Exploring fMRI Results Space: 31 Variants of an fMRI Analysis in AFNI, FSL, and SPM
 Ruth Pauli
Ruth Pauli Alexander Bowring
Alexander Bowring Richard Reynolds2
Richard Reynolds2  Gang Chen
Gang Chen Thomas E. Nichols
Thomas E. Nichols Camille Maumet
Camille Maumet- 1Warwick Manufacturing Group, University of Warwick, Coventry, UK
- 2Scientific and Statistical Computing Core, National Institute of Mental Health, National Institutes of Health, Bethesda, MD, USA
- 3Department of Statistics, University of Warwick, Coventry, UK
Background
Data sharing is becoming a priority in functional Magnetic Resonance Imaging (fMRI) research, but the lack of a standard format for shared data is an obstacle (Poline et al., 2012; Poldrack and Gorgolewski, 2014). This is especially true for information about data provenance, including auxiliary information such as participant characteristics and task descriptions. The three most commonly used analysis software packages [AFNI1 (Cox, 1996), FSL2 (Jenkinson et al., 2012), and SPM3 (Penny et al., 2011)] broadly conduct the same analysis, but differ in how fundamental concepts are described, and have a myriad of differences in the pre-processing and modeling steps. The practical consequence is that sharing analyzed data is further complicated by the idiosyncrasies of the particular software used.
The Neuroimaging Data Model [NIDM4 (Keator et al., 2013; Maumet et al., 2016)] is an initiative from the International Neuroinformatics Coordinating Facility (INCF5) that addresses these practical barriers through the development of a standard format for neuroimaging data. Ultimately, NIDM will provide a standard format that can handle data that has been processed in any of the common software packages. In order to achieve this, the development of NIDM requires publicly available derived data that covers all the major use cases in the main software programs.
The purpose of the current work was to produce a set of results of mass univariate fMRI analyses using the most common software packages: AFNI, FSL, and SPM [which between them cover 80% of published fMRI analyses (Carp, 2012)], utilizing publicly available data from OpenfMRI6 (Poldrack et al., 2013). The analyses (‘variants’) presented in this paper cover the most common options available in each software package at each analysis stage, from different Hemodynamic response function (HRF) basis functions through to group-level tests. The tests are arranged so that readers can compare the closest equivalent variants across software packages. In particular, these tests will be useful for comparing the results from default test settings across software packages.
While this collection of analyses was chosen for their relevance to the NIDM project, it also addresses a gap in the literature where publicly available processed data is concerned. Specifically, while there are published comparisons of different processing pipelines, the data are not publicly available (Carp, 2012) or are for resting state fMRI only (Bellec et al., 2016). Others have shared raw data but lack analysis results (Hanke et al., 2014) or do not include comparisons across multiple software packages [e.g., analyses in the The Human Connectome Project7 (Van Essen et al., 2013) are performed with FSL only]. Shared raw data is a useful resource, but we argue that shared processed data is also important, both to provide a basis of cross-software comparisons and to create a benchmark for testing of automated provenance software. The dataset presented in this paper is a contribution toward this omission in the literature.
Methods
Data Source
Data were downloaded from OpenfMRI’s BIDS-compliant ds000011 dataset8 between 09/02/2016 and 15/02/2016. A full description of the paradigm is in the original paper (Foerde et al., 2006). The first task was a training exercise in which participants counted high tones in a series of high-pitched and low-pitched tones (‘tone counting’ condition), and then selected a number that represented the number of high tones (the ‘tone counting probe’ condition, referred to as ‘probe’ hereafter). We modeled both the tone counting and probe conditions, using tone counting as the effect of interest ([1 0] contrast with implicit baseline). Single-subject tests were conducted with data from subject 01 only, while group-level tests were run with all 14 subjects. Analyses were conducted in AFNI, SPM12, and FSL.
In AFNI, single-subject variants were conducted using the uber_subject.py interface, which generates and runs two scripts: cmd.ap.sub_001 and proc.sub_001. Other variants did not require changing options in the interface, so were run directly from the command line, using a copy of the default cmd.ap.sub_001 script. Scripts for group-level tests were created manually.
For each of the SPM variants, a batch.m file conducting the full analysis (using dependencies across processing steps) was created and run with the Batch Editor GUI.
FSL-specific variants were modeled using FSL’s FMRI Expert Analysis Tool9, where a.fsf file for the complete analysis was created using the FEAT GUI.
Pre-defined Settings
In this section, settings held constant over variants (e.g., drift modeling) are described for each of the packages. These pre-defined settings (including pre-processing) were identical for each variant.
Pre-processing
As slice-time information was not available for this study, this step was not considered in the pre-processing.
In AFNI, pre-processing was conducted using the default settings in the AFNI uber_subject.py graphical interface. First, the BOLD images were rigidly aligned to the skull-stripped anatomical T1-weighted image using a negative local correlation cost function. Next, the anatomical image was registered to standard space using the AFNI default ‘Colin brain’ (TT_N27+tlrc) Talairach space template (Holmes et al., 1998) with an affine transformation and weighted least squares cost function. Head motion correction was performed by rigid body registration of each BOLD volume to the third volume, also using weighted least squares cost function; all three transformations were concatenated to allow a single resampling with cubic interpolation. In addition, volumes presenting an estimated motion greater than 0.3 mm (as estimated at 85% of the distance to the cortical envelope10) compared to the previous scan were censored from the first level regression. The BOLD images were smoothed with a 4 mm Full Width at Half Maximum (FWHM) Gaussian smoothing kernel, and each voxel was scaled to have a mean value of 100 across the run with values larger than 200 truncated to that value.
In FSL, pre-processing was conducted using the Brain Extraction Tool (BET)11 and the default options of the FEAT GUI. First, the anatomical image was skull-stripped. To correct for motion, each volume from the BOLD images was first registered rigidly to the middle volume using a normalized correlation cost function and linear interpolation (MCFLIRT12 tool). After 6 mm FWHM spatial smoothing and global scaling to set median brain intensity to 10,000, first level fMRI model fitting took place in the subject space. The mean realigned fMRI data was rigidly registered to the brain extracted anatomical image using a correlation ratio cost function, followed by affine registration of the anatomical to MNI space (as defined by the ICBM MNI 152 non-linear 6th generation template image), also with correlation ratio cost function. For group or second level fMRI modeling, the preceding registration parameters were composed to directly resample first level contrast estimates and their variance into standard space with trilinear interpolation.
In SPM, pre-processing was conducted with the Batch Editor GUI. To correct for motion, a two-step rigid body registration procedure was performed with a least squares cost function; each volume from the BOLD images was first registered to the first volume, and then registered to the mean of the aligned images (‘Realign: Estimate & Reslice’ function, cubic spline interpolation). The anatomical T1-weighted image was then rigidly registered to the mean BOLD image with a mutual information cost function (‘Coregister: Estimate’ function, cubic spline interpolation). Segmentation, bias field correction and non-linear registration of the anatomical image to standard space (“unified segmentation”) were then conducted (‘Segment’ function); instead of a simple cost function, this process uses a model incorporating tissue class, bias field and spatial deformations to best fit the T1 image data. The estimated deformation field was then used for warping the realigned BOLD images (cubic spline interpolation) and bias corrected anatomical image to MNI space (as defined by the average image of 549 of the subjects from the IXI dataset13, cf. spm_template.man for more details) using spline interpolation (‘Normalise: Write’ function). Finally, the normalized realigned BOLD images were smoothed using a 6 mm FWHM Gaussian smoothing kernel (‘Smooth’ function). Global scaling (1 value for whole 4D dataset) was used to set the mean brain intensity to target value of 10014.
Data Analysis
As specified by the tone counting task, for each software package, the subject-level design matrix included at least two regressors (“tone counting” and “probe”).
By default AFNI adds nine additional regressors in the design matrix: an intercept, two to model slow signal drifts using a second-order polynomial, and six motion regressors (three rotations, three shifts), resulting in a design matrix with 11 columns.
By default SPM adds a discrete cosine transform basis to the linear model to account for drift. The default cutoff of 128 s with this 208 s acquisition allowed three regressors. With an intercept, the model has six regressor parameters, though the drift basis columns are not displayed to the user.
In FSL, slow signal drifts were removed from the data and modeled with a Gaussian-weighted running line smoother with bandwidth parameter 60 s15, a reduction from the software default value of 100 s, since this is recommended for event-related designs16. The design matrix has only two columns, which are mean centered.
Variants
Users can specify from a range of options at each stage in the analysis processing pipeline. A one-factor-at-a-time design was used to run tests with these different options. In each of the analysis packages, at each processing stage (Column 1, Table 1.) a single variant was labeled as a default (Columns 3–5, Table 1.). This default variant was usually the same in each software package, except for software-defined defaults, which were left unchanged (e.g., HRF).
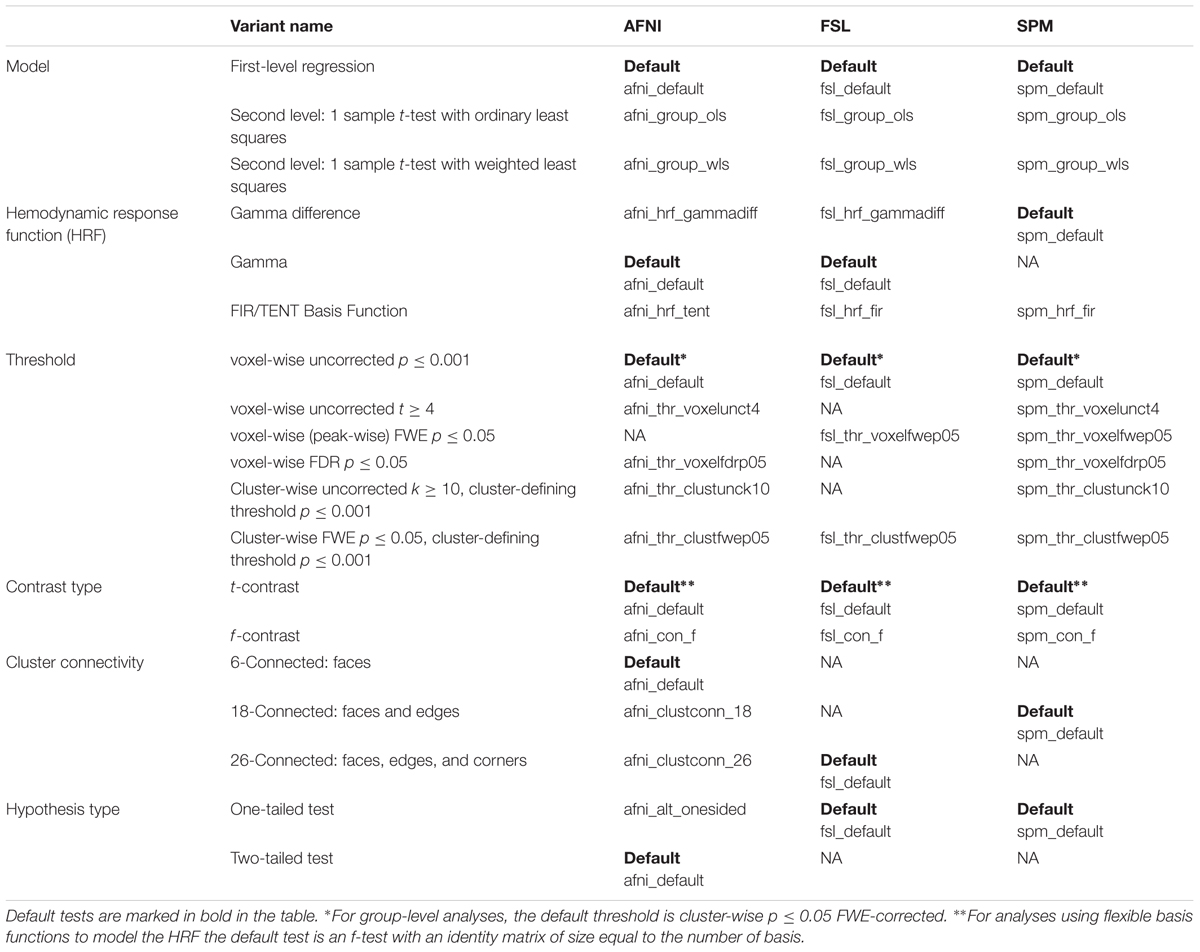
TABLE 1. Folder names for variants in each software package (columns 3–5), for each variant type (columns 1–2).
The variants are presented below. Apart from the aspect that had been explicitly changed for that variant, all other stages of the processing pipeline were kept the same as the default analysis. Using this method, at least one analysis was conducted for each possible variant at every stage of the processing pipeline in AFNI, SPM, and FSL.
Hemodynamic Response Function
Gamma Function
The HRF was modeled using a Gamma function.
Difference of Gamma Functions
The HRF was modeled using the difference of two Gamma functions. This is the default in SPM (SPM’s canonical HRF). In FSL, the Double-Gamma HRF option was used (with a phase 0).
Flexible Factorial Basis Functions
The HRF was modeled using a finite impulse response (FIR) basis set or a set of TENT functions. In FSL, three basis FIR functions spread over 15 s were defined. In SPM, 10 basis FIR functions spread over 20 s were defined. In AFNI, eight (respectively, seven) TENT functions were defined with a 0 s start and a duration of 12 s (respectively, 14 s) for the tone counting (respectively, the probe) regressor.
Model Variants
First-Level Regression
The default analysis for all software packages was a single-subject t-test on the tone counting contrast.
Second Level: 1 Sample t-test Estimated with Ordinary Least Squares
A one-sample group t-test with ordinary least square estimation was performed on the tone counting contrast over the 14 participants.
1 Sample t-test Estimated with Weighted Least Squares
A one-sample group t-test with weighted least square estimation was performed on the tone counting contrast over the 14 participants.
Threshold
Voxel-Wise Uncorrected p ≤ 0.001
Results were thresholded with a voxel-wise threshold of p ≤ 0.001 uncorrected for multiple comparisons.
Voxel-Wise t ≥ 4
Results were thresholded with a voxel-wise threshold of t ≥ 4.
Voxel-Wise (Peak-Wise) FWE p ≤ 0.05
Results were thresholded with a voxel-wise threshold of family-wise error rate p ≤ 0.05 with correction for multiple comparisons.
Voxel-Wise FDR p ≤ 0.05
Results were thresholded with a voxel-wise threshold of false discovery rate p ≤ 0.05 correction for multiple comparisons.
Cluster-Wise k ≥ 10
Results were thresholded with a cluster-wise threshold of 10 voxels. Clusters were defined using a cluster-forming threshold of p ≤ 0.001 uncorrected for multiple comparisons.
Cluster-Wise FWE p ≤ 0.05
Results were thresholded with a cluster-wise threshold of family-wise error rate p ≤ 0.05 with correction for multiple comparisons. Clusters were defined using a cluster-forming threshold of p ≤ 0.001 uncorrected for multiple comparisons.
Contrast
t-test
The default analysis for all software packages was a t-test on the tone counting contrast.
f-test
An f-test on the tone counting contrast was performed.
Cluster Connectivity
6-Connected
Neighboring voxels had faces touching. Under this definition a voxel can have up to six nearest neighbors. This is the default in AFNI.
18-Connected
Neighboring voxels were defined as those with faces or edges touching. Under this definition a voxel can have up to 18 nearest neighbours. This is the default in SPM.
26-Connected
Neighboring voxels had faces, edges, or corners touching. Under this definition a voxel can have up to 26 nearest neighbors. This is the default in FSL.
Alternative Hypothesis
One-Tailed Test
A one-tailed test looking at positive effects was performed. This is the default in SPM and FSL.
Two-Tailed Test
A two-tailed test looking at positive and negative effects was performed. This is the default in AFNI.
Results
Figure 1 shows the tone counting group level results from a one-sided test FWE-corrected p ≤ 0.05 cluster-wise inference with a p ≤ 0.001 uncorrected cluster forming threshold. Despite differences in smoothing, the unthresholded maps show the same general pattern of activation. Thresholded maps from SPM and FSL (6 mm FWHM smoothing) were most similar, while AFNI (4 mm FWHM smoothing) presented a smaller number of active voxels. Aside from smoothing, an important difference with AFNI is the inclusion of motion regressors in the first level model; this is good statistical practice but can reduce sensitivity if the subject motion is correlated with the regressor of interest.
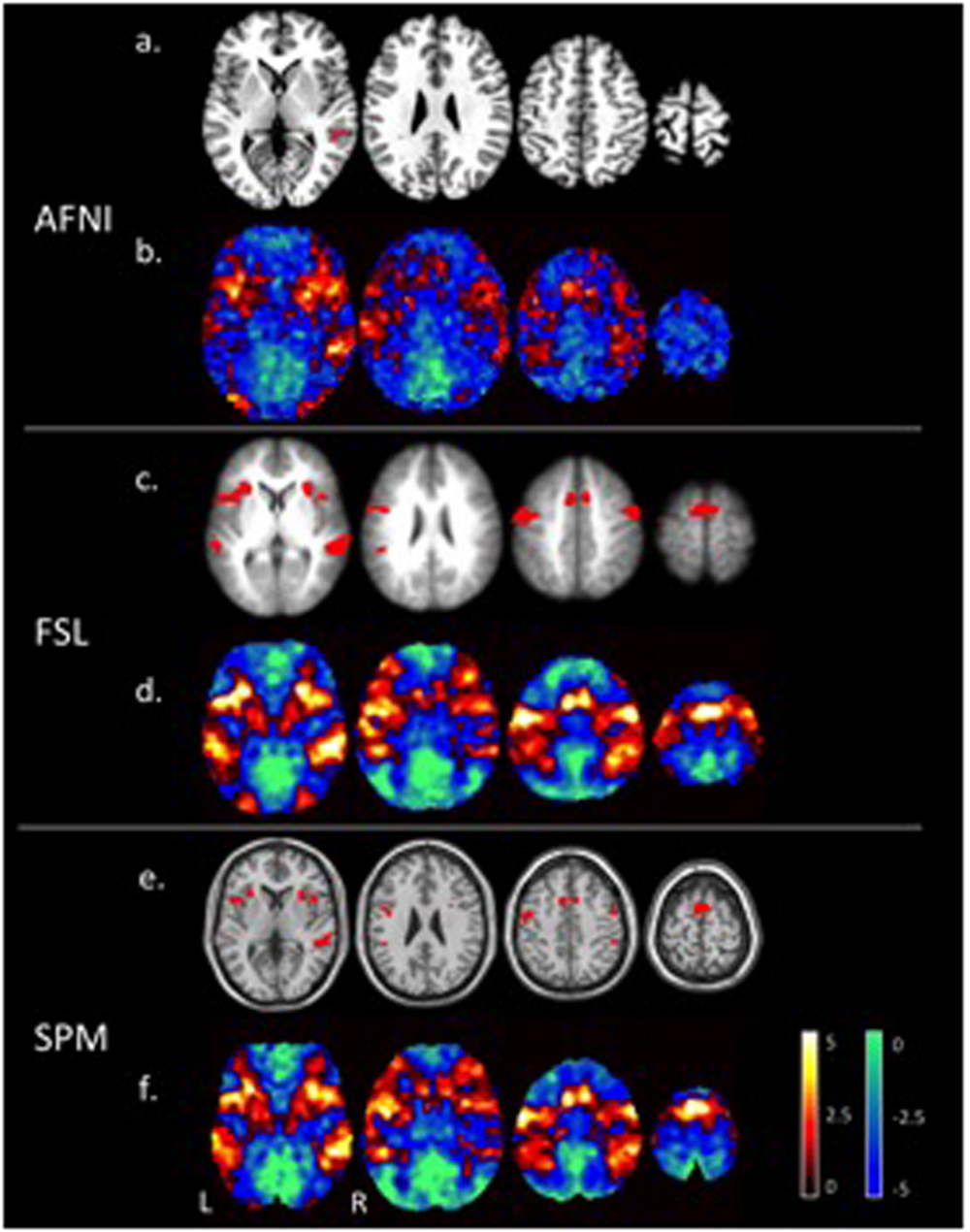
FIGURE 1. Areas of significant activations (red) for a one-sided t-test at a p ≤ 0.05 FWE corrected cluster-wise threshold for the tone counting contrast (a), (c), (e), and un-thresholded t-statistic maps (positive values in red to yellow and negative values in blue to green) (b), (d), (f), at the group level are compared for each of the three software packages (AFNI, FSL, and SPM).
In comparing software packages, there is naturally a tension between exact matching of parameter sets versus use of recommended defaults. The analyses presented here remain faithful to the default settings where possible. Consequently, the differences between packages can be difficult to interpret fully. We plan future work with carefully matched analyses, in order to further elucidate the differences between software packages using many more datasets.
Finally, it is important to emphasize that these tests are not intended to demonstrate the superiority of any particular software package over the others. Each package has its strengths and weaknesses. For example, SPM cannot compute cluster-size inference by FWE p-value, while FSL cannot specify inference by uncorrected cluster threshold. AFNI has immense flexibility in this regard, but the sheer number of options available can make it difficult for the user to judge how to proceed. Ultimately, choice of software will usually be a matter of personal preference for the researcher.
Data Sharing
The dataset is named fMRI Results Comparison Library and can be available at: http://warwick.ac.uk/tenichols/fmri_results. The folder names for each variant are provided in Table 1.
For the AFNI variants, each folder contains scripts for running the analysis (cmd.ap.sub_001 and proc.sub_001 for single-subject tests), scripts for specifying the threshold levels (batch.sh; these are not standard AFNI output, and are included so that future users can run the analysis without manually setting thresholds in the interface), the thresholded dataset (Clust_mask+tlrc) that contains significant clusters, and files that AFNI outputs automatically, saved in the sub_001.results folder.
For the FSL variants, each directory contains the complete FEAT output, which includes the FEAT setup file (design.fsf), motion correction reporting (mc/directory), low-res stats outputs (stats/directory), standard space registration outputs (reg/directory), resampling of stats images into standard space (reg_standard/stats/directory), and time series plots (tsplot/directory). All.html files of the FEAT report are also included.
For the SPM variants, each directory contains a batch.m file to run the analysis, as well as the SPM.mat file containing the design specification. NIFTI files for the regressors, contrasts, and thresholded results are included, and the results report obtained from the analysis has been printed in.pdf format.
Finally, a README.md file is contained in every variant directory, giving a description of the variant and data used in the test.
Recommended Uses
The dataset includes all the necessary scripts and files for future users to replicate the analyses exactly as they were carried out here. This is especially useful for those seeking quick comparisons between different processing options (both within and between software packages). In AFNI, this also removes the need to enter threshold or cluster information manually via the interface. In addition, the dataset and accompanying information in this paper should be useful for novice neuroimagers seeking clear descriptions and examples of basic tests to guide them in their own research.
Author Contributions
Analyses were conducted by AB, CM, and RP, with guidance from GC, RR, CM, and TN. The paper was drafted by AB and RP, and written by AB, CM, RP, TN, and RR.
Funding
The INCF provided funding for the use of Git Large File Storage (Git-LFS). AB, CM, and TN were supported by the Welcome Trust. RP was supported by the BBSRC-funded Midlands Integrative Biosciences Training Partnership (MIBTP), and RR and GC were supported by the NIMH and NINDS Intramural Research Programs (ZICMH002888) of the NIH/HHS, USA.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We gratefully acknowledge Karin Foerde, Barbara Knowlton, and Russell Poldrack, who provided their ds000011 data to OpenfMRI. We would like to thank Russell Poldrack for giving advice on re-using the data. We also gratefully acknowledge Krzysztof Gorgolewski, William Triplett, and others at OpenfMRI for their feedback.
Footnotes
- ^http://afni.nimh.nih.gov/
- ^http://fsl.fmrib.ox.ac.uk/fsl
- ^http://www.fil.ion.ucl.ac.uk/spm/
- ^http://nidm.nidash.org
- ^http://www.incf.org
- ^https://openfmri.org
- ^http://www.humanconnectome.org
- ^https://drive.google.com/folderview?id=0B2JWN60ZLkgkMGlUY3B4MXZIZW8&usp=sharing
- ^http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/FEAT
- ^https://afni.nimh.nih.gov/afni/community/board/read.php?1,149511,149513\#msg-149513
- ^http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/BET
- ^http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/MCFLIRT
- ^http://www.brain-development.org/
- ^Due to an over-sized brain mask used for global mean computation, SPM’s intracerebral mean tends to be under-estimated, resulting in a scaled brain mean intensity of 200 or more instead of 100. For more see: http://blogs.warwick.ac.uk/nichols/entry/spm_plot_units/.
- ^This parameter is only approximately the FWHM of the smoother’s Gaussian, since FSL uses 2.0 instead of 2.335 in the FWHM-to-sigma conversion. For more see: https://www.jiscmail.ac.uk/cgi-bin/webadmin?A2=ind1109\&L=FSL\&P=R30849
- ^http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/FEAT/UserGuide#FEAT_Basics.
References
Bellec, P., Chu, C., Chouinard-Decorte, F., and Margulies, D. S. (2016). The neuro bureau ADHD-200 preprocessed repository. bioRxiv. doi: 10.1101/037044
Carp, J. (2012). On the plurality of (methodological) worlds: estimating the analytic flexibility of fMRI experiments. Front. Neurosci. 6:149. doi: 10.3389/fnins.2012.00149
Cox, R. W. (1996). AFNI: software for analysis and visualization of functional magnetic resonance neuroimages. Comput. Biomed. Res. Int. J. 162–73. doi: 10.1006/cbmr.1996.0014
Foerde, K., Knowlton, B. J., and Poldrack, R. A. (2006). Modulation of competing memory systems by distraction. Proc. Natl. Acad. Sci. U.S.A. 103, 11778–11783. doi: 10.1073/pnas.0602659103
Hanke, M., Baumgartner, F. J., Ibe, P., Kaule, F. R., Pollmann, S., Speck, O., et al. (2014). A high-resolution 7-Tesla fMRI dataset from complex natural stimulation with an audio movie. Sci. Data 1:140003. doi: 10.1038/sdata.2014.3
Holmes, C. J., Hoge, R., Collins, L., Woods, R., Toga, A. W., and Evans, A. C. (1998). Enhancement of MR images using registration for signal averaging. J. Comput. Assisted Tomogr. 22, 324–333. doi: 10.1097/00004728-199803000-00032
Jenkinson, M., Beckmann, C. F., Behrens, T. E. J., Woolrich, M. W., and Smith, S. M. (2012). FSL. Neuroimage 62, 782–790. doi: 10.1016/j.neuroimage.2011.09.015
Keator, D. B., Helmer, K., Steffener, J., Turner, J. A., Van Erp, T. G. M., Gadde, S., et al. (2013). Towards structured sharing of raw and derived neuroimaging data across existing resources. Neuroimage 82, 647–661. doi: 10.1016/j.neuroimage.2013.05.094
Maumet, C., Auer, T., Bowring, A., Chen, G., Das, S., Flandin, G., et al. (2016). NIDM-results: a neuroimaging data model to share brain mapping statistical results. bioRxiv. doi: 10.1101/041798
Penny, W. D., Friston, K. J., Ashburner, J. T., Kiebel, S. J., and Nichols, T. E. (2011). Statistical Parametric Mapping: The Analysis of Functional Brain Images: The Analysis of Functional Brain Images. Cambridge, MA: Academic press.
Poldrack, R. A., Barch, D. N., Mitchell, J. P., Wager, T. D., Wagner, A. D., Devlin, J. T., et al. (2013). Toward open sharing of task-based fMRI data: the OpenfMRI project. Front. Neuroinformat. 7:12. doi: 10.3389/fninf.2013.00012
Poldrack, R. A., and Gorgolewski, K. J. (2014). Making big data open: data sharing in neuroimaging. Nat. Neurosci. 17, 1510–1517. doi: 10.1038/nn.3818
Poline, J. B., Breeze, J. L., Ghosh, S., Gorgolewski, K., Halchenko, Y. O., Hanke, M., et al. (2012). Data sharing in neuroimaging research. Front. Neuroinformat. 6:9. doi: 10.3389/fninf.2012.00009
Keywords: data sharing, functional MRI, provenance, fMRI analysis, neuroimaging
Citation: Pauli R, Bowring A, Reynolds R, Chen G, Nichols TE and Maumet C (2016) Exploring fMRI Results Space: 31 Variants of an fMRI Analysis in AFNI, FSL, and SPM. Front. Neuroinform. 10:24. doi: 10.3389/fninf.2016.00024
Received: 15 April 2016; Accepted: 22 June 2016;
Published: 05 July 2016.
Edited by:
David N Kennedy, University of Massachusetts Medical School, USAReviewed by:
Christine Cong Guo, QIMR Berghofer Medical Research Institute, AustraliaJiaojian Wang, University of Electronic Science and Technology of China, China
Copyright © 2016 Pauli, Bowring, Reynolds, Chen, Nichols and Maumet. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ruth Pauli, r.pauli@warwick.ac.uk