before. It is, however, increasingly indispensible. Over the last three decades scholars have been finding a growing percentage of their reading via search rather than browsing, a trend that still continues (Tenopir and King, 2008). Scholars have maxed out their ability to index work in their own heads, and so rely on the indexes maintained by search engines as the size of the literature continues to grow.
Who does it now: Currently scholarly work is indexed and searched at journal, publisher, library, subject, and global levels. Some search services, like Elsevier's Scopus, or dozens or subject-specific indexes, are sold to subscribers. Others are available for free from libraries and repositories. Google Scholar is a free, ad-supported search service that has seen wide adoption. Our own experience and anecdotal evidence suggests that scholars are migrating toward more global search tools and away from those offered by journals or publishers.
Options in the future: The future of academic search is likely to look quite similar to today, with a variety of providers using different business models to search different bodies of literature. One change is that search engines will have to accommodate different types of scholarly products as these become more important. Another is that these search engines will begin to incorporate signals like downloads, comments, and links to make better relevance judgments. They will also incorporate information about a searcher's professional social networks to personalize results further. Finally, we will see search continue to supplant browsing; readers will replace pushed content to just-in-time information pulled from search engines.
Transitional stages: There will be little if any transitional stage between the future of scholarly search and its present; since search is already mostly decoupled from the other functions, it will freely evolve, driven by market forces.
Marketing
Definition: Distributing scholarly content to users who have an ongoing need for it.
Description: Marketing should not be thought of as merely a commercial enterprise. Publishers do market their journals to subscribers, but this is much less significant than scholars' use of journals to market their own ideas. In this regard, the push of marketing should be thought of as complementary to the pull of search. When the marketing function is working efficiently, scholarly products are seen by their maximum useful audience, and individual scholars regularly consume all and only the work that is most valuable to them.
Who does it now: Today journals are the pre-eminent marketing space for scholars' ideas. Most scholarly articles are useful only to an extremely limited audience; authors face the problem of marketing their work to this tiny group of potentially interested readers. Today's narrowly focused journals have evolved to be good at this. These journals benefit authors, but also readers, who have the complementary need to access to as much literature as possible in their narrow sub-specialties. The problem, though, is that no matter how thin the subject matter of a journal is sliced, there will always be papers on the edges of its coverage. Readers' interests will never perfectly match the content of a journal. Meanwhile, ever-finer divisions promote fractured, isolated, and disconnected research.
Options in the future: Curated subject-area hubs like Smith's (1999) SFPs will form narrowly focused, journal-like information markets that are entirely decoupled, serving to connect authors and readers but leaving certification, publication, and archiving to others. However, unlike in Smith's vision, in the DcJ these will take a backseat to an entirely different form of marketing feeds.
Feeds will be powered not by expert editorial decisions but by analysis of a user's professional social network and past preferences. They will use dozens of data sources to analyze the reading, bookmarking, downloading, commenting, and sharing of a scholarly community as well as the assessments assigned to articles and their sources comparing them to the same activities of a given user. Over time, this will allow the system to make intelligent recommendations, both for reading material and for colleagues to “follow.” This has shown to be an effective way of creating strong but decentralized communities on services like Twitter.
Using informal ties to market and filter work is not a fundamentally new idea; scholarship has always been shaped by informal networks and “invisible colleges” (de Solla Price and Beaver, 1966). The true power of the scholarly social Web is not in formalizing or altering these ties (although this will happen); rather, it is in exposing them, uncovering the markers of “scientific ‘street cred’ ” (Cronin, 2001) for use as inputs for a wide array of computational techniques. Google uses the humble web link to fuel algorithms that have made it the user interface for Web. Imagine using the aggregated information footprints from millions of scholars to make similarly useful recommendations on which research they will find useful and important. And of course, scholars will have choices of multiple recommendation systems, letting algorithms compete on coverage, efficiency, creativity, and price. Scholars will decide which feeds to consume the same way they decide what journals to read now: by seeing which ones consistently surface content that's valuable to them. Decoupling marketing from the journal's other functions allows the market to quickly assess and reward innovative, effective systems.
To market their work, authors will think less in terms of where to submit products, and more about building connections over social networks with those scholars who want to see the kind of work they do. Marketing services may spring up to meet this need, driven by people with unusually high degrees of connectivity across multiple communities. Their knowledge of the network will be available for a fee, their service resembling matchmaking more than traditional marketing.
Transitional stages
The transition to a less centralized, more feed-based market has already begun. Tools like Mendeley and CiteULike already use network analysis of users' reading habits to tailor recommendations (Bogers and van den Bosch, 2008; Henning and Reichelt, 2008). Many scholars now turn to tools like Twitter feeds for marketing and being marketed to (Priem and Costello, 2010). One of this paper's authors has largely stopped reading journal tables of contents, finding that his Twitter feed gives him more relevant reading suggestions from a wider range of sources. In this environment, announcing a publication to one's feed is like publishing in a journal narrowly focused on the interests of your community. This will only become more pronounced as more scholars move more of their interactions online, and as data about these interactions accumulates.
Assessment
Definition: Attaching an assessment of quality to a scholarly object.
Description: We use “assessment” instead of the more traditional term “certification” to reflect the broader, more nuanced evaluation performed in the DcJ. A great many approaches to this have been suggested. It is useful to organize all these approaches along a set of dimensions that are more or less orthogonal to one another. We suggest such a set below, containing four scalar and three binary dimensions:
- Structure is anchored on one side by free text with no structure, and on the other by the maximum structure, a yes/no dichotomy. Most peer reviews fall somewhere in between, although they ultimately resolve into a yes or no ruling. Online article commenting systems mostly produce unstructured text.
- Anonymity runs from complete anonymity to real names backed up by globally unique identifies like those proposed by the ORCID initiative.
- Granularity refers to the size of the unit being assessed, from individual words on unique versions to global comments on the whole of a single version.
- Aggregation can be at a level as small as a single review on each paper or large as tens of thousands of users' downloads, each representing a single yes/no assessment.
- Invited or not: Are reviews accepted from specific people, or anyone?
- Assessing significance or not: Do reviews assess soundness only, or do they make the more subjective judgment of significance?
- Published or not: Are reviews published, or kept secret?
We can imagine these oppositions as describing dimensions in n-dimensional space. Any type of review imaginable can in theory be represented by exactly one point in this space. Of course, we do not claim that these particular dimensions are the only way to break down the topic, but rather that some set of dimensions like this one is a useful way to describe the many forms of certification.
Who does it now: Today, most of the possible certification n-space is empty of living examples. With a few exceptions, certification huddles around one small point: reviews that are unpublished, assess significance, and are by invited reviewers. There are two or three reviews that tend to examine both the paper as a whole and the quality of individual sections. Reviewers are anonymous, and reviews go from relatively unstructured free text at first, to a final ruling of thumbs up or down.
Options in the future: We argue that we do not need another grand scheme to revolutionize certification. Instead, we need a market where thousands of innovators, commercial and otherwise, can respond to the needs of authors and readers to evolve a new certification structure over time. For this to happen, certification must be entirely decoupled from the cost and distraction of supporting the other three functions, so that assessment services may compete fairly and evolve quickly.
When certification agents finally see themselves as certifiers rather than as publishers, we expect to see substantially greater diversity in the certification ecosystem. Certainly we will see overlay-type services that continue to supply journal-like peer review and branding while publishing only collections of links to approved papers. However, freed from the burden and crutch of publishing, assessment projects will quickly innovate further, looking for ways to differentiate themselves from competitors. Certification n-space will experience a land rush, quickly filling as innovators look to stake out claims on new-and-improved models.
Assessment services will experiment with a wide variety of review types including soundness-only reviews, high-volume reviews, editorial-only reviews, double-blind reviews, published reviews, reviews that assign grades rather than pass/fail, specialized supplementary reviews for statistics or ethics, non-exclusive reviews, pooled reviewers, and paid reviewers. What they will all have in common is a need to attract cash or attention in a crowded marketplace. Some will market their services to authors, others to readers—both of whom benefit from certification. A few may even charge reviewers for the chance to publicize their views. Many scholars will no doubt be interested in creating their own systems, funded by their institutions or granting agencies. Services will compete based on prestige, cost, turnaround time, and quality of feedback; most will fail to find enough users to be relevant (or solvent), but some will flourish. These will have proven their worth.
Along with these “traditional” stamping organizations we will see more qualitative review services that gather comments on an article from across the Web (as the Disqus system now does for blogs). We will see crowdsourced reviews and wikified articles. We will also see services that support purpose-built commenting or annotation systems layered atop existing article storage. As suggested by Hemminger (2009) and others, comments or annotations would be first-class scholarly products that would themselves be plugged into the base layer and could be disseminated, marketed, and reviewed like any other scholarly object.
We will also see more quantitative, data-driven reviews. These will draw their inspiration from data-hungry companies like Google. They will draw their raw material from the once-invisible traces of scholarly activities that are increasingly leaving tracks in the medium of the Web: tracks like downloads, bookmarks, comments, tweets, blog posts, and citations. All these aggregated altmetrics data, along with information about the social network generating them, will be a resource of unprecedented predictive power. We see early evidence for effectiveness of these approaches: webometrics techniques have delivered data on authors' and institution's productivity based on web mentions (Thelwall and Harries, 2004; Thelwall, 2008). Brody et al. (2006) are able to predict citation from early downloads, and Yan and Gerstein (2011) find that PLoS article-level metrics data from social sources resemble traditional citation data.
Recent studies have used Twitter activity to predict things like movie box-office earnings (Asur and Huberman, 2010) and stock prices (Bollen et al., 2010) with uncanny accuracy. Eventually, algorithmic prediction of articles' impact may be similarly accurate; we do not yet know. The proof is in the pudding: if aggregated quantitative assessments can consistently pick articles that user's value, their recommendations will become increasingly prestigious—and valuable. We can imagine a future in which administrators and funders value a certain time-tested, quantitatively based certification the same way they would value publication by a top journal today. After all, such quantitative metrics would be the result of aggregating many expert discussions and opinions together, rather than just two from reviewers.
There are two objections to this approach that deserve particular mention here. The first is, “do we really expect scholars to pay for services for review, then turn around and do reviews for the same services, for free?” The easy answer is, of course we do—it's what scholars already do now for journals. The more accurate answer, though, is that this is just the sort of problem that market-based, decoupled review will be good at solving. Any payment to reviewers will be passed along as a charge to authors buying reviews; if they find that the reviews are better for it, then it will happen. And of course reviewers might be rewarded in ways other than money; published reviews, for instance, could accumulate various types of electronic and traditional citations that directly benefit their writers. Certainly, reviewers that consistently identify important papers early will have opportunity to profit from their prognostication, either monetarily or socially. Finally, we do not know how much reviews have to cost, since they have never been subject to market forces in isolation. Even the best estimates involve guesswork, and vary between US$100 and 400 (Donovan, 1998; Rowland, 2002; Ware and Mabe, 2009). Competition is likely to drive these numbers down. Depending on the market's elasticity, money-saving measures like automatic reviewer selection (Rodriguez et al., 2006) may become common. Perhaps small groups of scholars will create their own free rankings, relying on social networks to gather and manage the review process. We cannot know until we uncouple certification and let it respond to market pressures on its own.
A second objection is what is to keep wealthy authors (or their funders) from buying stamps outright? After all, this system seems built primarily around the needs of authors; is to keep them from exploiting the system at the expense of readers, who need stamps they can trust? Of course it would be possible to set up a stamping agency that cheerfully passed out stamps to the highest bidder. But then, what exactly would that purchaser be bidding for? As Smith (1999) puts it: “(corrupt) organizations would soon disappear as evaluators would have nothing to sell but their reputation” (84).
Underwriters' Laboratories (UL), an organization that charges manufacturers for product safety certifications, is a good example. Certainly UL are as susceptible to kickbacks as peer review stampers would be. But they have been trusted for over a century because the public knows they have more to lose by being corrupts than by being honest. Who would pay for a certification, once UL had been caught selling them?
It's important to note, though, that assessment services in the DcJ would not need to be commercial. Non-profits or individuals with time and inclination could make their own assessment environments, crawlers, and algorithms, potentially drawing on more trust from their communities. If scholars can do a better job of delivering consistently useful assessment than commercial enterprises, the latter will gradually fade away. The important thing is that everyone be given the opportunity and raw data to build assessment services, without the vast additional infrastructure of publication, marketing, copyediting, and other functions.
Transitional stages: The transition to a decentralized certification marketplace is the most challenging part of the move to a DcJ. Overlay journals are a logical step, although seem to have attracted little enthusiasm outside the narrow open access community. Perhaps better technical tools for managing overlays will change this. Another possibility is to extend overlay journals into areas unserved by their traditional counterparts. One could imagine a journal designed to add peer review to blog posts or research technical reports. Instead of encouraging small communities to create overlays, large publishers might be interested. After all, while they have the most to lose in the DcJ, they also have a lot to gain: their brands continue to carry value whether they operate as overlays or not. A major publisher moving one of its large titles to an overlay model would signal agility and innovation to competitors, subscribers, and authors alike, and allow the publisher to focus on their core product: certification. A third approach would be for post-publication services like F1000 to market their service more aggressively as a stamp that should sit alongside journal publications on a CV—after all, it does represent a review by peers. The biggest and most practical step forward in the short-term is to plant the provocative idea in the heads of publisher, authors, readers, and funders that journals exist mostly to provide certification. What if we let them just do that?
Workflow in the Decoupled Journal
So far, these ideas are relatively abstract. Let's look at three imaginary examples of what scholarly communication might look like with the DcJ. Of course, these are just possibilities; the DcJ is meant to evolve, and one of its strengths is that we cannot predict exactly what it will look like.
Author: ANA
Ana, a biologist, is finishing a study on Florida lizards. As she finishes a rough draft of her paper, she navigates to her institutional repository and saves it. She has a free account with NeoNote, an overlay system that interfaces with her IR to provide an interface for her and her colleagues to annotate and comment on her draft. She has another account with an aggregation service that brings in external comments about her posted papers from twitter or blog posts. She blogs that the draft is up for comment and in a week both services have accumulated some interesting suggestions, criticisms, and annotations, which she works into a revised paper. Based on a commenter's suggestion, she sends this new version to StatStamp, a statistics review service, since she's using some relatively obscure techniques. The service gives her some advice with leads to a few minor changes, and then she's awarded a StatStamp seal of approval. This is recorded in the articles IR metadata, and also on a list of links maintained by StatStamp. She is now happy with the state of the article, so she submits to the most prestigious stamping agency in her field, Lizard Reviews. After a few rounds of reviews and revisions, each of which is published with links to her article, Ana gets her stamp. She's a bit disappointed that it is the “B” stamp instead of the “A” she was hoping for, but it's still a coup. Meanwhile, an argument she had with the reviewers has been picked up by LizardTalk, a conversation aggregator in her field. Several of her colleagues join in, and she meets a researcher from a different field whose expertise in Florida's lizard habitats makes him a perfect collaborator for her next study.
Author: Beatrice
Beatrice is a chemist in the middle of a large study. She has finished data collection, so she has uploaded her dataset to her institution's repository. She also decides to upload a paper explaining her preliminary findings. She pays out of her grant to have the paper's language polished up a bit, since she doesn't have time to write more than a draft. She also pays to have her claims encoded in several scholarly ontologies and attached to the article's metadata, so that machines can crawl, read and understand her conclusions and their warrant. Next week she gets an automated email from ChemCrawler, a bot that crawls chemistry papers. ChemCrawler combined her data with that of a researcher who did a similar study and found that the combined data both clearly disproves one of her claims, and also supports several new ones. She integrates the new data and claims, then decides that, since work is moving quickly in the area, she should publish to a wider audience. Her field's most prestigious stamp takes a while to get, so she submits to the cross-field stamping agency QuikStamp instead. This agency automatically assigns reviewers based on keywords and the author's social network; it also pays fast reviewers a bonus in credits they can use at a consortium of stamping agencies. This means that Beatrice gets her stamp in just a week. QuikStamp certifies thousands of papers every week, so there's little chance that someone will run into it. However, a small fee submits the newly stamped article to a service that pushes it to other scholars who will be most likely to find it valuable, based on their public browsing, download, bookmarking, and commenting profiles.
Reader: Carl
Carl is a medical researcher who reads his articles feed twice a day. In the morning, over coffee, he sets his aggregator to “must read,” which delivers articles that are stamped by the American Medical Association and articles that are being heavily read and recommended by his social networks. In the evening, he switches to “up and coming,” articles that haven't been stamped yet, but that his aggregator predicts will be the focus of conversation in the next few weeks, based on the activity of early adopters in his network, early downloads, and host of other metrics. Over time the algorithm adapts to Carl's preferences using his input and its own prediction record as feedback. Carl typically comments on both stamped and unstamped articles—wherever the conversation looks interesting. Carl enjoys his stature in his small disciplinary community, which converses online the way it used to at conferences—informally, but willing to make strong arguments backed by research. Carl notices that one of his earlier comments has spawned a long and interesting discussion overnight, accumulating good metrics. It will now be automatically added to his CV as evidence of his leadership in the community.
Advantages of the Decoupled Journal
The DcJ has three major advantages over other schemes to reform scholarly publishing.
Can be achieved incrementally: The most important advantage the DcJ has over alternatives is that it can evolve gradually from the current system. Indeed, as we have seen, it is already beginning to do so. Just as in biological evolution, immense changes can occur if each step along the way is viable in its own right. The DcJ ensures this by continuing to fulfill the essential functions of the journal at every step. It never replaces the essential currency of the traditionally peer reviewed paper—it just promotes a system that allows this currency to evolve, giving alternate certification approaches the space to convince conservative decision-makers of their value. The DcJ offers extant publishers a chance to evolve as well, shedding their legacy function as “publishers” (which they do with tremendous inefficiency compared to simple web repositories) and becoming lean, responsive certification providers. Whether they will overcome institutional inertial to succeed in this is an open question; however, if they seize the opportunity, today's publishers' experience and reputations offer them an early lead over startup stamping services. The important thing is the DcJ gives these major stakeholders in scholarly communications something to do besides dig in and fight for their survival. In these ways the DcJ is a model that can be reached via progressive change.
The decoupled journal is a paradigm shift: Although the DcJ is achievable by evolutionary means, its ultimate result is a complete revolution in the scholarly communication system. As Smith (1999) notes of his DJ proposal, the complete unbundling of the journal's function is nothing less than a Kuhnian paradigm shift in the way we communicate science. This is important because such a change is overdue; it is naïve to expect a paradigm built around seventeenth-century technology meet the needs of the Information Age. Attempts to patch pieces of the system in isolation without addressing its fundamental anachronisms will founder. This is what we expect from tightly coupled systems, where change in one function affects all the others.
The DcJ offers a legitimate and fundamentally different alternative to the present system, an alternative rooted in the technologies and ethos of the current age: openness, diversity, connectedness, customization, decentralization, the power of data. It promises a relatively bloodless revolution, in which some of the skills and experience of the current players can be gradually repurposed—but a revolution nonetheless. Nothing less will suffice.
The DcJ is in many ways similar to another well-known decoupled system with modest underpinnings but revolutionary implications, the Web. Both define a set of roles, and responsibilities for each role. Both maintain an effective central registry of IDs. But both systems provide little regulation beyond these minimal requirements. The DcJ, like the Web, embraces a laissez-faire approach to regulation, preferring to give the market the maximum possible space to innovate. This techno-anarchism has been extraordinarily effective in the case of the Web, allowing it to evolve functions far beyond its creators' dreams. This is no surprise, given that a central advantage of decoupling is the ability to freely adapt, modify and even occasionally break individual components without wrecking the system as a whole. There is good reason to suspect that the successful decoupling of the journal would lead to explosive innovation reminiscent of the Web's. The Web was itself invented as a scholarly communication platform (Clarke, 2010); it's time for us to reclaim that legacy.
The decoupled journal empowers innovators: It is worth repeating that the DcJ is not a scheme for reforming peer review, but rather a meta-scheme for creating an market to let peer review—and the journal's other functions—evolve. We believe this is necessary for three reasons. First, there is already no shortage of innovative ideas for the reform of peer review, and the list will continue to grow without our help. Second, and more importantly, these isolated ideas, whatever their merit, will never implemented at large-scale without fundamental change to the entire scholarly communication system. The current tight coupling between the four functions makes it very difficult to change one function without changing the others as well. When all the journal's functions are made available as modular services, though, new certification schemes will be able to clearly articulate value propositions, accurately price services, and realistically assess effectiveness—in short, they can sell themselves. This is a sine qua non for convincing scholars to embrace change in so fundamental an institution. Finally, we suggest that no scheme, no matter how well-conceived, will anticipate all scholars' requirements and concerns. Experience shows that is often better to favor adaptability and responsiveness over comprehensiveness and cleverness. Common sense also suggests that over time, a market that attracts hundreds or thousands of hungry innovators will prove more creative than any single individual. In the four centuries since the Scientific Revolution, we have seen the power of a decentralized, open market for scientific ideas (Franck, 1999). Sadly, our communication tools do share this approach; economist Mark McCabe describes the state of publishing as a “true market failure” (Poynder, 2002). We can fix this, simply by making individual functions available as individual services.
Conclusion
The journal is built around the delivery of ink and paper by horses and boats. Today, we have better ink and faster horses, but no fundamental change. This change, especially in an institution as conservative as the academy, is not easy and takes time. We should not expect a fully decoupled metajournal to emerge in the next year or even decade. However, neither should we expect the current system, based as it is on the paradigm of the seventeenth century, to continue with only small, evolutionary changes. There will be a revolution in scholarly communication, as the fundamental potential of the Web compared with traditional models puts increasing torsion on our system. The revolution will not be in the functions of the journal system, which have proven themselves over centuries, but on the structures of the system we use to perform them.
We suggest that this revolution will result in a more diverse and decentralized metajournal. In this DcJ, authors will publish any sort of product they create. They will adapt their work's form and make it retrievable with the help of external service providers. They will market it over richly connected networks with the help of specialists or without. They will certify it in dozens of ways, using hundreds or thousands of competing stamping and ranking agencies and algorithms. And all this data will be managed, organized, and curated by a set of relevance and ranking tools that will present customized views of the metajournal for scholars, practitioners, and administrators alike.
The most sensible early steps to achieving this vision are for publishers and interested academics to begin selling peer review as a service that can be a one-for-one replacement for journal peer review. If this can be successful, it will establish a precedent for peer review decoupled from the other functions, giving more services of more kinds a chance to enter the market. This in turn will lead to greater awareness of this approach's advantages, gradually encouraging the academy to adopt the DJ.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Allen, L., Jones, C., Dolby, K., Lynn, D., and Walport, M. (2009). Looking for landmarks: the role of expert review and bibliometric analysis in evaluating scientific publication outputs. PLoS One 4:e5910. doi: 10.1371/journal.pone.0005910
Asur, S., and Huberman, B. A. (2010). “Predicting the future with Social Media,” 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology. (Toronto, ON, Canada), 492–499.
Bogers, T., and van den Bosch, A. (2008). “Recommending scientific articles using citeulike,” in Proceedings of the 2008 ACM Conference on Recommender Systems, (New York, NY: ACM), 287–290.
Bollen, J., Mao, H., and Zeng, X. (2011). Twitter mood predicts the stock market. J. Comput. Sci. 2, 1–8.
Bosc, H., and Harnad, S. (2005). In a paperless world a new role for academic libraries: providing open access. Learn. Publ. 18, 95–100.
Brody, T., Harnad, S., and Carr, L. (2006). Earlier Web usage statistics as predictors of later citation impact. J. Am. Soc. Inf. Sci. Technol. 57, 1060–1072.
Brown, J. (2010). An introduction to overlay journals. Repositories Support Project: UK. Retrieved from http://discovery.ucl.ac.uk/19081. (in press).
Buckingham, S. S., Motta, E., and Domingue, J. (2000). ScholOnto: an ontology-based digital library server for research documents and discourse. Int. J. Digit. Libr. 3, 237–248.
Casati, F., Giunchiglia, F., and Marchese, M. (2007). Publish and perish: why the current publication and review model is killing research and wasting your money. Ubiquity 3. doi: 10.1145/1226694.1226695
Cassella, M., and Calvi, L. (2010). New journal models and publishing perspectives in the evolving digital environment. IFLA J. 36, 7–15.
Clarke, M. (2010, January 4). Why hasn't scientific publishing been disrupted already? The Scholarly Kitchen. Retrieved January 30, 2010, from http://scholarlykitchen.sspnet.org/2010/01/04/why-hasnt-scientific-publishing-been-disrupted-already/
Cronin, B. (2001). Bibliometrics and beyond: some thoughts on web-based citation analysis. J. Inf. Sci. 27, 1–7.
Ding, Y., Jacob, E. K., Caverlee, J., Fried, M., and Zhang, Z. (2009). Profiling social networks: a social tagging perspective. D-Lib Magazine, 15, 1082–9873.
Gordon, R., and Poulin, B. J. (2008, October 15). There is but one journal: the scientific literature. Retrieved from http://www.plosmedicine.org/annotation/listThread.action?inReplyTo=info%3Adoi/10.1371/annotation/b70a4689-cf09-4db6-a97b-8608b87e629e&root=info%3Adoi/10.1371/annotation/b70a4689-cf09-4db6-a97b-8608b87e629e
Gotzsche, P. C., Delamothe, T., Godlee, F., and Lundh, A. (2010). Adequacy of authors' replies to criticism raised in electronic letters to the editor: cohort study. Br. Med. J. 341, c3926.
Greaves, S., Scott, J., Clarke, M., Miller, L., Hannay, T., Thomas, A., and Campbell, P. (2006). Nature's trial of open peer review. Nature. 444, 971.
Groth, P., Gibson, A., and Velterop, J. (2010). The anatomy of a nanopublication. Inf. Serv. Use 30, 51–56.
Hemminger, B. (2009). NeoNote: suggestions for a global shared scholarly ecosystem. D-Lib Magazine 15. doi: 10.1045/may2009-hemminger
Henning, V., and Reichelt, J. (2008). “Mendeley – a last.fm for research?” in IEEE Fourth International Conference on eScience (Indianapolis, IN: IEEE) 327–328.
Jefferson, T., Rudin, M., Brodney Folse, S., and Davidoff, F. (2007). Editorial peer review for improving the quality of reports of biomedical studies. Cochrane Database of Systematic Reviews 2007, Issue 2. Art. No.: MR000016.
Kuperberg, G. (2002). Scholarly mathematical communication at a crossroads. Nieuw Archief voor Wiskunde 5, 262–264.
Moyle, M., and Lewis, A. (2008). RIOJA (Repository Interface to Overlaid Journal Archives) project: final report. Retrieved from http://discovery.ucl.ac.uk/12562/.
Peters, D. P., and Ceci, S. J. (1982). Peer-review practices of psychological journals: the fate of published articles, submitted again. Behav. Brain Sci. 5, 187–195.
Poynder, R. (2011, March 7). PLoS ONE, open access, and the future of scholarly publishing. Open and Shut? Retrieved March 17, 2011, from http://poynder.blogspot.com/2011/03/plos-one-open-access-and-future-of.html
Poynder, R. (2002). A true market failure. Inf. Today 19. Retrieved from http://www.infotoday.com/it/dec02/poynder.htm
Priem, J., and Costello, K. L. (2010). “How and why scholars cite on Twitter,” in Proceedings of the 73rd ASIS&T Annual Meeting. Presented at the American Society for Information Science and Technology Annual Meeting, (Pittsburgh, PA).
Rodriguez, M. A., Bollen, J., and van de Sompel, H. (2006). The convergence of digital libraries and the peer-review process. J. Inf. Sci. 32, 149–159.
Roosendaal, H., and Geurts, P. (1997). Forces and functions in scientific communication: an analysis of their interplay. Cooperative Research Information Systems in Physics, August 31-September 4 1997. (Oldenburg, Germany). Retrieved from http://www.physik.uni-oldenburg.de/conferences/crisp97/roosendaal.html
Schriger, D. L., Chehrazi, A. C., Merchant, R. M., and Altman, D. G. (2011). Use of the Internet by print medical journals in 2003 to 2009: a longitudinal observational study. Ann. Emerg. Med. 57, 153–160. e3.
Smith, J. (1999). The deconstructed journal: a new model for academic publishing. Learn. Publ. 12, 79–91.
Smith, J. W. T. (2003). “The deconstructed journal revisited: a review of developments,” in Proceedings. Presented at the ICCC/IFIP Conference on Electronic Publishing-ElPub03: From information to knowledge. (Minho, Portugal). 2–88.
de Solla Price, D. J., and Beaver, D. (1966). Collaboration in an invisible college. Am. Psychol. 21, 1011.
Stevens, W. P., Myers, G. J., and Constantine, L. L. (1974). Structured design. IBM Syst. J. 13, 115–139.
Tenopir, C., and King, D. W. (2008). Electronic journals and changes in scholarly article seeking and reading patterns. D-Lib Magazine 14. doi: 10.1045/november2008-tenopir
Thelwall, M., and Harries, G. (2004). Do the Web sites of higher rated scholars have significantly more online impact? J. Am. Soc. Inf. Sci. Technol. 55, 149–159.
van de Sompel, H. (2000). “Closing keynote address,” in Presented at the Coalition for Networked Information Meeting, San Antonio, Texas, USA. Retrieved from http://www.slideshare.net/hvdsomp/the-roof-is-on-fire
van de Sompel, H., Payette, S., Erickson, J., Lagoze, C., and Warner, S. (2004). Rethinking scholarly communication. D-Lib Magazine 10, 1082–9873.
Wager, L. (2011, March 22). Journals that dare not speak their name. BMJ Group Blogs. Retrieved May 17, 2011, from http://blogs.bmj.com/bmj/2011/03/22/liz-wager-journals-that-dare-not-speak-their-name/
Ware, M., and Mabe, M. (2009). The STM Report: an Overview of Scientific and Scholarly Journal Publishing. Oxford: STM: International Association of Scientific, Technical and Medical Publishers.
Wenneras, C., and Wold, A. (2008). “Nepotism and sexism in peer-review,” in Women, Science, and Technology: a reader in feminist science studies, ed M. Wyer (New York, NY: Taylor & Francis) 46–52.
Willinsky, J. (2003). Scholarly associations and the economic viability of open access publishing. J. Digit. Inf. 4. Available at: https://wwws.tdl.org/jodi/article/view/104
Keywords: scholarly communication, peer review, publishing, models
Citation: Priem J and Hemminger BM (2012) Decoupling the scholarly journal. Front. Comput. Neurosci. 6:19. doi: 10.3389/fncom.2012.00019
Received: 12 August 2011; Paper pending published: 11 November 2011;
Accepted: 16 March 2012; Published online: 05 April 2012.
Edited by:
Nikolaus Kriegeskorte, Medical Research Council Cognition and Brain Sciences Unit, UKReviewed by:
Thomas Boraud, Universite de Bordeaux, FranceNikolaus Kriegeskorte, Medical Research Council Cognition and Brain Sciences Unit, UK
Copyright: © 2012 Priem and Hemminger. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits noncommercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Jason Priem, School of Information and Library Science, University of North Carolina at Chapel Hill, 100 Manning Hall, Chapel Hill, NC 27599-3360, USA. e-mail: priem@email.unc.edu