Efficient coding of spectrotemporal binaural sounds leads to emergence of the auditory space representation
 Wiktor Młynarski
Wiktor Młynarski- Max-Planck Institute for Mathematics in the Sciences, Leipzig, Germany
To date a number of studies have shown that receptive field shapes of early sensory neurons can be reproduced by optimizing coding efficiency of natural stimulus ensembles. A still unresolved question is whether the efficient coding hypothesis explains formation of neurons which explicitly represent environmental features of different functional importance. This paper proposes that the spatial selectivity of higher auditory neurons emerges as a direct consequence of learning efficient codes for natural binaural sounds. Firstly, it is demonstrated that a linear efficient coding transform—Independent Component Analysis (ICA) trained on spectrograms of naturalistic simulated binaural sounds extracts spatial information present in the signal. A simple hierarchical ICA extension allowing for decoding of sound position is proposed. Furthermore, it is shown that units revealing spatial selectivity can be learned from a binaural recording of a natural auditory scene. In both cases a relatively small subpopulation of learned spectrogram features suffices to perform accurate sound localization. Representation of the auditory space is therefore learned in a purely unsupervised way by maximizing the coding efficiency and without any task-specific constraints. This results imply that efficient coding is a useful strategy for learning structures which allow for making behaviorally vital inferences about the environment.
1. Introduction
As originally proposed by Barlow (1961), the efficient coding hypothesis suggests that sensory systems adapt to the statistical structure of the natural environment in order to maximize the amount of conveyed information. This implies that stimulus patterns encoded by sensory neurons should reflect statistics and redundancies present in the natural stimuli. Indeed - it has been demonstrated that learning efficient codes of natural images (Olshausen and Field, 1996; Bell and Sejnowski, 1997) or sounds (Lewicki, 2002) reproduces shapes of neural receptive fields in the visual cortex and the auditory periphery. Additionally, recent studies provided statistical evidence suggesting that spectrotemporal receptive fields (STRFs) at processing stages beyond the cochlea, are adapted to the statistics of the auditory environment (Klein et al., 2003; Carlson et al., 2012; Terashima and Okada, 2012) to provide its efficient representation. However, having a sole representation of the stimulus is not enough for the organism to interact with the environment. In order to perform actions, the nervous system has to extract relevant information from the raw sensory data and then segregate it according to its functional meaning. For example the auditory system must extract position invariant information regardless of sound quality, separating “what” and “where” information. In a more recent paper (Barlow, 2001) Barlow proposed that behaviorally relevant stimulus features (i.e., ones supporting informed decisions) may be learned by redundancy reduction. In other words, functional segregation of neurons can be achieved by efficient coding of sensory inputs. The evidence in support of this notion is still sparse.
Among different sensory mechanisms, spatial hearing provides a good example for the extraction and separation of behaviorally vital information from the sensory signal. The ability to localize and track sound sources in space is of a critical relevance for the survival of most animal species. Contrary to vision, audition covers the entire space surrounding the listener and may therefore provide an early warning about the presence or motion of objects in the environment. Mammals localize sounds on the azimuthal plane using two ears (Schnupp and Carr, 2009; Grothe et al., 2010). Binaural hearing mechanisms rely on between-ear disparities to infer the spatial position of the sound source. In humans, according to the well known Duplex Theory (Strutt, 1907; Grothe et al., 2010), interaural time differences (ITDs) constitute a major cue for low frequency sound localization and sounds of high frequency (>1500 Hz) are localized with interaural level differences (ILDs). However in natural hearing conditions, spectrotemporal properties of sounds vary continuously, hence combinations of cues available to the organism also change. Even though temporal differences on the order of microseconds are of a substantial importance for sound localization, binaural neurons in the higher areas of the auditory pathway can be characterized with Spectrotemporal Receptive Fields (STRFS), which have much more coarse temporal resolution (ms) (Gill et al., 2006). Despite such loss of temporal accuracy, many of those neurons reveal sharp spatial selectivity (Schnupp et al., 2001) encoding the position of the sound source in space. What is the neural computation underlying this process remains an open question.
The present paper uses spatial hearing as an example of a sensory task, to show how information of different meaning (“what” and “where”) can be clearly separated. As its main result, it provides computational evidence pointing that redundancy reduction leads to the separation of spatial information from the representation of the sound spectrogram. This means that formation of the neural auditory space representation can be achieved without the need of any task-specific computations but solely by applying the general principle of redundancy reduction. It is demonstrated that Independent Component Analysis (ICA) - a linear efficient coding transform (Hyvärinen et al., 2009) trained on a dataset of spectrograms of simulated as well as natural binaural speech sounds, extracts sound position invariant features separating them from the representation of the sound position itself. Learned structures can be understood as model spatial and spectrotemporal receptive fields of auditory neurons which encode different kinds of behaviorally relevant information. Current results are in line with known physiological phenomena and allow to make new experimental predictions.
2. Materials and Methods
High order statistics of natural auditory signal were studied by performing ICA on a time-frequency representation of binaural sounds.
As a proxy for natural sounds, speech was used in the present study. Speech comprises a rich variety of acoustic structures and has been successfully used to learn statistical models predicting properties of the auditory system (Klein et al., 2003; Smith and Lewicki, 2006; Carlson et al., 2012). Additionally, it has been suggested that speech may have evolved to match existing neural representations, which are optimizing information transmission of environmental sounds (Smith and Lewicki, 2006).
Spatial sounds were obtained in two ways. Firstly, the efficient coding algorithm was trained using simulated naturalistic binaural sounds. Simulation gave the advantage of labeling each sound with its spatial position. Secondly a natural auditory scene was recorded with binaural microphones. The signal obtained in this way was less controlled, however it contained more complex and fully natural spatial information. Training datasets were obtained by drawing 70000 random intervals 216 ms long from each dataset separately. The data generation process together with its interpretation is displayed on Figure 1.
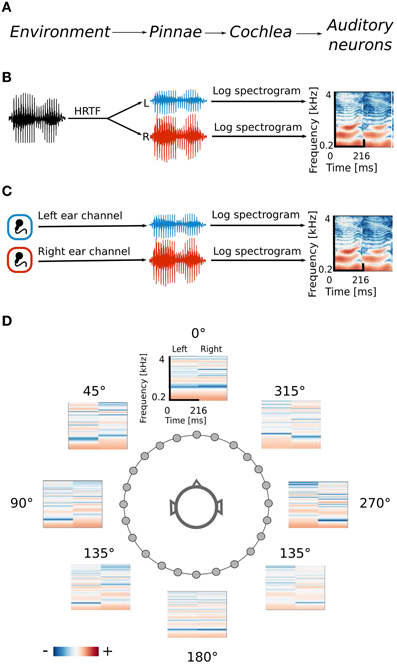
Figure 1. Data generation process. (A) Interpretation of consecutive stages of data generation. The acoustic environment is either simulated (B) or recorded with binaural microphones (C). Further stages of the processing include frequency decomposition and transformation with a logarithmic nonlinearity, which emulates cochlear filtering (D) Positions of HRTFs around the head are marked with circles.
2.1. Simulated Sounds
As a corpus of natural sounds, data from the International Phonetic Association Handbook (International Phonetic Association, 1999) were used. The database contains speech sounds of a narrative told by male and female speakers in 29 languages. All sounds were downsampled to 16000 Hz from their original sampling rate and bandpass filtered between 200 and 6000 Hz. The training dataset was created by drawing random intervals of 216 ms from the speech corpus data. Spatial sounds were simulated by convolving sampled speech chunks with human Head Related Transfer Functions (HRTFs). HRTF fully describe the sound distortion due to the filtering by the pinnae and therefore contain entire spatial information available to the organism. Given an angular sound source position θ, HRTF is defined by a pair of linear filters:
where L, R subscrpits denote left and right ear respectively, and t denotes time sample. One should note that in the temporal domain, HRTFs are often called Head Related Impulse Response (HRIR). A set of HRTFs was taken from the LISTEN database (Warfusel, 2002). The database contains human HRTFs recorded for 187 positions in the three-dimensional space surrounding the subject's head. HRTFs from a single random subject were selected and further limited to positions lying on the azimuthal plane with 15° spacing (24 positions in total). Monaural stimulus vectors xE(t) (E ∈ {R, L} denotes the ear) were created by drawing random chunks g(t) of speech sounds and convolving them with HRTF(θ) corresponding to an azimuthal position θ, which was also randomly drawn:
where ∗ denotes the convolution operator. In this data, spatial and identity information constitute independent factors.
2.2. Natural Sounds
In order to obtain a dataset of natural binaural sounds a complex auditory scene was recorded using binaural microphones. The recording consisted of three people (two males and one female) engaged in a conversation while moving freely in an echo-free chamber. Such an environment without reflections and echoes reduced the number of factors modifying sound waveforms. One of the male speakers was recording the audio signal with Soundman OKM-II binaural microphones placed in the ear channels. In total 20 min were recorded and included moving and stationary, often overlapping sound sources. To test the spatial sensitivity of learned features a recording with a single male speaker was performed. He walked around the head of the recording subject with a constant speed following a circular trajectory while reading a book out loud, twice in the clockwise and twice anti-clockwise direction. The length of the testing dataset was 54 s.
2.3. Simulated Cochlear Preprocessing
Before reaching the auditory cortex, where spatial receptive fields (SRFs) were observed (Schnupp et al., 2001), sound waveforms undergo a substantial processing. Since the modeling focus of the present study was beyond the auditory periphery, the data were preprocessed to roughly emulate the cochlear filtering (see the scheme on Figure 1).
Short Time Fourier Transform (STFT) was performed on each sound interval included in the training dataset. Each chunk was divided into 25 overlapping windows each 16 ms long. STFT spanned 256 frequency channels logarithmically spaced between 200 and 4000 Hz (decomposition into arbitrary, non-linearly spaced frequency channels was computed using the Goertzel algorithm). Logarithmic frequency spacing was observed in the mammalian cochlea and seems to be a robust property across species (Greenwood, 1990; Smith et al., 2002). The spectral power of the resulting spectrograms was transformed with a logarithmic function which emulates the cochlear compressive non-linearity (Robles and Ruggero, 2001).
Stimuli were 216 ms long in order to match the temporal extent of cortical neurons' STRFs, which were characterized by SRFs (Schnupp et al., 2001). Besides emulating the cochlear transformation of the air pressure waveform, such spectrograms were reminiscent of the sound representation most effective in mapping spectrotemporal receptive fields in the songbird midbrain (Gill et al., 2006). A very similar representation was used in a recent sparse coding study (Carlson et al., 2012).
Spectrograms of left and right ears were concatenated. Such data representation attempts to simulate the input to higher binaural neurons, which operate on spectrotemporal information, simulteneously fed from monaural channels (Schnupp et al., 2001; Miller et al., 2002; Qiu et al., 2003). In principle, we could first train ICA on monaural spectrograms and then model their codependencies. In such way, however, the algorithm could not explicitly model binaural correlations. Additionally, this would require application of a hierarchical model, which lies outside of the scope of this study. Our approach resembles ICA studies, which focused on modeling of visual binocular receptive fields (Hoyer and Hyvärinen, 2000; Hunt et al., 2013). There, the input to binocular neurons in the visual cortex was modeled by concatenating image patches from the left and the right eye.
The efficient coding algorithm was run on the resulting time-frequency representation of the binaural waveforms. After preprocessing the dimensionality of data vectors was equal to 2 × (25 × 256) = 12800. Both training datasets: simulated and natural one consisted of 70000 samples. Prior to the ICA learning, the data dimensionality was reduced with Principal Component Analysis (PCA) to 324 dimensions, preserving more than 99% of total variance in both cases. Due to memory issues (allocation of a very large covariance matrix) a probabilistic PCA implementation was used (Roweis, 1998).
2.4. Independent Component Analysis
ICA is a family of algorithms which attempt to find a maximally non-redundant, information-preserving representation of the training data within the limits of the linear transform (Hyvärinen et al., 2009). In its standard version, given the data matrix X ∈ ℝn×m (where n is the number of data dimensions and m the number of samples), ICA learns a filter matrix W ∈ ℝn×n, such that:
where columns of X are data vectors x ∈ ℝn, rows of W are linear filters w ∈ ℝn and S ∈ ℝn×m is a matrix of latent coefficients. Equivalently the model can be defined using a basis function matrix A = W−1, such that:
Columns a ∈ ℝn of matrix A are known as basis functions and in neural systems modeling can be interpreted as linear stimulus features represented by neurons, which form an efficient code of the training data ensemble (Hyvärinen et al., 2009). Linear coefficients s are in turn a statistical analogy of the neuronal activity. Since they can take both positive and negative values, their direct interpretation as physiological quantities such as firing rates is not trivial. For a discussion of relationship between linear coefficients and neuronal activity, please refer to Rehn and Sommer (2007); Hyvärinen et al. (2009). Equation 4 implies that each data vector can be represented as a linear combination of basis functions a
where t indexes the data dimensions. The set of basis functions a is called a dictionary. ICA attempts to learn a maximally non-redundant code. For this reason latent coefficients s are assumed to be statistically independent i.e.,
The marginal probability distributions p(si) are usually assumed to be sparse (i.e., of high kurtosis), since natural sounds and images have intrinsically sparse structure (Olshausen and Field, 1997) and can be represented as a combination of a small number of primitives. In the present work logistic distribution of the form:
with position μ = 0 and scale parameter ξ = 1 is assumed. The basis functions are learned by maximizing the log-likelihood of the model via gradient ascent (Hyvärinen et al., 2009).
2.5. Analysis of Learned Basis Functions
Similarity between left and right ear parts of learned basis functions was assessed using the Binaural Similarity Index (BSI), as proposed in Miller et al. (2002). The BSI is simply Pearson's correlation coefficient between left and right ear parts of each basis function. BSI equal to −1 means that absolute values at every frequency and time position are equal and have the opposite sign, while BSI equal to 1 means that the basis function represents the same information in both ears.
Dictionary of binaural basis functions learned from natural data was classified according to the modulation spectra of their left ear parts. A modulation spectrum is a two-dimensional Fourier transform of a spectrogram. It is informative about spectral and temporal modulation of learned features and it has been applied to study properties of natural sounds (Singh and Theunissen, 2003) and real (Miller et al., 2002) as well as modeled (Saxe et al., 2011) receptive fields in the auditory system.
Spatial sensitivity of basis functions learned from natural data was further quantified by means of Fisher information. Fisher information is a measure of how accurate one can estimate a hidden parameter θ from an observable s knowing a conditional probability distribution p(s|θ) (Brunel and Nadal, 1998). Here, θ corresponds to the angular position of the auditory stimulus and s to one of the sparse coefficients. Assuming a deterministic mapping s(θ) = f(θ) = μθ distorted with a zero-mean stationary Gaussian noise, one obtains:
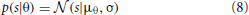
For simplicity σ was assumed to be equal to 1. Fisher information 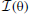 then becomes (Brunel and Nadal, 1998):
then becomes (Brunel and Nadal, 1998):
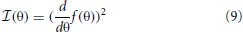
Mean values μθ were estimated by averaging coefficient activations over four trials during which the speaker walked around the head of the subject. Each activation time course was additionally smoothed with a 20 samples long rectangular window.
3. Results
Besides the properties of the sound source itself, natural sounds reaching the ear membrane are also shaped by head-related filtering. The spectrotemporal structure imposed by the filter depends on the spatial configuration of objects. By performing redundancy reduction the auditory system could, in principle, separate those two sources of variability in the data and extract spatial information. One should observe that transformations performed by the cochlea can strongly facilitate this task. The stimulus xE (where E ∈ L, R indicates the left or the right ear) is an air pressure waveform g(t) convoluted with an HRTF (or a combination of HRTFs) hE,θ(t), as defined by equation 2. The basilar membrane performs frequency decomposition, emulated here by the Fourier transform:
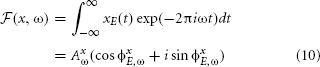
where ω denotes frequency, AxE,ω amplitude and ϕxE,ω phase. By the convolution theorem (Katznelson, 2004), convolution in the temporal domain is equivalent to a pointwise product in the frequency domain, i.e.,
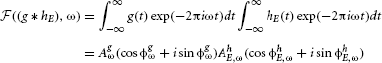
Additionally, the basilar membrane applies a compressive non-linearity (Robles and Ruggero, 2001) which this study approximates by transforming the spectral power with a logarithmic function. Since the logarithm of the product is equal to the sum of logarithms, the spectral amplitude of the stimulus AxE,ω = AhE,ωAgω can be decomposed into the sum:
This means that the spectrotemporal representation of the signal generated by the cochlea is a sum of the raw sound and HRTF features. One should note, however, that the above analysis applies to an infnite window Fourier transform, and the data used in this study was generated by performing a STFT with a 16 ms long, overlapping windows. Fourier coefficients were mixed between neighboring windows due to their overlap. For point-source, stationary sounds this effect did not influence the log(AhE,ω) term of the Equation 11, since HRTFs were shorter than the STFT window, hence hear-related filtering was temporally constant. For a dynamic scene, where neighboring STFT windows contained different spatial information, the additive separability of sound and HRTF features (as described by Equation 11) may have been distorted. Taken together, a linear redundancy reducing transform such as ICA provides a reasonable approach to separate information about object positions from the raw sound. In an ideal case, ICA trained on stimulus spectrograms Axω could separate representation of HRTF (AhE,ω) and stimulus (AgE,ω) amplitudes into two distinct basis functions sets (Harper and Olshausen, 2011). The difficulty of the separation task depends on the temporal variability of the spatial information which reflects configuration of the environment (i.e., number of sources, their motion patterns and positions). The current study considers two cases of different complexity: (a) simulated dataset consisting of short periods of speech displayed from single positions and (b) a binaural recording of a natural scene with freely moving human speakers.
3.1. Simulated Sounds
The goal of the present study was to identify high-order statistics of natural sounds informative about positions of the sound source. Association of a sound waveform with its spatial position requires detailed knowledge about source localization i.e., each sound should be labeled with spatial coordinates of its source. For this reason binaural sounds studied in this section were simulated, using speech sounds and human HRTFs. Naturalistic data created in this way resembled binaural input from the natural environment, while making position labeling of sources available.
From the simulated dataset, after reducing data dimensionality with PCA (see section 2.3), 324 ICA basis functions were learned. A subset of 100 features is depicted in Figure 2. It is clearly visible that the learned basis can be divided into two separate subpopulations by the similarity between their left and right ear parts, which is quantified by the Binaural Similarity Index (BSI) (see Materials and Methods). Sorted values of the BSI are displayed on Figure 6A as black circles. The majority of basis functions (314) exceed the 0.9 threshold and only 10 fall below it. Out of those 8 reveal strong negative interaural correlation and only 2 are close to 0. Basis functions with the BSI below 0.9, were separated from the rest and all ten of them are depicted on Figure 2A. Since they represent different information in each ear they are going to be called “binaural” through the rest of the paper. This is in contrast to “monaural” basis functions which encode similar sound features in both ears (see Figure 2B).
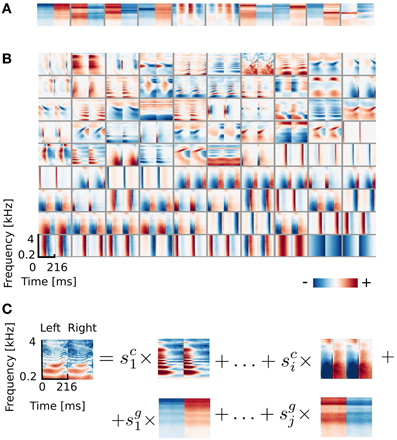
Figure 2. ICA basis functions trained on simulated sounds (A) Binaural basis functions agi. Left and right ear parts are dissimilar. (B) Monaural basis functions aki. Left and right ear parts are highly similar. (C) Explanation of the representation. Each stimulus can be decomposed into a linear combination of monaural basis functions (multiplied by their coefficients sci) and binaural ones multiplied by coefficients sgi.
The binaural sub-dictionary captures signal variability present due to the head-related filtering. Even though the training dataset included sounds displayed from 24 positions, hence 24 different HRTFs were used, only 10 binaural basis functions emerged from the ICA. Out of those, almost all are temporally stable i.e., do not reveal any temporal modulation (except for 2 - positions 5 and 6 on Figure 2A). The dominance of temporally constant features was expected, since training sounds were displayed from fixed positions and were convoluted with filters, which did not change in time. Temporally stable basis functions weight spectral power across frequency channels, mostly with opposite sign in both ears (as reflected by negative values of the BSI). Surprisingly, despite the lack of moving sounds in the training dataset, two temporally modulated basis functions were also learned by the model. They represent envelope comodulation in high frequencies with an interaural phase shift of π radians.
A representative subset of 90 monaural basis functions is depicted on Figure 2B. Their left and right ear parts are exactly the same and encode a variety of speech features. Regularities such as harmonic stacks, on- and offsets or formants are visible. Captured monaural patterns essentially reproduce results from a recent study by Carlson et al. (2012) which shows that efficient coding of speech spectrograms learns features similar to STRFs in the Inferior Colliculus (IC). Monaural basis functions are, however, not a focus of the present study and are not going to be discussed in detail.
A separation of the learned dictionary into two subpopulations of binaural and monaural basis functions (ag and ak respectively) allows to represent every sound spectrogram in the training dataset as a linear combination of two isolated factors i.e., representations of speech and HRTF structures (see Figure 2C). Taking this fact into account, Equation 5 can be rewritten as:
This notation explicitly decomposes the basis into G spatial basis functions ag and K and non-spatial basis functions ak.
3.1.1. Emergence of model spatial receptive fields
Marginal coefficient histograms conformed rather well to the logistic distribution assumed by the ICA model, although binaural coefficients were typically more sparse (see Figure 3). In order to understand how informative learned features are about position of sound sources, conditional distributions of the linear coefficients were studied. Histograms conditioned on a location of a sound source reveal whether any spatial information is encoded by learned basis functions.
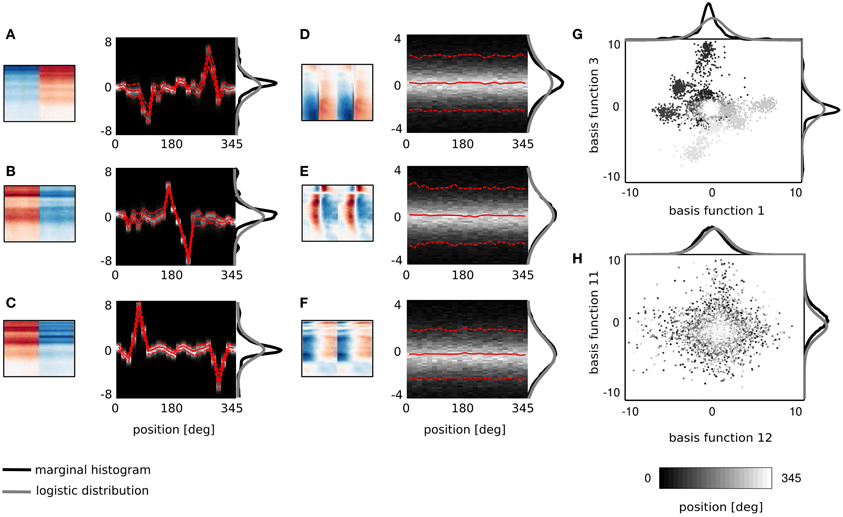
Figure 3. Spatial sensitivity of basis functions. (A–F) Spectrotemporal basis functions and associated conditional histograms of linear coefficients s. Solid red lines mark means and dashed lines limits of plus/minus standard deviation. (G,H) Example pairwise dependencies between monaural and binaural basis functions respectively. Each point is one sound and grayscale corresponds to its spatial position.
Figures 3A–F displays 6 basis functions and corresponding conditional histograms. The horizontal axis of each conditional histogram corresponds to the angular position of the sound source (from 0 to 345°). A vertical cross-section is a normalized histogram of the coefficient values for all sounds displayed in the training dataset from a particular position (around 2900 samples on average).
Three representative monaural basis functions are depicted on Figures 3D–F. It is immediately visible that conditional distributions of their coefficients are stationary across spatial positions. The zero-centered logistic pdf with a constant scale parameter (parameters equal to those of the marginal pdf) is preserved across all positions. This implies that coefficients of monaural basis functions are independent from the sound source location. Monaural bases encode speech features and since all speech structures were displayed from all positions in the training data, their activations do not carry spatial information. This property is characteristic for all basis functions with BSI greater than 0.9.
Coefficients of binaural basis functions reveal a very different dependency structure (see Figures 3A–C. Their variance at each spatial position is very low, however, variability across positions is much higher. Activations of binaural features remain close to zero at most angular positions regardless of the sound identity. At few preferred positions they reveal pronounced peaks in activation (positive or negative) reflected by strong shifts in the mean value. This highly non-stationary structure of conditional pdfs is informative about the sound position, while remains almost invariant to the sound's identity (which is reflected by the small standard deviation). Basis function depicted on Figure 3A responds with a strong positive activation to sounds originating at 270° (i.e., directly in front of the right ear) and with a strong negative activation to sounds originating from the directly opposite location - at 90° (i.e., in front of the left ear). Sounds at positions deviating ±15° from peaks also modulate basis activations, although activations are weaker. Similar spatial selectivity pattern is revealed by the basis function on Figure 3C, which however responds positively to sounds at 60 and negatively to sounds at 315°. The spectrotemporal feature on Figure 3B encodes spatial information of a particularly high behavioral relevance. Its activity significantly deviates from zero, only when sounds are placed behind the head in the interval between 165 and 210°. This region is not visually accessible, therefore position or motion of objects in that area has to be inferred basing on auditory information only. It may appear that conditional histograms are symmetric around the 180° point. However, positive and negative peaks of coefficient histograms do not have exactly equal absolute values.
It is important to notice here that each spectrotemporal feature captured by binaural basis functions is an indirect representation of the sound position in the surrounding environment. Therefore if ICA basis functions can be interpreted as STRFs of binaural neurons, the corresponding conditional histograms constitute a theoretical analogy of their SRFs informing the organism about the position of the sound source within the head-centered frame of reference.
3.1.2. Decoding of the sound position
As described in the previous subsection, linear coefficients of binaural basis functions are informative about the location of the sound source. Spatial selectivity of single basis functions is however not specific enough to reliably localize sounds. Pairwise coefficient activations of two exemplary basis functions are depicted on Figure 3G. Each point represents a single sound and its color corresponds to the source's angular position. Strong clustering of same-colored points is strongly visible. They form at least 6 highly separable clusters. This, in turn, shows that the joint distribution of those two coefficients contains more information about the source position than one dimensional conditional pdfs. This is in contrast to Figure 3H depicting co-activations of two monaural basis functions. There, points of all colors are strongly mixed, creating a “salt and pepper” pattern, where no clear separation between source positions is visible.
To test, whether reliable decoding of sound position from activations of binaural basis functions is possible, this work employs the Gaussian Mixture Model (GMM). The GMM models the marginal distribution of latent coefficients sg used for the position decoding as a linear combination of Gaussian distributions, such that:
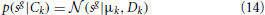
where Ck is a position label (C1 = 0 deg, C24 = 345 deg) and μk, Dk denote a position specific mean vector and covariance matrix respectively. The structure of dependencies among random variables is presented in a graphical form in Figure 4A. Since the prior on position labels p(Ck) is assumed to be uniform, the decoding procedure can be recast as a maximum-likelihood estimation:
where is the decoded position. The resulting procedure iterates over all position labels and returns the one which maximizes the probability of an observed data sample.
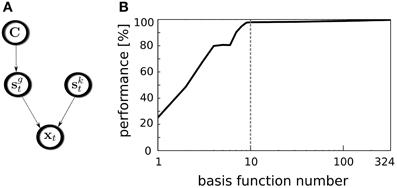
Figure 4. Position decoding model. (A) A graphical model representing variable dependencies. (B) Decoders performance plotted against the number of used basis functions. Vertical dashed line separates binaural basis functions from monaural ones.
The decoding performance relies on the selected subset of basis functions used for this task. To test whether binaural features contribute stronger to the position decoding than monaural ones, all basis functions were sorted according to their BSI. Then, the GMM was trained using incrementally larger number of latent coefficients, starting from a single one corresponding to the basis function with the highly negative BSI and ending using the entire basis function set. In every step, for the GMM training 70% of the data were used, while remaining 30% were used for cross-validation. The average decoder performance is plotted against the number of used features on Figure 4B. Binaural features are separated from the monaural ones with a dashed vertical line. A straightforward observation is that binaural basis functions almost saturate the decoding accuracy. Indeed it reaches the level of 97.9%. Adding remaining 314 monaural basis functions increases the performance to 99.7% which is only 1.8% point. Interestingly, temporally modulated binaural basis functions number 5 and 6 did not contribute to the decoding quality, which is visible as a short plateau on the plot. Saturation of the decoder's performance by binaural basis function activations entails that almost entire spatial information present in the sound is separated from other kinds of information by the ICA model and represented by binaural basis functions. Relating this observation to the nervous system, this means, that the spatial position of natural sound sources can be decoded from the joint activity of a relatively small subpopulation of binaural neurons.
3.2. Natural Sounds
The previous section described results for simulated sounds. While simulated sounds have the advantage of giving a full control over source positions they are only a very crude approximation to the binaural stimuli occurring in the real natural environment. This section describes results obtained using binaural recordings of a real-world auditory scene, consisting of three speakers moving freely in an echo-free environment.
Binaurality of learned basis functions was again quantified with the BSI. Sorted BSI values are plotted on Figure 6A as gray triangles. A strong difference is visible, when compared with values of the dictionary trained on simulated data (black circles). Firstly, 64 natural basis functions lay below the 0.9 threshold - many more compared to only 10 simulated ones. Secondly, natural BSIs vary more smoothly, and are more uniformly distributed between −1 and 0.9 (see the histogram displayed in the inset).
Similarly to the previous case, the learned dictionary was divided into two sub-dictionaries - binaural ones - below and monaural ones - above the 0.9 BSI threshold. The sub-dictionary consisting of binaural basis functions is displayed on Figures 5A,B displays 40 exemplary monaural basis functions. While no qualitative difference is visible between monaural features when compared with results from the previous section (Figure 2B), the binaural sub-dictionaries differ strongly. Basis functions trained using natural data, reveal much richer variety of shapes including temporally modulated ones along patterns of strong spectral modulation.
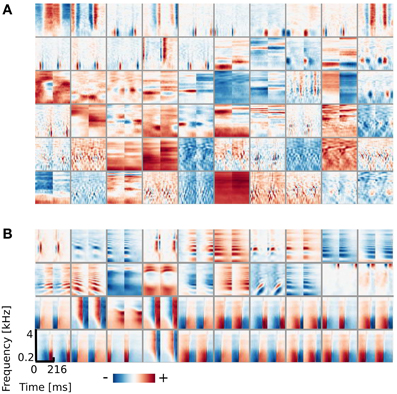
Figure 5. Basis functions learned using natural data. (A) Binaural basis functions (60 out of 64). (B) Monaural basis functions (40 out of 250).
3.2.1. Properties of the learned representation
This subsection presents properties of binaural basis functions trained with the natural binaural data. They were studied in more detail than the dictionary learned from simulated data since its structure is more complex and may reflect better the properties of binaural neurons. One should note that in neural systems modeling, neural receptive fields correspond better to ICA filters (rows w of matrix W in Equation 12). Basis functions, however, constitute optimal stimuli i.e., given basis function ai as input the only non-zero coefficient is going to be si. Additionally, basis functions are a low-passed version of filters (Hyvärinen et al., 2009), and are more appropriate for plotting, since they represent actual parts of stimulus. For those reasons, this study focuses on basis function statistics.
The binaural dissimilarity of learned features was assessed with two measures. The BSI provides a continuous value quantifying how well the left ear part matches the right ear part. It however does not take into account the dominance of one ear over another. The dominance can be measured by comparing monaural peaks i.e., points of the maximal absolute value of left and right ear parts. Both measures were used by Miller et al. (2002) to describe receptive fields of binaural neurons in the auditory thalamus and cortex. Monaural peaks (measured in standard deviation of the basis function dimensions) are compared on Figure 6B. Crosses mark basis functions with the positive and diamonds with the negative BSI. Symbol sizes correspond to the absolute BSI value. Basis functions cluster along the diagonals (marked with dashed lines) which means that left and right ear peaks have similar absolute values and no clear dominance of a single ear is present. Interestingly, while roughly the same number of basis functions lays in upper right and both lower quadrants, only 4 lay in the upper left one, corresponding to basis functions with a negative peak in the left ear and positive in the right ear. Unfortunately, direct comparison of the analysis on Figure 6B with Figure 9 in Miller et al. (2002) is not possible, due to the arbitrariness of the sign in the ICA model (coefficients can have positive and negative values, flipping the sign of the basis function). Additionally the notion of ipsi- and contra- laterality is meaningless for ICA basis functions.
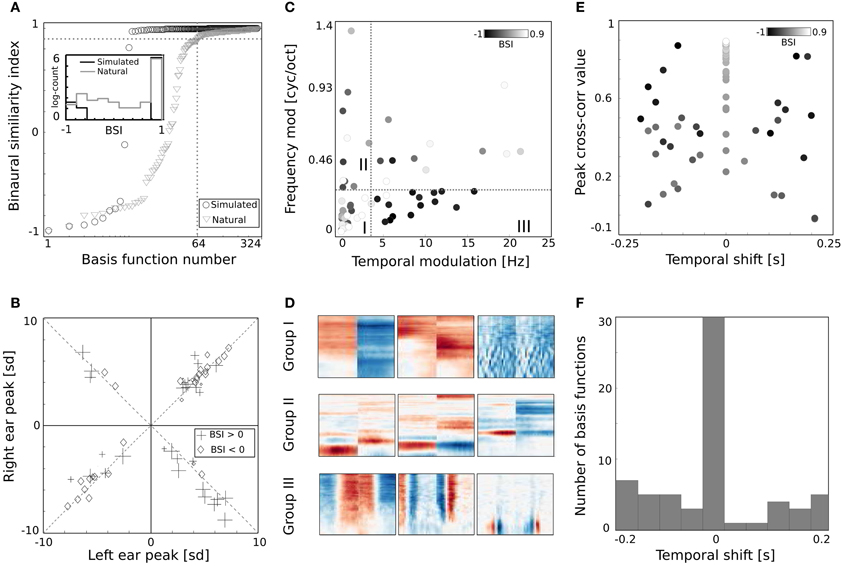
Figure 6. Properties of basis functions learned using natural data. (A) BSI values of natural and simulated bases. (B) Peak values of binaural bases. (C) Centers of mass of modulation spectra. (D) Exemplary basis functions belonging to groups I, II, and III. (E) Temporal cross-correlation plotted against its peak value. Color marks the BSI. (F) A histogram of temporal shifts maximizing the cross correlation.
Shapes of basis functions belonging to the binaural sub-dictionary were studied by analyzing modulation spectra of their left-ear parts. Even though functions were binaural, classification according to only the single ear part was sufficient to identify subgroups with interesting binaural properties. Centers of mass of modulation spectra (for computation details see Materials and Methods) are plotted as circles on Figure 6C. Circle color corresponds to the BSI value. Left parts of binaural features display a tradeoff between spectral and temporal modulation. This complies with the general trend of natural sound statistics (Singh and Theunissen, 2003). Dictionary elements were divided into three distinctive groups according to their modulation properties (marked with roman numerals I, II, III, and separated with dotted lines on Figure 6C). The first group consisted of weakly modulated features with spectral modulation below 0.3 cycles/octave and temporal modulation below 4 Hz. Majority of basis functions belonging to this group had high BSI, close to 0.9. Three representative members of the first group are displayed on Figure 6D in the first row. Since their spectrotemporal modulation is weak, they capture constant patterns, similar in both ears, up to the sign. The second group consists of basis functions revealing strong spectral modulation - above 0.3 cycles/octave. Three exemplary members are visible in the second row of Figure 6D. Basis functions belonging to the second group resemble majority of ones learned from simulated data. They weight spectral power across frequency channels constantly over time. In contrast to simulated basis functions, their BSIs are mostly close to 0, indicating that channel weights do not necessarily have opposite sign between ears. Additionally, as visible in two out of three displayed examples, low frequencies below 1 kHz are also weighted.
The third group includes highly temporally modulated features. Their temporal modulation exceeds 4 Hz, while the spectral one stays below 0.3 cycles/octave. Out of 15 members of this group, only one has a positive BSI value - the rest remains close to −1. This implies that when their monaural parts are aligned with each other - corresponding dimensions have a similar absolute value and an opposite sign. Three examplary members of the third group are depicted in the last row of Figure 6D. They are qualitatively similar to two temporal basis functions learned from the simulated data (they represent an envelope comodulation across multiple frequency channels with a π phase difference).
The temporal differences between monaural parts of basis functions were further studied using cross-correlation functions (ccf). Maximal values of the normalized ccf are plotted against maximizing temporal shifts on Figure 6E. As in the Figure 6C - the color of circles represents the BSI value. The histogram of temporal shifts is depicted on Figure 6F. Cross-correlation of 30 binaural features with a positive BSI, is maximized at 0 temporal shift. In this case, BSI and the peak of cross-correlation have the same value. This is a property of basis functions with a weak temporal modulation, which constitute a major part of the binaural sub-dictionary. Features revealing temporal modulation have a negative BSI value (dark colors) and a non-zero temporal difference, which spanned the range between −0.2 and 0.2 s.
3.2.2. Spatial sensitivity of binaural basis functions
In contrast to the simulated dataset, binaural recordings were not labeled with sound source positions. Furthermore, learned features may represent dynamic aspects of the object motion, therefore conditional histograms (constructed as in the previous section) would not be meaningful.
In order to verify whether binaural basis functions reveal tuning to spatial position of sound sources and invariance to their identity, a test recording was performed. One of the male speakers read a book out loud, while walking around the head of the recording subject, following a circular trajectory in a constant pace. This was repeated twice in the anticlockwise and twice in the clockwise direction. In such a way, the angular position of the speaker was made easy to estimate at each time point. The recording was divided into 216 ms overlapping intervals, and each interval was encoded using the learned dictionary. A general trend in the spatial sensitivity of basis functions was measured by computing correlation between estimated speaker's position and time courses of linear coefficients in the following way. Firstly, activation time courses were standarized to have mean equal to 0 and variance equal to 1. In the next step, time intervals where the coefficient's absolute value exceeded 1 were extracted. This was done, since highly sensitive coefficients remained close to 0 most of the time, and correlated with the speaker's position only in a narrow part of the space (i.e., their receptive field). Elements of the binaural sub-dictionary correlated stronger with the estimated position than elements of the monaural one. Normalized histograms of linear correlations between the position of the sound source and sparse coefficients are presented on Figure 7. Monaural basis functions correlate much weaker with the sound position, which is reflected in the strong histogram peak around 0. Binaural coefficients in turn, reveal strong correlations of the absolute value of 0.8 in extreme cases. Linear correlation is however not a perfect way to assess relationship between sparse coefficients and the source position, since spatial selectivity of basis function may be limited to a narrow spatial area (as in Figures 8A,B). This results in correlations of low absolute values, even though spatial sensitivity of a basis function may be quite high. To show spatial selectivity of learned features, their activations were plotted. Resulting time courses of basis function activations are displayed as black continuous lines on Figure 8. Gray dashed lines mark approximated angular position of the speaker at every time point.
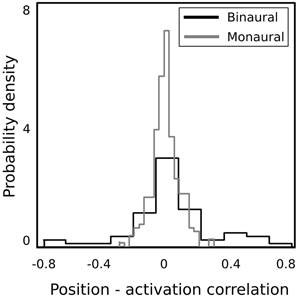
Figure 7. Normalized histograms of activation-position correlations.
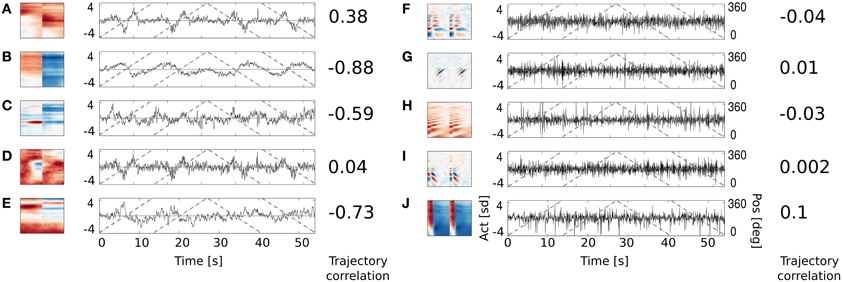
Figure 8. Activation time course of basis functions learned using natural data. An audio-video version is available in the supplementary material. Subfigures (A–E) depict binaural basis functions with their activation time courses, while subfigures (F–J) monaural ones. Black continuous lines mark standarized activation values, gray dashed lines mark speaker's angular position.
Subfigures (F–J) display activations of 5 representative monaural basis functions. As expected, their activity correlates very weakly with the speaker's trajectory. Monaural basis functions encode features of speech and are invariant to the position of the speaker. In contrary, activations of binaural basis functions visible on subfigures (A–E), reveal strong dependence on subjects position and direction of motion. Basis function A remains non-activated for most of positions and deviates from zero when the speaker is crossing the area behind the head of the recording subject. The slope of activation time courses is informative about the direction of speaker's motion. Similar, however noisier, spatial tuning is revealed by the basis function D. Basis function B displays broader spatial sensitivity, and its activation varies smoothly along the circle surrounding the subject's head. Spatial information represented by the spectrally modulated basis functions C and E does not have such a clear interpretation, however they display pronounced covariation with sound source's position (feature C for instance is strongly positively activated, when the speaker crosses directly opposite to the left ear).
Spatial sensitivity of basis functions can be further quantified using Fisher information (for computation details please see Materials and Methods). Figure 9 shows Fisher information estimates as a function of spatial position for features displayed on Figure 8. Each binaural basis function reveals a preferred region in space where source's position is encoded with higher accuracy. For this reason, histograms depicted on Figures 9A–E can be interpreted as an abstract descriptions of auditory SRFs. Basis function (A), is most strongly informative about position of the sound source behind the head (around 180°), which is also reflected in the timecourse of its activation. The Fisher information peaks in visually inaccessible areas also in other, depicted basis functions [subfigures (B), (C), (E)]. There, however, the peak is not as pronounced as in the first basis function, and sensitivity to frontal positions is also visible. Fisher information of monaural basis functions [subfigures (F)–(J)] does not reveal spatial selectivity, is order of magnitude smaller and would most probably vanish in the limit of more samples.
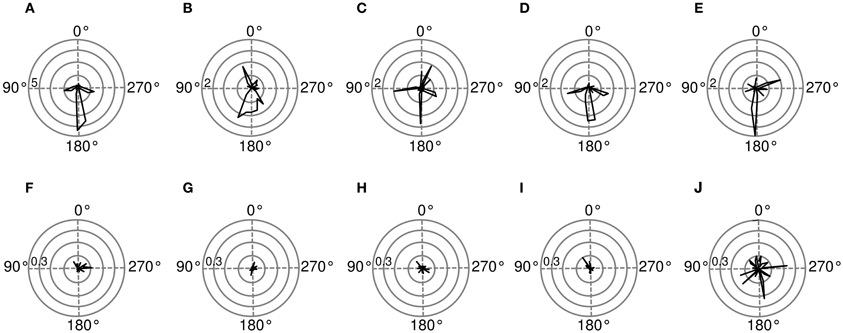
Figure 9. Spatial sensitivity quantified with Fisher information. Polar plots represent area surrounding the listener, black lines mark Fisher information at each angular position. Each subfigure corresponds to a basis function on the previous figure marked with the same letter. (A–E) Exemplary binaural basis functions (F–J) exemplary monaural features. Please note different scales of the plots.
All binaural basis functions presented on Figure 8 are weakly temporally modulated. Temporally modulated basis functions, do not correlate strongly with the speaker's position (they also did not contribute to the position decoding, as described in the previous section).
4. Discussion
Experimental evidence suggests that redundancy across neurons is decreased in the consecutive processing stages in the auditory system (Chechik et al., 2006). This is directly in line with the efficient coding hypothesis. Additionally, a number of studies have provided evidence of adaptation of binaural neural circuits to the statistics of the auditory environment over different time scales. Harper and McAlpine (2004) have argued that properties of neural representations of ITDs across many species can be explained by a single principle of coding with maximal accuracy (maximization of Fisher information). Two recent experimental studies provide physiological and psychophysical evidence that neural representations of interaural level (Dahmen et al., 2010), and time (Maier et al., 2012) disparities are not static but adapt rapidly to statistics of the stimulus ensemble. The present study contributes to this lines of research, by showing that coding of the auditory space can be achieved by redundancy reduction of spectrotemporal sound representation.
The auditory system has to infer the spatial arrangement of the surrounding space by analyzing spectrotemporal patterns of binaural sound. Auditory SRFs are formed, by extracting signal features which correlate well with environment's spatial states and result from the head related filtering. Both sound datasets used in the present study included two, categorically different variability sources: spatial information carried by binaural differences resulting from the HRTF filtering and the raw sound waveform. Application of ICA - a simple redundancy reducing transform led to a separation of those information sources and formation of distinct model neuron sub-populations with specific spatial and spectrotemporal sensitivity.
4.1. Linear Processing of Spectrotemporal Binaural Cues
Emulation of the cochlear processing by performing spectral decomposition and application of the logarithmic non-linearity produces a data representation well adapted for the position decoding task. While it is usually argued that the logarithmic non-linearity implemented by mechanical response of the cochlear membrane is useful for reducing the dynamical range of the signal (Robles and Ruggero, 2001) it provides an additional advantage. Since in the frequency domain convolution is equivalent to a pointwise product of the signal and the filter (Katznelson, 2004), a logarithm transforms it to a simple addition. A linear operation on the “cochlear” data representation suffices to extract features imposed by the pinnae filtering (Harper and Olshausen, 2011). One should note, however, that in complex listening situations involving more than a single, stationary sound source, this simple relationship (as described by Equation 11) may be distorted and extracted features can be mixing different aspects of the signal.
It has been observed that a linear approximation of spectrotemporal receptive fields in the auditory cortex predicts their spatial selectivity (Schnupp et al., 2001). This result may be surprising given that sound localization is a non-linear operation (Jane and Young, 2000) and that in a general case, linear STRF models do not explain firing patterns of auditory neurons (Escabı and Schreiner, 2002; Christianson et al., 2008). Results shown in this paper suggest that a linear-redundancy reducing transform applied to log-spectrograms suffices to create model SRFs, providing a candidate computational mechanism explaining results provided by Schnupp et al. (2001). Localization of a natural sound source involves information included in multiple frequency channels. Binaural cues such as ILD are computed in each channel separately and have to be fused together at a later stage. This is exemplified by temporally constant basis functions learned using simulated and natural datasets. They linearly weight levels in frequency channel of both ears and in this way form their spatial selectivity. Interestingly the weighting is often asymmetric (which is reflected by BSI values different from −1). Such patterns represent binaural level differences coupled across multiple frequency channels. A recent study has shown that a similar computational strategy underlies spatial tuning of binaural neurons in the nucleus of the brachium of IC in monkeys (Slee and Young, 2013). Since it has already been suggested that IC neurons code natural sounds efficiently (Carlson et al., 2012), present results extend evidence in support of this hypothesis.
4.2. Complex Shapes of Binaural STRFs
Early binaural neurons localized in the auditory brainstem can be classified according to kinds of input they receive from each ear (inhibitory-excitatory - IE and excitatory-excitatory - EE) (Grothe et al., 2010). At the higher stages of auditory processing (Inferior Colliculus, Auditory Cortex), binaural neurons respond also to complex spectrotemporal excitation-inhibition patterns (Schnupp et al., 2001; Miller et al., 2002; Qiu et al., 2003). The present paper suggests, which kinds of binaural features may be encoded and used for spatial hearing tasks by higher binaural neurons. It demonstrates that the reconstruction of natural binaural sounds requires basis functions representing various spectrotemporal patterns in each ear. The dictionary of learned binaural features is best described by a continuous binaural similarity value (in this case Pearson's correlation coefficient - BSI) and not by a classification into non-overlapping IE-EE groups. Temporally modulated basis functions consitute a particularly interesting subset of all binaural ones. Many of them represent a single cycle of envelope modulation, in opposite phase in each ear (see Figure 6D). The time interval corresponding to such phase shift is, however, much larger than the one required for the soundwave to travel between the ears. Their emergence and aspects of the environment they represent remain to be explained. Coding of different spectrotemporal features in each ear is useful not only for sound localization and tracking, but may be also applied for separation of sources while parsing natural auditory scenes (i.e., solving the “cocktail party problem”).
4.3. The Role of HRTF Structure
Spatial information is created when the sound waveform becomes convoluted with the head and pinnae filter - HRTF. By taking into account that this convolution is equivalent to addition of the log-spectral representation of the sound and the HRTF, one may conclude that the ICA recovers exact HRTF forms. A subset of basis functions learned by the ICA model from the simulated data could, in principle, contain 24 elements, which would constitute an exactly recovered set of HRTFs used to generate the training data (see Figure 1D). The other basis function subset would contain features modeling speech variability. This is, however, not the case. Firstly - in the simulated dataset - HRTFs corresponding to 24 positions were used, 10 basis functions emerged and only 8 were temporally non-modulated, as HRTFs are. Despite such dimensionality reduction, information included in the 8 basis functions was sufficient to perform the position decoding with 15° spatial resolution. This implies that binaural basis functions did not recover HRTF shapes but rather formed their compressed representation. It is important to note here that learned binaural features were much smoother and did not include all spectral detail included in HRTFs themselves (compare basis binaural basis functions from Figures 2A, 5A with HRTFs from Figure 1D). The fact that coarse spectral information suffices to perform position decoding stands in accord with human psychophysical studies. It has been demonstrated that HRTFs can be significantly smoothed without influencing human performance in spatial auditory tasks (Kulkarni and Colburn, 1998).
In humans and many other species, the area behind the listener's head is inaccessible to vision and information about the presence or motion of objects there can be obtained only by listening. This particular spatial information is of high survival value since it may inform about an approaching predator. Interestingly, in both used datasets features providing pronounced information about presence of sound sources behind the head clearly emerged (see Figures 3B, 8A). Their sensitivity to sound position quantified with Fisher information is highest for the area roughly between 160 and 230°. Since those basis functions reflect the HRTF structure, one could speculate that the outer ear shape (which determines the HRTF) was adapted to make this valubable spatial information explicit. It is interesting to think that one of the factors in pinnae evolution, was to provide spectral filters, highly informative about sound positions behind the head. This, however, can not be verified within the current setup and remains a subject of the future research.
4.4. Conclusion
Taken together, this paper demonstrates that a theoretical principle of efficient coding can explain the emergence of functionally separate neural populations. This is done using an exemplary task of binaural hearing.
In a previous work by Asari et al. (2006), it has already been shown that a sparse coding approach may be useful for monaural position decoding. Their work, however, did not show separation of spatial and identity information into two distinct channels. Additionally in contrast to this study (Asari et al., 2006), relied on simulated data which did not include patterns such as sound motion.
Learning independent components of binaural spectrograms has extracted spatially informative features. Their sensitivity to sound source position, was therefore a result of applying a general-purpose strategy. This may suggest that seemingly different neural computations may be instantiations of the same principle. For instance, it may appear that auditory neurons with spatial and spectrotemporal receptive fields must perform different computations. Current results imply that they may be sharing a common underlying design principle—efficient coding, which extracts stimulus features useful for performing probabilistic inferences about the environment.
5. Funding
This work was funded by DFG Graduate College “InterNeuro.”
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
I would like to thank Nils Bertschinger, Timm Lochmann, Philipp Benner, and Pierre Baudot for helpful discussions and proofreading of this paper.
Supplementary Material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fncom.2014.00026/abstract
Movie1.avi - a multimedia version of Figure 8.
References
Asari, H., Pearlmutter, B. A., and Zador, A. M. (2006). Sparse representations for the cocktail party problem. J. Neurosci. 26, 7477–7490. doi: 10.1523/JNEUROSCI.1563-06.2006
Barlow, H. (2001). Redundancy reduction revisited. Network 12, 241–253. doi: 10.1088/0954-898X/12/3/301
Barlow, H. B. (1961). “Possible principles underlying the transformations of sensory messages,” in Sensory Communication, ed W. A. Rosenblith (Cambridge, MA: MIT Press), 217–234.
Bell, A. J., and Sejnowski, T. J. (1997). The independent components of natural scenes are edge filters. Vision Res. 37, 3327–3338. doi: 10.1016/S0042-6989(97)00121-1
Brunel, N., and Nadal, J.-P. (1998). Mutual information, fisher information, and population coding. Neural Comput. 10, 1731–1757. doi: 10.1162/089976698300017115
Carlson, N. L., Ming, V. L., and DeWeese, M. R. (2012). Sparse codes for speech predict spectrotemporal receptive fields in the inferior colliculus. PLoS Comput. Biol. 8:e1002594. doi: 10.1371/journal.pcbi.1002594
Chechik, G., Anderson, M. J., Bar-Yosef, O., Young, E. D., Tishby, N., and Nelken, I. (2006). Reduction of information redundancy in the ascending auditory pathway. Neuron 51, 359–368. doi: 10.1016/j.neuron.2006.06.030
Christianson, G. B., Sahani, M., and Linden, J. F. (2008). The consequences of response nonlinearities for interpretation of spectrotemporal receptive fields. J. Neurosci. 28, 446–455. doi: 10.1523/JNEUROSCI.1775-07.2007
Dahmen, J. C., Keating, P., Nodal, F. R., Schulz, A. L., and King, A. J. (2010). Adaptation to stimulus statistics in the perception and neural representation of auditory space. Neuron 66, 937–948. doi: 10.1016/j.neuron.2010.05.018
Escabı, M. A., and Schreiner, C. E. (2002). Nonlinear spectrotemporal sound analysis by neurons in the auditory midbrain. J. Neurosci. 22, 4114–4131.
Gill, P., Zhang, J., Woolley, S. M., Fremouw, T., and Theunissen, F. E. (2006). Sound representation methods for spectro-temporal receptive field estimation. J. Comput. Neurosci. 21, 5–20. doi: 10.1007/s10827-006-7059-4
Greenwood, D. D. (1990). A cochlear frequency-position function for several species 29 years later. J. Acoust. Soc. Am. 87:2592. doi: 10.1121/1.399052
Grothe, B., Pecka, M., and McAlpine, D. (2010). Mechanisms of sound localization in mammals. Physiol. Rev. 90, 983–1012. doi: 10.1152/physrev.00026.2009
Harper, N., and Olshausen, B. (2011). “what” and “where” in the auditory system - an unsupervised learning approach. COSYNE 2011 Proceedings (Salt Lake City, UT).
Harper, N. S., and McAlpine, D. (2004). Optimal neural population coding of an auditory spatial cue. Nature 430, 682–686. doi: 10.1038/nature02768
Hoyer, P. O., and Hyvärinen, A. (2000). Independent component analysis applied to feature extraction from colour and stereo images. Network 11, 191–210. doi: 10.1088/0954-898X/11/3/302
Hunt, J. J., Dayan, P., and Goodhill, G. J. (2013). Sparse coding can predict primary visual cortex receptive field changes induced by abnormal visual input. PLoS Comput. Biol. 9:e1003005. doi: 10.1371/journal.pcbi.1003005
Hyvärinen, A., Hurri, J., and Hoyer, P. O. (2009). Natural Image Statistics, Vol. 39. London: Springer. doi: 10.1007/978-1-84882-491-1
International Phonetic Association. (1999). Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet. Cambridge: Cambridge University Press.
Jane, J. Y., and Young, E. D. (2000). Linear and nonlinear pathways of spectral information transmission in the cochlear nucleus. Proc. Natl. Acad. Sci. U.S.A. 97, 11780–11786. doi: 10.1073/pnas.97.22.11780
Katznelson, Y. (2004). An Introduction to Harmonic Analysis. Cambridge, UK: Cambridge University Press. doi: 10.1017/CBO9781139165372
Klein, D. J., Konig, P., and Kording, K. P. (2003). Sparse spectrotemporal coding of sounds. EURASIP J. Appl. Signal Proc. 7, 659–667. doi: 10.1155/S1110865703303051
Kulkarni, A., and Colburn, H. S. (1998). Role of spectral detail in sound-source localization. Nature 396, 747–749. doi: 10.1038/25526
Lewicki, M. S. (2002). Efficient coding of natural sounds. Nat. Neurosci. 5, 356–363. doi: 10.1038/nn831
Maier, J. K., Hehrmann, P., Harper, N. S., Klump, G. M., Pressnitzer, D., and McAlpine, D. (2012). Adaptive coding is constrained to midline locations in a spatial listening task. J. Neurophysiol. 108, 1856–1868. doi: 10.1152/jn.00652.2011
Miller, L. M., Escabí, M. A., Read, H. L., and Schreiner, C. E. (2002). Spectrotemporal receptive fields in the lemniscal auditory thalamus and cortex. J. Neurophysiol. 87, 516–527.
Olshausen, B. A., and Field, D. J. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 381, 607–609. doi: 10.1038/381607a0
Olshausen, B. A., and Field, D. J. (1997). Sparse coding with an overcomplete basis set: A strategy employed by v1? Vision Res. 37, 3311–3325. doi: 10.1016/S0042-6989(97)00169-7
Qiu, A., Schreiner, C. E., and Escabí, M. A. (2003). Gabor analysis of auditory midbrain receptive fields: spectro-temporal and binaural composition. J. Neurophysiol. 90, 456–476. doi: 10.1152/jn.00851.2002
Rehn, M., and Sommer, F. T. (2007). A network that uses few active neurones to code visual input predicts the diverse shapes of cortical receptive fields. J. Comput. Neurosci. 22, 135–146. doi: 10.1007/s10827-006-0003-9
Robles, L., and Ruggero, M. A. (2001). Mechanics of the mammalian cochlea. Physiol. Rev. 81, 1305–1352.
Roweis, S. (1998). “Em algorithms for pca and spca,” in Advances in Neural Information Processing Systems (Cambridge, MA), 626–632.
Saxe, A., Bhand, M., Mudur, R., Suresh, B., and Ng, A. (2011). “Unsupervised learning models of primary cortical receptive fields and receptive field plasticity,” in Advances in Neural Information Processing Systems (Cambridge, MA), 1971–1979.
Schnupp, J. W., and Carr, C. E. (2009). On hearing with more than one ear: lessons from evolution. Nat. Neurosci. 12, 692–697. doi: 10.1038/nn.2325
Schnupp, J. W., Mrsic-Flogel, T. D., and King, A. J. (2001). Linear processing of spatial cues in primary auditory cortex. Nature 414, 200–204. doi: 10.1038/35102568
Singh, N. C., and Theunissen, F. E. (2003). Modulation spectra of natural sounds and ethological theories of auditory processing. J. Acoust. Soc. Am. 114:3394. doi: 10.1121/1.1624067
Slee, S. J., and Young, E. D. (2013). Linear processing of interaural level difference underlies spatial tuning in the nucleus of the brachium of the inferior colliculus. J. Neurosci. 33, 3891–3904. doi: 10.1523/JNEUROSCI.3437-12.2013
Smith, E. C., and Lewicki, M. S. (2006). Efficient auditory coding. Nature 439, 978–982. doi: 10.1038/nature04485
Smith, Z. M., Delgutte, B., and Oxenham, A. J. (2002). Chimaeric sounds reveal dichotomies in auditory perception. Nature 416, 87–90. doi: 10.1038/416087a
Strutt, J. W. (1907). On our perception of sound direction. Philos. Magazine 13, 214–232. doi: 10.1080/14786440709463595
Terashima, H., and Okada, M. (2012). “The topographic unsupervised learning of natural sounds in the auditory cortex,” in Advances in Neural Information Processing Systems 25 (Cambridge, MA), 2321–2329.
Warfusel, O. (2002). Listen hrtf database. Avilable online at: http://recherche.ircam.fr/equipes/salles/listen/index.html
Keywords: efficient coding, natural sound statistics, binaural hearing, spectrotemporal receptive fields, auditory scene analysis
Citation: Młynarski W (2014) Efficient coding of spectrotemporal binaural sounds leads to emergence of the auditory space representation. Front. Comput. Neurosci. 8:26. doi: 10.3389/fncom.2014.00026
Received: 04 November 2013; Accepted: 19 February 2014;
Published online: 07 March 2014.
Edited by:
Ken Miller, Columbia University, USACopyright © 2014 Młynarski. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wiktor Młynarski, Max-Planck Institute for Mathematics in the Sciences, Inselstrasse 22, Leipzig 04123, Germany e-mail: mlynar@mis.mpg.de