 Baljinder K. Sahdra
Baljinder K. Sahdra Joseph Ciarrochi
Joseph Ciarrochi Philip Parker1
Philip Parker1 Luca Scrucca
Luca Scrucca- 1Institute for Positive Psychology and Education, Australian Catholic University, Strathfield, NSW, Australia
- 2Department of Economics, University of Perugia, Perugia, Italy
Genetic algorithms (GAs) are robust machine learning approaches for abbreviating a large set of variables into a shorter subset that maximally captures the variance in the original data. We employed a GA-based method to shorten the 62-item Multidimensional Experiential Avoidance Questionnaire (MEAQ) by half without much loss of information. Experiential avoidance or the tendency to avoid negative internal experiences is a key target of many psychological interventions and its measurement is an important issue in psychology. The 62-item MEAQ has been shown to have good psychometric properties, but its length may limit its use in most practical settings. The recently validated 15-item brief version (BEAQ) is one short alternative, but it reduces the multidimensional scale to a single dimension. We sought to shorten the 62-item MEAQ by half while maintaining fidelity to its six dimensions. In a large nationally representative sample of Americans (N = 7884; 52% female; Age: M = 47.9, SD = 16), we employed a GA method of scale abbreviation implemented in the R package, GAabbreviate. The GA-derived short form, MEAQ-30 with five items per subscale, performed virtually identically to the original 62-item MEAQ in terms of inter-subscales correlations, factor structure, factor correlations, and zero-order correlations and unique latent associations of the six subscales with other measures of mental distress, wellbeing and personal strivings. The two measures also showed similar distributions of means across American census regions. The MEAQ-30 provides a multidimensional assessment of experiential avoidance whilst minimizing participant burden. The study adds to the emerging literature on the utility of machine learning methods in psychometrics.
Introduction
Recent methodological advances in scale abbreviation have demonstrated genetic algorithms (GAs) to be robust machine learning approaches to short-form construction (Yarkoni, 2010; Eisenbarth et al., 2015), which work just as well as traditional approaches (Sandy et al., 2014). Conventional methods of scale abbreviation require researchers to manually balance several recommended criteria for item selection, such as, high item-total correlations, high factor loadings, low cross-loadings, low correlated uniqueness, low missing data, high coefficient alpha, and researchers' subjective judgment of the suitability of the selected items (Marsh et al., 2005). In contrast, the GA is a completely automated, highly sophisticated optimization tool that is relatively simple to implement in freely available software, such as the Precis package in Python (see Eisenbarth et al., 2015) and the GAabbreviate package in R (Scrucca and Sahdra, 2015).
The GAs mimic Darwinian evolution principles to efficienty search for a short form of a long form measure in a fully automated manner (Holland, 1975; Scrucca, 2013). An exhaustive search of all possible shorter forms of the original long form and running their respective validation tests would be inefficient. For a long form of length L (e.g., 100 items), the size of the search space for any machine learning method is 2L(1.26e+30) and forms a hypercube of L dimensions. (A hypercube is an extension of L-dimensional geometric figures: a two-dimensional hypercube is a square, a three-dimensional one is a cube and so on). A GA method uses “hypercube sampling” by sampling the corners of the L-dimensional hypercube. It optimizes the search for a good solution—the “fittest” short form that maximally explains the variance in the data of the original long-form—by mimicking Darwinian evolution mechanisms of selection, crossover and mutation while searching through a “landscape” of the collection of all possible fitness values to find an optimal value. Selection in a GA algorithm refers to whether or not an item is selected in a particular iteration. Crossover refers to switching of two items such that the selected item in one generation is unselected in the next one and the unselected item in one generation is selected in the next one. Mutation refers to a (small) probability that an item will randomly switch status (selected or unselected) in a particular generation. The technical details of the GA method of scale abbreviation have been described elsewhere (Whitley, 1994; Yarkoni, 2010; Scrucca, 2013).
In the current study, we used a GA-based method to shorten a long measure of experiential avoidance or the tendency to avoid negative internal experiences. Measurement of experiential avoidance is a vital issue in psychology. Substantial experimental work has shown that one aspect of experiential avoidance, thought suppression, is related to paradoxical rebound effects of increased emotional and behavioral impact of thoughts (Wegner, 1989; Wegner and Erber, 1992; Abramowitz et al., 2001). Avoidance of internal states has been linked to clinical conditions such as depression, generalized anxiety, panic disorder, post traumatic distress, and many other psychopathologies (Chawla and Ostafin, 2007). Consequently, experiential avoidance is a key target of change in modern mindfulness-based psychological interventions such as acceptance and commitment therapy (Hayes et al., 2012), and dialectical behavior therapy (Linehan, 1993).
The Acceptance and Action Questionnaires (the AAQ and its revision, AAQ-II) were early attempts at assessing experiential avoidance (Mccurry et al., 2004). These measures treated experiential avoidance as a unidimensional subcomponent of a broader construct termed “psychological flexibility,” or the ability to connect with the present moment and experience thoughts and feelings openly as they arise, whilst persisting in action that is consistent with values, or changing action when the situation requires it (Ciarrochi et al., 2014). There has been some controversy around AAQ-II. It has been criticized for confounding the process or trait it is designed to measure (experiential avoidance) and the outcomes (e.g., wellbeing) of the process (Chawla and Ostafin, 2007), and for lacking discriminant validity with respect to negative emotionality (Gámez et al., 2011). However, other research suggests that experiential avoidance at the daily level can be distinguished from highly related constructs of mental distress (Kashdan et al., 2014).
The 62-item Multidimensional Experiential Avoidance Questionnaire (MEAQ) was an important attempt to improve on the AAQ-II in that it focused explicitly on key aspects of experiential avoidance without reducing them to a single dimension (Gámez et al., 2011). Specifically, the MEAQ measures the following six dimensions of experiential avoidance: behavioral avoidance (e.g., “I won't do something if I think it will make me uncomfortable”), distress aversion (e.g., “I would do anything to feel less stressed”), distraction and suppression (e.g., “When something upsetting comes up, I try very hard to stop thinking about it”), repression/denial (e.g., “I am able to turn off my emotions when I don't want to feel”), procrastination (e.g., “I tend to put off unpleasant things that need to get done”), and distress endurance (e.g., “Even when I feel uncomfortable, I don't give up working toward things I value”). Gámez et al. (2011) provided the first compelling evidence that experiential avoidance is best treated as a multidimensional construct: the six subscales were differentially related to other constructs, even beyond the effects of individual differences in negative emotionality. However, despite having good psychometric properties, the 62-item MEAQ may be too lengthy to use in many settings (Gámez et al., 2014). The recently validated 15-item Brief Questionnaire (BEAQ) reduces the administration time from about 12 to 3 min (Gámez et al., 2014), but it defeats the key purpose of the original MEAQ by collapsing across the six dimensions. Recent evidence suggests that people may have different profiles of experiential avoidance, being above average on some aspects of avoidance, and average and below average on others, and this may have important implications for practice (Ciarrochi et al., 2014).
In the current study, we employed recent methodological advances in scale abbreviation using genetic algorithms to develop a measure that was short enough to be of practical utility in most settings but not so short as to lose the multidimensional nature of experiential avoidance. We utilized a large nationally representative American sample to evaluate the extent that a reduced MEAQ was comparable to the original long form in terms of inter-subscales correlations, reliability, factor structure, and zero-order and unique associations with a variety of criterion variables. We used the following constructs relevant for convergent and discriminant validity, psychological inflexibility (Bond et al., 2011) and alexithymia (Bagby et al., 1994), both of which are expected to be related to high avoidance. Additional constructs relevant for construct validity included mental health (Goldberg et al., 1996), flourishing (Keyes, 2006), satisfaction with life (Diener et al., 1985), and personal strivings (Emmons and McAdams, 1991; Sheldon and Kasser, 2001). We expected experiential avoidance to be linked to high mental distress, low wellbeing, low life satisfaction, high importance of personal strivings but low autonomous and high controlled reasons for striving, and low progress on personal strivings. The key goal of our study was methodological: to test how well the GA-derived short form preserved the psychometric properties of the long form MEAQ. The results also allowed us to explore the relative importance of different dimensions of experiential avoidance for understanding the link between experiential avoidance and other mental distress, wellbeing and personal strivings related constructs.
Materials and Methods
Participants and Design
A nationally representative American sample (N = 7884; 52% female; Age: M = 47.9, SD = 16) was conducted by a professional survey company. Ethics approval was obtained from the University of Western Sydney Human Research Ethics Committee (H9798) before data collection. Participants completed an on-line anonymous survey in exchange for points they received from the survey company, which they could redeem for merchandize directly from the company. They were asked to complete the survey in a quiet place free of distractions, alone and all in one sitting. In the first part of the survey, all participants completed a measure of personal strivings, the results from which are reported elsewhere (Ciarrochi et al., 2014). For the remaining part of the survey, we utilized a planned missing data design or “matrix sampling” (Schafer, 1997; Graham et al., 2006) to keep the burden on participants to a minimum, and used multiple imputations to deal with the uncertainty related to missing data (as described in detail in Section Multiple Imputation Procedure below). Each participant received a random sample of 60 items. Each item consisted of responses from at least 21% of the sample (1655 respondents).
Measures
Experiential Avoidance
We used the 62-item Multidimensional Experiential Avoidance Questionnaire or MEAQ (Gámez et al., 2011). Using a scale ranging from 1 (strongly disagree) to 6 (strongly agree), participants rated their response to 62 items assessing six dimensions of avoidance: behavioral avoidance (α = 0.81; “I won't do something if I think it will make me uncomfortable”), distress aversion (α = 0.80; “I would do anything to feel less stressed”), distraction and suppression (α = 0.74; “When something upsetting comes up, I try very hard to stop thinking about it”), repression/denial (α = 0.83; “I am able to turn off my emotions when I don't want to feel”), procrastination (α = 0.77; “I tend to put off unpleasant things that need to get done”), and distress endurance (α = 0.78; “Even when I feel uncomfortable, I don't give up working toward things I value”).
Alexithymia
Using a scale ranging from 1 (Strongly Disagree) to 5 (Strongly Agree), participants rated their responses to two subscales of the Toronto Alexithymia Scale (Bagby et al., 1994; Landstra et al., 2013): seven items of difficulties identifying feelings (α = 0.86; e.g., “When I am upset, I don't know if I am sad, frightened, or angry”), and five items for difficulties describing feelings (α = 0.77; e.g., “It is difficult for me to find the right words for my feelings”).
Psychological Inflexibility
We used the Acceptance and Action Questionnaire II or AAQ-II (Bond et al., 2011). The AAQ-II measures the tendency to control thoughts and feelings and ability to act in the presence of difficult thoughts or feelings. Each item is rated on a seven-point Likert scale (α = 0.87; e.g., “I worry about not being able to control my worries and feelings” and “My painful memories prevent me from having a fulfilling life”). Higher scores indicate higher psychological flexibility. The AAQ-II has been shown to have adequate test-retest reliability, discriminant, convergent, and predictive validity (Bond et al., 2011).
Mental Health
We used a well-validated measure of personal mental health, the General Health Questionnaire (Goldberg, 1978; Goldberg et al., 1996). Participants used a four-point scale with labels such as “not at all” to “much more than usual” to respond to 12 items, all beginning with a sentence stem, “Have you recently….” Example items include: “been feeling unhappy or depressed,” “felt you couldn't overcome your difficulties.” Higher scores indicate greater psychological distress. The measure showed decent internal consistency in our sample (α = 0.87).
Satisfaction with Life
We used a well-established measure (Diener et al., 1985), in which participant rated their responses to five items using a scale from 1 (Strongly Disagree) to 5 (Strongly Agree). Example items include: “In most ways my life is close to my ideal,” “I am satisfied with my life.” The measure showed satisfactory internal consistency (α = 0.85).
Flourishing
To measure the positive aspect of mental health, we used a measure consisting of 12 items measuring the following three aspects of flourishing (Keyes, 2006): emotional wellbeing (α = 0.82; e.g., “In the past month, how often have you felt happy?”); psychological wellbeing (α = 0.61; e.g., “In the past month, how often did you feel good at managing the responsibilities of your daily life?”); and social wellbeing (α = 0.72; e.g., “In the past month, how often did you feel that you belonged to a community like a social group, your school, or your neighborhood?”). Participants rated their responses using a scale with the following labels: 1 (Never), 2 (Once or twice), 3 (About once a week), 4 (Two or three times a week), 5 (Almost every day), and 6 (Every day).
Personal Strivings
We used a measure of personal strivings (Emmons and McAdams, 1991; Sheldon and Kasser, 2001) in which participants were asked to describe four personal strivings (important goals) and respond to a series of questions about those strivings using a rating scale that ranged from 1 (Disagree Strongly) to 6 (Agree Strongly). They were asked to rate the importance of striving, the extent to which it was autonomous (three questions; e.g., “I strive for this because it makes my life more meaningful”) or controlled (two questions; e.g., “I strive for this because I would feel ashamed, guilty or anxious if I didn't strive for it”), and how much progress they had made on the striving (“In the past 10 weeks I have made progress on this striving”).
Multiple Imputation Procedure
The data were missing completely at random or MCAR (Enders, 2010) because the study had missing data by design. Having an MCAR design allowed us to utilize a multiple imputation procedure to produce unbiased estimates (Little and Rubin, 1987). We used the package Amelia II (Honaker et al., 2011) in the statistical software R (R_Core_Team, 2015) to derive 25 imputations. Amelia II implements Expectation-Maximization (EM) algorithm with bootstrapping (Dempster et al., 1977; King et al., 2001; Honaker et al., 2011). In this procedure, multiple bootstrapped samples of the original incomplete data are used to draw values of the complete data. The EM algorithm draws imputed values from each set of bootstrapped parameters and automatically fills in the missing values with the imputed values. Across the imputed datasets, the observed values remain the same, but the missing values are replaced with draws from EM based predictive distribution of missing data. We confirmed the robustness of the imputation model by checking that EM convergence was normal and EM chain lengths of all 25 imputed datasets were reasonably short and consistent in length. We also used the following diagnostic functions in Amelia II to further verify the validity of the imputation model: the compare density function to check the distribution of imputed values to the distribution of observed values; and the over impute function to ensure that the observed data tended to fall within the region where it would have been imputed had it been missing instead of observed.
The imputation procedure was conducted using the entire sample to maximally utilize the EM algorithm. As recommended in machine learning applications (James et al., 2014), the sample was randomly split into a training subset (N = 5913; 75% of the original sample) and a testing subset (N = 1971; 25% of the full sample), each subset with their respective 25 imputed files. The training subset was used to run a genetic algorithm to derive a short-form of MEAQ, and only the testing subset was employed for running validation tests on the short-form.
Genetic Algorithm Procedure
We employed a freely available R package, GAabbreviate (Scrucca and Sahdra, 2015), which uses the GA package (Scrucca, 2013) to efficiently implement the recently validated GA method for scale reduction (Yarkoni, 2010; Sandy et al., 2014; Eisenbarth et al., 2015). (See Appendix A in Supplementary Material for an example R code using GAabbreviate). Technical details of the GA method for scale abbreviation are described elsewhere (Yarkoni, 2010). In brief, the algorithm is designed to minimize the following fitness function:
Here, I represents a user-specified fixed item cost, k represents the number of items retained by the GA, s is the number of subscales in the measure, wi are the weights associated with each subscale, and is the amount of variance in the ith subscale that can be explained by a linear combination of individual item scores. The equation above is identical to the cost function of Yarkoni (2010), except we have made the weighting of subsets more explicit in the formula. By default, wi has a value of 1 in GAabbreviate, giving equal weighting to all subscales, but it is relatively easy to adjust weights if needed. GAabbreviate also allows users to constrain k, the number of items to be retained. Adjusting the value of I low or high yields longer or shorter measures respectively. When the cost of each individual item retained in each generation outweighs the cost of a loss in explained variance, the GA yields a relatively brief measure. When the cost is low, the GA yields a relatively longer measure maximizing explained variance (Yarkoni, 2010).
Results
GA-Derived Short Measure
The GA procedure was run using the training sample (N = 5913; 75% of the full sample), as is recommended for machine learning applications (James et al., 2014). After trail runs on two imputed datasets used to fine-tune the GA parameters, the following specifications were set for separate 25 GA runs on each of the 25 imputed datasets:
• item cost = 0.05 (same as the specification in Yarkoni, 2010)
• population size = 200 (same as the specification in Yarkoni, 2010)
• maximum number of iterations in each generation = 200 (approximately double the number of iterations it took the GA to converge in trial runs)
• maximum number of items per subscale = 5 (constrained to shorten the 62-item original MEAQ measure roughly by half)
• probability of crossover between pairs of chromosomes (typically a large value) = 0.8 (the default in the GA package; Scrucca, 2013)
• probability of mutation in a parent chromosome (typically a small value) = 0.1 (the default in the GA package; Scrucca, 2013)
• elitism or the number of best fitness individuals to survive at each generation = top 5% individuals (the default in the GA package; Scrucca, 2013).
Since the GA is a stochastic approach, the solution for each of the 25 GA runs on 25 datasets varied slightly. As an example, Figure 1 depicts the GA solution obtained for one of the imputed datasets. The left panel of the figure shows the reduction in the cost, number of items retained and the mean explained variance of the selected measure across the 200 GA generations. The middle panel shows the best solution from the GA run with maximum variance explained for each of the six subscales. The right panel visually depicts the selected (black squares) and excluded (white squares) items from the first (top of the figure) to the 200th (bottom of the figure) generation. (This figure shows the final solution of a GA run, which can observed from start to finish in real-time in R if the plot option in GAabbreviate is turned on by adding the argument plot = TRUE to the GAabbreviate function.)
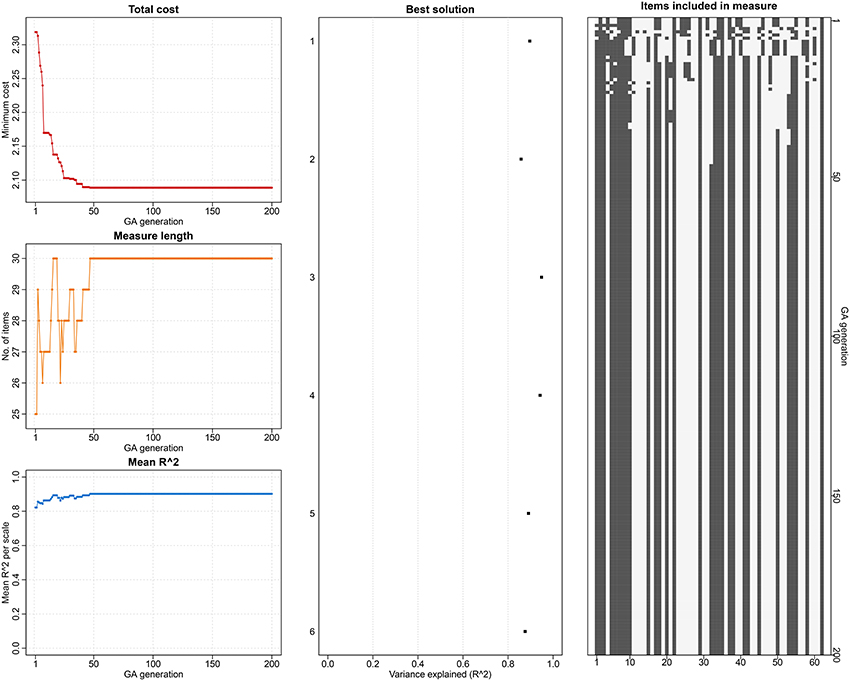
Figure 1. The genetic algorithm solution for shortening the 62-item MEAQ in one of the imputed datasets. The left panel shows the reduction in the cost, number of items retained and the mean explained variance of the selected measure across the 200 GA generations. The middle panel shows the best solution from the GA run with maximum variance explained for each of the six subscales. The right panel visually depicts the selected (black squares) and excluded (white squares) items from the first (top of the figure) to the 200th (bottom of the figure) generation. This figure shows the final solution of a GA run, which can be observed from start to finish in real-time in R if the plot option in GAabbreviate is turned on.
For each of the subscales of MEAQ, a list of GA-selected items from the 25 runs was created. Each item was ranked depending on the number of GA runs that selected that item (e.g., an item that was selected by 19 out of 25 GA runs received a rank of 19). The top five ranking items within each of the six subscales' list were selected to form the 30-item MEAQ (MEAQ-30 henceforth). This method allowed us to capitalize on the multiple imputation procedure accounting for missing-data uncertainty (Rubin, 1987; Schafer, 1997). Table 1 contains the items of the MEAQ-30. Further validation tests (reported below) on the MEAQ-30 employed only the testing sample's (N = 1971) respective 25 imputed datasets.

Table 1. The 30-item Multidimensional Experiential Avoidance Questionnaire derived using a genetic algorithm for scale reduction.
Subscales Intercorrelations
The pattern of intercorrelations of the subscales of the GA-derived MEAQ-30 (above diagonal in Table 2A) was very similar to the respective subscales' intercorrelations of the 62-item MEAQ (below diagonal of Table 2A). Further, the extent to which the subscales were intercorrelated in the long-form MEAQ was comparable to the correlations of the subscales of the long form with the subscales of the short form (compare the correlations below diagonal in Table 2A with the correlations in the rows of Table 2B). Similarly, the extent to which the subscales were intercorrelated in the MEAQ-30 was similar to the correlations of the subscales of MEAQ-30 with the subscales of the original 62-item MEAQ (compare the above diagonal correlations in Table 2A with the columns in Table 2B). In addition, the high correlations (all above 90) in the diagonal of Table 2B show high convergence for each of the subscale of the two MEAQ measures. Figure 2 visually depicts the high convergence in the two versions of MEAQ in scatterplots built using data from a randomly selected imputed file. The short MEAQ measure (plotted on the x-axis) has a high correlation with the original long form (plotted on the y-axis) for each of the subscales. Since the correlations of the subscales of the original MEAQ and MEAQ-30 can be artifactually inflated due to the common items both measures share in each of the subscales, it is important to do additional tests (reported below) to see if the MEAQ-30 performs similarly to the original MEAQ in terms of factor structure and construct validity.
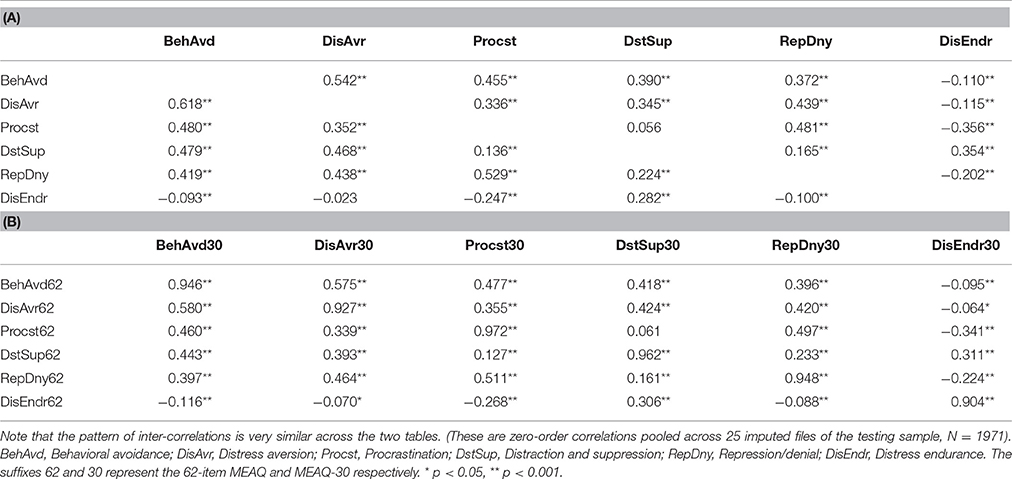
Table 2. Intercorrelations (A) between the six subscales of the 62-item MEAQ (below diagonal) and the MEAQ-30 (above diagonal), and (B) between the six subscales of the 62-item MEAQ and 30-item MEAQ.
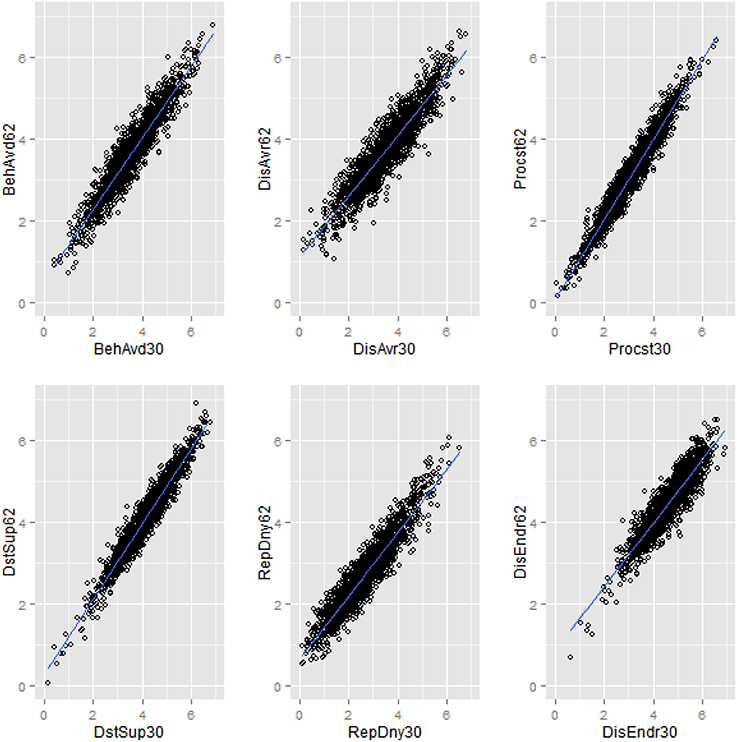
Figure 2. Scatterplots displaying convergent correlations of each of the six subscales of the 62-item MEAQ with the respective subscales of the 30-item MEAQ in one of the imputed datasets. The short MEAQ measure (plotted on the x-axis) has a high correlation with the original long form (plotted on the y-axis) for each of the subscales. BehAvd, Behavioral avoidance; DisAvr, Distress aversion; Procst, Procrastination; DstSup, Distraction and suppression; RepDny, Repression/denial; DisEndr, Distress endurance.
Factor Structure and Reliability
A confirmatory factor analyses (CFA) of the original 62-item MEAQ with six factors yielded a good fit, χ, p < 0.001, CFI = 0.96, TLI = 0.95, RMSEA = 0.01, 95% CI [0.006 0.01]. A six-factor CFA of the GA-derived MEAQ-30 also yielded as good, if not better, fit, χ, p < 0.001, CFI = 0.97, TLI = 0.97, RMSEA = 0.01, 95% CI [0.006 0.01] (For interested readers, Appendix B in Supplementary Material contains the fit of a short measure derived using a conventional manual method of item selection). As with the subscales intercorrelations, the 62-item MEAQ and the GA-derived MEAQ-30 showed virtually identical patterns of factor correlations (included in Table 3): The mean of absolute values of the differences in the inter-subscale zero-order correlations (in Table 2A) was 0.06, and the mean of the differences in inter-factor correlations (in Table 3) was 0.05, both numbers being very small. Furthermore, as reported in Table 4, the alpha coefficients and average inter-item correlations of all the subscales of the 62-item and 30-item MEAQ measure were comparable. In short, the two measures yielded similar factor structure and reliability.
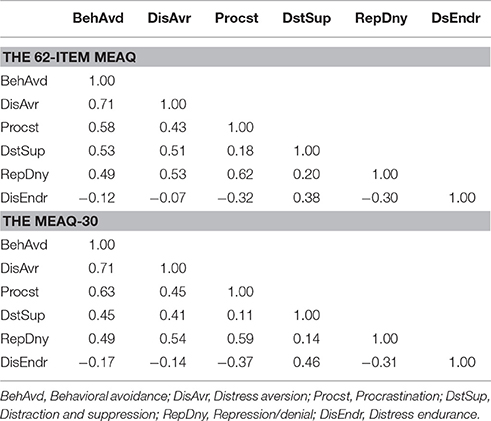
Table 3. Correlations between the six factors from the confirmatory factor analyses of the 62-item and the 30-item MEAQ measures.
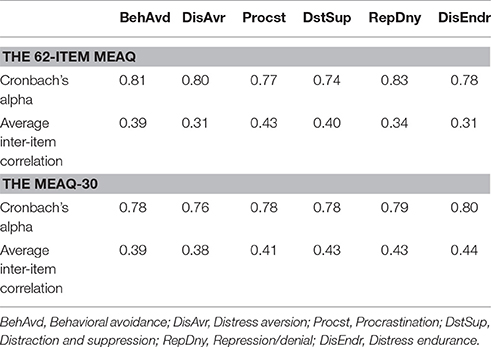
Table 4. The Cronbach's alpha coefficients and average inter-item correlations of each of the subscales of the 62-item and 30-item MEAQ measures.
Construct Validity
Table 5 reports zero-order correlations of each of the six dimensions of the 62-item MEAQ (Table 5A) and the respective dimensions of the MEAQ-30 (Table 5B) with the criterion variables. The variables relevant for convergent and discriminant validity, alexithymia and psychological flexibility, show similar pattern of correlations across Tables 5A,B. Other variables relevant for construct validity, mental distress, satisfaction with life, the three aspects of wellbeing and the four aspects of strivings, also show similar correlations across the two forms of MEAQ. The mean of absolute values of the differences in the zero-order correlations of each of the two MEAQ measures with all other measures was only 0.03, suggesting that the MEAQ-30 performed virtually identically to the original MEAQ in terms of the associations of the six subscales with other variables.
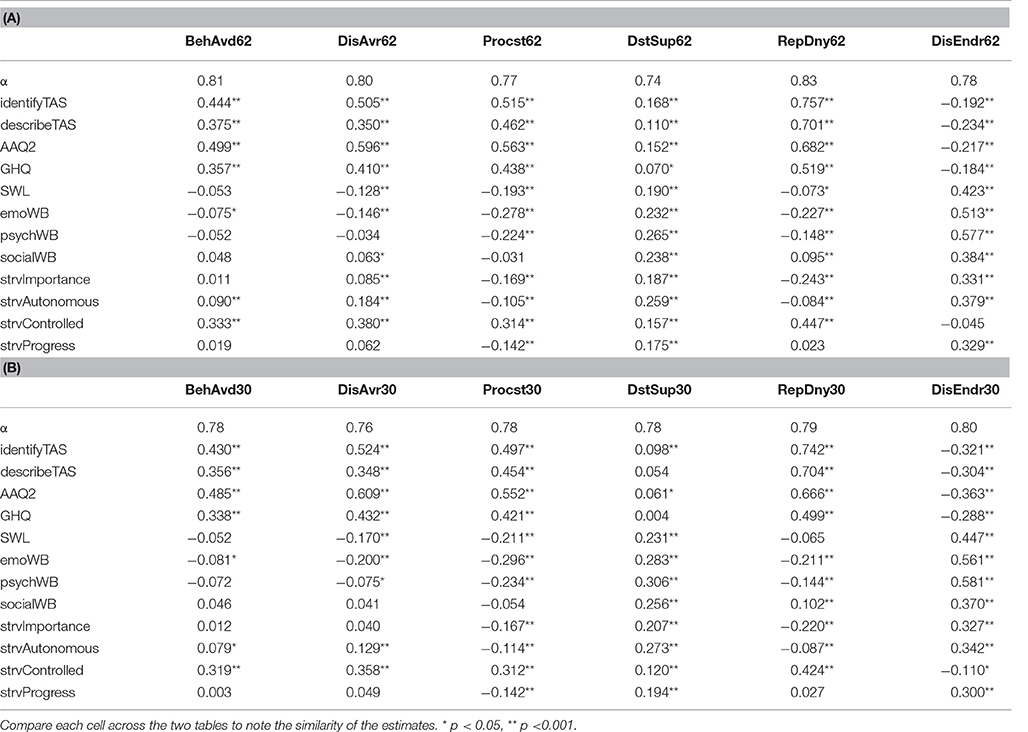
Table 5. Coefficient alphas and zero-order correlations of (A) each of the six dimensions of the 62-item with other constructs, and (B) each of the subscales of the MEAQ-30 with other constructs.
One limitation of zero-order correlations is that they do not show unique contribution of each experiential avoidance dimension, controlling for other dimensions, in explaining the variance in the criterion variables. To examine such unique relations as accurately as possible, that is, by removing as much measurement error as possible in each MEAQ measure, we ran structural equation models. We used the R packages lavaan (Rosseel, 2012) and semTools (Pornprasertmanit et al., 2013) to run these models using the 25 imputed dataset of the validation sample. See Table 6 for goodness of fit indices, and Tables 7–9 for standardized regression coefficients and R2 from these models. The mean of absolute values of the differences in regression coefficients of the two MEAQ measures predicting the outcomes was only 0.02, suggesting that the MEAQ-30 performed almost identically to the 62-item MEAQ. Further, the R2 values from these models show that the MEAQ-30, compared to the original MEAQ, consistently explained slightly more or similar degree of variance in the outcomes.
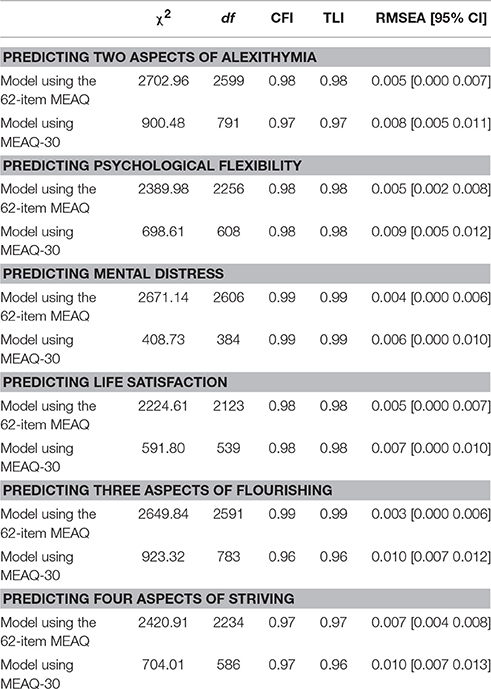
Table 6. Summary of goodness of fit for models using the 62-item MEAQ to predict other constructs and models using the 30-item MEAQ to predict the same constructs.
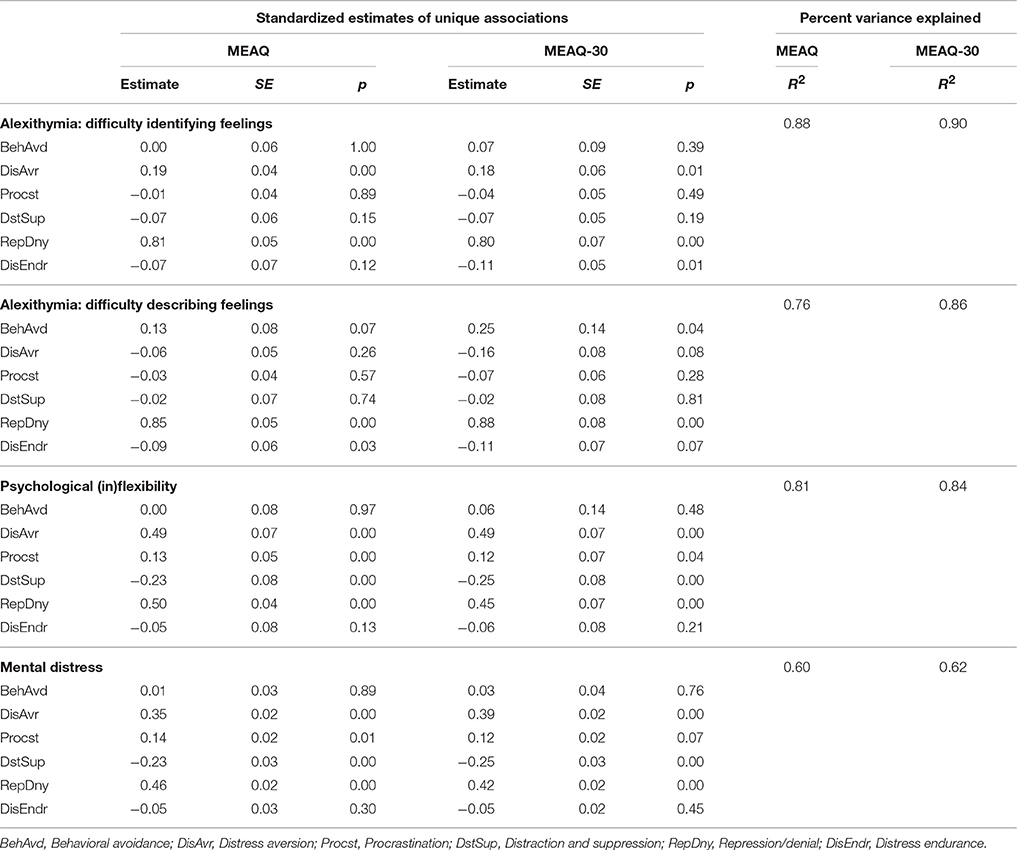
Table 7. Regression coefficients and R2 from structural equation models showing unique relationships of the subscales of the 62-item and the 30-item MEAQ measures with alexithymia (difficulty identifying and describing internal states), psychological flexibility, and mental distress.
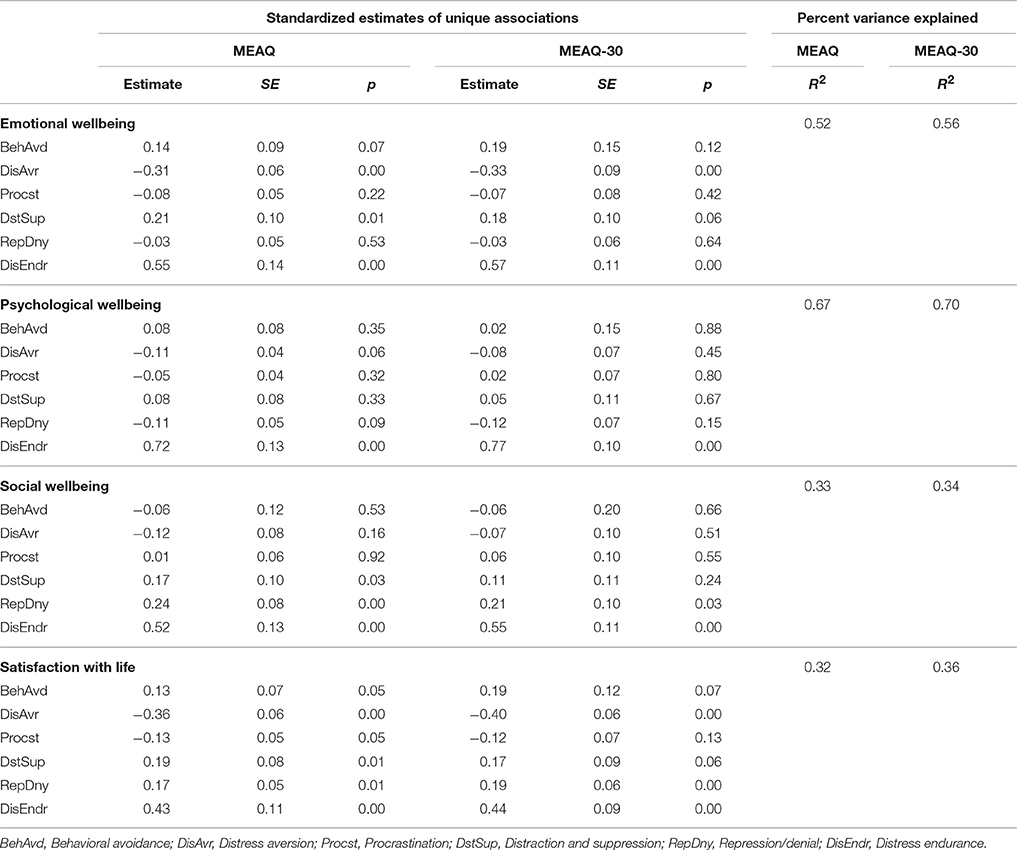
Table 8. Regression coefficients and R2 from structural equation models showing unique relationships of the subscales of the 62-item MEAQ and the MEAQ-30 with the three aspects of flourishing, and satisfaction with life.
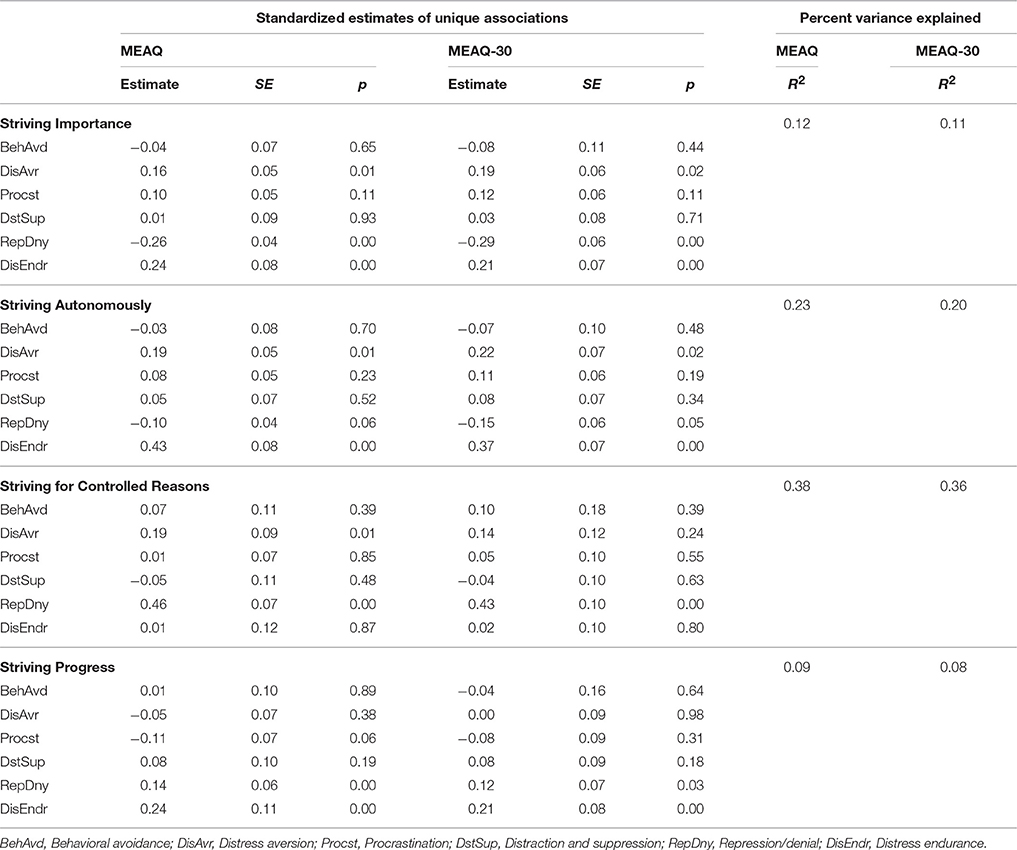
Table 9. Regression coefficients and R2 from structural equation models showing unique relationships of the subscales of the 62-item MEAQ and the MEAQ-30 with the four aspects of the first reported personal striving.
Distribution of Means in USA
Finally, using all available data, we explored the distribution of mean levels of the six dimensions of experiential avoidance in the USA to see if the means of the 30-item measure were similar to the 62-item measure across the six census regions. Using participants' IP addresses, we obtained geographical information using the ip2coordinates application programming interface of Data Science Toolkit (Warden, 2011). Accurate geographical data were available from 6429 participants. Table 10 reports sample sizes in each of the American census regions, along with means and standard deviations of the six dimensions of experiential avoidance in the regions for both the 62-item and 30-item MEAQ measures. The mean of absolute values of the differences in the means of the two MEAQ measures reported in Table 10 was 0.09, a negligible difference on average.
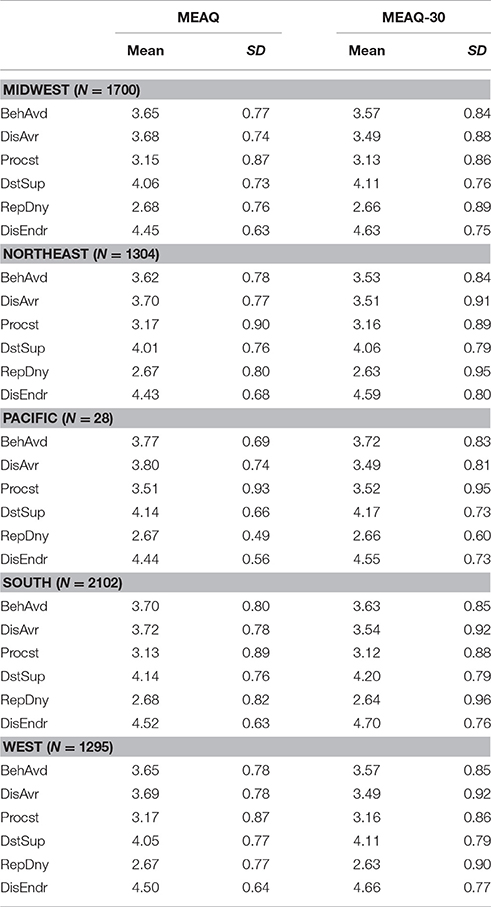
Table 10. Means and standard deviations of each of the six subscales of the 62-item and 30-item MEAQ measures in the five census regions of United States.
Discussion
The key goal of our study was methodological—to use recent machine learning advances in psychometrics employing genetic algorithms to shorten the 62-item MEAQ by half whilst preserving its psychometric properties, including its multidimensional structure. In a large nationally representative American sample with a wide age range, the GA-derived short measure, MEAQ-30 performed virtually identically to the original MEAQ in terms of intercorrelations of the subscales, factor structure and reliability estimates, average levels of the subscales in the five census regions of USA, and zero-order correlations and unique latent associations of the six dimensions of experiential avoidance with other measures of personal strivings, mental health and wellbeing. The MEAQ-30 maintains fidelity to the six sub-dimensions of experiential avoidance measured by the original 62-item but takes about half as long to complete. The results make an important contribution to the nascent field of machine learning approaches in psychometrics by demonstrating the validity of GAs as relatively easy to use optimization tools for scale abbreviation.
The GA method is highly efficient and does not take much computing time. GAabbreviate can use parallel processing to speed up computation. Also, turning the plot argument off while running the GA procedure (the default in GAabbreviate) speeds up the run time while allowing users to plot the data after a solution has been obtained. To give concrete figures of the computing time involved, we recorded the computing time for a GA run on one of the imputed subsets of our testing sample (N = 1971, 62 items of MEAQ, 6 subscales) using the GA parameters reported in the paper. These computations were run on a MacBook Pro with 2.6 GHz Intel Core i7 processor and 16 GB RAM. A single iteration of fitness evaluation took 0.40 s. A complete run of 200 iterations took 49.36 s without parallel processing and 25.87 s. (Parallel processing can be switched on by adding the argument parallel=TRUE to the GAabbreviate function) The computing times reported above are averages of 10 replications. In sum, the R package GAabbrevaite allows a highly efficient implementation of the GA method without much computational demand.
Our results also make a substantive contribution to psychology by highlighting the value of treating experiential avoidance as a multidimensional construct. As initial evidence of the distinctiveness of the six dimensions of experiential avoidance, the intercorrelations of the subscales of the MEAQ-30 (and the 62-item MEAQ) ranged from negligible to moderate in size, which is consistent with previous research using the 62-item MEAQ (Gámez et al., 2011; Ciarrochi et al., 2014). As further evidence, the correlations of each MEAQ measure with other variables were also different across the experiential avoidance dimensions. Perhaps the most compelling evidence comes from the unique latent relations of the six subscales with other variables, which paint a complex picture of how different experiential avoidance dimensions had different unique relations with other variables. For instance, distress aversion, but not distress endurance, was uniquely associated with difficulty identifying feelings (one aspect of alexithymia). However, distress endurance, but not distress aversion, was important for explaining unique variance in difficulty describing feelings (the other aspect of alexithymia). As another example, behavioral avoidance and distress endurance were not uniquely associated with mental distress, but they did explain unique variance in satisfaction with life. Distress endurance seemed to be the most important of all six experiential avoidance dimensions in accounting for unique variance in positive outcomes of wellbeing and life satisfaction, but it did little in explaining the variance of the negative outcomes of alexithymia, psychological (in)flexibility, and general mental distress. Repression/denial appeared to be the most important experiential avoidance dimension in accounting for the variance in the negative outcomes, but other dimensions of experiential avoidance also mattered to varying degrees, depending on the criterion variable.
Research on the multidimensional nature of experiential avoidance is in its infancy. We hesitate to make strong conclusions regarding specific aspects of experiential avoidance based on our data because we did not have specific a priori predictions about unique relationships of different experiential avoidance dimensions with mental health and wellbeing related outcomes. Our primary goal was to use a GA-based method to shorten the 62-item MEAQ without much loss of information. To that end, the MEAQ-30 captured the complex pattern of the associations of the six experiential avoidance dimensions with other variables virtually identically to the original 62-item MEAQ. We hope that our results would guide hypothesis for future research to advance a more nuanced understanding of the different dimensions of experiential avoidance.
Although comparison of the experiential avoidance levels in US census regions was not the main goal of this study, our data suggest that the mean levels of the six aspects of experiential avoidance were comparable across the census regions. The conclusions of the present study are limited to the English speaking Americans. Future studies should examine the psychometric properties of the MEAQ-30 in other languages and cultures, and clinical populations, and its test-re-test reliability and stability of the factor structure over time. Nevertheless, the MEAQ-30 may help researchers and practitioners evaluate the different experiential avoidance dimensions in half the time it takes to administer the original MEAQ.
Lengthy questionnaires tend to burden participants, which can result in poor data quality and high attrition rate (Cook et al., 2000). The 62-item MEAQ takes about 12 min to complete and can add to participant burden in a long battery. The 15-item alternative, the BEAQ, is problematic because it collapses across the multidimensional nature of experiential avoidance. One of the dangers of using excessively short versions of well-constructed longer measures is that they can increase both the Type 1 and Type 2 error rates by underestimating or overestimating the relations of the construct with other measures (Smith et al., 2000). The MEAQ-30 is a happy compromise. It cuts the original MEAQ by half while maintaining fidelity to the six dimensions of experiential avoidance.
If a valid and reliable shorter form of a long measure is available, researchers have an ethical obligation to use the short form to avoid burdening participants unnecessarily. Further, a difference of roughly 6 min in the administration time of the original MEAQ (which takes about 12 min) and the MEAQ-30 (which takes about 6 min) has significant practical implications. It can mean the difference between not being able to measure experiential avoidance at all and measuring it reliably when only 6 min are available in an otherwise lengthy battery. And when more room is available in a survey, the MEAQ-30, if used instead of the 62-item MEAQ, can help researchers spare about 6 min for another measure of a separate construct of interest, thus expanding the scope of the original study. Most importantly, the MEAQ-30 provides a multidimensional assessment of experiential avoidance. The BEAQ takes about 3 min to complete whereas the MEAQ-30 takes about 6 min. The slight increase in time may well be worth it. It may mean the difference between identifying the right experiential avoidance strategy for a particular population or client to precisely target that strategy in a tailor-made intervention, and missing that level of specificity all together.
Author Contributions
Conceived and designed the study: BKS and JC; Data collection: BKS and JC; Analyzed the data: BKS, JC, PP, and LS; Designed analysis tools: BKS and LS; Wrote the paper: BKS, JC, PP, and LS.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This paper was partially funded by grants from the Australian Research Council, the Mind & Life Institute, and the Sir John Templeton Foundation.
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fpsyg.2016.00189
The R data file, Imputation1.Rdata, contains the MEAQ data from one of our imputed dataset. All 25 imputed datasets are available upon request. The text file MEAQitems.txt contains information about the labels of the variables in the data file.
References
Abramowitz, J. S., Tolin, D. F., and Street, G. P. (2001). Paradoxical effects of thought suppression: a meta-analysis of controlled studies. Clin. Psychol. Rev. 21, 683–703. doi: 10.1016/S0272-7358(00)00057-X
Bagby, R. M., Parker, J. D., and Taylor, G. J. (1994). The twenty-item toronto alexithymia scale—I. Item selection and cross-validation of the factor structure. J. Psychosom. Res. 38, 23–32. doi: 10.1016/0022-3999(94)90005-1
Bond, F. W., Hayes, S. C., Baer, R. A., Carpenter, K. M., Guenole, N., Orcutt, H. K., et al. (2011). Preliminary psychometric properties of the Acceptance and Action Questionnaire–II: a revised measure of psychological inflexibility and experiential avoidance. Behav. Ther. 42, 676–688. doi: 10.1016/j.beth.2011.03.007
Chawla, N., and Ostafin, B. (2007). Experiential avoidance as a functional dimensional approach to psychopathology: an empirical review. J. Clin. Psychol. 63, 871–890. doi: 10.1002/jclp.20400
Ciarrochi, J., Sahdra, B., Marshall, S., Parker, P., and Horwath, C. (2014). Psychological flexibility is not a single dimension: the distinctive flexibility profiles of underweight, overweight, and obese people. J. Contextual Behav. Sci. 3, 236–247. doi: 10.1016/j.jcbs.2014.07.002
Cook, C., Heath, F., and Thompson, R. L. (2000). A meta-analysis of response rates in web-or internet-based surveys. Educ. Psychol. Meas. 60, 821–836. doi: 10.1177/00131640021970934
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. B 39, 1–38.
Diener, E., Emmons, R. A., Larsen, R. J., and Griffin, S. (1985). The satisfaction with life scale. J. Pers. Assess. 49, 71–75. doi: 10.1207/s15327752jpa4901_13
Eisenbarth, H., Lilienfeld, S. O., and Yarkoni, T. (2015). Using a genetic algorithm to abbreviate the psychopathic personality inventory–revised (PPI-R). Psychol. Assess. 27, 194–202. doi: 10.1037/pas0000032
Emmons, R. A., and McAdams, D. P. (1991). Personal strivings and motive dispositions: exploring the links. Pers. Soc. Psychol. Bull. 17, 648–654. doi: 10.1177/0146167291176007
Gámez, W., Chmielewski, M., Kotov, R., Ruggero, C., Suzuki, N., and Watson, D. (2014). The brief experiential avoidance questionnaire: development and initial validation. Psychol. Assess. 26, 35–45. doi: 10.1037/a0034473
Gámez, W., Chmielewski, M., Kotov, R., Ruggero, C., and Watson, D. (2011). Development of a measure of experiential avoidance: the multidimensional experiential avoidance questionnaire. Psychol. Assess. 23, 692–713. doi: 10.1037/a0023242
Goldberg, D. (1978). Manual of the General Health Questionnaire. Windsor, ON: National Foundation of Education Research.
Goldberg, D., McDowell, I., and Newell, C. (1996). Measuring Health: A Guide to Rating Scales and Questionnaires. New York, NY: Oxford University Press.
Graham, J. W., Taylor, B. J., Olchowski, A. E., and Cumsille, P. E. (2006). Planned missing data designs in psychological research. Psychol. Methods 11:323. doi: 10.1037/1082-989X.11.4.323
Hayes, S. C., Strosahl, K. D., and Wilson, K. G. (2012). Acceptance and Commitment Therapy: The Process and Practice of Mindful Change, 2nd Edn. New York, NY: Guilford Press.
Holland, J. (1975). Adaption in Natural and Artificial Systems. Ann Arbor, MI: The University of Michigan Press.
Honaker, J., King, G., and Blackwell, M. (2011). Amelia II: a program for missing data. J. Stat. Softw. 45, 1–47. doi: 10.18637/jss.v045.i07
James, G., Witten, D., and Hastie, T. (2014). An Introduction to Statistical Learning: With Applications in R. New York, NY: Springer.
Kashdan, T. B., Goodman, F. R., Machell, K. A., Kleiman, E. M., Monfort, S. S., Ciarrochi, J., et al. (2014). A contextual approach to experiential avoidance and social anxiety: evidence from an experimental interaction and daily interactions of people with social anxiety disorder. Emotion 14, 769–781. doi: 10.1037/a0035935
Keyes, C. L. (2006). Mental health in adolescence: is America's youth flourishing? Am. J. Orthopsychiatry 76, 395–402. doi: 10.1037/0002-9432.76.3.395
King, G., Honaker, J., Joseph, A., and Scheve, K. (2001). Analyzing incomplete political science data: An alternative algorithm for multiple imputation. Am. Polit. Sci. Rev. 95, 49–69.
Landstra, J., Ciarrochi, J., Deane, F. P., and Hillman, R. J. (2013). Identifying and describing feelings and psychological flexibility predict mental health in men with HIV. Br. J. Health Psychol. 18, 844–857. doi: 10.1111/bjhp.12026
Linehan, M. (1993). Cognitive-Behavioral Treatment of Borderline Personality Disorder. New York, NY: Guilford Press.
Little, R. J., and Rubin, D. B. (1987). Statistical Analysis with Missing Data. New York, NY: Wiley.
Marsh, H. W., Ellis, L. A., Parada, R. H., Richards, G., and Heubeck, B. G. (2005). A short version of the Self Description Questionnaire II: operationalizing criteria for short-form evaluation with new applications of confirmatory factor analyses. Psychol. Assess. 17:81. doi: 10.1037/1040-3590.17.1.81
Mccurry, S. M., Hayes, S. C., Strosahl, K., Wilson, K., Bissett, R., Pistorello, J., et al. (2004). Measuring experiential avoidance: a preliminary test of a working model. Psychol. Rec. 54, 553–578.
Pornprasertmanit, S., Miller, P., Schoemann, A., and Rosseel, Y. (2013). semTools: Useful Tools for Structural Equation Modeling (Version 0.4-0). Available online at: http://CRAN.R-project.org/package=semTools
R_Core_Team (2015). R: A Language And Environment For Statistical Computing (Version 3.2.0). Vienna: R Foundation for Statistical Computing. Available online at: http://www.R-project.org/
Rosseel, Y. (2012). lavaan: an R package for structural equation modeling. J. Stat. Softw. 48, 1–36. doi: 10.18637/jss.v048.i02
Sandy, C. J., Gosling, S. D., and Koelkebeck, T. (2014). Psychometric comparison of automated versus rational methods of scale abbreviation. J. Individ. Diff. 35, 221–235. doi: 10.1027/1614-0001/a000144
Scrucca, L. (2013). GA: a package for genetic algorithms in R. J. Stat. Softw. 53, 1–37. doi: 10.18637/jss.v053.i04
Scrucca, L., and Sahdra, B. (2015). GAabbreviate: Abbreviating Questionnaires (or Other Measures) using Genetic Algorithms (Version 1.0): R package. Available onlie at: http://CRAN.R-project.org/package=GAabbreviate
Sheldon, K. M., and Kasser, T. (2001). Getting older, getting better? Personal strivings and psychological maturity across the life span. Dev Psychol. 37:491. doi: 10.1037/0012-1649.37.4.491
Smith, G. T., McCarthy, D. M., and Anderson, K. G. (2000). On the sins of short-form development. Psychol. Assess. 12:102. doi: 10.1037/1040-3590.12.1.102
Wegner, D. M. (1989). White Bears and Other Unwanted Thoughts: Suppression, Obsession, and the Psychology of Mental Control. New York, NY: Penguin Press.
Wegner, D. M., and Erber, R. (1992). The hyperaccessibility of suppressed thoughts. J. Pers. Soc. Psychol. 63:903. doi: 10.1037/0022-3514.63.6.903
Keywords: genetic algorithms, experiential avoidance, abbreviation, measurement, psychometrics
Citation: Sahdra BK, Ciarrochi J, Parker P and Scrucca L (2016) Using Genetic Algorithms in a Large Nationally Representative American Sample to Abbreviate the Multidimensional Experiential Avoidance Questionnaire. Front. Psychol. 7:189. doi: 10.3389/fpsyg.2016.00189
Received: 06 September 2015; Accepted: 31 January 2016;
Published: 24 February 2016.
Edited by:
Pietro Cipresso, IRCCS Istituto Auxologico Italiano, ItalyReviewed by:
Victor P. Andreev, Arbor Research Collaborative for Health, USAKa-Chun Wong, City University of Hong Kong, China
Laetitia Jourdan, Université Lille 1, France
Copyright © 2016 Sahdra, Ciarrochi, Parker and Scrucca. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Baljinder K. Sahdra, baljinder.sahdra@acu.edu.au