Numerical Proportion Representation: A Neurocomputational Account
 Qi Chen1,2,3*
Qi Chen1,2,3*  Tom Verguts4
Tom Verguts4- 1School of Psychology, South China Normal University, Guangzhou, China
- 2Center for Studies of Psychological Application, South China Normal University, Guangzhou, China
- 3Guangdong Key Laboratory of Mental Health and Cognitive Science, South China Normal University, Guangzhou, China
- 4Department of Experimental Psychology, Ghent University, Ghent, Belgium
Proportion representation is an emerging subdomain in numerical cognition. However, its nature and its correlation with simple number representation remain elusive, especially at the theoretical level. To fill this gap, we propose a gain-field model of proportion representation to shed light on the neural and computational basis of proportion representation. The model is based on two well-supported neuroscientific findings. The first, gain modulation, is a general mechanism for information integration in the brain; the second relevant finding is how simple quantity is neurally represented. Based on these principles, the model accounts for recent relevant proportion representation data at both behavioral and neural levels. The model further addresses two key computational problems for the cognitive processing of proportions: invariance and generalization. Finally, the model provides pointers for future empirical testing.
Introduction
Numerical processing is an important cognitive capacity across a variety of animal species. Accordingly, it is a topic of great interest in recent cognitive neuroscience and psychology, studied with methodologies as diverse as single-cell recording (Nieder and Miller, 2004), neuroimaging (Piazza et al., 2004), and developmental paradigms (Xu et al., 2005). Many studies focus on simple (i.e., single-variable) quantity representation, for example the number of objects in a set (Nieder and Miller, 2003) or the length of a line (Tudusciuc and Nieder, 2007). However, ratios of quantities (proportions, where two variables are combined) are an important and emerging field of study (Kallai and Tzelgov, 2009; Ganor-Stern et al., 2011; Holmin and Norman, 2012; Siegler et al., 2013). One recurring finding here is that the classical distance effect from numerical cognition (Moyer and Landauer, 1967) is also robustly observed for proportions (Schneider and Siegler, 2010). Another relevant finding is that this distance effect tends to be approximately symmetrical (Vallentin and Nieder, 2008). However, the mechanistic interpretation of these data has remained unclear. Computational model can help us integrate these data in a computational framework and make novel experimental predictions. Unfortunately, there are as yet no computational proposals on how such ratios are processed. Such a proposal is the content of the current paper.
On a computational level, learning and representing proportions (either non-symbolic or symbolic) involve two core computational properties. The first is the invariance property (Salinas and Abbott, 1997). This means that both humans and non-human animals can represent abstract length proportions, and ignore the exact length of two lines. For example, they can represent the proportion 1:4 for different combinations of line length (e.g., 1 cm vs. 4 cm and 2 cm vs. 8 cm). Using fMRI adaptation paradigm with healthy subjects, Jacob and Nieder (2009) found clear evidence to support this invariance property of proportion representation. The second is the generalization property. This means that after learning, both humans and non-human animals can generalize learned proportions to novel proportions. In a recent study (Vallentin and Nieder, 2008), macaques were trained on length proportions between two lines (1:4, 2:4, 3:4, and 4:4). Remarkably, precision was the same for the trained proportions (e.g., 1:4, 2:4, 3:4, and 4:4) and transfer proportions (e.g., 3:8 and 5:8). As noted by the authors of that study, this suggests that the animals had a conceptual understanding of abstract proportions.
A series of recent studies (for review, see Jacob et al., 2012; Siegler et al., 2013) begin to shed light on the neural basis of proportion representation and these two computational problems. To investigate the neuronal code of proportions, Vallentin and Nieder (2008, 2010) recorded electrophysiological data from cells in the frontal and parietal cortex of behaving rhesus monkeys in a delayed match-to-sample task, in which monkeys matched sample and test proportions, defined by the ratio of the length of two lines. Approximately, 30% of the prefrontal cortex (PFC) neurons and approximately 16% of inferior parietal cortex neurons encoded one of the trained proportions. These neurons code magnitude proportion information with unimodal tuning curves, characterized by a maximum firing rate for a specific proportion and decreasing as the distance from this preferred ratio increased. This coding mechanism, called place code (Verguts and Fias, 2004) or labeled line code (Nieder and Merten, 2007) is also used for simple magnitude representation (Nieder and Miller, 2003).
Whereas there are several computational models about simple quantity representation (Dehaene and Changeux, 1993; Grossberg and Repin, 2003; Stoianov and Zorzi, 2012), no attempts have been made to exploring ratios of quantities (proportions and fractions) computationally. To fill this gap, here we propose a gain-field model for proportions. This model is based on two recent neuroscientific findings. The first is gain modulation, which is a ubiquitous mechanism for information integration in the mammalian brain (Salinas and Bentley, 2009). Salinas and colleagues (Salinas and Thier, 2000; Abbott, 2005) have pointed out that different types of information can be integrated by multiplicative gain modulation, which is implemented by radial basis function neurons, at the neural level. A well-known example is that different spatial representations are mapped on radial basis function neurons in parietal cortex, and transformation on the original spatial representations is implemented by projections from the radial basis function neurons to different spatial representations. This theory is supported by much neurophysiological evidence (Pouget and Snyder, 2000). An example is the transformation from visual information in eye-centered coordinates to head-centered coordinates, which is useful for correctly turning the head toward a seen object. For this spatial transformation, the response profile of radial basis function neurons in parietal cortex can be modeled by a product of retinotopic position and eye position receptive fields (Pouget and Sejnowski, 1997). Modeling studies have shown that gain modulation can also support many other cognitive tasks, including: arbitrary sensory-motor remapping (Salinas, 2004), generation of motor sequences (Salinas, 2009), serial order representation (Botvinick and Watanabe, 2007), and elementary arithmetic (Chen and Verguts, 2012). In this study, we apply this well-motivated and ubiquitous framework to proportion representation.
The second relevant neuroscientific finding on which our model is based, is how simple quantity is represented. Recent studies in non-human animals and humans using diverse methodologies have provided detailed answers to this problem (for review, see Nieder and Dehaene, 2009). Representation of simple quantity is instantiated by a distinct set of place coding neurons in regions of the prefrontal and posterior lobes, each tuned maximally to a specific number, with approximately Gaussian tuning curves when plotted on a logarithmic axis (Nieder and Miller, 2003). Importantly, neuronal population coding of continuous quantity (line length) in the primate posterior parietal cortex uses the same coding mechanism (Tudusciuc and Nieder, 2007).
In the present study, we integrate these two findings into a model for proportion representation. In the following, we first describe the model in detail, then report a series of simulation studies, and conclude by a General Discussion.
Materials and Methods
Network Architecture
The model architecture is shown in Figure 1. Its core is a three-layer feedforward structure, consisting of 60 input, 900 hidden, and 8 output neurons.
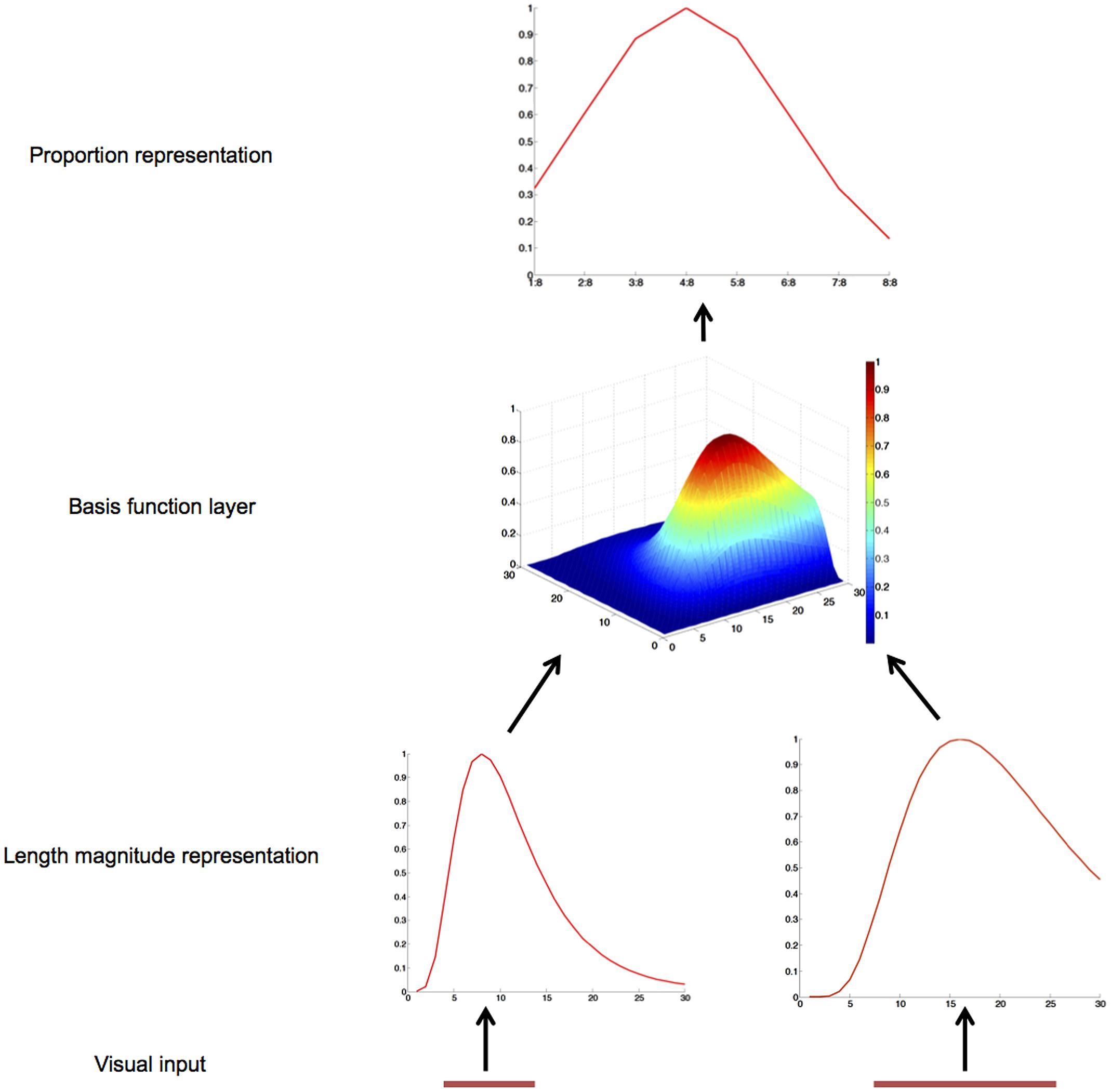
FIGURE 1. Schematic diagram and operation of the gain-field model of proportion representation. The two operands of a proportion problem, the length of two lines, are mapped onto two length magnitude representation layers. The basis function layer combines these two inputs and sends activation to the proportion representation layer.
There are two groups of 30 input neurons, one for the length of each line (Vallentin and Nieder, 2008). Presentation of a line to such an input layer results in a logarithmically compressed Gaussian activation curve (Tudusciuc and Nieder, 2007). In particular, each input neuron is maximally activated by a preferred length, p, and the activation value of each input neuron is based on the logarithmic distance between this preferred length and the actual length, s, according to a Gaussian function (see Figure 1):
where Rp(s) is the activation of the neuron with preferred length p for a target length s (Botvinick and Watanabe, 2007). Note that lns - lnp = ln(s/p), so even at the simple number representation level a ratio is calculated, although its calculation is different from neurons in the hidden layer.
Each neuron in the hidden layer receives input from a unique combination of one neuron from each of the two layers of input neurons, so the hidden layer comprises 900 basis function neurons. The activation value of a hidden layer neuron equals the product of its input neurons’ activation values:
where Hj is the activation of the hidden unit receiving input from two input neurons from the two groups, with preferred length x and y, respectively.
To simulate the target data from Vallentin and Nieder (2008) where eight proportions were used, our output layer also has eight neurons. At this output layer, there is one neuron for each proportion (1:8, 2:8, 3:8, 4:8, 5:8, 6:8, 7:8, and 8:8). Every output neuron receives inputs from all hidden neurons as follows:
where wij represents the synaptic connection weight from hidden neuron j to output neuron i.
Simulation
The weights between the hidden layer and the output layer are trained such that they minimize the average squared error between intended and actual responses. These weights are initially set to random values. Input pairs with corresponding targets are presented in random order, and after each training trial the weights are updated by the delta learning rule:
where α is the learning rate, and Ti is the target value for output neuron i. We define the target T as a Gaussian function curve across the output layer (with standard deviation 0.3). One motivation for this target setting is the fact that the neuronal population tuning curve can be fitted with a Gaussian function with standard deviation about 0.3 (reported in Vallentin and Nieder, 2008; Figure 2A). See a recent study (Weisswange et al., 2011) for a similar approach in their model of Bayesian cue integration and causal inference. To mimic the setting of Vallentin and Nieder (2008), four proportions are trained: 1:4, 2:4, 3:4, and 4:4. Each is specified by three concrete training examples (different line length combinations) so there are 12 training pairs. The learning rate is 0.01 for all simulations. The model was tested 10 times, with 20000 training trials in each replication. The results are averaged across the 10 replications.
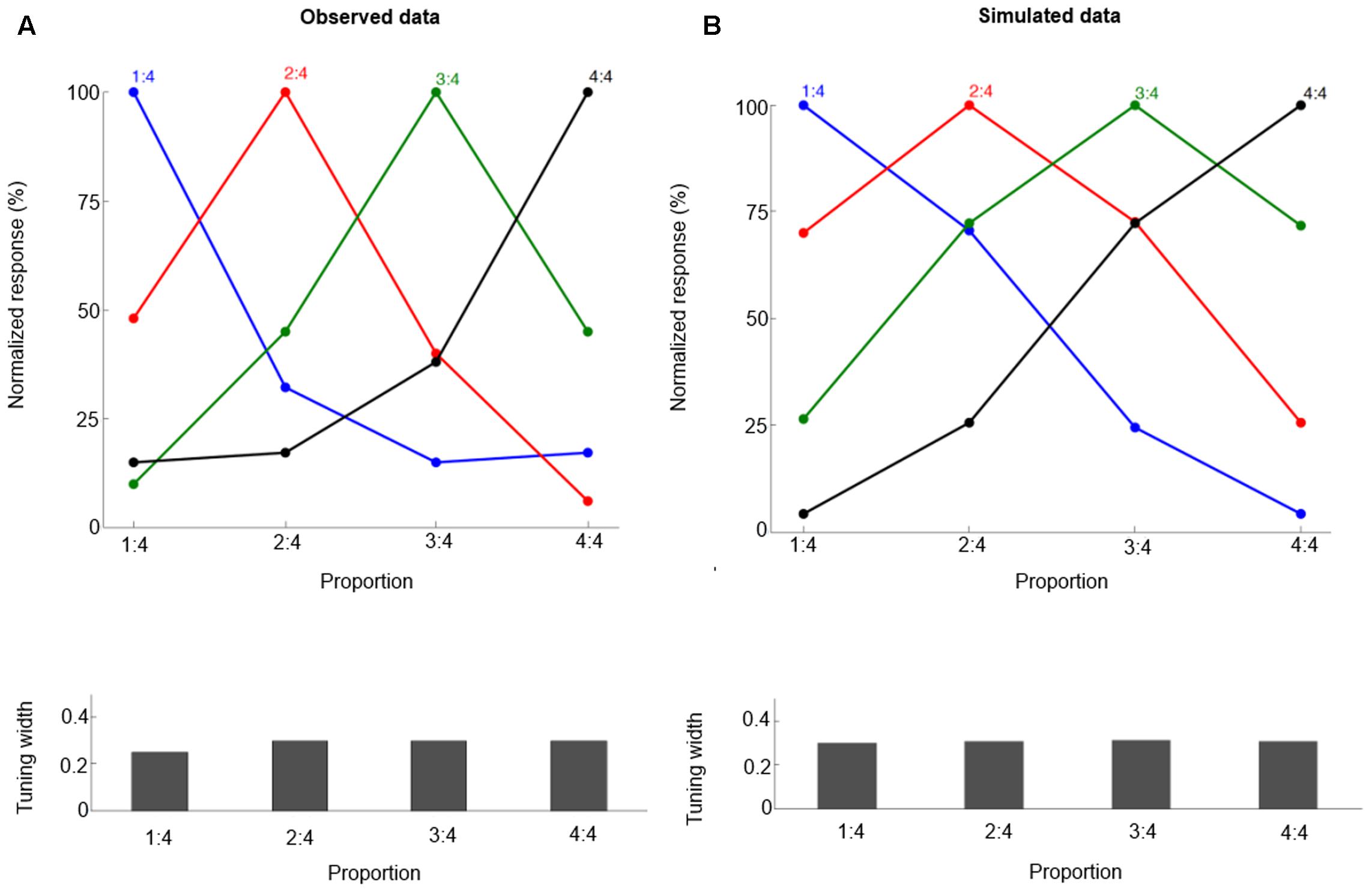
FIGURE 2. The neural tuning curve properties for proportions 1:4, 2:4, 3:4, and 4:4. Each curve is for neurons tuned to a specific proportion, and the labels on the X-axis are for specific proportions that are presented. Observed data (A, from Vallentin and Nieder, 2008) and simulated data (B). The normalized tuning functions are plotted relative to the preferred proportion. Bottom panels show the standard deviation values (Tuning width) for each tuning curve.
We follow the method of Vallentin and Nieder (2008) and fit the neuronal population tuning curve with a Gaussian function. For all proportions, the goodness of fit (r2) of the Gaussian function is determined, and the tuning curves’ standard deviation value (the half-bandwidth of the fitted Gaussian function) is derived.
To test the model’s performance for the delayed match-to-sample task, we transform the neuronal population response (Figure 2B) into behavioral performance (Figure 3B). The macaques are trained to perform a delayed match-to-sample task, in which they matched sample and test proportions, defined by the ratio of the length of two lines, in order to obtain reward. For simplicity, here we use an intuitive way to calculate the probability of responding ‘same’ [for a more elaborate and complex expression based on Signal Detection Theory and Bayesian decision, see (Dehaene, 2007); for a more detailed neural model, see Engel and Wang, 2011]. It is given by
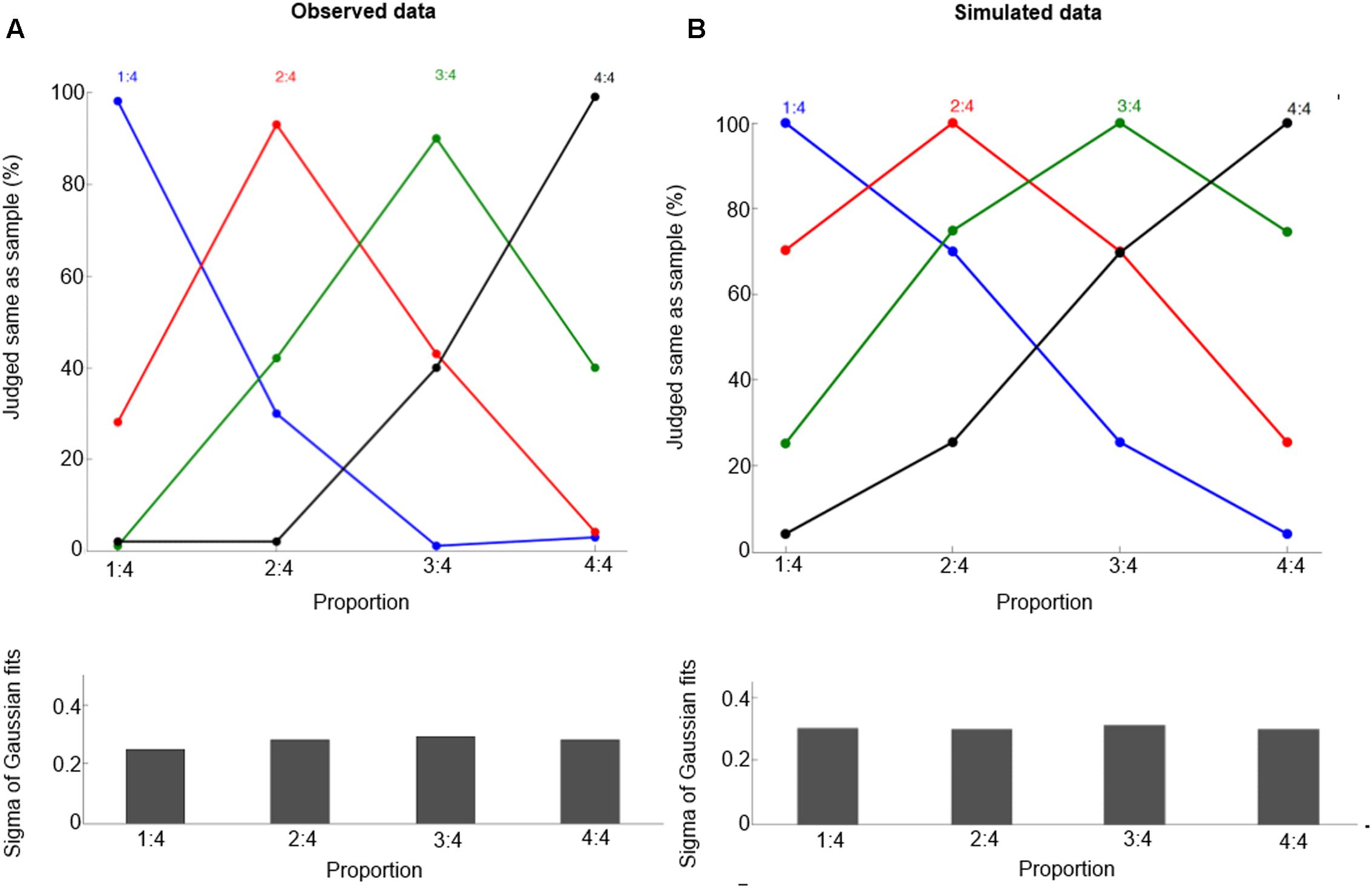
FIGURE 3. Behavioral performance for proportions 1:4, 2:4, 3:4, and 4:4. Observed data (A, from Vallentin and Nieder, 2008) and simulated data (B). These curves show the percentage of trials in which one judged sample and test displays containing the same proportion, and the curves refer to the preferred proportions. Bottom panels show half bandwidth (Sigma of Gaussian fits) of the Gaussian functions fitted to behavioral performance curves.
where on2(n1) is the activation of the neuron with preferred proportion n2 when a proportion n1 and on1(n1) is the activation of the neuron with preferred proportion n1 when a proportion n1. Furthermore, we use this equation for calculating the probability of responding ‘same,’ and evaluate the goodness of fit of a Gaussian function. The goodness (r2) is determined, and the standard deviation (the half-bandwidth of the fitted Gaussian function) is derived. Note that Eq. (5) is just the simplest way to create a probability Psame(n1,n2) that is a monotonic function of the distance |n1 - n2| based on the model output; future work should also consider whether the model can capture trial-to-trial variability in this task.
Results
After training, our model can produce correct proportion representation. Representative simulated neural tuning curves are shown in Figure 2B. The goodness of fit of a Gaussian function is approximately 1. These neurons code proportion information with unimodal tuning curves, characterized by a maximum firing rate for a specific proportion independent of the particular numbers making up the proportion (invariance property). This is consistent with single-cell data (Figure 2A, Vallentin and Nieder, 2008). The simulated tuning curves’ standard deviation (tuning width) is about 0.3. The tuning width changes with different ratios, although this effect is subtle (as in the empirical data). One departure from observed data is that in the simulation there is no clearly narrower tuning for 1:4 than for the other proportions. Also the simulated behavioral performance is comparable to macaques’ performance (compare Figures 3A and 3B, the mean goodness of fit of a Gaussian function is again approximately 1). Furthermore, our model clearly shows a distance effect (see Figure 3B). For example, the percentage of trials in which 2:4 is judged the same as sample 3:4 is higher than the percentage of trials in which 1:4 is judged the same as sample 3:4.
To check whether our model can generalize from learned to novel proportions, we test our model on 3:8 and 5:8. Like macaques (Figure 4A), our model can respond appropriately to 3:8 and 5:8, as shown in Figure 4B (mean r2 = 0.99). Thus, our model is able to generalize based on its basis function layer and place coding representation. These two properties entail that similar representations are trained similarly, so training target proportions (e.g., 1:4, 2:4, 3:4, and 4:4) implicitly also trains similar proportions (e.g., 3:8 and 5:8).
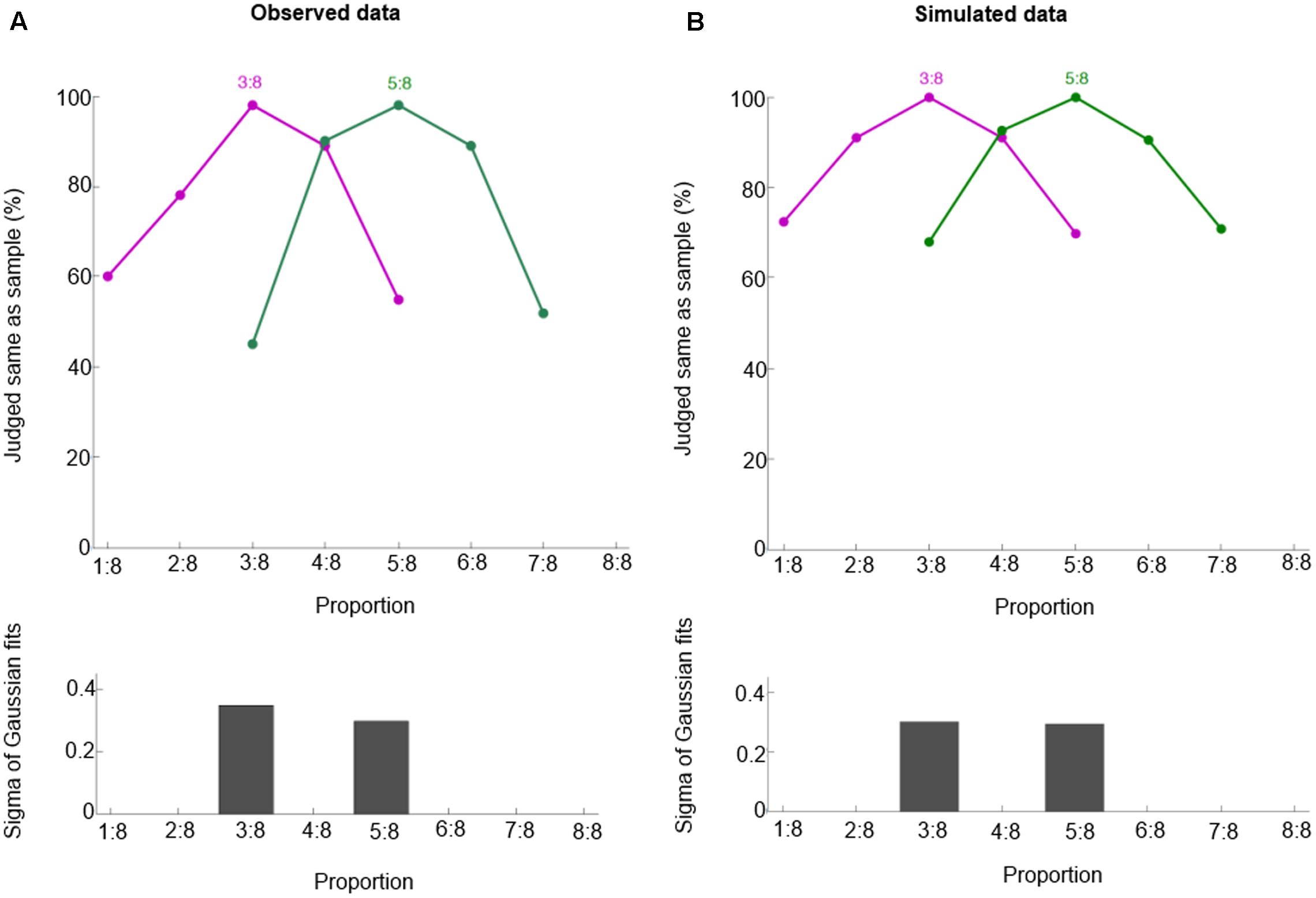
FIGURE 4. Behavioral performance for proportions 3:8 and 5:8. Observed data (A, from Vallentin and Nieder, 2008) and simulated data (B). These curves show the percentage of trials in which one judged sample and test displays containing the same proportion. Bottom panels show half bandwidth of the Gaussian functions fitted to behavioral performance curves.
Discussion
Based on two well-evidenced neuroscientific findings (gain modulation coding and neural coding of simple number), we proposed a novel model to account for recent findings of proportion representation. The model also provides a minimal computational framework to solve two key computational problems for proportion representation: invariance and generalization. Our model is of the connectionist variety. The connectionist approach is to model cognition based on the idea that the knowledge underlying cognitive activity is stored in the connections (weights) among neurons (McClelland et al., 2010). In particular, we used the basis function framework, in which input-to-hidden connections are fixed, and hidden units respond to a restricted part of the two input spaces. This allows constructing a powerful model, in combination with a simple (hidden-to-output, delta) learning rule. We have used this computational framework in earlier work to model elementary arithmetic (Chen and Verguts, 2012), where two numerical representations are combined together. The current study can thus be considered an extension of our previous work (Chen and Verguts, 2012). The study is consistent with our general approach to instantiate core computational principles as simply as possible, thus to investigate which principles are sufficient to account for numerical cognition.
One possible departure from neurobiology is that the hidden layer was much bigger than the input layers. However, this simplification is well-motivated. First, the current input layer only represents a simplified approximation to the actual input. Second, in reality the hidden layer probably approximates the required input-output function with a less extensive set of basis function (Botvinick and Watanabe, 2007). We performed additional simulations with less basis functions. This led to very similar results.
The model can help addressing two core questions about proportion representation. The first is how the analog code for proportions is constructed (Jacob et al., 2012). According to our model, individual components of a proportion (for example, the length of two lines) are mapped onto two length magnitude representation layers. The basis function layer combines these two inputs and sends activation to the proportion representation layer. In this sense, proportions are represented at the apex of the processing hierarchy; different neurons encode either simple magnitude or proportions separately, and these two kinds of neurons are linked by basis function neurons. Both simple magnitude and proportion neurons have been found in the same cortical regions [e.g., bilaterally in the intraparietal sulcus (IPS) and lateral PFC (Vallentin and Nieder, 2008, 2010)]. The model predicts that these basis function neurons for proportion representations can also be found in the same cortical regions. Such basis function neurons would be maximally tuned to a specific combination of line lengths, with approximately two-dimension Gaussian tuning curves when plotted on a logarithmic axis (see Basis function layer in Figure 1). Furthermore, the model also predicts that there are both invariant and variant proportion cells. On the one hand, in the proportion representation layer, cells respond to any pair with one specific proportion (e.g., 1:2). On the other hand, in the basis function layer, cells only respond to specific pairs (e.g., 2 cm: 4 cm, only for a particular combination of line length). In their data analysis, Vallentin and Nieder (2008) only included invariant cells. However, there is some suggestion that variant neurons occur in the data. Indeed a substantial number of neurons (16%) show a proportion × protocol interaction (Vallentin and Nieder, 2008), suggesting that they selectively respond to some quantitative combinations (e.g., 1:2 with quantities 1 and 2) but not others (e.g., 1:2 with quantities 2 and 4). A followup investigation or reanalysis of the data from (Vallentin and Nieder, 2008) may reveal whether such variant cells (basis function neurons) indeed exist and whether (as we predict) the variant cells are activated slightly earlier than the invariant ones.
The second core question concerns the componential vs. analog (holistic) representation of proportions. Single-cell recording from macaques (Vallentin and Nieder, 2008, 2010) and neuroimaging studies with human adults using the adaptation paradigm (Jacob and Nieder, 2009) strongly favor holistic (place coding) representations of proportion. In contrast, a lot of behavioral studies with human participants and symbolic proportions (i.e., fraction) clearly support componential representation (Meert et al., 2010). Our model provides a unified explanation for both componential and holistic representation of proportion: the simple magnitude representations (Figure 1) can be considered as the neural base for componential representation, and place coding of proportion representation in the output layer as neural base for holistic representation. In this sense, our model implies that componential and holistic representations occur simultaneously.
Until now, we applied our computational model to continuous proportions. However, the same computational model principle and structure can be applied to discrete ratios (e.g., ratio of two vs. five balls). In our opinion, the difference between continuous and discrete ratio architectures resides in the input (to the model). For continuous ratios, the input layer represents continuous quantities (e.g., length); for discrete ratios, the input layer represents discrete quantities (number of balls in the example). Furthermore, our model can be generalized to explain symbolic proportions (fractions). Again, the concept of fractions encounters the same key computational problems of invariance and generalization, and can be addressed by a similar model with different input layers. This can partly explain why it is more difficult to deal with fractions than natural numbers for children (Siegler et al., 2011, 2013). To correctly name and deal with fractions, the numerator and denominator need to be combined (Jacob et al., 2012).
Our model resembles exemplar models of categorization (Kruschke, 1992; Love et al., 2004) and visual object recognition (Riesenhuber and Poggio, 1999, 2000). In particular, the hidden layer combines and integrate different pieces of information in a non-linear manner and sends activation to the output layer (e.g., category or object representation layer). This similarity is no coincidence because categorization and visual object recognition encounter very similar challenges of invariance and generalization, both of which are very well-handled by the basis function model architecture.
Conclusion
We propose that a gain-field model accounts for extant data concerned with proportion representation. This theory has several advantages: it is computationally implemented, its neural underpinnings are beginning to be known (Jacob et al., 2012), and it provides some testable predictions.
Author Contributions
QC and TV developed the study concept and contributed to the study design; computer simulation was performed by QC; the data analysis and interpretation was performed by QC and TV; QC and TV wrote the manuscript.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This research was supported by grants from the Natural Science Foundation of China (Grant 31300834 and 31671135 to QC), the Special Innovation Project of Guangdong Province Universities and Colleges (Grant 2014WTSCX019 to QC), and the Guangdong Province Universities and Colleges Pearl River Scholar Funded Scheme (2016) to QC.
References
Abbott, L. (2005). “Where are the switches on this thing,” in 23 Problems in Systems Neuroscience, eds J. L. van Hemmen and T. J. Sejnowski (Oxford: Oxford University Press), 423–431.
Botvinick, M., and Watanabe, T. (2007). From numerosity to ordinal rank: a gain-field model of serial order representation in cortical working memory. J. Neurosci. 27, 8636–8642. doi: 10.1523/JNEUROSCI.2110-07.2007
Chen, Q., and Verguts, T. (2012). Spatial intuition in elementary arithmetic: a neurocomputational account. PLoS ONE 7:e31180. doi: 10.1371/journal.pone.0031180
Dehaene, S. (2007). “Symbols and quantities in parietal cortex: elements of a mathematical theory of number representation and manipulation,” in Attention Performance XXII. Sensori-Motor Foundations of Higher Cognition, eds P. Haggard and Y. Rossetti (Cambridge, MA: Harvard University Press), 527–574.
Dehaene, S., and Changeux, J. (1993). Development of elementary numerical abilities: a neuronal model. J. Cogn. Neurosci. 5, 390–407. doi: 10.1162/jocn.1993.5.4.390
Engel, T. A., and Wang, X.-J. (2011). Same or different? A neural circuit mechanism of similarity-based pattern match decision making. J. Neurosci. 31, 6982–6996. doi: 10.1523/JNEUROSCI.6150-10.2011
Ganor-Stern, D., Karasik-Rivkin, I., and Tzelgov, J. (2011). Holistic representation of unit fractions. Exp. Psychol. 58, 201–206. doi: 10.1027/1618-3169/a000086
Grossberg, S., and Repin, D. V. (2003). A neural model of how the brain represents and compares multi-digit numbers: spatial and categorical processes. Neural Netw. 16, 1107–1140. doi: 10.1016/S0893-6080(03)00193-X
Holmin, J. S., and Norman, J. F. (2012). Aging and weight-ratio perception. PLoS ONE 7:e47701. doi: 10.1371/journal.pone.0047701
Jacob, S. N., and Nieder, A. (2009). Notation-independent representation of fractions in the human parietal cortex. J. Neurosci. 29, 4652–4657. doi: 10.1523/JNEUROSCI.0651-09.2009
Jacob, S. N., Vallentin, D., and Nieder, A. (2012). Relating magnitudes: the brain’s code for proportions. Trends Cogn. Sci. 16, 157–166. doi: 10.1016/j.tics.2012.02.002
Kallai, A. Y., and Tzelgov, J. (2009). A generalized fraction: an entity smaller than one on the mental number line. J. Exp. Psychol. Hum. Percept. Perform. 35, 1845–1864. doi: 10.1037/a0016892
Kruschke, J. K. (1992). ALCOVE: an exemplar-based connectionist model of category learning. Psychol. Rev. 99, 22–44. doi: 10.1037/0033-295X.99.1.22
Love, B. C., Medin, D. L., and Gureckis, T. M. (2004). SUSTAIN: a network model of category learning. Psychol. Rev. 111, 309–332. doi: 10.1037/0033-295X.111.2.309
McClelland, J. L., Botvinick, M. M., Noelle, D. C., Plaut, D. C., Rogers, T. T., Seidenberg, M. S., et al. (2010). Letting structure emerge: connectionist and dynamical systems approaches to cognition. Trends Cogn. Sci. 14, 348–356. doi: 10.1016/j.tics.2010.06.002
Meert, G., Grégoire, J., and Noël, M.-P. (2010). Comparing 5/7 and 2/9: adults can do it by accessing the magnitude of the whole fractions. Acta Psychol. 135, 284–292. doi: 10.1016/j.actpsy.2010.07.014
Moyer, R. K., and Landauer, T. K. (1967). Time required for judgements of numerical inequality. Nature 215, 1519–1520. doi: 10.1038/2151519a0
Nieder, A., and Dehaene, S. (2009). Representation of number in the brain. Annu. Rev. Neurosci. 32, 185–208. doi: 10.1146/annurev.neuro.051508.135550
Nieder, A., and Merten, K. (2007). A labeled-line code for small and large numerosities in the monkey prefrontal cortex. J. Neurosci. 27, 5986–5993. doi: 10.1523/JNEUROSCI.1056-07.2007
Nieder, A., and Miller, E. K. (2003). Coding of cognitive magnitude: compressed scaling of numerical information in the primate prefrontal cortex. Neuron 37, 149–157. doi: 10.1016/S0896-6273(02)01144-3
Nieder, A., and Miller, E. K. (2004). A parieto-frontal network for visual numerical information in the monkey. Proc. Natl. Acad. Sci. U.S.A. 101, 7457–7462. doi: 10.1073/pnas.0402239101
Piazza, M., Izard, V., Pinel, P., Le Bihan, D., and Dehaene, S. (2004). Tuning curves for approximate numerosity in the human intraparietal sulcus. Neuron 44, 547–555. doi: 10.1016/j.neuron.2004.10.014
Pouget, A., and Sejnowski, T. (1997). Spatial transformations in the parietal cortex using basis functions. J. Cogn. Neurosci. 9, 222–237. doi: 10.1162/jocn.1997.9.2.222
Pouget, A., and Snyder, L. H. (2000). Computational approaches to sensorimotor transformations. Nat. Neurosci. 3(Suppl.), 1192–1198. doi: 10.1038/81469
Riesenhuber, M., and Poggio, T. (1999). Hierarchical models of object recognition in cortex. Nat. Neurosci. 2, 1019–1025. doi: 10.1038/14819
Riesenhuber, M., and Poggio, T. (2000). Models of object recognition. Nat. Neurosci. 3(Suppl.), 1199–1204. doi: 10.1038/81479
Salinas, E. (2004). Fast remapping of sensory stimuli onto motor actions on the basis of contextual modulation. J. Neurosci. 24, 1113–1118. doi: 10.1523/JNEUROSCI.4569-03.2004
Salinas, E. (2009). Rank-order-selective neurons form a temporal basis set for the generation of motor sequences. J. Neurosci. 29, 4369–4380. doi: 10.1523/JNEUROSCI.0164-09.2009
Salinas, E., and Abbott, L. F. (1997). Invariant visual responses from attentional gain fields. J. Neurophysiol. 77, 3267–3272.
Salinas, E., and Bentley, N. M. (2009). “Gain modulation as a mechanism for switching reference frames, tasks, and targets,” in Coherent Behavior in Neuronal Networks, eds K. Josic, J. Rubin, M. Matias, and R. Romo (New York, NY: Springer), 121–142.
Salinas, E., and Thier, P. (2000). Gain modulation: a major meeting report computational principle of the central nervous system. Neuron 27, 15–21. doi: 10.1016/S0896-6273(00)00004-0
Schneider, M., and Siegler, R. S. (2010). Representations of the magnitudes of fractions. J. Exp. Psychol. Hum. Percept. Perform. 36, 1227–1238. doi: 10.1037/a0018170
Siegler, R. R. S., Thompson, C. C. A., and Schneider, M. (2011). An integrated theory of whole number and fractions development. Cogn. Psychol. 62, 273–296. doi: 10.1016/j.cogpsych.2011.03.001
Siegler, R. S., Fazio, L. K., Bailey, D. H., and Zhou, X. (2013). Fractions: the new frontier for theories of numerical development. Trends Cogn. Sci. 17, 13–19. doi: 10.1016/j.tics.2012.11.004
Stoianov, I., and Zorzi, M. (2012). Emergence of a “visual number sense” in hierarchical generative models. Nat. Neurosci. 15, 194–196. doi: 10.1038/nn.2996
Tudusciuc, O., and Nieder, A. (2007). Neuronal population coding of continuous and discrete quantity in the primate posterior parietal cortex. Proc. Natl. Acad. Sci. U.S.A. 104, 14513–14518. doi: 10.1073/pnas.0705495104
Vallentin, D., and Nieder, A. (2008). Behavioral and prefrontal representation of spatial proportions in the monkey. Curr. Biol. 18, 1420–1425. doi: 10.1016/j.cub.2008.08.042
Vallentin, D., and Nieder, A. (2010). Representations of visual proportions in the primate posterior parietal and prefrontal cortices. Eur. J. Neurosci. 32, 1380–1387. doi: 10.1111/j.1460-9568.2010.07427.x
Verguts, T., and Fias, W. (2004). Representation of number in animals and humans: a neural model. J. Cogn. Neurosci. 16, 1493–1504. doi: 10.1162/0898929042568497
Weisswange, T. H., Rothkopf, C. A., Rodemann, T., and Triesch, J. (2011). Bayesian cue integration as a developmental outcome of reward mediated learning. PLoS ONE 6:e21575. doi: 10.1371/journal.pone.0021575
Keywords: numerical cognition, numerical proportion representation, computational modeling, gain-field model, invariance and generalization
Citation: Chen Q and Verguts T (2017) Numerical Proportion Representation: A Neurocomputational Account. Front. Hum. Neurosci. 11:412. doi: 10.3389/fnhum.2017.00412
Received: 20 June 2017; Accepted: 31 July 2017;
Published: 14 August 2017.
Edited by:
Xiaolin Zhou, Peking University, ChinaCopyright © 2017 Chen and Verguts. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qi Chen, chen.qi@m.scnu.edu.cn