Aggregating post-publication peer reviews and ratings
- 1Romanian Institute of Science and Technology, Cluj-Napoca, Romania
- 2Epistemio Ltd., London, UK
- 3Epistemio Systems SRL, Cluj-Napoca, Romania
Allocating funding for research often entails the review of the publications authored by a scientist or a group of scientists. For practical reasons, in many cases this review cannot be performed by a sufficient number of specialists in the core domain of the reviewed publications. In the meanwhile, each scientist reads thoroughly, on average, about 88 scientific articles per year, and the evaluative information that scientists can provide about these articles is currently lost. I suggest that aggregating in an online database reviews or ratings on the publications that scientists read anyhow can provide important information that can revolutionize the evaluation processes that support funding decisions. I also suggest that such aggregation of reviews can be encouraged by a system that would provide a publicly available review portfolio for each scientist, without prejudicing the anonymity of reviews. I provide some quantitative estimates on the number and distribution of reviews and ratings that can be obtained.
Introduction
There is an increasing awareness of the problems of the current scientific publication system, which is based on an outdated paradigm, resulted from the constraints of physical space in printed journals, and which largely ignores the possibilities opened by current internet technologies. There also is an increasing interest in alternatives to this paradigm (Greenbaum et al., 2003; Van de Sompel et al., 2004; Rodriguez et al., 2006; Carmi and Coch, 2007; Easton, 2007; Kriegeskorte, 2009; Chang and Aernoudts, 2010). Several papers within this journal's Research Topic on Beyond open access present convincingly a vision of a future where the scientific journal's functions are decoupled and/or the pre-publication reviews by about two or three reviewers is replaced or complemented by an ongoing post-publication process of transparent peer review and rating of papers (Kravitz and Baker, 2011; Lee, 2011; Ghosh et al., 2012; Priem and Hemminger, 2012; Sandewall, 2012; Wicherts et al., 2012; Zimmermann et al., 2012). This could ensure a better assessment of the validity of the information provided in a scientific publication, which would help those that intend to use that information in their research or in applications.
Peer review supports not just the scientific publication system, but also the allocation of funding to scientists and their institutions. Just as an open post-publication peer review process can revolutionize scientific publication, it can also revolutionize the evaluation procedures that support funding decisions. I will argue here that aggregating post-publication peer reviews is a better alternative to organizing dedicated review committees and I will suggest some mechanisms to motivate the aggregation of such peer reviews.
Peer Review for Funding Decisions
Funding decisions include: funding research projects through grants; allocating funding to a research group or an institution; and hiring or granting tenure. These decisions are typically based, in a significant measure, on a review by a committee of the previous results of a scientist or of a group of scientists, and in many cases these results are scientific publications.
In many cases, because of practical issues, the review committee does not include specialists in the core area of expertise of the assessed scientists. Such practical issues include:
- selecting reviewers from in-house databases that are not comprehensive or up-to-date, which limits the range of potential reviewers to those in the database;
- selecting reviewers using software that matches them to assessed scientists using keywords or matching between broad domains, a method that can lead to imprecise results; better results could be obtained if matching would be based on co-authorship networks (Rodriguez and Bollen, 2008) or co-citation networks;
- the lack of time or other reasons for the unavailability of selected reviewers, especially when the type of review requires a trip or other significant time investment from the reviewers.
Because of the increased specialization of modern science, this can prevent a thorough understanding by the reviewer of the assessed scientist's publications. In other cases, the reviewers simply do not have the time to thoroughly read and properly assess these publications. These situations may lead the reviewers to rely on indirect, more imprecise indicators of the publication's quality, such as the impact factor of the journal where it was published, its number of citations or other such metrics, instead of the publication's content, as they should do, and thus may lead to a higher subjectivity of the review.
For example, the Research Assessment Exercise (RAE) has been used in the UK for allocating funding to universities, of about £1.5 billion per year (HEFCE, 2009). A key part of the exercise was the peer review of outputs, typically publications, submitted by universities. Universities were allowed to submit up to four output items per each of the selected university staff members. About 1400 members of the RAE review panels reviewed 214,287 outputs1, i.e., on average there were about 150 outputs per reviewer. This large number of outputs that a reviewer had to assess means that only few of them were thoroughly reviewed.
Even minor improvements in evaluation of science, that would improve the efficiency of the allocation of research funding, would translate in huge efficiency increases, as the global research and development spending is about 1143 billion US dollars annually (Advantage Business Media, 2009). For example, a 1% relative improvement would lead to worldwide efficiency increases of about 11 billion dollars annually.
Aggregating Post-Publication Peer Reviews and Ratings
An alternative to reviewing publications independently for each funding allocation decision is centralizing and aggregating reviews or ratings from each scientist who reads the papers for her own needs. Internet technologies make quite simple to implement a system where reviews or ratings collected through one or multiple websites or mobile applications are centralized in a single database. Encouraging a simple procedure, that a scientist goes to a website or opens a mobile app and spends several minutes logging there her rating or review information on each new publication that she reads, would provide a much more precise and relevant review information than most of the currently available processes. In many cases, this would entail just collecting existing information, the evaluative valences of which are otherwise wasted for the society.
Scientists spend anyhow a large percentage of their time reading scientific publications—the results of two studies point to 6% or, respectively, 38% of the work time as being spent reading, on average (Tenopir et al., 2009, 2011), assuming a 45 h work week (Table 1). A questionnaire performed on US university staff in 2005 has shown that a scientist reads, on average, 204 unique articles per year, for a total of 280 readings. The average reading time was 31 min (Tenopir et al., 2009). Forty-three percent of these readings (i.e., about 88 unique articles per year) were read “with great care” and 51% were read “with attention to the main points” (Tenopir et al., 2009) (see also Table 2). While reading a paper, scientists form an opinion about its quality and relevance, and this opinion could be collected by an online service as a rating of the paper. Across the world, journal clubs are organized periodically in most universities and research institutes, where scientists discuss new publications. Again, the results of these discussions could be collected by an online service, as reviews of those publications.
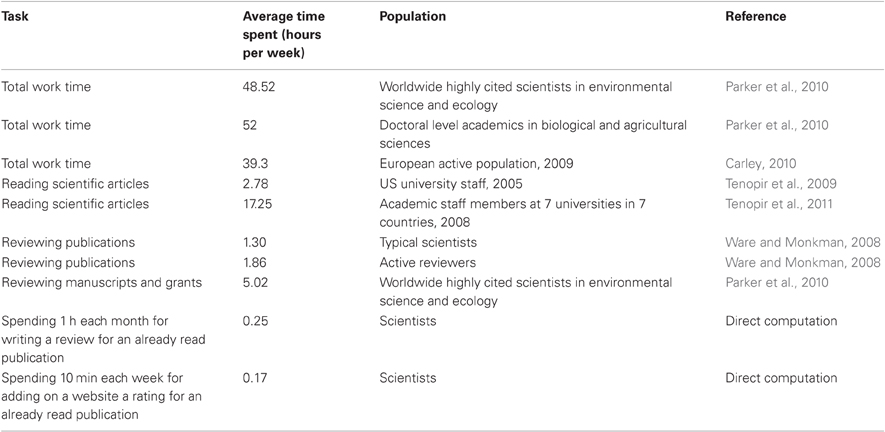
Table 1. Total work time and time spent on various tasks.
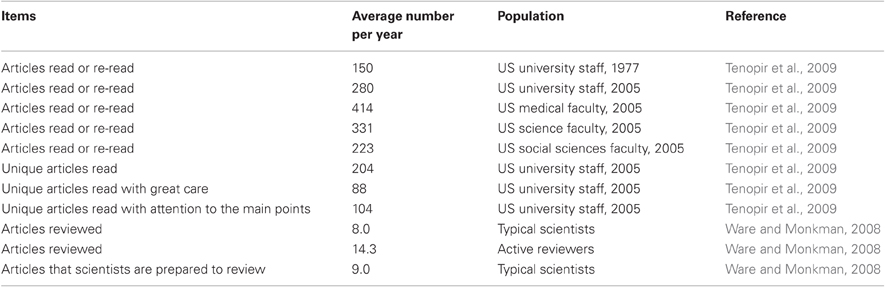
Table 2. The average number per year of readings, reviews and related activities that a scientist performs.
There is a quite large gap between the average number of articles that a scientist reads with great care (88 per year) (Tenopir et al., 2009) and the average number of articles that a scientist reviews (8 per year) (Ware and Monkman, 2008). Review information on the about 80 articles per scientist per year that were not specifically read for review is currently lost.
The people that would provide these ratings and reviews are typically specialists in the core field of the publications they review, unlike many of the reviewers in committees formed for decision making. If this information would be aggregated globally, from all scientists in the world who read a particular publication, the accuracy and relevance of the review information would be much higher than the one available through classical means.
This review information might be similar in scope to the one provided in typical pre-publication reviews. However, brief reviews or just ratings of the scientific articles on a few dimensions would also be informative when many of them (e.g., 10 or more) would be aggregated. As I discuss below, we can expect that only a fraction of publications will get, e.g., three or more reviews or 10 or more ratings.
The content of the reviews would be made public. Reviews could be rated themselves, and this would provide information from scientists that do not have the time to write the reviews themselves but just to express their agreement or disagreement with existing reviews. The rating of reviews would also encourage their authors to pay attention to the quality of these reviews (Wicherts et al., 2012).
Although the reviews or ratings could be kept anonymous for the public if their authors desire it, the identity of the reviewers should be checked by the providers of the proposed system in order to ensure the relevance of the aggregated information. The relevance of the reviews and ratings could be weighted by the scientific prestige of their authors and by the fit between the reviewer's and the reviewed paper's fields. This scientific prestige could be assessed initially using classical scientometric indicators, but once reviews and ratings would start being aggregated these would be used increasingly for assessing scientific prestige. Synthetic indicators of scientific prestige built upon the aggregated review information should take into account differences between different fields of research in publication frequency and impact. These synthetic indicators should also be presented with error bars/confidence intervals (Kriegeskorte, 2009) or as distributions and not only just as unique numerical values, like current scientometric indicators are typically presented.
One problem that is often mentioned about the present system of pre-publication review is the issue of political reviewing—unjustified negative reviews of papers of direct competitors or of scientists supporting competing views (Smith, 2006; Benos et al., 2007). Because the pre-publication review typically leads to a binary decision (accept or reject the publication), one negative, unjust review by a competitor can lead to a negative outcome even if other reviews are positive. Since the proposed system would also consider and display the distribution of reviews/ratings, a paper that is highly acclaimed by a significant percentage of reviewers could be considered as an interesting one even if another significant percentage of reviewers consider it in a negative way. Automated mechanisms could easily be developed to distinguish between unimodal and bimodal distributions of ratings. Simple checks based on coauthorship information or institutional affiliations and more complex checks based on the detection of citation circles or reciprocal reviewing could also filter out other more general conflicts of interest (Aleman-Meza et al., 2006).
Enabling the collection of reviews and ratings through mobile applications is important, since only 64.7% of article readings happen in the office or lab, while 25.7% happen at home and 4.1% while traveling, on average (Tenopir et al., 2009).
The Current Status of Review Aggregation
There were many attempts to collect post-publication review information, but, to date, despite the enthusiasm for the concept, the number of reviews provided through the available channels is deceptively low. For example, the prestigious journal Nature launched a trial of open peer review, which proved to be not widely popular, either among authors or by scientists invited to comment (Greaves et al., 2006). Some of the causes of this outcome could have been corrected, however (Pöschl, 2010). PLoS ONE2 peer reviews submissions on the basis of scientific rigor, leaving the assessment of the value or significance of any particular article to the post-publication phase (Patterson, 2010). So far, the usage of the commentary tools of PLoS ONE is fairly modest and does not make a major contribution to the assessment of research content (Public Library of Science, 2011). Innovative journals such as Philica3 or WebMedCentral4 that aim to provide only post-publication review for the papers that they publish suffer from a lack of reviews and are overwhelmed by low quality papers. Faculty of 10005 organizes the review of about 1500 articles monthly, corresponding to approximately the top 2% of all published articles in the biology and medical sciences6, but this covers just a few scientific areas, a small fraction of the publications within these areas, and accepts reviews from a limited pool of scientists only. The Electronic Transactions on Artificial Intelligence7, which combined open post-publication review with a traditional accept/reject decision by editor-appointed reviewers, seems to be an example of moderate success (Sandewall, 2012), but is, however, currently closed. The Atmospheric Chemistry and Physics8 journal and its sister journals of the European Geosciences Union and Copernicus Publications, which use an interactive open access peer review, also are examples of moderate success, but only about 25% of the papers receive a comment from the scientific community in addition to the comments from designated reviewers, for a total average of about 4–5 interactive comments (Pöschl, 2010).
All these show that the existing mechanisms and incentives are not sufficient to encourage scientists to contribute a significant number of reviews.
Scientists are quite busy and work long hours, the work time being about 30% higher that the average one of the general population (Table 1). Over the last few decades, as the number of scientific publications and their accessibility has grown, the average number of articles read by scientists has increased from 150 per year in 1977 to 280 per year in 2005. However, the average time spent reading a paper has decreased from 48 to 31 min, suggesting that the amount of time available for reading scientific articles is likely reaching a maximum capacity (Tenopir et al., 2009).
The highly cited scientists in environmental science and ecology spend, on average, more than 10% of their work time reviewing manuscripts and grants (Parker et al., 2010). Typical scientists review, on average, 8.0 papers per year, which takes, on average, 8.5 h per paper (median 5 h) (Ware and Monkman, 2008). Active reviewers review, on average, 14.3 papers per year, for 6.8 h per paper (Ware and Monkman, 2008) (see also Tables 1 and 2). The average number of papers per year that scientists are prepared to review is 9.0, i.e., slightly higher than the 8.0 papers they actually review, however, the active reviewers are overloaded (Ware and Monkman, 2008). The lack of time is a major factor determining the decision to decline to review a paper (Table 3).

Table 3. Most important factors in the decision to decline to review a paper.
All these suggest that it is not realistic to expect that scientists can spend significantly more of their time reading new articles just for the purpose of providing reviews for them, unless there would be some strong incentives for doing so. However, logging on a website review or rating information for some of the articles that they have already read would not be a significant burden, as estimated below.
In a survey (Schroter et al., 2010), 48% of scientists said their institution or managers encouraged them to take part in science grant review, yet only 14% said their institution or managers knew how much time they spent reviewing and 31% knew what funding organizations they reviewed for. A total of 32% were expected to review grants in their own time (out of office hours) and only 7% were given protected time to conduct grant review. A total of 74% did not receive any academic recognition for conducting grant review (Schroter et al., 2010). This suggests that, currently, institutions do not reward sufficiently the scientists' review activities.
Previous Suggestions for Encouraging the Aggregation of Reviews
Several surveys asked reviewers about their motivation to review and the factors that would make them more likely to review. The main motivations for reviewing are: playing one's part as a member of the academic community; enjoying being able to help improve the paper; enjoying seeing new work ahead of publication; reciprocating the benefit gained when others review your papers (Ware and Monkman, 2008; Sense About Science, 2009). The incentives that would best encourage reviewers to accept requests to review are presented in Table 4.

Table 4. The most important factors that would encourage scientists to review papers.
A potential reviewer's decision to spend time reviewing an article, which yields an information that is a public good, as opposed to the alternative of spending time in a way that is more directly beneficial to the reviewer, can be construed as a social dilemma. Northcraft and Tenbrunsel (2011) argue that reviewers' cooperation in this social dilemma depends on the costs and the benefits as personally perceived by the reviewers. This personal perception may be influenced by the frame reviewers bring to the decision to review. Frames may lead reviewing to be viewed as an in-role duty or an extra-role choice, and may lead reviewers to focus only on consequences to the self or consequences to others as well (Northcraft and Tenbrunsel, 2011). This theoretical framework allowed Northcraft and Tebrunsel to suggest several methods for improving cooperation within this social dilemma, among which are:
- institutions that employ the reviewers should encourage the perspective that reviewing is an in-role duty, by recognizing and rewarding reviewing in evaluations of reviewers' professional activity;
- creating a public database of reviewers, which would increase reviewer accountability by communicating publicly who is and who is not reviewing, and thus decreasing the probability of undetected free riding.
Another suggestion to discourage free riding in the reviewer social dilemma was to establish a credit system to be used by all journals, where a scientist's account would be credited for his/her reviews and debited when he/she submits a paper for review (Fox and Petchey, 2010).
Other suggestions include considering reviews as citable publications in their own right, which will motivate reviewers in terms of quality and quantity (Kriegeskorte, 2009).
Another option would be to simply eliminate the dilemma, by considering that reviewers should read and review only papers that are of direct interest to them to read, and by considering that the papers that are not read and reviewed are simply not worthy of attention and presumably of low quality (Lee, 2011).
Motivating the Aggregation of Reviews and Ratings
I propose a simple system that aims to motivate the aggregation of reviews and ratings by reinforcing the in-role duty of the reviewers, by recognizing publicly that by reviewing they play their part as a member of the academic community, and by facilitating the reward by their institutions of their review and rating activities. Critically, this system would do this without prejudicing the anonymity of reviews, an issue that reviewers are quite keen about (Sense About Science, 2009).
The proposed system will build a review and rating portfolio for each scientist, which would be publicly available, similar to the publication or citation portfolios of scientists, which are currently used to reward them. The system would need a mechanism for uniquely identifying scientists, which hopefully will be provided soon by the Open Researcher and Contributor ID (ORCID)9. Each journal or grant giving agency, once authenticated, will be able to register to the system the identity of the reviewers that helped them and, possibly, to rate the reviewer's contribution. This information provided by the journals or the agencies, i.e., a quantity representing the extent of the reviewer's contribution and another quantity representing the quality of the reviewer's contribution, will be made public after a random timing. This random timing will be chosen such that it will not be possible for the public, including the reviewed scientists, to associate the change of the reviewer's public information to the actual review, and thus to establish the identity of the reviewers who performed a given review. The anonymity of reviews will thus be respected.
Once there will be a system that will provide this kind of information, in a certified manner (with the contribution of journals and funding agencies), it will be easier for institutions to reward reviewing. As presented above, institutions do not reward sufficiently the in-role duty of scientists to review. A possible cause for this is the lack of easy access to information about a scientist's contribution to peer review, certified by a third party other than the scientist. The proposed system will provide this information, thus facilitating institutions to reward reviews and, finally, contributing to a higher participation of scientists to peer review.
This system can be then extended to account not only for pre-publication reviews and the review of grant applications, but also for post-publication reviews and ratings. For ratings, the portfolio would include their number. Public reviews, such as post-publication reviews, could be rated themselves by others, and thus public information on the review quality of a particular scientist could be made available (Wicherts et al., 2012). Highly rated reviews could then be published as independent publications. Such a system is currently being developed by Epistemio10.
However, it is likely that scientists will not spend time reading papers that would not interest them. A large proportion of scientific publications is not cited and probably not read by scientists other than the authors and the reviewers involved in the publication, and thus, there will always be a significant percentage of papers that would not attract post-publication peer reviews. Scientists prefer reading papers written by an author they recognize as a top scholar and published in a top-tier peer-reviewed journal (Tenopir et al., 2010). Thus, it would be a challenge for young or emerging authors publishing in middle- or low-tier journals to attract the attention of relevant reviewers, even in the case that their results are important. If post-publication peer review will gain importance in supporting funding decisions or as a complement or replacement of pre-publication peer review, then the interested parties will have the option of offering incentives, including direct payment, to competent reviewers to spend their time reading and reviewing articles that did not attract initially the attention of other scientists. If the quality of these papers will be mostly low and the process will ensure the independence and the competence of reviewers, then the result of the process will reflect this quality. However, there are chances that this process would sort out a small proportion of important papers within the ones that did not attract attention initially, and this would motivate the process.
Estimating the Distribution of the Number of Post-Publication Reviews Per Article
Throughout this section, we consider that review means either a proper review or a rating, where not distinguished explicitly. Let's consider that the population of scientists who write papers is identical to the population of scientists who read scientific papers, and this population consists of N scientists. Let's consider that each of the scientists writes, on average, two full articles per year, where a scientist's contribution to a multi-author paper is accounted for fractionally (Tenopir and King, 1997). This means that all scientists write 2 N articles per year. If a scientist reads with great care about 88 unique articles per year, on average (Tenopir et al., 2009), this means that, if all scientists would log reviews for all these articles read with great care, there would be 88 N reviews per year. This leads to an average of about 88 N/2 N = 44 aggregated reviews per article. In practice, a fraction of scientists would log reviews for a fraction of the articles they read, and the average number or reviews per article will be lower than 44.
Scientometric distributions are much skewed: few articles attract a lot of attention and most of the articles attract little attention, and thus, the actual number of reviews per article will be in many cases far from the average. Let's assume that the number of reviews that an article attracts is proportional to the number of citations it attracts. A previous study has found that the dependence on the number of citations c of the number of articles that are cited c times can be fitted well, except for large numbers of citations, by a stretched exponential (Redner, 1998). For the general scientific literature, this exponential coefficient was β = 0.44. I will use here a simple model where I consider a continuous probability density p(x) for the number x of reviews that an article has. I consider that this probability density is such a stretched exponential,
where Γ is the Gamma function and a is a positive parameter. The form of p is chosen such that the average number of reviews per article is a,
For an integer number of reviews n, the fraction of the articles having n reviews can be approximated as
Figure 1 shows the fraction of the articles that get given numbers of reviews, as a function of the average number or reviews per article a, under this model.
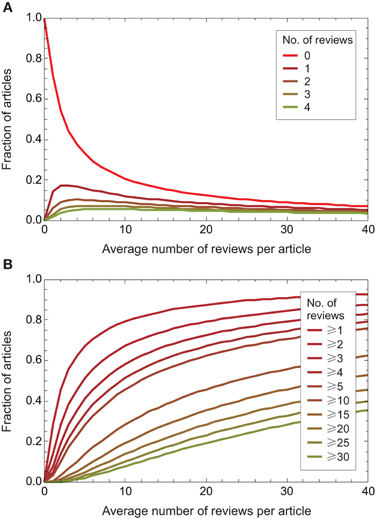
Figure 1. The fraction of articles having a given numbers of reviews, as a function of the average number of reviews per article a. (A) Fraction of articles having a particular number of reviews. (B) Fraction of articles having at least some particular number of reviews.
Under a moderately optimistic example, let's assume that each scientist logs, on average, one proper review monthly and one rating weekly. Thus, there would be 12 N/2 N = 6 proper reviews per article, on average, and 52 N/2 N = 26 ratings per article, on average. The distribution of the number of proper reviews and ratings per article is presented in Table 5. Forty-six percent of the articles would get three or more proper reviews, and 52% of the articles would get 10 or more ratings, thus receiving enough evaluative information for a proper assessment of the article's relevance.
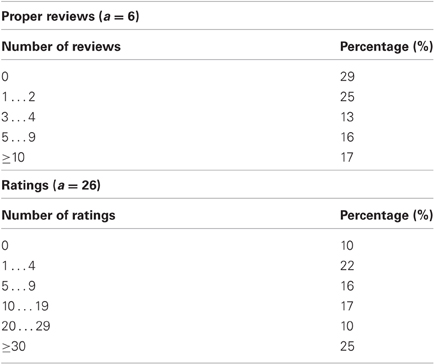
Table 5. An estimated distribution of the number of proper reviews and ratings per article, assuming that each scientist logs, on average, one proper review monthly and one rating weekly.
Estimating the Additional Time Burden on Scientists of Post-Publication Reviews
As mentioned above, currently a pre-publication review for a paper takes, on average, 8.5 h (median 5 h) for a typical scientist, and 6.8 h for an active reviewer (Ware and Monkman, 2008). This probably includes the time needed for reading the paper, reading additional relevant papers cited in the reviewed paper, and actually conceiving and writing the review.
We focused here on the aggregation of reviews and ratings of publications that are read anyhow by the scientists, so the time needed for reading the reviewed publications is not an additional burden in our case. It is also possible that in many cases reviewers for papers currently submitted for publication receive and accept for review papers that are not in their core field of research, hence the possible need for an extra documentation requiring reading some of the publications cited in the reviewed paper. As already mentioned above, the lack of expertise in the paper's domain is an often mentioned reason for refusing a review (Lu, 2008; Sense About Science, 2009), which means that receiving for review papers that are not in the reviewer's core field of research is common. In the case of reviews of papers that scientists read anyhow, these papers are guaranteed to be from their core field, and thus, reading extra publications cited in the reviewed papers is not an additional burden.
Thus, the time needed for reading the actual paper and any additional papers must be subtracted from the current duration of pre-publication reviews in order to estimate the time spent for just conceiving and writing a review. The average reading time for an article is 31 min (Tenopir et al., 2009), but this averages the time spent for reading articles with various degrees of attention. Thus, we would expect that the time reading an article with great care is somehow larger than 31 min, on average. After subtracting the time needed for reading the papers, a reasonable estimate of the time spent for just conceiving and writing a proper review for an already read paper is of about 1 h.
The time needed to access a website or a mobile app, search for the publication that has just been read and add ratings on a few dimensions can also be reasonably estimated to about 10 min.
The additional time burden resulted from these estimates, for logging, on average, one proper review monthly, and one rating weekly, is presented in Table 2 together with the time burden of other activities and appears to be small.
This extra work will be later compensated by less time spent on searching for relevant information, when review information will be available to filter articles of interest. In the cases where post-publication peer review will replace the pre-publication peer review, there would be no extra work at all.
Conclusions
I have argued that the aggregation of post-publication peer reviews and ratings can play an important role for revolutionizing not only scientific publication, but also the evaluation procedures that support funding decisions. I have presented some suggestions for motivating scientists to log such reviews or ratings. I have also estimated quantitatively the maximum average number of reviews/ratings and the distribution of the number of reviews/ratings that articles are expected to receive if reviews/ratings for some of the articles that scientists read thoroughly are logged online and centralized in a database.
The internet has revolutionized many aspects of economy and society, such as communication, press, travel, music, and retail. Although the scientific enterprise is centered around information, it resisted to date to a significant embrace of the possibilities of online collaboration and information sharing offered by the internet. Besides moving the publications from print to web and allowing an easier access to publications, the advent of the internet has not changed much the scientific enterprise. A centralized aggregation of reviews and ratings of scientific publications can provide better means to evaluate scientists, thus allowing improved efficiencies in allocating research funding and accelerating the scientific process.
Conflict of Interest Statement
The author has financial interests in the Epistemio group of companies, which aim to provide commercial services related to aggregation of post-publication peer reviews and ratings.
Footnotes
References
Aleman-Meza, B., Nagarajan, M., Ramakrishnan, C., Ding, L., Kolari, P., Sheth, A., Arpinar, I., Joshi, A., and Finin, T. (2006). “Semantic analytics on social networks: experiences in addressing the problem of conflict of interest detection,” in Proceedings of the 15th International Conference on World Wide Web (New York, NY: ACM), 407–416.
Benos, D. J., Bashari, E., Chaves, J. M., Gaggar, A., Kapoor, N., LaFrance, M., Mans, R., Mayhew, D., McGowan, S., Polter, A., Qadri, Y., Sarfare, S., Schultz, K., Splittgerber, R., Stephenson, J., Tower, C., Walton, R. G., and Zotov, A. (2007). The ups and downs of peer review. Adv. Physiol. Educ. 31, 145–152.
Carley, M. (2010). Working time developments – 2009. Available from http://www.eurofound.europa.eu/eiro/studies/tn1004039s/tn1004039s.htm
Chang, C.-M., and Aernoudts, R. H. R. M. (2010). Towards scholarly communication 2.0, peer-to-peer review and ranking in open access preprint repositories. Available from SSRN: http://ssrn.com/abstract=1681478
Easton, G. (2007). Liberating the markets for journal publications: some specific options. J. Manage. Stud. 44, 4.
Fox, J., and Petchey, O. (2010). Pubcreds: fixing the peer review process by “privatizing” the reviewer commons. Bull. Ecol. Soc. Am. 91, 325–333.
Ghosh, S. S., Klein, A., Avants, B., and Millman, K. J. (2012). Learning from open source software projects to improve scientific review. Front. Comput. Neurosci. 6:18. doi: 10.3389/fncom.2012.00018
Greaves, S., Scott, J., Clarke, M., Miller, L., Hannay, T., Thomas, A., and Campbell, P. (2006). Nature's trial of open peer review. Nature. doi: 10.1038/nature05535
Greenbaum, D., Lim, J., and Gerstein, M. (2003). An analysis of the present system of scientific publishing: what's wrong and where to go from here. Interdiscipl. Sci. Rev. 28, 293–302.
HEFCE (2009). Research excellence framework: second consultation on the assessment and funding of research. Available from http://www.hefce.ac.uk/pubs/hefce/2009/09_38/09_38.pdf
Kravitz, D., and Baker, C. I. (2011). Toward a new model of scientific publishing: discussion and a proposal. Front. Comput. Neurosci. 5:55. doi: 10.3389/fncom.2011.00055
Kriegeskorte, N. (2009). The future of scientific publishing: ideas for an open, transparent, independent system. Available from http://futureofscipub.wordpress.com
Lee, C. (2011). Open peer review by a selected-papers network. Front. Comput. Neurosci. 6:1. doi: 10.3389/fncom.2012.00001
Lu, Y. (2008). Peer review and its contribution to manuscript quality: an Australian perspective. Learn. Publ. 21, 307–318.
Northcraft, G. B., and Tenbrunsel, A. E. (2011). Effective matrices, decision frames, and cooperation in volunteer dilemmas: a theoretical perspective on academic peer review. Organ. Sci. 22, 1277–1285.
Parker, J. N., Lortie, C., and Allesina, S. (2010). Characterizing a scientific elite: the social characteristics of the most highly cited scientists in environmental science and ecology. Scientometrics 85, 129–143.
Patterson, M. (2010). PLoS ONE: Editors, contents and goals. Available from http://blogs.plos.org/plos/2010/05/plos-one-editors-contents-and-goals
Priem, J., and Hemminger, B. H. (2012). Decoupling the scholarly journal. Front. Comput. Neurosci. 6:19. doi: 10.3389/fncom.2012.00019
Public Library of Science (2011). “Peer review—optimizing practices for online scholarly communication,” in Peer Review in Scientific Publications, Eighth Report of Session 2010–2012, Vol. I: Report, Together with Formal, Minutes, Oral and Written Evidence, eds House of Commons Science and Technology Committee (London: The Stationery Office Limited), Ev 77–Ev 81.
Pöschl, U. (2010). Interactive open access publishing and peer review: the effectiveness and perspectives of transparency and self-regulation in scientific communication and evaluation. Liber Q. 19, 293–314.
Redner, S. (1998). How popular is your paper? An empirical study of the citation distribution. Eur. Phys. J. B 4, 131–138.
Rodriguez, M., and Bollen, J. (2008). “An algorithm to determine peer-reviewers,” in Proceeding of the 17th ACM Conference on Information and Knowledge Management (New York, NY: ACM), 319–328.
Rodriguez, M. A., Bollen, J., and Van de Sompel, H. (2006). The convergence of digital libraries and the peer-review process. J. Inf. Sci. 32, 149–159.
Sandewall, E. (2012). Maintaining live discussion in two-stage open peer review. Front. Comput. Neurosci. 6:9. doi: 10.3389/fncom.2012.00009
Schroter, S., Groves, T., and Højgaard, L. (2010). Surveys of current status in biomedical science grant review: funding organisations' and grant reviewers' perspectives. BMC Med. 8, 62.
Sense About Science (2009). Peer review survey 2009. Available from http://www.senseaboutscience.org/pages/peer-review-survey-2009.html
Smith, R. (2006). Peer review: a flawed process at the heart of science and journals. J. R. Soc. Med. 99, 178–182.
Tenopir, C., Allard, S., Bates, B., Levine, K. J., King, D. W., Birch, B., Mays, R., and Caldwell, C. (2010). Research publication characteristics and their relative values: a report for the publishing research consortium. Available from http://www.publishingresearch.org.uk/documents/PRCReportTenopiretalJan2011.pdf
Tenopir, C., and King, D. W. (1997). Trends in scientific scholarly journal publishing in the United States. J. Sch. Publ. 28, 135–170.
Tenopir, C., King, D., Edwards, S., and Wu, L. (2009). “Electronic journals and changes in scholarly article seeking and reading patterns,” in Aslib Proceedings: New Information Perspectives, Vol. 61, (Bingley, UK: Emerald Group Publishing Limited), 5–32.
Tenopir, C., Mays, R., and Wu, L. (2011). Journal article growth and reading patterns. New Rev. Inf. Netw. 16, 4–22.
Tite, L., and Schroter, S. (2007). Why do peer reviewers decline to review? A survey. J. Epidemiol. Community Health 61, 9–12.
Van de Sompel, H., Erickson, J., Payette, S., Lagoze, C., and Warner, S. (2004). Rethinking scholarly communication: building the system that scholars deserve. D-Lib Magazine 10, 9.
Ware, M., and Monkman, M. (2008). Peer review in scholarly journals: perspective of the scholarly community – an international study. Available from http://www.publishingresearch.net/documents/PeerReviewFullPRCReport-final.pdf
Wicherts, J. M., Kievit, R. A., Bakker, M., and Borsboom, D. (2012). Letting the daylight in: reviewing the reviewers and other ways to maximize transparency in science. Front. Comput. Neurosci. 6:20. doi: 10.3389/fncom.2012.00020
Keywords: peer review, post-publication peer review, scientific evaluation
Citation: Florian RV (2012) Aggregating post-publication peer reviews and ratings. Front. Comput. Neurosci. 6:31. doi: 10.3389/fncom.2012.00031
Received: 16 February 2012; Paper pending published: 07 March 2012;
Accepted: 07 May 2012; Published online: 22 May 2012.
Edited by:
Diana Deca, Technical University Munich, GermanyReviewed by:
Dietrich S. Schwarzkopf, Wellcome Trust Centre for Neuroimaging at UCL, UKDwight Kravitz, National Institutes of Health, USA
Copyright: © 2012 Florian. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Răzvan V. Florian, Romanian Institute of Science and Technology, Str. Cireşilor nr. 29, 400487 Cluj-Napoca, Romania. e-mail: florian@rist.ro