
- 1Department of Biology, Brigham Young University, Provo, UT, USA
- 2Department of Biology, The American University in Cairo, New Cairo, Egypt
The importance of metabolism in cancer is becoming increasingly apparent with the identification of metabolic enzyme mutations and the growing awareness of the influence of metabolism on signaling, epigenetic markers, and transcription. However, the complexity of these processes has challenged our ability to make sense of the metabolic changes in cancer. Fortunately, constraint-based modeling, a systems biology approach, now enables one to study the entirety of cancer metabolism and simulate basic phenotypes. With the newness of this field, there has been a rapid evolution of both the scope of these models and their applications. Here we review the various constraint-based models built for cancer metabolism and how their predictions are shedding new light on basic cancer phenotypes, elucidating pathway differences between tumors, and dicovering putative anti-cancer targets. As the field continues to evolve, the scope of these genome-scale cancer models must expand beyond central metabolism to address questions related to the diverse processes contributing to tumor development and metastasis.
Introduction
“One of the goals of cancer research is to ascertain the mechanisms of cancer.” These words, penned by Dulbecco (1986), began a treatise on how a mechanistic understanding of cancer requires a sequenced human genome. Now with the abundance of sequence data, we are finding diverse genetic changes among different cancers (Vogelstein et al., 2013). While we are cataloging these mutations, the associated mechanisms leading to phenotypic changes are often unclear since mutations occur in the context of complex biological networks. For example, mutations to isocitrate dehydrogenase lead to oncometabolite synthesis, which alters DNA methylation and ultimately changes gene expression and the balance of normal cell processes (Sasaki et al., 2012). Furthermore, many different combinations of mutations can lead to cancer. Since the genetic heterogeneity between tumors can be large, the biomolecular mechanisms underlying tumor physiology can vary substantially. This is apparent in metabolism, where tumors can differ in serine metabolism dependence (Possemato et al., 2011) or TCA cycle function (Frezza et al., 2011b). In addition, diverse mutations can alter NADPH synthesis by differentially regulating signaling pathways, such as the AMPK pathway (Cairns et al., 2011; Jeon et al., 2012).
The challenges regarding complexity and heterogeneity in cancer metabolism are beginning to be addressed with the COnstraint-Based Reconstruction and Analysis (COBRA) approach (Hernández Patiño et al., 2012; Sharma and König, 2013), an emerging field in systems biology. Specifically, it accounts for the complexity of the perturbed biochemical processes by using genome-scale metabolic network reconstructions (Duarte et al., 2007; Ma et al., 2007; Thiele et al., 2013). In a reconstruction, the stoichiometric chemical reactions in a cell are carefully annotated and stitched together into a large network, often containing thousands of reactions. Genes and enzymes associated with each reaction are also delineated. The networks are converted into computational models and analyzed using many algorithms (Lewis et al., 2012). COBRA approaches are also beginning to address heterogeneity in cancer by integrating experimental data with the reconstructions (Blazier and Papin, 2012; Hyduke et al., 2013) to tailor the models to the unique gene expression profiles of general cancer tissue, and even individual cell lines and tumors. Here we describe the recent conceptual evolution that has occurred for constraint-based cancer modeling.
Evolution of Model Scope and Specificity
The molecular basis of cancer includes mutations, epigenetic changes, mRNA splice variants, fluctuations in protein expression, etc. Each molecular change influences other cell components, and the perturbed molecular interactions ultimately induce cancer phenotypes. Thus, cancer is a phenotypic manifestation of a dysfunctional biomolecular network. To understand how the complex and heterogeneous changes in cell networks lead to cancer phenotypes, several studies have recently constructed constraint-based metabolic network models of the disease. With each publication, these models have evolved in scope and detail (Figure 1). That is, the first few models represented the coarse-grained canonical commonalities of cancer metabolism, while the more recent models have been specific to individual cell lines, tissues, or patients. Here we compare these models, and discuss the scope of insights they provided.
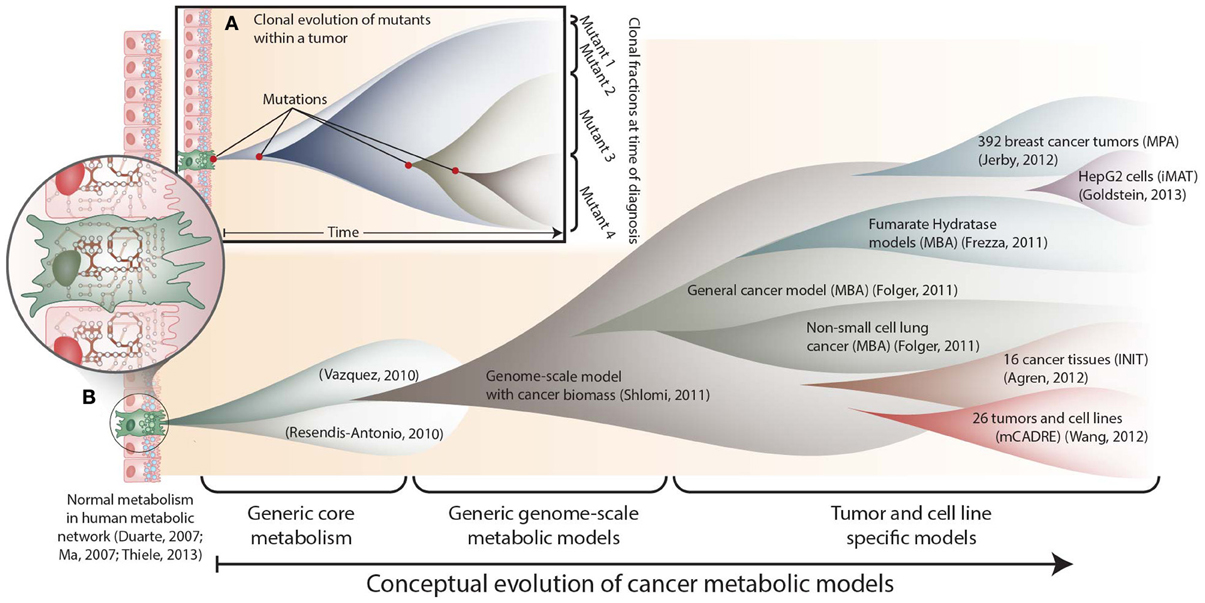
Figure 1. The conceptual evolution of constraint-based models of cancer metabolism. (A) Clonal evolution commonly occurs in a developing tumor as new mutations are acquired that confer increased growth capabilities to new mutants. At the time of diagnosis, a tumor often consists of a mixed population of cancerous cells. (B) Similarly, the scope and specificity of cancer metabolic models have rapidly evolved over the past few years. Genome-scale metabolic network reconstructions have provided a valuable resource, since they contain thousands of known human metabolic reactions (Duarte et al., 2007; Ma et al., 2007; Thiele et al., 2013). This knowledge enabled the first two cancer-specific metabolic models, which focused on core metabolic pathways(Resendis-Antonio et al., 2010; Vazquez et al., 2010). In 2011, the first genome scale model of general cancer metabolism was used to provide insights into the Warburg effect(Shlomi et al., 2011). Shortly thereafter, transcriptomic data from the NCI-60 cell lines were used to build a general genome-scale model of cancer metabolism, which was used to assess metabolic drug targets(Folger et al., 2011). Now, numerous additional models have been built using data from specific cell lines and tumors. These models have elucidated pathways that differ between tumors(Agren et al., 2012; Wang et al., 2012), identified pathways that are differentially regulated with changes in estrogen receptor or p53 expression(Jerby et al., 2012; Goldstein et al., 2013), and predicted potential anti-cancer drug targets(Folger et al., 2011; Frezza et al., 2011b).
Generic Cancer Models
Cancer is highly complex for two reasons. First, molecular changes occur in the context of a vast network of interactions. Thus, a mutation's impact is not apparent without accounting for the functions of many downstream molecules. Second, the induction of tumorigenesis from one mutation is rare. Multiple mutations accumulate over time as the tumor evolves (Yates and Campbell, 2012) (Figure 1A). The complex context in which cancer mutations reside often confounds efforts to understand their phenotypic link. However, the complexity of cellular networks can be addressed computationally.
Several metabolic properties are common among tumors (Kroemer and Pouyssegur, 2008), such as anaerobic glycolysis, ATP production and growth. Thus, generic models of cancer metabolism were constructed by including major pathways producing ATP or biomass. This was done for two small-scale models of core metabolism (Resendis-Antonio et al., 2010; Vazquez et al., 2010) and another genome-scale metabolic model (Shlomi et al., 2011). Resendis-Antonio et al. (2010) analyzed core metabolic pathways in cancer: glycolysis, TCA cycle, pentose phosphate, glutaminolysis and oxidative phosphorylation. This model accurately predicted HeLa cell line growth rates and identified known drug targets, including lactate dehydrogenase and pyruvate dehydrogenase. The model also recapitulated the Warburg effect, i.e., at a fixed glucose uptake rate, a decrease in pyruvate dehydrogenase flux increased biomass production capacity. Using another model of ATP production, Vazquez and colleagues demonstrated that the Warburg effect may result from molecular crowding in proliferating cells (Vazquez et al., 2010; Vazquez and Oltvai, 2011). This finding was further supported by Shlomi et al. (2011), using a generic genome scale model of human metabolism that was modified to simulate biomass precursor formation as a proxy for cancer cell proliferation.
The initial three constraint-based cancer metabolic models successfully recapitulated general features of cancer metabolism and provided systems-level insights into the Warburg effect. More detailed predictions were obtained from a fourth generic cancer model (Folger et al., 2011). This model was built by mapping transcriptomic data to the human metabolic network (Duarte et al., 2007). Using the Model Building Algorithm (MBA; Jerby et al., 2010) to remove pathways that were not supported by the data, a model with 772 reactions and 683 genes was obtained. The MBA general cancer model was built as follows. Highly expressed genes in the NCI-60 cell lines were identified from transcriptomic data. Reactions associated with the highly expressed genes were called “core” reactions and assumed to be active in cancer cells. Then non-core reactions were removed if all core reactions remained functional. The model included a biomass objective function to simulate the synthesis of all metaboltes needed for cell proliferation (e.g., nucleotides, amino acids, lipids, etc.). Thus, this model was the first genome-scale model of cancer metabolism that captured the main metabolic functions shared by many cancer types, while removing pathways that were not endemic to cancer.
Flux Balance Analysis (FBA) (Orth et al., 2010) was used with the generic MBA cancer model to identify potential drug targets (Folger et al., 2011). Since FBA simulates a cell's metabolic state (including growth and metabolic flux), the phenotypic response following gene knockdowns can be predicted, and the effects of drug applications can be simulated on a large scale. In the MBA cancer model, genes were identified that, when inhibited, decreased the model-predicted growth rate. In doing so, 52 cytostatic drug targets were identified, of which 40% are targeted by known, approved, or experimental anticancer drugs. Predictions were also made for pairs of synthetic lethal drug targets. The synergistic effects of these target pairs were validated by looking for increases in drug susceptibility among NCI-60 cell lines lacking expression of one target in each synthetic lethal pair. Cell lines missing one target were often more susceptible to treatments against the other gene in the synthetic lethal pair. Thus, by accounting for cancer-specific combinations of metabolic pathways, one could design therapeutics to inhibit cancer cell proliferation.
Cell Line and Tumor-Specific Cancer Models
General cancer models have demonstrated that COBRA approaches can manage the complexity of cancer metabolism. While there are common biochemical features and mutations, there remains much heterogeneity between different tumors. Thus, algorithms are now generating genome-scale metabolic models specific to cancer cell lines and tumors. These models provide varying levels of insight by elucidating cancer-specific pathways and predicting therapeutic targets for specific tumors.
Identifying Cancer-Relevant Pathways
Two studies recently identified metabolic pathways that differ between cancer and the parent tissue from which the tumor arose (Agren et al., 2012; Wang et al., 2012). To do this, algorithms were developed to integrate omic data with a reference human metabolic reconstruction to build tumor-specific metabolic networks.
One algorithm, called Integrative Network Inference for Tissues (INIT), used immunohistochemical staining data (Uhlen et al., 2010), metabolomic data (Wishart et al., 2013), and transcriptomic data to construct metabolic models for 16 cancer types and their parent tissues (Agren et al., 2012). These models each contained more than 2600 reactions. Genes and reactions that were more frequently identified in the cancer tissues were analyzed to identify Reporter Metabolites (Patil and Nielsen, 2005) that were more frequently associated with cancer. Several metabolites arose as dominant features in cancer. These included polyamines (e.g., spermine, spermidine, and putrescine), intermediates of isoprenoid biosynthesis (e.g., geranylgeranyl diphosphate), prostaglandins and leukotrienes. Previous studies targeted these processes in cancer, but this study predicted key sites where the pathways could be targeted. In addition, bilirubin and biliverdin arose as novel targets. By targeting biliverdin reductase, one could potentially block the anti-oxidative stress functions of these metabolites, thus enhancing cell death.
Another 26 tumor-specific genome-scale models were generated using an algorithm called Metabolic Context-specificity Assessed by Deterministic Reaction Evaluation (mCADRE) (Wang et al., 2012), and the sizes of these models ranged from roughly 1000–1400 reactions. Each cancer model was compared to a corresponding healthy tissue model. Cancer-specific pathways were identified, many of which were previously known to contribute to tumorigenesis and neoplastic growth, including folate metabolism, eicosanoid metabolism, and nucleotide metabolism. For example, folate and nucleotide metabolism have previously been chemotherapy targets since they contribute to the increased nucleotide synthesis rate in cancer. Beyond general pathway differences, several reactions were identified as being more frequently associated with cancer models. These included eicosanoid metabolism reactions catalyzed by 5-lipoxygenase, which contributes to angiogenesis and proliferation (Ye et al., 2005). Importantly, the association of these metabolic pathways with cancer was not apparent when the authors only looked at differential gene expression without the model topology. Thus, it is clearly advantageous to study gene regulatory programs in cancer in the context of functional metabolic networks.
Assessing the Metabolic Phenotype of Tumors
Recently, models were built to elucidate p53′s role in regulating cancer metabolism (Goldstein et al., 2013). This was accomplished using an algorithm called integrative Metabolic Analysis Tool (iMAT) (Shlomi et al., 2008), which uses gene expression levels to predict the distribution of metabolic fluxes. iMAT uses an optimization problem to maximize the number of highly expressed genes that carry flux while minimizing the number of low expression genes that must be used. Using iMAT, models were constructed for cell lines with different levels of p53 expression. Specifically, two liver-derived HepG2 cell lines were developed, expressing either a short hairpin RNA (shRNA) targeting p53 or a control shRNA. The cell lines were grown with or without Nutlin-3a, which activates p53, and then the transcriptomes of the samples were assayed. For each condition, iMAT models were constructed, and these models demonstrated that p53 increases the expression of gluconeogenesis. Thus, p53 may be diverting glucose away from growth-promoting pathways, such as glycolysis and the pentose phosphate pathway, thereby inhibiting neoplastic growth and tumorigenesis.
Another method, called Metabolic Phenotype Analysis (MPA), elucidated metabolic features among 392 breast cancer tumors, based on microarray data (Jerby et al., 2012). To do this, several cellular metabolic functions were defined (e.g., lipid production). Then, for each breast cancer sample, microarray data were used to constrain the human metabolic model using a variant of iMAT. For each metabolic function, a score was assigned to describe the fitness of the given tumor sample for performing the metabolic function of interest. Across all samples, the authors compared metabolic functions, growth rates, posttranscriptional regulation, and metabolic biomarkers. For example, the authors found that premalignant cells grow faster than malignant tumors, suggesting a proliferative deceleration prior to metastasis. In addition, late-stage tumors showed increased flux in glycolysis, lactate production, ROS detoxification, and the pentose phosphate pathway.
MPA further elucidated metabolic differences between tumors differing in their estrogen receptor (ER) status (commonly used to differentiate between breast cancer types) (Jerby et al., 2012). Specifically, between ER+ and ER− tumors, 73% of the metabolic processes had significantly different MPA scores. For example, glutamine biosynthesis/secretion and lactate production were more pronounced in ER+, while serine metabolism and glutamine uptake were more predominant in ER−. These differences resulted from a stoichiometric tradeoff between glutamine secretion and serine metabolism, consistent with the observation that serine biosynthesis requires glutamine as a nitrogen donor (Possemato et al., 2011). Thus, the use of models for -omic data analysis can elucidate the biomolecular mechanisms underlying complex phenotypes in different tumors.
Model-Guided Inhibition of Cancer Cell Proliferation
The biochemical detail provided by COBRA models is elucidating differences between tumors. Can the models also predict therapeutic targets? While the constraint-based cancer modeling field is young, two studies demonstrated the predictive power of cell line-specific models. Folger et al. (2011) built a cancer model for non-small cell lung cancer metabolism, based on microarray data. Model-predicted genes that were essential for growth significantly overlapped with experimentally measured essential genes from an shRNA screen. Furthermore, the overlap was more significant than when the test was repeated with the general cancer MBA model, thus demonstrating that cell-line specific models could suggest novel targets.
A subsequent study found and validated a target relevant to hereditary leiomyomatosis and renal cell cancer (HLRCC). This cancer can develop when the tumor suppressor gene fumarate hydratase (FH) is mutated. To mimic HLRCC, a murine renal cell line was derived, and subsequently FH was disabled (Frezza et al., 2011b). MBA models were constructed for the cell line before and after disabling FH. Simulations with these models demonstrated that a loss of FH is buffered by other pathways. Indeed, 24 model genes were synthetic lethal with FH, most of which contributed to heme biosynthesis. When an inhibitor for heme oxygenase was used, FH-deficient cells could not proliferate. Since normal cells are FH+, they were relatively unaffected by the therapeutic inhibition of heme oxygenase. Thus, a cell-line specific model enabled the identification of a potential new drug target for a specific tumor type, highlighting the potential of model-predicted cancer therapies.
Expanding the Scope of Genome-Scale Models in Cancer
Insight into cancer metabolism may be expanded as genome-scale metabolic network models are further analyzed using the expanding toolbox of constraint-based modeling methods (Price et al., 2004; Lewis et al., 2012). A current challenge, however, is to increase the scope of genome-scale cancer modeling. Three directions of relevance to cancer include: (1) employing models as data integration platforms, (2) using models to discover details about mutations and enzyme regulation, and (3) expanding models to account for the other hallmarks of cancer.
True to Dulbecco's vision (Dulbecco, 1986), the human genome sequence enables systematic approaches and novel technologies to understand cancer. Numerous cancer genomes have been sequenced (Hudson et al., 2010), and their mutations are being cataloged (Forbes et al., 2011). Others have profiled cancer chromatin landscapes (Schuster-Böckler and Lehner, 2012) and studied dysregulated transcriptional regulatory programs in cancer (Lee et al., 2012; Lee and Young, 2013). Protein modifications are routinely identified and proteins are being quantified (Cohen et al., 2008; Uhlen et al., 2010). In parallel, other studies are characterizing the metabolome (Jain et al., 2012) and metabolic flux through pathways in cancer (Wellen et al., 2010; Locasale et al., 2011).
Genomic, metabolomic, and phenotyping studies yield valuable data, but it is challenging to integrate the datasets for deeper insight. Relationships between disparate data types can be unclear. Some successes have relied on complex statistical methods to find loci that co-vary with metabolites (Kettunen et al., 2012; Krumsiek et al., 2012). Genome-scale metabolic models provide a complementary approach. Their mechanistic context with physical interaction data enables one to integrate metabolomic, transcriptomic, proteomic, genomic, and high-throughput phenotyping array data (Figure 2A) (Blazier and Papin, 2012; Hyduke et al., 2013). For example, changes in the extracellular metabolome can be used to constrain model uptake and secretion fluxes. Then transcriptomic and proteomic data can constrain internal fluxes, and phenotypic assays provide limits on growth rates or other phenotypic measures. Thus, these models become biochemically-based data integration platforms. This will likely become increasingly common for interpreting cancer omic data.
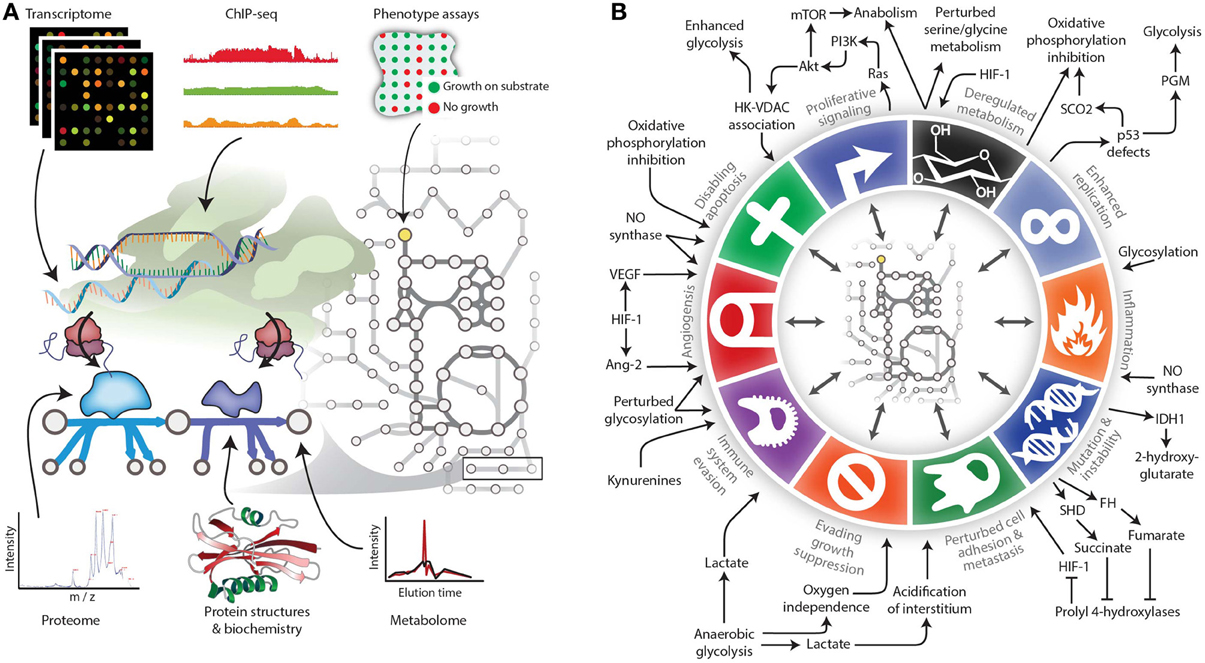
Figure 2. Expanding the reach of genome-scale metabolic models for studying cancer. (A) Genome-scale metabolic models serve as biochemically-supported data-integration platforms. In the metabolic network, metabolomic data can be associated with metabolites, while genomic, transcriptomic, proteomic, and related data types can be associated with metabolic reactions. Phenotypic measurements can be used to constrain properties of the network such as growth rate under certain experimental conditions. (B) The various Hallmarks of Cancer either affect metabolism or are modulated by metabolic changes. Therefore, modeling techniques are needed to account for these interactions between metabolism and other cell processes. Panel B adapted from (Hanahan and Weinberg, 2011) and (Kroemer and Pouyssegur, 2008) with permission.
Metabolism significantly changes during tumorigenesis and metastasis (Cairns et al., 2011). This stems from numerous biochemical adjustments, including mutations and posttranslational modifications (PTMs) (Solit and Mellinghoff, 2010). Ongoing studies biochemically characterize how aberrant PTMs and mutations regulate metabolism in cancer, but the low-throughput nature of biochemistry prohibits the characterization of all mutations. Fortunately, emerging approaches are beginning to prioritize and infer the functional impact of biomolecular changes (Ng and Henikoff, 2006; Beltrao et al., 2012). Furthermore, developments in constraint-based modeling and metabolic flux analysis are beginning to predict regulatory roles of PTMs in metabolism (Oliveira et al., 2012). As cancer models further improve, they will likely help to rapidly characterize biochemical changes in cancer.
Several mutations have been repeatedly witnessed in metabolic enzymes in tumors. Many of these changes also influence other Hallmarks of Cancer (Kroemer and Pouyssegur, 2008; Hanahan and Weinberg, 2011) (Figure 2B). For example, mutations in succinate dehydrogenase and fumarate hydratase eventually lead to the activation of the HIF-1 transcription factor. HIF-1 regulates invasion, cell survival, angiogenesis, and inflammation in cancer (Semenza, 2003; Frezza et al., 2011a). Conversely, some changes in metabolic flux are downstream effects of perturbed transcriptional regulatory and signaling systems. For example, p53 expression influences gluconeogenesis (Goldstein et al., 2013), and mTOR signaling influences pyrimidine synthesis (Robitaille et al., 2013). Furthermore, metabolic changes in cancer influence cell-cell interactions in tumors. For example, changes in kynurenine concentration induce immune suppression, thereby facilitating immune escape in cancer (Prendergast, 2008). Metabolic exchanges also occur between cancer cells and the surrounding stroma (Giatromanolaki et al., 2012). These are just a few examples of diverse cell processes that interact with metabolism throughout the stages of cancer.
Advances in constraint-based modeling are now addressing cell–cell interactions(Lewis et al., 2010; Bordbar et al., 2011; Zomorrodi and Maranas, 2012; Levy and Borenstein, 2013) and incorporating other cellular processes into these models, including transcription regulation, translation, and signaling (Lee et al., 2008; Karr et al., 2012; Lerman et al., 2012; Thiele et al., 2012, 2010; Simeonidis et al., 2013). Efforts to link these processes to cancer metabolism should be fruitful. Lastly, models are needed that incorporate the hallmark processes of cancer, such as angiogenesis, apoptosis evasion, and cell adhesion. Such models will allow COBRA methods to reach beyond metabolism for a more holistic view of dysregulated processes in cancer.
Conclusion
When Renato Dulbecco pleaded with the scientific community to sequence the entire human genome (Dulbecco, 1986), seeds were sown for the genomic era of cancer biology. Now we are witnessing early developments in genome-scale modeling of cancer metabolism. The recent modeling successes serve as a harbinger to the discoveries that, in conjunction with advances in experimental tools, will deepen our understanding of cancer biology and our success in treating diverse classes of cancer.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Agren, R., Bordel, S., Mardinoglu, A., Pornputtapong, N., Nookaew, I., and Nielsen, J. (2012). Reconstruction of genome-scale active metabolic networks for 69 human cell types and 16 cancer types using INIT. PLoS Comput. Biol. 8:e1002518. doi: 10.1371/journal.pcbi.1002518
Beltrao, P., Albanèse, V., Kenner, L. R., Swaney, D. L., Burlingame, A., Villén, J., et al. (2012). Systematic functional prioritization of protein posttranslational modifications. Cell 150, 413–425. doi: 10.1016/j.cell.2012.05.036
Blazier, A. S., and Papin, J. A. (2012). Integration of expression data in genome-scale metabolic network reconstructions. Front. Physiol. 3:299. doi: 10.3389/fphys.2012.00299
Bordbar, A., Feist, A. M., Usaite-Black, R., Woodcock, J., Palsson, B. O., and Famili, I. (2011). A multi-tissue type genome-scale metabolic network for analysis of whole-body systems physiology. BMC Syst. biol. 5:180. doi: 10.1186/1752-0509-5-180
Cairns, R. A., Harris, I. S., and Mak, T. W. (2011). Regulation of cancer cell metabolism. Nat. Rev. Cancer 11, 85–95.
Cohen, A. A., Geva-Zatorsky, N., Eden, E., Frenkel-Morgenstern, M., Issaeva, I., Sigal, A., et al. (2008). Dynamic proteomics of individual cancer cells in response to a drug. Science 322, 1511–1516. doi: 10.1126/science.1160165
Duarte, N. C., Becker, S. A., Jamshidi, N., Thiele, I., Mo, M. L., Vo, T. D., et al. (2007). Global reconstruction of the human metabolic network based on genomic and bibliomic data. Proc. Natl. Acad. Sci. U.S.A. 104, 1777–1782. doi: 10.1073/pnas.0610772104
Dulbecco, R. (1986). A turning point in cancer research: sequencing the human genome. Science 231, 1055–1056. doi: 10.1126/science.3945817
Folger, O., Jerby, L., Frezza, C., Gottlieb, E., Ruppin, E., and Shlomi, T. (2011). Predicting selective drug targets in cancer through metabolic networks. Mol. Syst. Biol. 7, 501.
Forbes, S. A., Bindal, N., Bamford, S., Cole, C., Kok, C. Y., Beare, D., et al. (2011). COSMIC: mining complete cancer genomes in the catalogue of somatic mutations in cancer. Nucleic Acids Res. 39, D945–D950. doi: 10.1093/nar/gkq929
Frezza, C., Pollard, P. J., and Gottlieb, E. (2011a). Inborn and acquired metabolic defects in cancer. J. Mol. Med. 89, 213–220.
Frezza, C., Zheng, L., Folger, O., Rajagopalan, K. N., MacKenzie, E. D., Jerby, L., et al. (2011b). Haem oxygenase is synthetically lethal with the tumour suppressor fumarate hydratase. Nature 477, 225–228.
Giatromanolaki, A., Koukourakis, M. I., Koutsopoulos, A., Mendrinos, S., and Sivridis, E. (2012). The metabolic interactions between tumor cells and tumor-associated stroma (TAS) in prostatic cancer. Cancer Biol. Ther. 13, 1284–1289. doi: 10.4161/cbt.21785
Goldstein, I., Yizhak, K., Madar, S., Goldfinger, N., Ruppin, E., and Rotter, V. (2013). p53 promotes the expression of gluconeogenesis-related genes and enhances hepatic glucose production. Cancer Metab. 1:9. doi: 10.1186/2049-3002-1-9
Hanahan, D., and Weinberg, R. A. (2011). Hallmarks of cancer: the next generation. Cell 144, 646–674. doi: 10.1016/j.cell.2011.02.013
Hernández Patiño, C. E., Jaime-Muñoz, G., and Resendis-Antonio, O. (2012). Systems biology of cancer: moving toward the integrative study of the metabolic alterations in cancer cells. Front. Physiol. 3:481. doi: 10.3389/fphys.2012.00481
Hudson, T. J., Anderson, W., Artez, A., Barker, A. D., Bell, C., Bernabé, R. R., et al. (2010). International network of cancer genome projects. Nature 464, 993–998. doi: 10.1038/nature08987
Hyduke, D. R., Lewis, N. E., and Palsson, B. Ø. (2013). Analysis of omics data with genome-scale models of metabolism. Mol. Biosyst. 9, 167–174. doi: 10.1039/c2mb25453k
Jain, M., Nilsson, R., Sharma, S., Madhusudhan, N., Kitami, T., Souza, A. L., et al. (2012). Metabolite profiling identifies a key role for glycine in rapid cancer cell proliferation. Science 336, 1040–1044. doi: 10.1126/science.1218595
Jeon, S.-M., Chandel, N. S., and Hay, N. (2012). AMPK regulates NADPH homeostasis to promote tumour cell survival during energy stress. Nature 485, 661–665. doi: 10.1038/nature11066
Jerby, L., Shlomi, T., and Ruppin, E. (2010). Computational reconstruction of tissue-specific metabolic models: application to human liver metabolism. Mol. Syst. Biol. 6:401. doi: 10.1038/msb.2010.56
Jerby, L., Wolf, L., Denkert, C., Stein, G. Y., Hilvo, M., Oresic, M., et al. (2012). Metabolic associations of reduced proliferation and oxidative stress in advanced breast cancer. Cancer Res. 72, 5712–5720. doi: 10.1158/0008-5472.CAN-12-2215
Karr, J. R., Sanghvi, J. C., Macklin, D. N., Gutschow, M. V., Jacobs, J. M., Bolival, B., et al. (2012). A whole-cell computational model predicts phenotype from genotype. Cell 150, 389–401. doi: 10.1016/j.cell.2012.05.044
Kettunen, J., Tukiainen, T., Sarin, A.-P., Ortega-Alonso, A., Tikkanen, E., Lyytikäinen, L.-P., et al. (2012). Genome-wide association study identifies multiple loci influencing human serum metabolite levels. Nat. Genet. 44, 269–276. doi: 10.1038/ng.1073
Kroemer, G., and Pouyssegur, J. (2008). Tumor cell metabolism: cancer's Achilles' heel. Cancer Cell 13, 472–482. doi: 10.1016/j.ccr.2008.05.005
Krumsiek, J., Suhre, K., Evans, A. M., Mitchell, M. W., Mohney, R. P., Milburn, M. V., et al. (2012). Mining the unknown: a systems approach to metabolite identification combining genetic and metabolic information. PLoS Genet. 8:e1003005. doi: 10.1371/journal.pgen.1003005
Lee, J. M., Min Lee, J., Gianchandani, E. P., Eddy, J. A., and Papin, J. A. (2008). Dynamic analysis of integrated signaling, metabolic, and regulatory networks. PLoS Comput. Biol. 4:e1000086. doi: 10.1371/journal.pcbi.1000086
Lee, M. J., Ye, A. S., Gardino, A. K., Heijink, A. M., Sorger, P. K., MacBeath, G., et al. (2012). Sequential application of anticancer drugs enhances cell death by rewiring apoptotic signaling networks. Cell 149, 780–794. doi: 10.1016/j.cell.2012.03.031
Lee, T. I., and Young, R. A. (2013). Transcriptional regulation and its misregulation in disease. Cell 152, 1237–1251. doi: 10.1016/j.cell.2013.02.014
Lerman, J. A., Hyduke, D. R., Latif, H., Portnoy, V. A., Lewis, N. E., Orth, J. D., et al. (2012). In silico method for modelling metabolism and gene product expression at genome scale. Nat. Commun. 3, 929. doi: 10.1038/ncomms1928
Levy, R., and Borenstein, E. (2013). Metabolic modeling of species interaction in the human microbiome elucidates community-level assembly rules. Proc. Natl. Acad. Sci. U.S.A. 110, 12804–12809. doi: 10.1073/pnas.1300926110
Lewis, N. E., Nagarajan, H., and Palsson, B. O. (2012). Constraining the metabolic genotype-phenotype relationship using a phylogeny of in silico methods. Nat. Rev. Microbiol. 10, 291–305.
Lewis, N. E., Schramm, G., Bordbar, A., Schellenberger, J., Andersen, M. P., Cheng, J. K., et al. (2010). Large-scale in silico modeling of metabolic interactions between cell types in the human brain. Nat. Biotechnol. 28, 1279–1285. doi: 10.1038/nbt.1711
Locasale, J. W., Grassian, A. R., Melman, T., Lyssiotis, C. A., Mattaini, K. R., Bass, A. J., et al. (2011). Phosphoglycerate dehydrogenase diverts glycolytic flux and contributes to oncogenesis. Nat. Genet. 43, 869–874. doi: 10.1038/ng.890
Ma, H., Sorokin, A., Mazein, A., Selkov, A., Selkov, E., Demin, O., et al. (2007). The Edinburgh human metabolic network reconstruction and its functional analysis. Mol. Syst. Biol. 3, 135. doi: 10.1038/msb4100177
Ng, P. C., and Henikoff, S. (2006). Predicting the effects of amino acid substitutions on protein function. Annu. Rev. Genomics Hum. Genet. 7, 61–80. doi: 10.1146/annurev.genom.7.080505.115630
Oliveira, A. P., Ludwig, C., Picotti, P., Kogadeeva, M., Aebersold, R., and Sauer, U. (2012). Regulation of yeast central metabolism by enzyme phosphorylation. Mol. Syst. Biol. 8, 623. doi: 10.1038/msb.2012.55
Orth, J. D., Thiele, I., and Palsson, B. Ø. (2010). What is flux balance analysis. Nat. Biotechnol. 28, 245–248. doi: 10.1038/nbt.1614
Patil, K. R., and Nielsen, J. (2005). Uncovering transcriptional regulation of metabolism by using metabolic network topology. Proc. Natl. Acad. Sci. U.S.A. 102, 2685–2689. doi: 10.1073/pnas.0406811102
Possemato, R., Marks, K. M., Shaul, Y. D., Pacold, M. E., Kim, D., Birsoy, K., et al. (2011). Functional genomics reveal that the serine synthesis pathway is essential in breast cancer. Nature 476, 346–350. doi: 10.1038/nature10350
Prendergast, G. C. (2008). Immune escape as a fundamental trait of cancer: focus on IDO. Oncogene 27, 3889–3900. doi: 10.1038/onc.2008.35
Price, N. D., Reed, J. L., and Palsson, B. Ø. (2004). Genome-scale models of microbial cells: evaluating the consequences of constraints. Nat. Rev. Microbiol. 2, 886–897. doi: 10.1038/nrmicro1023
Resendis-Antonio, O., Checa, A., and Encarnación, S. (2010). Modeling core metabolism in cancer cells: surveying the topology underlying the warburg effect. PLoS ONE 5:e12383. doi: 10.1371/journal.pone.0012383
Robitaille, A. M., Christen, S., Shimobayashi, M., Cornu, M., Fava, L. L., Moes, S., et al. (2013). Quantitative phosphoproteomics reveal mTORC1 activates de novo pyrimidine synthesis. Science 339, 1320–1323. doi: 10.1126/science.1228771
Sasaki, M., Knobbe, C. B., Munger, J. C., Lind, E. F., Brenner, D., Brüstle, A., et al. (2012). IDH1(R132H) mutation increases murine haematopoietic progenitors and alters epigenetics. Nature 488, 656–659. doi: 10.1038/nature11323
Schuster-Böckler, B., and Lehner, B. (2012). Chromatin organization is a major influence on regional mutation rates in human cancer cells. Nature 488, 504–507. doi: 10.1038/nature11273
Semenza, G. L. (2003). Targeting HIF-1 for cancer therapy. Nat. Rev. Cancer 3, 721–732. doi: 10.1038/nrc1187
Sharma, A. K., and König, R. (2013). Metabolic network modeling approaches for investigating the “hungry cancer.” Semin. Cancer Biol. 23, 227–234. doi: 10.1016/j.semcancer.2013.05.001
Shlomi, T., Benyamini, T., Gottlieb, E., Sharan, R., and Ruppin, E. (2011). Genome-Scale metabolic modeling elucidates the role of proliferative adaptation in causing the warburg effect. PLoS Comput. Biol. 7:e1002018. doi: 10.1371/journal.pcbi.1002018
Shlomi, T., Cabili, M. N., Herrgård, M. J., Palsson, B. Ø., and Ruppin, E. (2008). Network-based prediction of human tissue-specific metabolism. Nat. Biotechnol. 26, 1003–1010. doi: 10.1038/nbt.1487
Simeonidis, E., Chandrasekaran, S., and Price, N. D. (2013). A guide to integrating transcriptional regulatory and metabolic networks using PROM (probabilistic regulation of metabolism). Methods Mol. Biol. 985, 103–112. doi: 10.1007/978-1-62703-299-5_6
Solit, D. B., and Mellinghoff, I. K. (2010). Tracing cancer networks with phosphoproteomics. Nat. Biotechnol. 28, 1028–1029. doi: 10.1038/nbt1010-1028
Thiele, I., Fleming, R. M. T., Bordbar, A., Schellenberger, J., and Palsson, B. Ø. (2010). Functional characterization of alternate optimal solutions of Escherichia coli's transcriptional and translational machinery. Biophys. J. 98, 2072–2081. doi: 10.1016/j.bpj.2010.01.060
Thiele, I., Fleming, R. M. T., Que, R., Bordbar, A., Diep, D., and Palsson, B. O. (2012). Multiscale modeling of metabolism and macromolecular synthesis in E. coli and its application to the evolution of codon usage. PLoS ONE 7:e45635. doi: 10.1371/journal.pone.0045635
Thiele, I., Swainston, N., Fleming, R. M. T., Hoppe, A., Sahoo, S., Aurich, M. K., et al. (2013). A community-driven global reconstruction of human metabolism. Nat. Biotechnol. 31, 419–425. doi: 10.1038/nbt.2488
Uhlen, M., Oksvold, P., Fagerberg, L., Lundberg, E., Jonasson, K., Forsberg, M., et al. (2010). Towards a knowledge-based Human Protein Atlas. Nat. Biotechnol. 28, 1248–1250. doi: 10.1038/nbt1210-1248
Vazquez, A., and Oltvai, Z. N. (2011). Molecular crowding defines a common origin for the Warburg effect in proliferating cells and the lactate threshold in muscle physiology. PLoS ONE 6:e19538. doi: 10.1371/journal.pone.0019538
Vazquez, A., Liu, J., Zhou, Y., and Oltvai, Z. N. (2010). Catabolic efficiency of aerobic glycolysis: the Warburg effect revisited. BMC Syst. Biol. 4:58. doi: 10.1186/1752-0509-4-58
Vogelstein, B., Papadopoulos, N., Velculescu, V. E., Zhou, S., Diaz, L. A., and Kinzler, K. W. (2013). Cancer genome landscapes. Science 339, 1546–1558. doi: 10.1126/science.1235122
Wang, Y., Eddy, J. A., and Price, N. D. (2012). Reconstruction of genome-scale metabolic models for 126 human tissues using mCADRE. BMC Syst. Biol. 6:153. doi: 10.1186/1752-0509-6-153
Wellen, K. E., Lu, C., Mancuso, A., Lemons, J. M. S., Ryczko, M., Dennis, J. W., et al. (2010). The hexosamine biosynthetic pathway couples growth factor-induced glutamine uptake to glucose metabolism. Genes Dev. 24, 2784–2799. doi: 10.1101/gad.1985910
Wishart, D. S., Jewison, T., Guo, A. C., Wilson, M., Knox, C., Liu, Y., et al. (2013). HMDB 3.0–the human metabolome database in 2013. Nucleic Acids Res. 41, D801–D807.
Yates, L. R., and Campbell, P. J. (2012). Evolution of the cancer genome. Nat. Rev. Genet. 13, 795–806. doi: 10.1038/nrg3317
Ye, Y. N., Wu, W. K. K., Shin, V. Y., and Cho, C. H. (2005). A mechanistic study of colon cancer growth promoted by cigarette smoke extract. Eur. J. Pharmacol. 519, 52–57. doi: 10.1016/j.ejphar.2005.07.009
Keywords: cancer, metabolism, omics, systems biology, constraint-based modeling, data analysis, modeling and simulation, warburg effect
Citation: Lewis NE and Abdel-Haleem AM (2013) The evolution of genome-scale models of cancer metabolism. Front. Physiol. 4:237. doi: 10.3389/fphys.2013.00237
Received: 30 May 2013; Accepted: 13 August 2013;
Published online: 03 September 2013.
Edited by:
Erwin Gianchandani, National Science Foundation, USAReviewed by:
Jason Papin, University of Virginia, USAHermann Frieboes, University of Louisville, USA
Copyright © 2013 Lewis and Abdel-Haleem. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Nathan E. Lewis, Department of Biology, Brigham Young University, 401 WIDB, Provo, UT 84602, USA e-mail: nlewis@byu.edu