 A. Radhika Ramya1,2
A. Radhika Ramya1,2 Lal Ahamed M1
Lal Ahamed M1 C. Tara Satyavathi3Abhishek Rathore2
C. Tara Satyavathi3Abhishek Rathore2 Pooja Katiyar2A. G. Bhasker Raj2Sushil Kumar4Rajeev Gupta2Mahesh D. Mahendrakar2
Pooja Katiyar2A. G. Bhasker Raj2Sushil Kumar4Rajeev Gupta2Mahesh D. Mahendrakar2 Rattan S. Yadav5
Rattan S. Yadav5 Rakesh K. Srivastava2*
Rakesh K. Srivastava2*- 1Department of Genetics and Plant Breeding, Acharya N. G. Ranga Agricultural University, Guntur, India
- 2International Crops Research Institute for the Semi-Arid Crops, Patancheru, India
- 3All India Coordinated Research Project on Pearl Millet, Indian Council of Agricultural Research, Jodhpur, India
- 4Centre of Excellence in Biotechnology, Anand Agricultural University, Anand, India
- 5Institute of Biological, Environmental and Rural Sciences, Aberystwyth University, Aberystwyth, United Kingdom
Pearl millet is a climate resilient crop and one of the most widely grown millets worldwide. Heterotic hybrid development is one of the principal breeding objectives in pearl millet. In a maiden attempt to identify heterotic groups for grain yield, a total of 343 hybrid parental [maintainer (B-) and restorer (R-)] lines were genotyped with 88 polymorphic SSR markers. The SSRs generated a total of 532 alleles with a mean value of 6.05 alleles per locus, mean gene diversity of 0.55, and an average PIC of 0.50. Out of 532 alleles, 443 (83.27%) alleles were contributed by B-lines with a mean of 5.03 alleles per locus. R-lines contributed 476 alleles (89.47%) with a mean of 5.41, while 441 (82.89%) alleles were shared commonly between B- and R-lines. The gene diversity was higher among R-lines (0.55) compared to B-lines (0.49). The unweighted neighbor-joining tree based on simple matching dissimilarity matrix obtained from SSR data clearly differentiated B- lines into 10 sub-clusters (B1 through B10), and R- lines into 11 sub-clusters (R1 through R11). A total of 99 hybrids (generated by crossing representative 9 B- and 11 R- lines) along with checks were evaluated in the hybrid trial. The 20 parents were evaluated in the line trial. Both the trials were evaluated in three environments. Based on per se performance, high sca effects and standard heterosis, F1s generated from crosses between representatives of groups B10R5, B3R5, B3R6, B4UD, B5R11, B2R4, and B9R9 had high specific combining ability for grain yield compared to rest of the crosses. These groups may represent putative heterotic gene pools in pearl millet.
Introduction
Pearl millet [Pennisetum glaucum (L.) R. Br.] known by several names, such as bulrush millet, spiked millet, cattail millet, candle millet, bajra, is a climate resilient nutritious cereal (Anuradha et al., 2017). It is widely distributed across arid and semi-arid tropics of Africa and Asia and other parts of the world. It is grown in about 29 mha in more than 30 countries. The major growing areas lie in Asia (>9 mha), Africa (about 18 mha), and America (>2 mha). It is one of the most widely cultivated cereals globally, ranking after rice, wheat, maize, barley, and sorghum in terms of area planted to these crops (Khairwal et al., 2007). The out-crossing breeding biology and wider adaptive nature lead to greater levels of diversity in pearl millet (Satyavathi et al., 2013; Singh et al., 2013).
Development of high-yielding hybrids is an important breeding objective for pearl millet worldwide. The availability, assessment, and exploitation of genetic diversity help to develop new cultivars and heterotic groups which would result in hybrids with a high degree of heterosis for grain yield. The assignment of germplasm into different heterotic groups is fundamental for maximum exploitation of heterosis for hybrid development (Gurung et al., 2009). Prediction of heterosis and F1 performance from the parental generation could largely enhance the efficiency of breeding hybrid or synthetic cultivars by reducing the costs associated with making crosses and field evaluation for selecting heterotic crosses (Teklewold and Becker, 2005). In pearl millet, a successful heterosis breeding program rests on the development of diverse seed (A-/B- lines) and pollen/restorer (R- lines) parents with distinctly separated gene pools. Limited information is available on the classification of a large number of hybrid parental lines based on molecular marker data, while there is no information available on the identification of heterotic pools in pearl millet using genomic tools. The present study was carried out with an objective to define putative heterotic gene pools in pearl millet assisted by expressed sequence tag (EST) and genomic SSR markers.
Materials and Methods
Genetic Material and DNA Extraction
The plant material used in the experiment comprised of 342 hybrid parental line of pearl millet which included 160 B- (maintainer) and 182 R- (restorer) lines along with Tift 23D2B1-P1-P5 (world reference germplasm) as control (repeated five times). These are International Crops Research Institute for the Semi-Arid Tropics (ICRISAT)-bred lines representing genetic diversity of mainly Asia and Africa. The world reference line, Tift 23D2B1-P1-P5 is a single plant selection done at ICRISAT from Tift 23D2B1 line which was bred at the Coastal Plain Experiment Station, Tifton, Georgia, USA. Tift 23D2B1-P1-P5 has recently been sequenced (Varshney et al., 2017). The list of experimental material with pedigree details are presented in Table S1. Leaf samples were collected from 15 to 20 days old seedlings and DNA isolation was carried out using high throughput DNA extraction method (Mace et al., 2003). The quantification of concentrated DNA were done on 0.8% agarose gel using Lambda DNA (New England BioLabs) as a standard. Based on the quantity of DNA, working stocks with diluted DNA were prepared at a concentration of 5 ng/μl for SSR genotyping.
Molecular Markers
Out of 124 markers used in this study, 88 SSR markers were selected for final analysis. These included 72 EST-SSRs (69 IPES and 3 ICMP) and 16 genomic SSRs. These SSRs produced clear, scorable and polymorphic profile upon PCR amplification. Number of repeats in the SSR motifs were 2, 3, 4, 5, and 6 for 30, 28, 10, 15, and 5 markers, respectively. Of the 88 SSR markers, 81 were mapped on the 7 linkage groups of pearl millet, with 14, 12, 10, 7, 6, 19, and 14 markers located on LG1, LG2, LG3, LG4, LG5, LG6, and LG7, respectively (Allouis et al., 2001; Qi et al., 2004; Senthilvel et al., 2008; Rajaram et al., 2013). The details of markers are presented in Table S2.
PCR (Polymerase Chain Reaction) Setup
PCR reactions were carried out as per Kumar et al. (2016) using GeneAmp PCR System 9700 thermal cycler (Applied Biosystems, USA). PCR reaction mixture of 5 μl was prepared in 384 well PCR plate which comprises of 1 μl DNA template, 0.3 μl of 2 mM dNTPs, 0.12 μl of 25 mM MgCl2, 0.5 μl of 2 pmole/μl forward and reverse primers each, 0.5 μl of 10X PCR buffer, 0.03 μl of 0.5 U Taq DNA polymerase and the rest was double sterilized water. PCR steps comprised of 94°C for 5 min, 40 cycles for 94°C for 10 s, 54°C for 20 s, 72°C 30 s, and a final extension at 72°C for 20 min. PCR products were size separated on 1.5% agarose gel.
SSR/Microsatellite Analysis
After confirmation of amplification, based on the amplicon size and forward primer label of the markers, different multiplex sets were defined to perform SSR genotyping. Each set consisted of 3–4 markers with different product sizes and labels in order to avoid ambiguity during data analysis. One microliter dye-labeled PCR products of each multiplex set were pooled and mixed with 7 μl of Hi-Di formamide, 0.15 LIZ-500 size standard (Applied Biosystems, USA) and 5 μl of distilled water. The pooled PCR amplicons were denatured for 5 min at 95°C and cooled immediately on ice. These amplicons were size separated based on the principle of capillary electrophoresis using an ABI Prism 3730 DNA analyzer (Applied Biosystems Inc.). Raw data obtained from ABI 3730 × l Genetic Analyser was subjected to analysis using the software Genemapper® version 4.0 (Applied Biosystems, USA). Based on the relative migration of internal size standard, product sizes were scored in base pairs (bp). Further analysis was done using Allelobin 2.0 program (Prasanth et al., 1997) based on repeat of SSR marker motif to get perfect allele calls.
The software package PowerMarker version 3.25 (Liu and Muse, 2005) was used to determine allele frequency, availability of data, allele number, gene diversity, heterozygosity, and polymorphic information content (PIC) from the marker data. A neighbor joining tree was constructed based on the simple matching dissimilarity matrix obtained from the marker data using DARwin 5.0.156 software (Perrier and Jacquemoud-Collet, 2006).
Hybridization
The crossing program was undertaken at ICRISAT, Patancheru during Summer, 2015. Based on the genetic distance obtained from the simple matching dissimilarity matrix constructed using genotyping data, mean representatives from each group were selected for crossing. In this study, 10 B- and 12 R- lines were selected to generate 120 crosses using line × tester mating design. Later on, one B- (from B7) and one R- (from R1) line were excluded from crossing plan due to a poor plant stand. Therefore, 99 crosses made from 9 B- (lines) and 11 R- (testers) lines were taken forward. The details of the selected parental lines are given in Table 1.
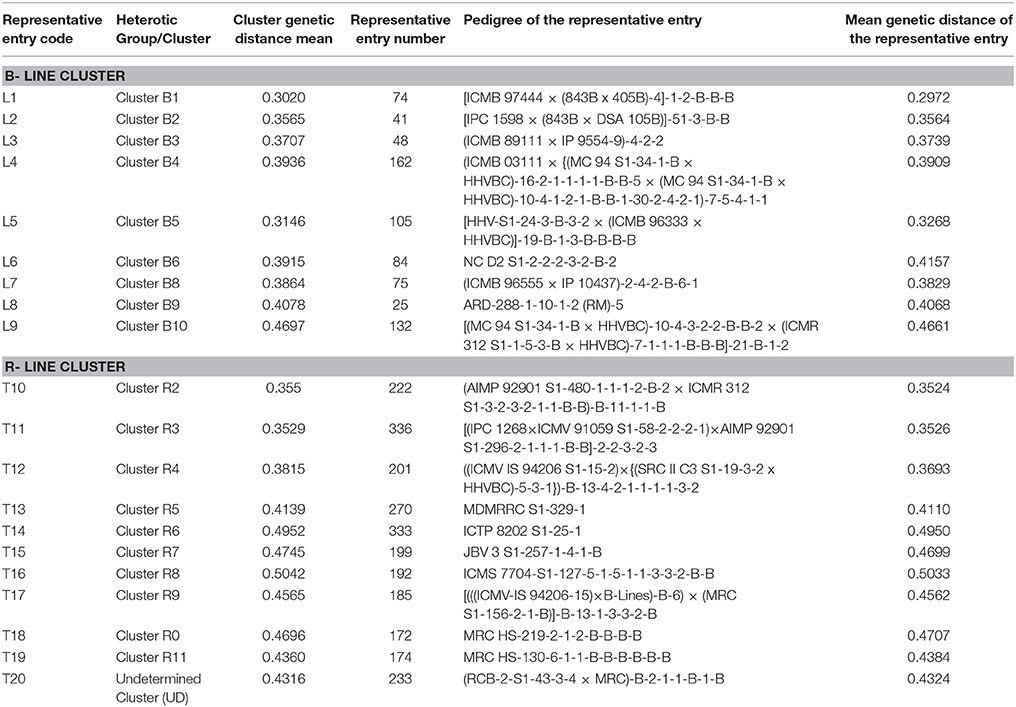
Table 1. Details of 9 B- and 11 R- lines used in the line × tester crossing design.
Evaluation of Parental Lines and F1 Crosses
The parental lines and F1 hybrids were evaluated in two contiguous, but separate trials at three locations. In the hybrid trial, a total of 123 F1 hybrids along with seven checks were evaluated, while in the inbred line trial a total of 60 inbred lines (54 inbreds + 6 checks) were evaluated during rainy season, 2015 over two locations viz., ICRISAT, Patancheru and Agricultural Research Station, Vizianagaram, Acharya N. G. Ranga Agricultural University (ANGRAU); and at one location during post-rainy season, 2015 at Agricultural College Farm, Naira, ANGRAU. Both hybrid and line trials were laid out in a two-replication Alpha lattice design, where each entry was sown in 2 rows of 2 m length, spaced at 15 cm between plants and 75 cm between rows. However, only 99 hybrids and three checks viz., HHB 67 Improved, ICMH 356 and HHB 146 Improved were considered for analysis in the hybrid trial, and 20 lines (11R- lines and 9 B- lines involved in the cross combinations) were considered for the line trial.
Standard agronomic management practices were followed in each of the trials viz., basal dose of 100 kg of DAP (diammonium phosphate, containing 18% N, 46% P) was applied at the time of field preparation and 100 kg of urea (46% N) was applied as top dressing to meet the recommended dose of 64 kg of N ha−1 and 46 of P ha−1; irrigations were given soon after sowing, subsequently as and when required. Seedlings were thinned at 15 days after sowing to maintain one healthy seedling per hill at a spacing of ~15 cm. The other cultural practices like weeding, protection against insects, pests, diseases and birds were done throughout the growing period as and when required. The data on grain yield was recorded on plot basis in all the experimental trials at all locations.
Statistical Analysis
The standard/useful/economic heterosis is superiority (or inferiority) of the F1 hybrid in relation to the check(s). It was calculated by the formula, [(F1 – check)/check] × 100. Analysis of variance (ANOVA) (Panse and Sukhatme, 1985) was performed to estimate the variance components among and within B- and R-line groups. Estimates of combining ability variances and effects were obtained using line × tester method suggested by Kempthorne (1957) and detailed by Singh and Chaudhary (1985). Statistical analysis was performed using PROC MIXED model in SAS software at ICRISAT, Patancheru. In this model, block within replications were kept random, while replications and genotypes were treated as fixed.
Analysis of molecular variance (AMOVA) (Excoffier et al., 1992), was performed using the software package GenAlEx version 6.5 (Peakall and Smouse, 2012) to estimate FST index which represented the distribution of allelic diversity across multiple levels of population subdivisions. Statistical significance for FST was computed by random permutation of all the population samples. PhiST was calculated after every reshuffling step for generation of a distribution of PhiST values. “Codom-Allelic” randomization method was selected where all alleles at a single locus were randomly shuffled among individuals. Comparison of the observed FST values to the distribution of 999 permutations provided P-values for the B- and R- lines.
Results
Molecular Diversity
Genetic parameters like total allele number, gene diversity, heterozygosity, and Polymorphism Information Content (PIC) are given in Table S3. The average availability [which is defined as (1 – Obs/n), where Obs is the number of observations, and n is the number of individuals sampled] of marker data for analysis was 89.0%.
Allele Size, Number, and Their Distribution Across Parental Lines
The SSR markers used in the present study had allele size within a range of 108–122 bp (Xipes0066) to 409–414 bp (Xipes0205). Moreover, all the markers used in the study had shown band sizes in correspondence with the expected band sizes. The check, Tift 23D2B1-P1-P5 repeated five times along with experimental material had shown identical allele size for each of the markers indicating the robustness of the results.
A total of 532 alleles were found among 342 parental lines and check with a mean value of 6.05 alleles per locus. The number of alleles ranged from 2 (Xipes0142, Xipes0079, Xipes0026, Xipes0205, Xpsmp2235, Xpsmp2253, and Xipes0147) to 28 (Xpsmp2070) alleles per locus, followed by Xipes0233 (21), Xipes0027 (17) and Xipes0098 (16). Seventy-two out of 88 markers detected alleles within the range of 3–10 with a mean value of 5.14 alleles per locus, whereas 5 markers identified alleles within the range of 11–15 with an average of 13.20. The 72 EST-SSRs used in study resulted an average of 5.89 alleles, ranged from 2 (Xipes0142, Xipes0079, Xipes0026, Xipes0205, and Xipes0147) to 21 (Xipes0233), whereas 16 genomic SSRs identified number of alleles which varied from 2 (Xpsmp2235 and Xpsmp2253) to 28 (Xpsmp2070), with a mean value of 6.75. Out of 532 alleles, 443 (83.27%) alleles were contributed by maintainer (B-) lines with a mean of 5.03 alleles per locus, whereas restorer (R-) lines contributed 476 alleles (89.47%) with a mean of 5.41. A total of 441 (82.89%) alleles out of 532 alleles were shared commonly between B- and R- lines. All the markers were polymorphic across R-lines, while one marker Xipes0147 was found to be monomorphic among B-lines.
Gene Diversity, Heterozygosity, and Polymorphism Information Content (PIC)
Gene diversity is defined as the probability that two randomly chosen alleles from the population are different. The average gene diversity in this study was 0.55, varied from 0.02 (Xipes0147) to 0.90 (Xpsmp2070). Out of 88 SSR markers, 60 loci showed gene diversity of equal to or more than 0.50, with a mean value of 0.66, whereas 28 markers resulted in gene diversity < 0.50 with a mean value of 0.29. The EST-SSRs and genomic SSRs recorded mean gene diversity values of 0.56 and 0.48, respectively. Based on individual analysis among B- and R- lines, pollen parents (0.55) had high average gene diversity than seed parents (0.49).
Seventy-one of the 88 SSR markers revealed heterozygosity, of which marker Xipes0226 detected maximum (0.12) heterozygotes followed by Xipes0027 (0.07) and Xipes0206 (0.07), while 21 markers could not find any heterozygotes. The mean heterozygosity was 0.02. Of 71 markers, 56 SSRs showed < 0.05 heterozygosity with an average of 0.02 and 11 SSRs had more than 0.05 heterozygosity with a mean of 0.06. The average heterozygosity was greater among R- lines (0.03) than B- lines (0.01).
The PIC ranged from 0.02 (Xipes0147) to 0.90 (Xpsmp2070) with an average of 0.50. Out of 88 markers, 50 markers showed PIC > 0.50 with a mean of 0.65, whereas 21 markers resulted in PIC values that ranged from 0.30 to 0.50, and rest of the 17 markers had PIC < 0.30. The PIC value ranged from 0.00 (Xipes0147) to 0.79 (Xipes0098) among B-lines and from 0.03 (Xpsmp2253) to 0.91 (Xpsmp2070) among R-lines with an average of 0.44 and 0.50 in B- and R- lines, respectively. The mean PIC value of EST-SSRs (0.51) was greater than that of genomic SSRs (0.45).
Grouping of B- and R- Lines Based on Genetic Distance
The dendrogram generated from the cluster analysis using simple matching dissimilarity matrix obtained from SSR data depicted in Figure 1 clearly differentiated the B- lines from R- lines. The B- and R-lines were further grouped into 10 clusters and 11 clusters, respectively. Dissimilarity coefficient values for 347 lines ranged from 0.78 between line 266 of cluster R6 and 163 of cluster B8 to 0.06 between 118 and 66 in cluster B4 with an average of 0.55.
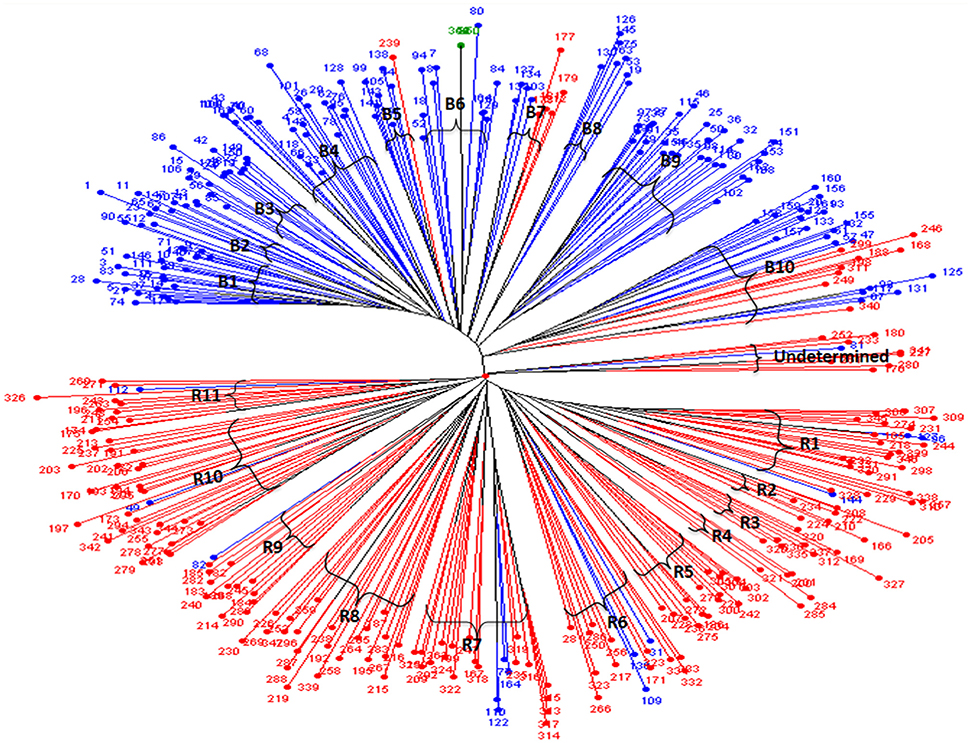
Figure 1. Unweighted neighbor joining tree based on the simple matching dissimilarity matrix of 88 SSR marker data for 347 hybrid parental lines. Lines in in blue are B- lines, line in green is Tift 23D2B1-P1-P5 (B-line, and the world reference genotype), lines in red are R- lines; B1 to B10 are the 10 sub-clusters of the B- lines; while R1 to R11 are the 11 sub-clusters of the R- lines.
Among the clusters of B- lines, the cluster B10 was largest with 28 lines. It comprised of 20 seed parents and 8 pollen parents, while smallest cluster was B8 with 7 maintainer lines. The clusters B1, B3, B4, B6, and B9 consisted of 26, 14, 22, 15, and 27 B-lines, respectively. The remaining clusters B2 comprised of 9 B-lines, B5 grouped 7 B- and 1 R-lines and B7 had 4 B- and 5 R-lines in their clusters. Out of 10 clusters of B-lines, 6 had more than 13 lines, whereas 4 clusters possessed < 10 lines in their groups. Based on individual cluster analysis, the lines in B1, B2, B3, B4, B5, B6, B7, B8, B9, and B10 were grouped at 0.30, 0.36, 0.37, 0.39, 0.31, 0.39, 0.39, 0.39, 0.41, and 0.47 genetic dissimilarity values. The mean representative entries in each cluster on the basis of dissimilarity values were 74 (0.30), 41 (0.36), 48 (0.37), 162 (0.39), 105 (0.33), 84 (0.42), 137 (0.40), 75 (0.38), 25 (0.41), and 132 (0.47) in B1, B2, B3, B4, B5, B6, B7, B8, B9, and B10, respectively.
Amongst the clusters of R-lines, R10 was the largest with 28 lines with 27 R- lines and one B-line and R4 was the smallest cluster with 5 R-lines. The remaining clusters of R- lines were R1, R2, R3, R5, R6, R7, R8, R9, and R11 with 25 (22 R- and 3 B-lines), 7, 8, 16, 15 (12R- and 3 B-lines), 22 (18 R- and 4 B-lines), 22, 13 (12 R-lines and 1B-line), and 12 (11 R-lines and 1 B-line) lines, respectively. On the basis of individual cluster analysis, the grouping of clusters R1, R2, R3, R4, R5, R6, R7, R8, R9, R10, and R11 was done at genetic dissimilarity values of 0.41, 0.35, 0.35, 0.38, 0.41, 0.50, 0.47, 0.50, 0.46, 0.47, and 0.44, respectively. The mean representative entries in each cluster on the basis of dissimilarity values were 298 (0.40), 222 (0.35), 336 (0.35), 201 (0.37), 270 (0.41), 333 (0.50), 199 (0.47), 192 (0.50), 185 (0.46), 172 (0.47), and 174 (0.44) in R1, R2, R3, R4, R5, R6, R7, R8, R9, R10, and R11, respectively. Nine lines were included in the undetermined cluster at dissimilarity value of 0.43 and the representative entry of this cluster was 233 (0.43).
Analysis of Variance (ANOVA) and Analysis of Molecular Variance (AMOVA)
The combined analysis of variance for grain yield of the testcross hybrids generated by crossing 9 representative B- lines with 10 representative R- lines and one representative R- line from the undetermined cluster is presented in Table 2A. The analysis of variance revealed highly significant (P = 0.001) differences between the clusters for different cross combinations.

Table 2A. Combined analysis of variance of the testcross hybrids generated on 11 representative R-lines for grain yield.
AMOVA was generated using genotyping data from 88 microsatellite loci for 160 B- lines and 182 R-lines. The comparison of the observed FST values to the distribution of 999 permutations provided highly significant (P = 0.001) differences between the 10 B- line clusters; and between 10 R- line clusters, and an undetermined group. Genetic variations among individual for B- and R- lines (96 and 94%, respectively) was significantly higher compared to within individual variance for B- and R- lines (2 and 5%, respectively) (Table 2B).
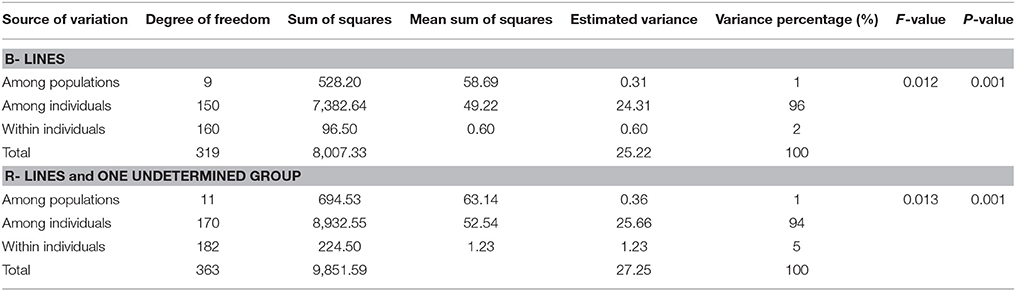
Table 2B. Analysis of molecular variance (AMOVA) for B- and R- line clusters.
Combined Analysis of Variance for Combining Ability
Analysis of variance for combining ability for different grain yield per plant based on line × tester analysis is presented in Table 3. The pooled analysis of variance showed highly significant (P ≤ 0.01) differences among parents, hybrids, hybrids vs. parents, parents × environment interaction, hybrid × environment interaction for grain yield per plant.
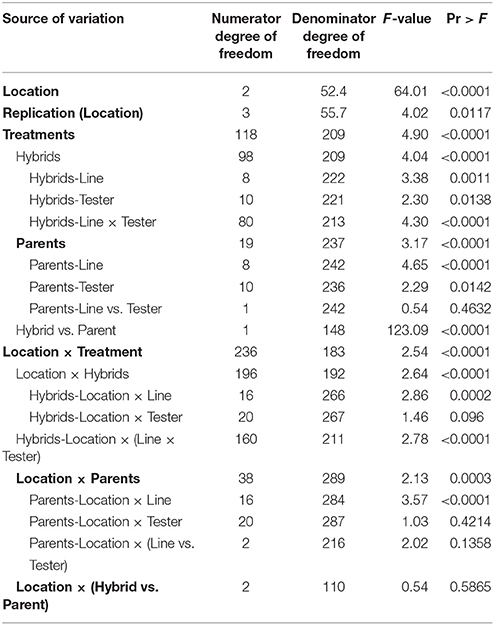
Table 3. Combined analysis of variance for combining ability of grain yield per plant based on pooled data of three environments.
Per se Performance of Parents and Hybrids, General Combining Ability (GCA), and Specific Combining Ability (SCA) Effects
The details on per se performance of parents and hybrids, general combining ability and specific combining ability effects for grain yield per plant based on pooled data of three environments are presented in Tables 4, 5. The mean values of grain yield per plant among the B- line groups varied from 15.12 (B1) to 36.91 g (B2) with a mean of 22.04 g, whereas amongst the R- line groups the range varied from 16.75 (R4) to 34.51 g (R5) with an average of 23.27 g. The mean of hybrids varied from 20.74 (B3R9) to 70.88 g (B10R5) with a mean of 33.94 g. Based on the pooled mean performance of 99 F1s generated from cross between a representative of each B- line group with a representative of each R- line group, cluster combination B1R3 (42.66 g), B2R4 (42.24 g), B3R5 (57.23 g), B4UD (47.73 g), B5R11 (43.88 g), B6R3 (44.25 g), B8R4 (39.87 g), B9R7 (38.26 g) and B10R5 (70.88 g) recorded high grain yield per plant than their counterparts.
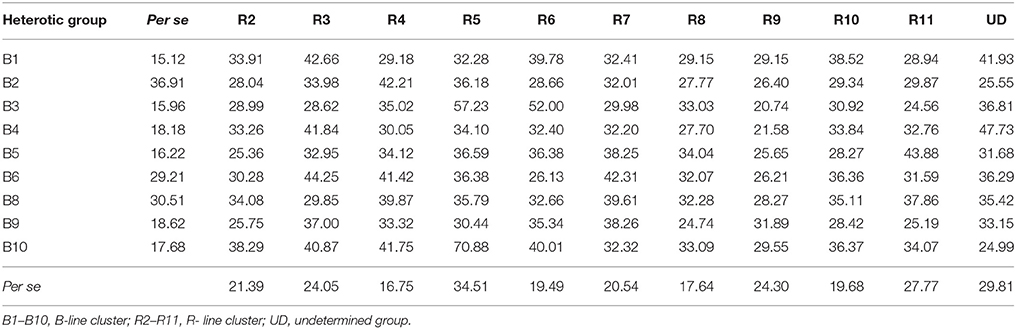
Table 4. Per se performance of B- and R-lines, hybrids for grain yield per plant in line × tester analysis based on pooled data of three environments.
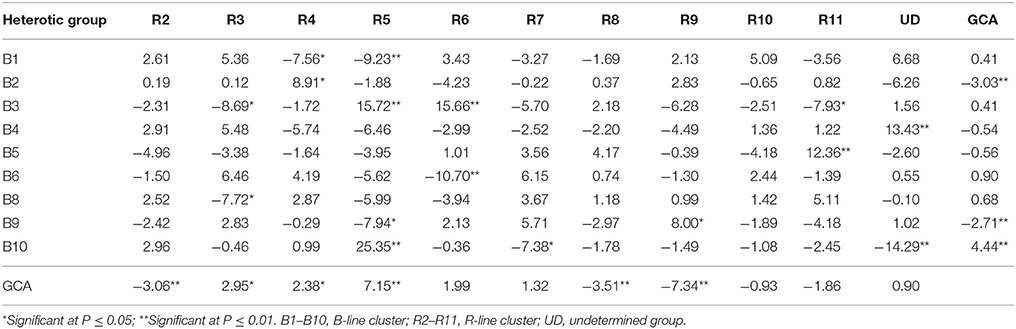
Table 5. General combining ability (GCA) effects of parents and specific combining ability (SCA) effects of crosses for grain yield per plant based on pooled data of three environments.
The gca effects for grain yield per plant varied from −3.03** (B2) to 4.44** (B10) among B- line groups and among R- line groups the range varied from −7.34** (R9) to 7.15** (R5). Only one B- line, B10 (4.44**) and three R- lines, R5 (7.15**), R3 (2.95*) and R4 (2.38*) exhibited positive and significant gca effects whereas two B- lines, B2 (−3.03**) and B9 (−2.71**) and three R-lines, R9 (−7.34**), R8 (−3.51**), and R2 (−3.06**) showed negative and significant gca effects.
Among 99 hybrids, sca effects varied from −14.29** (B10UD) to 25.35** (B10R5). Nine and seven hybrids possessed significant negative and positive sca effects, respectively. Of seven hybrids (mean ranged from 31.89 to 70.88 g) with specific combining ability in a desirable direction, three crosses had at least one best general combiner for this trait as their parent. The cross combination, B10R5 (25.35**) with H+ gca x H+ gca parental combination, showed highest significant sca effect followed by B3R5 (15.72**) (L+ gca x H+ gca), B3R6 (15.66**) (L+ gca x L+ gca), B4UD (13.43**) (L− gca x L+ gca), B5R11 (12.36**) (L− gca x L− gca), B2R4 (8.91*) (H− gca x H+ gca), and B9R9 (8.00*) (H− gca x H− gca).
Standard Heterosis
The estimates of standard heterosis for yield over standard checks (HHB 67 Improved, ICMH 356 and HHB 146 Improved) of 99 F1s is presented in the Table 6. The range of standard heterosis over check HHB 67 Improved ranged from −48.86* (B3R9) to 74.12** (B10R5), for the check, ICMH 356, it ranged from −49.50* (B3R9) to 71.93** (B10R5), and for the check, HHB 146 Improved, the standard heterosis ranged from −42.67 (B3R9) to 95.21** (B10R5). Positive heterosis is a desirable feature for this trait. Two of 99 hybrids, B10R5 (95.21**), and B3R5 (57.10*) recorded significant positive standard heterosis over the superior check, HHB 146 Improved.
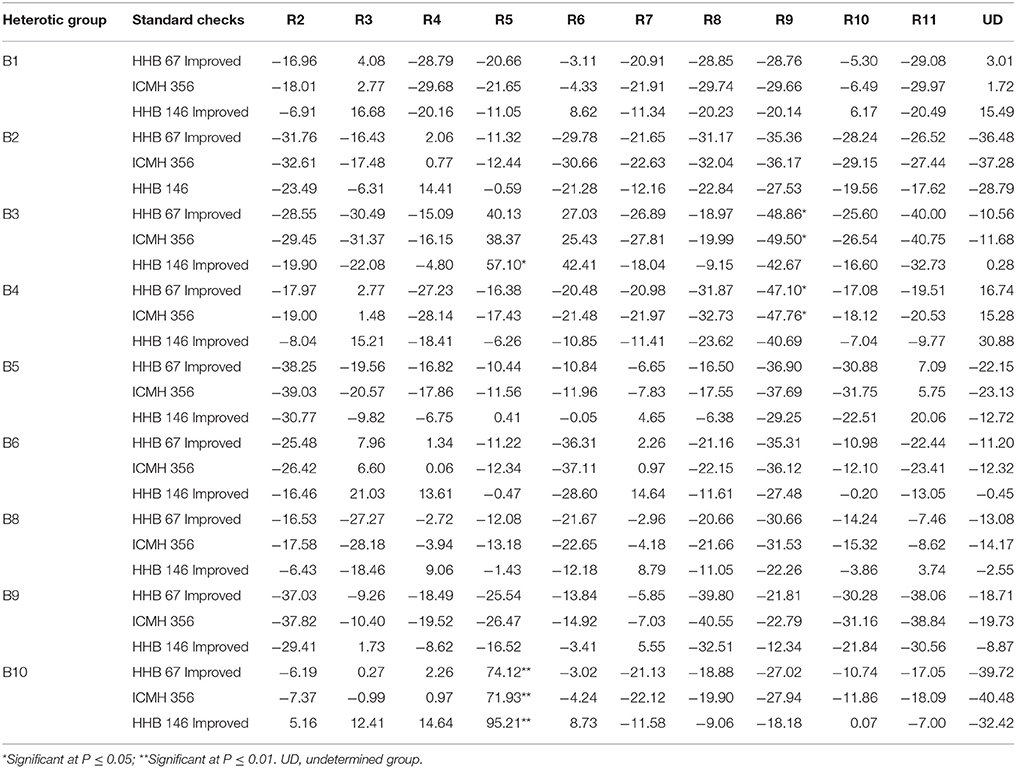
Table 6. Standard heterosis over three checks for grain yield per plant using data of three environments.
Discussion
Heterosis has been an area of intense research in many cross-pollinated and a few self- and often cross-pollinated crops for over a century. It has been defined as the superior (or inferior) performance of the F1 hybrid relative to the mid-parent value (mid-parent/average heterosis), or to the better parent (better-parent heterosis or heterobeltiosis), or over a suitable check cultivar (standard heterosis).
Identification of heterotic grouping is an important exercise in crop species where hybrids are prevalent. In pearl millet so far no information is available on heterotic gene pools using genomic tools. In this first report, we used SSR-based groupings to generate information on heterotic groups in pearl millet. We used the world reference genotype Tift23 D2B1-P1-P5 as a check in our study. The identical allele size of the check for each marker indicated the accuracy of protocol and reproducibility of the allelic data for the set of markers used in this study. The number of alleles obtained in the present investigation was higher than the earlier reports in pearl millet (Chandra-Shekara et al., 2007; Chakauya and Tongoona, 2008; Satyavathi et al., 2013; Singh et al., 2013; Sumanth et al., 2013; Kapadia et al., 2016). On the other hand, higher number of alleles per locus were detected than present study in pearl millet (Mariac et al., 2006; Kapila et al., 2008; Stich et al., 2010; Nepolean et al., 2012). The variation in allele number from one study to other might be due to type of material/sample (less or more diverse), sample size, type, and number of markers and repeat motifs of markers used in the investigation (Yang et al., 2010). A maximum number of alleles was identified by the marker Xpsmp2070, which was in agreement with the finding of Nepolean et al. (2012).
Markers with high gene diversity resulted in more number of alleles among the lines used in the study. The average gene diversity among germplasm of pearl millet was lower than earlier reports of Mariac et al. (2006) in wild sample, Stich et al. (2010), Nepolean et al. (2012). The lower average gene diversity in the present study than earlier findings might be due to type, size of sample, type, and number of markers. For instance, Mariac et al. (2006) detected gene diversity of 0.49 and 0.67 among cultivated and wild samples of pearl millet respectively. The gene diversity was found to be high among R-lines than B-lines as in Nepolean et al. (2012).
The greater heterozygosity observed in R-lines than B-lines was in correspondence with the findings of Nepolean et al. (2012). Even though pearl millet is a highly cross pollinated crop, the amount of heterozygosity observed among inbred lines was very less, which could be due to homogeneous and homozygous nature of inbreds obtained from several generations of directional selections and selfings. The small amount of heterozygosity found in experimental materials may be due to high mutational rate and mutational bias at the SSR loci (Udupa and Baum, 2001).
PIC is the best indicator for identification of most informative markers. A total of 50 markers were found to be highly informative with PIC ≥ 0.50, and can be used for discrimination of genotypes. The average PIC value in present study was higher than that reported in pearl millet inbred lines (Singh et al., 2013; Sumanth et al., 2013; Kapadia et al., 2016), but lower than that reported in pearl millet (Nepolean et al., 2012; Satyavathi et al., 2013). The average PIC of B-lines was lower than R-lines was in accordance with the study of Nepolean et al. (2012). Detection of high gene diversity and PIC among EST-SSRs than genomic SSRs revealed that EST-SSR markers had high discriminative power than genomic SSR markers, which is supported by Ramu et al. (2013). It might also be due to higher directional selection for a different set of traits in B- and R- lines, resulting in more genetic diversity in the intra-genomic regions over inter-genomic regions. Detection of a maximum number of alleles, highest gene diversity and high PIC by Xpsmp2070 among maintainer and restorer lines of pearl millet was in corroboration with the finding of Nepolean et al. (2012).
The clear differentiation of B- lines from R-lines with some intrusions was in correspondence with the finding of Nepolean et al. (2012). Based on genetic dissimilarity values, grouping of inbred lines was done at an average genetic distance of 0.55 indicated the presence of a moderate level of genetic variation among the lines used in the study. Likewise, many findings on grouping of germplasm based on marker genetic distance were reported in pearl millet by Stich et al. (2010), Nepolean et al. (2012), Satyavathi et al. (2013), Singh et al. (2013), Sumanth et al. (2013), and Kapadia et al. (2016).
The lines with similar a pedigree in their parentage are grouped together in the same cluster with minor deviations indicated the precision of marker-based genetic distance in grouping of the diverse parental lines. For example, among B- line clusters, in B1, 21 lines had 843B as a common parent in their pedigree, while remaining lines possessed mixed parentage. The check Tift 23D2B1-P1-P5 which was repeated five times in the experiment grouped in B6, indicating the accuracy of the protocol adopted and reproducibility of the analyzed data. In B10, 14 lines had (MC 94 S1-34-1-B × HHVBC) in their parentage. In addition, B10 comprised of eight R-lines, of which six had [((MC 94 S1-34-1-B × HHVBC)-16-2-1) × (IP 19626-4-2-3)] in their pedigrees.
Likewise, amongst the R- line clusters, one B- line grouped with R-lines in R1 cluster, which might be due to its common parentage with most of the lines in the corresponding cluster. The lines with ICMR 312 in their parentage grouped in R2, while lines with AIMP 92901 clustered in R3. The cluster R5 is dominated by lines derived from crosses involving ICMR 312 S1-3-2-1-2-4 in their parentage. Majority of the lines possessed (SRC II C3 S1-19-3-2 × HHVBC) commonly in their parentages in R7, where B- lines were grouped in this cluster which could be due to involvement of cross combination (SRC II C3 S1-19-3-2 × HHVBC) in their parentages. In the cluster R10, out of 28, 16 lines possessed MRC series in their pedigree. A similar result of coincidence of clustering patterns based on marker distance with pedigree data was given by Satyavathi et al. (2013).
The presence of significant phenotypic differences for grain yield between the 11 R- line groups involved in a total of 99 crosses, and significant molecular differences among B- and R- line clusters (Tables 2A,B) suggested the existence of sufficient phenotypic and genetic variation in the experimental material for heterotic gene pool formation exercise.
Based on the gca effects, one B-line 132 (B10) and three R- lines 336 (R3), 201 (R4), and 270 (R5) were found as good general combiners for the trait, grain yield per plant. Therefore the lines of groups (represented by mean representative entries) with trait of interest can be utilized in breeding program straightaway as parents for production of hybrids by crossing with other divergent lines or may be used in the line development programs.
Seven cross combinations, B10R5, B3R5, B3R6, B4UD, B5R11, B2R4, and B9R9 with high specific combining ability effects in desirable direction were obtained from the parental combinations of (H+ gca × H+ gca), (L+ gca × H+ gca), (L+ gca × L+ gca), (L− gca × L+ gca), (L− gca × L− gca), (H− gca × H+ gca), (H− gca × H− gca), respectively. The cross between two high general combiners revealed additive and additive × additive genetic components of variance. The cross between high × low general combiners that resulted in superior cross combination might be due to complimentary action arising out of both additive and non-additive genetic components. The superiority of the crosses having low gca parents may be due to high nicking ability and high sca effects for the parents. It will, therefore, be rewarding to design hybrid breeding programs which precisely estimate not just gca effects, but also sca effects of the hybrid parental lines by making factorial crosses with the right set of testers. Also, since every B- and R- line cluster was different and distinct in terms of genetic distance, the presence of heterotic combinations in just a few groups over others, suggests a more complex interaction of genetic distance with sca effects. This result is similar to Pucher et al. (2016) who reported statistically non-significant differences in the grain yield between the inter- and intra-country crosses in pearl millet.
Based on overall performance (per se performance, high sca effects and standard heterosis over superior check), the best heterotic cross combinations identified for grain yield per plant were obtained from F1s generated from mean representatives of groups B3 and B10 with representative of group R5. Other high yielding cross combinations were obtained between groups B1 and R3, B2 and R4, B3 and R5, B4 and undetermined cluster, B5 and 11R, B6 and R3, B8 and R4, B9 and R7 and B10 and R5. This clearly suggests that the crosses between the given B × R combinations from the specific clusters resulted in higher grain yield compared to the other groups. These may be due to a high degree of gene complementation and dispersion of favorable alleles between the groups for the manifestation of a higher degree of heterosis. These groups may represent putative heterotic gene pools in pearl millet.
Conclusion
The current study is a step closer toward defining heterotic gene pools in pearl millet. A relatively large number of B- and R- lines were grouped using SSR-assisted genetic distances. Their representative testcross hybrids were evaluated in three environments in this study, which shed light on the existence of putative heterotic gene pools in B- and R- lines for the first time. However, these heterotic groups need to be further refined and broadened by selecting more appropriate set of testers for maximizing combining ability, and by evaluating the testcross hybrids in more number of representative environments.
Apart from further study on the genetic aspects, it might be interesting to integrate epigenomics, metabolomics, proteomics, and systems biology approaches for gaining better insights into the heterotic gene pools of pearl millet.
Author Contributions
RS planned and coordinated this study. ARR, PK, AGBR generated lab and field data. AR helped in data analysis. RS, CS, RG, RY, LA provided technical guidance during the conduct of research work. RS, ARR, RG, CS, SK, RY, MM drafted the manuscript. RS critically revised the paper for final publication.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The research work was financially supported by the S.M. Sehgal Foundation Endowment Fund, ICRISAT. The authors are thankful to the authorities of ANGRAU for providing facilities to carry out field evaluations. This work has been published as part of the CGIAR Research Program on Dryland Cereals.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2017.01934/full#supplementary-material
References
Allouis, S., Qi, X., Lindup, S., Gale, M. D., and Devos, K. M. (2001). Construction of a BAC library of pearl millet, Pennisetum glaucum. Theor. Appl. Genet. 102, 1200–1205. doi: 10.1007/s001220100559
Anuradha, N., Satyavathi, C. T., Bharadwaj, C., Nepolean, T., Sankar, S. M., Singh, S. P., et al. (2017). Deciphering genomic regions for high grain iron and zinc content using association mapping in pearl millet. Front. Plant Sci. 8:412. doi: 10.3389/fpls.2017.00412
Chakauya, E., and Tongoona, P. (2008). Analysis of genetic relationships of pearl millet [Pennisetum glaucum (L.)] land races from Zimbabwe, using microsatellites. Int. J. Plant Breed. Genet. 2, 35–41. doi: 10.3923/ijpbg.2008.35.41
Chandra-Shekara, A. C., Prasanna, B. M., Bhat, S. R., and Singh, B. B. (2007). Genetic diversity analysis of elite pearl millet inbred lines using RAPD and SSR markers. J. Plant Biochem. Biotechnol. 16, 23–28. doi: 10.1007/BF03321924
Excoffier, L., Smouse, P. E., and Quattro, J. M. (1992). Analysis of molecular variance inferred from metric distances among DNA haplotypes: application to human mitochondrial DNA restriction data. Genetics 131, 479–491.
Gurung, D. B., George, M. L. C., and Delacruz, Q. D. (2009). Determination of heterotic groups in nepalese yellow maize populations. Nepal J. Sci. Technol. 10, 1–8. doi: 10.3126/njst.v10i0.2802
Kumar, S., Hash, C. T., Thirunavukkarasu, N., Singh, G., Rajaram, R., Rathore, A., et al. (2016). Mapping quantitative trait loci controlling high iron and zinc content in self and open pollinated grains of pearl millet [Pennisetum glaucum (L.) R. Br.]. Front. Plant. Sci. 7:1636. doi: 10.3389/fpls.2016.01636
Kapadia, V. N., Bhalala, K. C., Raiyani, A. M., Saiyad, M. R., and Sushilkumar (2016). Genetic diversity analysis of elite forage pearl millet [Pennisetum glaucum (L.) R Br.] inbred lines using SSR markers. Adv. Life Sci. 5, 2278–3849.
Kapila, R. K., Yadav, R. S., Plaha, P., Rai, K. N., Yadav, O. P., Hash, C. T., et al. (2008). Genetic diversity among pearl millet maintainers using microsatellite markers. Plant Breed. 127, 33–37. doi: 10.1111/j.1439-0523.2007.01433.x
Kempthorne, O. (1957). An Introduction to Genetic Statistics. New York, NY; London: John Wiley and Sons Inc.; Chapman and Hall.
Khairwal, I. S., Rai, K. N., Diwakar, B., Sharma, Y. K., Rajpurohit, B. S., Nirwan, B., et al. (2007). “Pearl millet,” in Crop Management and Seed Production Manual. (Patancheru: International Crops Research Institute for the Semi-Arid Tropics), 104.
Liu, K., and Muse, S. V. (2005). PowerMarker: integrated analysis environment for genetic marker data. Bioinformatics 21, 2128–2129. doi: 10.1093/bioinformatics/bti282
Mace, E. S., Buhariwalla, H. K., and Crouch, J. H. (2003). A high-throughput DNA extraction protocol for tropical molecular breeding programs. Plant Mol. Biol. Rep. 21, 459a−459h. doi: 10.1007/BF02772596
Mariac, C., Luong, V., Kapran, I., Mamadou, A., Sagnard, F., Deu, M., et al. (2006). Diversity of wild and cultivated pearl millet accessions [Pennisetum glaucum (L.) R. Br.] in Niger assessed by microsatellite markers. Theor. Appl. Genet. 114, 49–58. doi: 10.1007/s00122-006-0409-9
Nepolean, T., Gupta, S. K., Dwivedi, S. L., Bhattacharjee, R., Rai, K. N., and Hash, C. T. (2012). Genetic diversity in maintainer and restorer lines of pearl millet. Crop Sci. 52, 2555–2563. doi: 10.2135/cropsci2011.11.0597
Panse, V. G., and Sukhatme, P. V. (1985). Statistical Methods for Agricultural Workers. New Delhi: Indian Council of Agricultural Research Publications.
Peakall, R., and Smouse, P. E. (2012). GenAlEx 6.5: Genetic analysis in excel. Population genetic software for teaching and research- an update. Bioinformatics 28, 2537–2539. doi: 10.1093/bioinformatics/bts460
Perrier, X., and Jacquemoud-Collet, J. P. (2006). DARwin Software. Available online at: http://darwin.cirad.fr/darwin
Prasanth, V. P., Chandra, S., Jayashree, B., and Hoisington, D. (1997). AlleloBin - A Program for Allele Binning of Microsatellite Markers Based on the Algorithm of Idury and Cardon. Patancheru: ICRISAT.
Pucher, A., Sy, O., Sanogo, M. D., Angarawai, I. I., Zangre, R., Ouedraogo, M., et al. (2016). Combining ability patterns among West African pearl millet landraces and prospects for pearl millet hybrid breeding. Field Crops Res. 195, 9–20. doi: 10.1016/j.fcr.2016.04.035
Qi, X., Pittaway, T. S., Lindup, S., Liu, H., Waterman, E., Padi, F. K., et al. (2004). An integrated genetic map and a new set of simple sequence repeat markers for pearl millet, Pennisetum glaucum. Theor. Appl. Genet. 109, 1485–1493. doi: 10.1007/s00122-004-1765-y
Rajaram, V., Nepolean, T., Senthilvel, S., Varshney, R. K., Vadez, V., Srivastava, R. K., et al. (2013). Pearl millet [Pennisetum glaucum (L.) R. Br.] consensus linkage map constructed using four RIL mapping populations and newly developed EST-SSRs. BMC Genomics 14:159. doi: 10.1186/1471-2164-14-159
Ramu, P., Billot, C., Rami, J. F., Senthilvel, S., Upadhyaya, H. D., Reddy, L. A., et al. (2013). Assessment of genetic diversity in the sorghum reference set using EST-SSR markers. Theor. Appl. Genet. 126, 2051–2064. doi: 10.1007/s00122-013-2117-6
Satyavathi, C. T., Tiwari, S., Bharadwaj, C., Rao, A. R., Bhat, J., and Singh, S. P. (2013). Genetic diversity analysis in a novel set of restorer lines of pearl millet [Pennisetum glaucum (L.) R. Br] using SSR markers. Vegetos 26, 72–82. doi: 10.5958/j.2229-4473.26.1.011
Senthilvel, S., Jayashree, B., Mahalakshmi, V., Sathish Kumar, P., Nakka, S., Nepolean, T., et al. (2008). Development and mapping of simple sequence repeat markers for pearl millet from data mining of Expressed Sequence Tags. BMC Plant Biol. 8:119. doi: 10.1186/1471-2229-8-119
Singh, A. K., Rana, M. K., Singh, S., Kumar, S., Durgesh, K., and Arya, L. (2013). Assessment of genetic diversity among pearl millet [Pennisetum glaucum (L.) R Br.] cultivars using SSR markers. Range Manag. Agrofor. 34, 77–81.
Singh, R. K., and Chaudhary, B. D. (1985). Biometrical Methods in Quantitative Genetic Analyses. Ludhiana; New Delhi: Kalyani Publishers.
Stich, B., Haussmann, B. I. G., Pasam, R., Bhosale, S., Hash, C. T., Melchinger, A. E., et al. (2010). Patterns of molecular and phenotypic diversity in pearl millet [Pennisetum glaucum (L.) R. Br.] from West and Central Africa and their relation to and environmental parameters. BMC Plant Biol. 10:216. doi: 10.1186/1471-2229-10-216
Sumanth, M., Sumathi, P., Vinodhana, N. K., and Sathya, M. (2013). Assessment of genetic distance among the inbred lines of pearl millet (Pennisetum glaucum (L.) R. Br.) using SSR markers. Int. J. Biotechnol. Allied Fields 1, 153–162.
Teklewold, A., and Becker, H. C. (2005). Comparison of phenotypic and molecular distances to predict heterosis and F1 performance in Ethiopian mustard (Brassica carinata A. Braun). Theor. Appl Genet. 112, 752–759. doi: 10.1007/s00122-005-0180-3
Udupa, S. M., and Baum, M. (2001). High mutation rate and mutational bias at (TAA)n microsatellite loci in chickpea (Cicer arietinum L.). Mol. Genet. Genomics 265, 1097–1103. doi: 10.1007/s004380100508
Varshney, R. K., Shi, C., Thudi, M., Mariac, C., Wallace, J., Qi, P., et al. (2017). Pearl millet genome sequence provides a resource to improve agronomic traits in arid environments. Nat. Biotechnol. 35, 969–976. doi: 10.1038/nbt.3943
Keywords: pearl millet, B- (maintainer) lines, R- (restorer) lines, SSR (simple sequence repeat) markers, gene diversity, PIC (polymorphism information content), heterotic groups
Citation: Ramya AR, Ahamed M L, Satyavathi CT, Rathore A, Katiyar P, Raj AGB, Kumar S, Gupta R, Mahendrakar MD, Yadav RS and Srivastava RK (2018) Towards Defining Heterotic Gene Pools in Pearl Millet [Pennisetum glaucum (L.) R. Br.]. Front. Plant Sci. 8:1934. doi: 10.3389/fpls.2017.01934
Received: 30 June 2017; Accepted: 26 October 2017;
Published: 02 March 2018.
Edited by:
Prashant Vikram, International Maize and Wheat Improvement Center, MexicoReviewed by:
Elisabetta Frascaroli, Università di Bologna, ItalyVikrant Singh, Punjab Agricultural University, India
Copyright © 2018 Ramya, Ahamed M, Satyavathi, Rathore, Katiyar, Raj, Kumar, Gupta, Mahendrakar, Yadav and Srivastava. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rakesh K. Srivastava, r.k.srivastava@cgiar.org