 Steven G. Luke
Steven G. Luke John M. Henderson
John M. Henderson- 1Department of Psychology and Neuroscience Center, Brigham Young University, Provo, UT, USA
- 2Department of Psychology, University of California Davis, Davis, CA, USA
- 3Center for Mind and Brain, University of California, Davis, Davis, CA, USA
The present study investigated the influence of content meaningfulness on eye-movement control in reading and scene viewing. Texts and scenes were manipulated to make them uninterpretable, and then eye-movements in reading and scene-viewing were compared to those in pseudo-reading and pseudo-scene viewing. Fixation durations and saccade amplitudes were greater for pseudo-stimuli. The effect of the removal of meaning was seen exclusively in the tail of the fixation duration distribution in both tasks, and the size of this effect was the same across tasks. These findings suggest that eye movements are controlled by a common mechanism in reading and scene viewing. They also indicate that not all eye movements are responsive to the meaningfulness of stimulus content. Implications for models of eye movement control are discussed.
Introduction
When we are performing a visual task, such as reading, searching for an object, or just looking around at the world, our eyes make rapid movements, called saccades, several times a second. In between these saccades, the eyes make pauses (called fixations) to take in visual information. Researchers who study eye movements are interested in why we look where we do and why we move our eyes when we do. It is thought by many that eye movements are under cognitive control, meaning that the where and when of eye movements are influenced by cognitive processes related to perception, memory, and language (Rayner, 2009; Rayner and Reingold, 2015; but see Yang and McConkie, 2001; Vitu, 2003 for an alternate viewpoint). In short, cognitive control implies that our eye movements respond quickly to the nature of what we are looking at in any given moment.
The study of reading has proven to be fertile ground for investigating the influence of cognitive factors on eye movement control. This is primarily because words have multiple quantifiable cognitive properties such as frequency and predictability, properties that influence the processing of those words in multiple ways. Studies exploring the influence of these cognitive properties have shown that cognitive processing can influence eye movements on a moment-by-moment basis (Just and Carpenter, 1980; Rayner, 1998, 2009; Kliegl et al., 2006).
Studying the influence of cognitive processing in other visual tasks, such as scene viewing, has proven more difficult, because the units of processing (i.e., objects) are not so clearly differentiated in visual scenes (they overlap) and their cognitive properties are not so easily defined or quantified. As a result, the influence of cognitive factors in scene viewing is less clearly understood (Henderson et al., 1999; Henderson, 2003; Võ and Henderson, 2009; Wang et al., 2010). Researchers have therefore been forced to rely more on manipulations of global image properties in order to investigate cognitive control of eye movements in these scene viewing tasks. These global manipulations, which are described below, reduce the possibility of cognitive control by removing or denying access to information needed to interpret and understand the image.
These global image manipulations are also useful because they can also be applied to reading, permitting direct cross-task comparisons. This is important because reading is measurably different from other visual tasks, such as scene viewing. For example, fixation durations are significantly shorter in reading (Henderson and Hollingworth, 1998; Rayner, 2009; Luke et al., 2013). Saccade amplitudes tend to be shorter in reading as well (Rayner, 2009; Henderson and Luke, 2014). On the other hand, in reading the eyes are presumably guided by the same neural systems as in other visual tasks, and eye movements are made for the purpose of gathering information regardless of task. In support of this is the observation that aggregate measures of eye movement behavior correlate across tasks (Henderson and Luke, 2014), although not all researchers have found this relationship with regard to reading (Rayner et al., 2007). At the same time, while many core visual and eye movement control areas appear to be common to both tasks (Choi and Henderson, 2015), cognitive control in reading and scene viewing could be exerted by different cortical centers. For example, the parahippocampal place area (PPA; Epstein and Kanwisher, 1998; Epstein et al., 1999) appears to be involved in scene viewing but not in reading (Choi and Henderson, 2015; Henderson and Choi, 2015), while the visual word form area (VWFA; Cohen et al., 2000; McCandliss et al., 2003) and language areas in the left hemisphere contribute to eye movement control in reading but not in scene viewing (Choi and Henderson, 2015; Henderson et al., 2015). So, the underlying processes that control eye movements, making them sensitive to the meaning of words and objects, might differ in significant ways in reading compared to other tasks. Identifying which processes are common to all tasks and which are task-specific is an important goal of eye-movement research.
Usually, the global image manipulations used to study eye movement control involve obscuring or removing the stimulus for an extended period of time. Sometimes participants are given a brief view of part of the text or of the scene before it is removed from view (Rayner et al., 2003, 2009). The results of these studies suggest that saccades are under cognitive control in both tasks. Another technique, called the stimulus onset delay (SOD) paradigm, involves covering all or part of the visual stimulus with a mask during predefined saccades, so that when the next fixation begins the stimulus is not visible. The mask remains on screen for a predetermined and varied delay and is then removed so that the stimulus again becomes visible. The SOD paradigm thus simulates processing difficulty in a manner that is precisely controlled and easily applied to a variety of different visual tasks. This paradigm has been employed to study eye movement control in both reading (Rayner and Pollatsek, 1981; Morrison, 1984; Dambacher et al., 2013) and scene processing (Henderson and Pierce, 2008; Henderson and Smith, 2009). The SOD paradigm has also been used to compare reading and scene viewing directly (Nuthmann and Henderson, 2012; Luke et al., 2013), and equivalent effects of delay duration on fixation durations were observed in both tasks, strongly suggesting that reading and scene viewing share a common mechanism for the control of fixation duration.
The SOD paradigm typically reveals two populations of fixations: some that outlast the delay and others that do not (Henderson and Pierce, 2008; Henderson and Smith, 2009; Luke et al., 2013). The first population of fixations appear to be under cognitive control, increasing linearly with the duration of the delay, while the second population of fixations does not lengthen in response to the presence of the mask, suggesting that these fixations are not under cognitive control. Thus, direct comparisons of eye movement control in different tasks are important not only because they tell us that these tasks share a common mechanism, but also because they reveal something about the nature of that mechanism. In some models, such as E–Z reader (Reichle et al., 1998), most or all reading saccades are initiated by successful completion of some stage of lexical access, while other models such as SWIFT (Engbert et al., 2002, 2005), CRISP (Nuthmann et al., 2010; Nuthmann and Henderson, 2012), and the competition-interaction model (Yang and McConkie, 2001) delay some saccades when cognitive processing difficulty is encountered. The existence of two different populations of fixations is more consistent with the latter class of models. Exploring eye movement control across multiple tasks can help to further adjudicate between these different proposals.
Another global method for exploring eye movement control that has been employed exclusively in reading is the pseudo-reading paradigm, in which all letters in a text are replaced with block shapes or a single letter such as Z. This manipulation removes all meaning from the text, but preserves the visual-spatial layout of the words, sentences, and paragraphs. A finding from this technique is that fixations are typically longer in pseudo-reading than in reading. This finding seems rather paradoxical at first, as one might expect longer fixations when cognitive processing is engaged, not when it is absent, as no processing difficulty should occur when there is nothing to process; nevertheless this finding has been consistently shown across studies (Vitu et al., 1995; Rayner and Fischer, 1996). If we define processing difficulty simply as an inability to identify a stimulus, such as a word, then it makes sense that fixation durations should be lengthened when meaning is removed and identification is not possible. Or it could be that having meaning facilitates processing, thereby shortening fixations relative to the meaningless text condition (Reichle et al., 2012).
Like the SOD paradigm, the pseudo-reading technique has also shown that some eye movement behaviors in reading are under the influence of cognitive control, while others appear not to be (Nuthmann et al., 2007; Henderson and Luke, 2012; Luke and Henderson, 2013). The pseudo-reading technique has also been used in combination with EEG or MRI to explore the neural bases of cognitive control in reading (Henderson et al., 2013, 2014a, 2015).
The present study uses the principle behind the pseudo-reading paradigm, the removal of meaningfulness, to directly compare the cognitive control of eye movements in reading and in scene viewing. We manipulated text and scenes to create a pseudo-reading and a pseudo-scene viewing condition, and we then compared participants’ eye movements in the two tasks and in their pseudo-variants in a within-subjects design. Based on previous research on reading, we expected increased fixation durations for meaningless stimuli (Vitu et al., 1995; Rayner and Fischer, 1996; Luke and Henderson, 2013). Filtering scenes to remove high-frequency visual information, which makes object identification difficult, has also been shown to increase fixation durations (Mannan et al., 1997; Henderson et al., 2014b). We predict, therefore, that fixation durations will be longer for our pseudo-stimuli, indicating that at least some fixations are under cognitive control.
This manipulation permits us to test two more specific hypotheses about eye-movement control as well. The first is that the same systems control eye movements in reading and in scene viewing: If eye movements are controlled by the same systems across tasks, then eye movements should be influenced similarly by the removal of meaningfulness in both tasks. We note here that we use the term ‘meaningfulness’ because of the global nature of the manipulation; the pseudo-stimuli differ from the original text and scenes on many levels, but what is important is that they are not interpretable, meaning that cognitive control has little opportunity to influence eye movements for these stimuli (see Figures 1 and 2 below). The second hypothesis is that, consistent with findings from the SOD paradigm and from pseudo-reading that not all fixations are under cognitive control (Henderson and Pierce, 2008; Henderson and Smith, 2009; Luke and Henderson, 2013; Luke et al., 2013; Henderson and Luke, 2014), the removal of meaningfulness will only affect some, and, not all, fixations.

FIGURE 1. Examples of text and pseudo-text. Normal text is above, with the corresponding pseudo-text below.

FIGURE 2. Examples of the scene and pseudo-scene stimuli. Normal scenes are on the left, with the corresponding pseudo-scenes on the right.
Materials and Methods
Participants
Forty participants recruited from Brigham Young University completed the experiment. All participants were native English speakers with 20/20 corrected or uncorrected vision. Prior to participant recruitment, the institutional review board that Brigham Young University approved the study.
Apparatus
Eye movements were recorded via an SR Research Eyelink 1000 plus tower mount eye tracker (spatial resolution of 0.01°) sampling at 1000 Hz. Subjects were seated 60 cm away from a 24″ LCD monitor with display resolution set to 1600 × 900, so that approximately three characters subtended 1° of visual angle. Scenes (800 × 600 pixel images) subtended 21 by 16° of visual angle. Head movements were minimized with a chin and head rest. Although viewing was binocular, eye movements were recorded from the right eye. The experiment was controlled with SR Research Experiment Builder software.
Materials
Fifty-six short paragraphs (40–60 words) were taken from online news articles. These texts were used in Luke and Henderson (2013) and included a total of 1415 unique words: three one-letter words, 30 two-letter words, 93 three-letter words, 197 four-letter words, 247 five-letter words, 227 six-letter words, 218 seven-letter words, 159 eight-letter words, 110 nine-letter words, and 131 words 10 letters or longer. Two different versions of each text were created, a Normal Reading version, in which the text appeared on the screen in Courier New 16pt font, and a Mindless Reading version, in which the text was displayed in a custom font (also 16pt). This font transformed letters into block shapes (see Figure 1) while preserving overall word shape. Both fonts were monospace, and all letters, words, and lines of text appeared in exactly the same location regardless of font.
For the scene stimuli, pseudo-scenes were created that were analogous to the pseudo-texts in that they had a complex visual structure similar to that of their real scene counterparts but were not meaningful. These pseudo-scenes did not contain any identifiable objects and were not easily assigned to a particular scene category. In order to create a set of pseudo-scenes, we began with a large set of 840 images. The images depicted scenes from seven different categories, five outdoor and two indoor. The outdoor scenes were images of beaches, forests, mountains, cityscapes, and highways (Walther et al., 2009), while the indoor scenes were images of bedrooms and kitchens.
Our goal was to find a manipulation for scenes that was similar to the manipulation that we and others had previously used for text (see Figure 1), which still looked like text but was not interpretable. Specifically, we wanted to (1) preserve the spatial layout of the scene as much as possible, while (2) removing meaning. This proved to be a difficult task for visual scenes, and we tried and rejected several different methods. The manipulation we ultimately chose removed the meaning from these images via an extensive filtering process that extracted the edges from the images, expanded and distorted these edges, and then filled the empty areas within these newly warped edges with color, a process which also erased the edge lines. Then both the scenes and pseudo-scenes were transformed to grayscale.
This manipulation disguised the identities of the objects in the image and made the scene categories difficult to identify. The pseudo-scenes were then normed to see which ones were the most difficult to identify. All 840 meaningless images were posted on Amazon’s Mechanical Turk (Buhrmester et al., 2011). Participants were told that each image was created by altering a photograph of a scene, and asked to provide a short label identifying the category of the scene that the image was created from (or “Don’t Know” if they were unable to identify it) and to rate their confidence in the label they had provided. Each image was labeled by ten different participants.
Based on these norming data, 56 pseudo-scenes were selected, eight from each scene category. Overall, participants in the norming study gave the “Don’t Know” response for 73% of the images, and for the minority of images that they did attempt to provide a label for, they provided a correct label only 10% of the time. Confidence ratings were very low (M = 1.34 on a 5-point scale). Therefore, these images were extremely difficult to identify, even for participants who knew that the images had been derived from actual scenes. Examples of the images used can be seen in Figure 2.
Procedure
For the reading task, participants were told that they would be reading short texts on a computer screen while their eye movements were recorded. Participants were also told that some of the texts would appear with blocks in place of letters, and that in those cases they should move their eyes as if they were reading. These are the standard instructions given in pseudo-reading experiments (Vitu et al., 1995; Rayner and Fischer, 1996; Nuthmann et al., 2007; Luke and Henderson, 2013). Participants were informed that their memory for the texts and pseudo-texts would be tested at the end of the experimental session. Each trial involved the following sequence. The trial began with a gaze trigger, a black circle presented in the position of the first character in the text. Once a stable fixation was detected on the gaze trigger, the text was presented. The participant read the text and pressed a button when finished. Then a new gaze trigger appeared and the next trial began.
For the scene task, participants were told that they would be viewing both photographs and patterns of blobs and shapes on the screen as their eye movements were monitored. Participants were further told that they should view each image in preparation for a memory test that would be administered at the end of the experiment. Each trial involved the following sequence. Each trial began with a gaze trigger, which consisted of a black circle presented in the center of the screen. Once a stable fixation had been detected on the gaze trigger, the image was presented for 10 s. At the end of 10 s, a new gaze trigger appeared and the next trial began.
Stimulus condition (Meaningful vs. Pseudo-Stimulus) was counterbalanced across two stimulus lists, separately for each task (Reading vs. Scene Viewing), and each participant saw only one of the lists. Thus, each participant saw 28 normal texts, 28 pseudo-texts, 28 normal scenes, and 28 pseudo-scenes, and no participant saw the same text or scene twice. The order of stimulus presentation was counterbalanced across participants, with half of the participants completing the scene viewing task first, and half the reading task. Within each task, stimuli were presented in a random order for each participant. For the memory test, participants were presented with a random selection of novel and previously viewed texts, scenes, and pseudo-scenes, and asked to indicate via button-press if they had seen the stimulus before. The memory test was administered solely to ensure that participants attended carefully to the experimental tasks, and so the data from the memory task were not analyzed.
Results
Fixations shorter than 50 ms or longer than 1200 ms were removed as outliers, and saccades larger than 22° were removed to exclude return sweeps in reading. Summary statistics for all dependent variables can be found in Table 1.

TABLE 1. Means (and standard deviations) for the dependent variables.
Saccade Amplitude
A by-participant 2 (TASK: Reading vs. Scene Viewing) × 2 (STIMULUS TYPE: Meaningful vs. Pseudo-Stimulus) ANOVA was conducted on saccade amplitude. In this analysis, both main effects were significant, as was the interaction (all Fs > 9.12, all ps < 0.0061). Follow-up t-tests showed that the significant interaction indicated that the effect of STIMULUS TYPE was present for reading but was not significant for scene viewing (Reading t(39) = -2.82, p = 0.0082, difference = 0.44; Scene Viewing t(39) = -0.63, p = 0.53, difference = 0.1). Interestingly, the mean saccade amplitude was shorter in reading than in pseudo-reading (see Table 1). This contradicts findings from previous studies using similar pseudo-reading tasks, where longer mean saccades were observed in normal reading than in pseudo-reading (Vitu et al., 1995; Rayner and Fischer, 1996; Luke and Henderson, 2013). Luke and Henderson (2013) observed that these mean differences were due to a greater proportion of very short and long fixations in pseudo-reading. Figure 3 shows that the same pattern of results was obtained for reading in the current study. A similar increase in the proportion of longer saccades is observable for pseudo-scene viewing, although this shift was not large enough to significantly influence the means. Thus, although the findings of the present study with regard to mean saccade amplitudes may appear to contradict previous findings that saccades are shorter is pseudo-reading, the pattern of changes in the distribution of saccade amplitudes is the same.
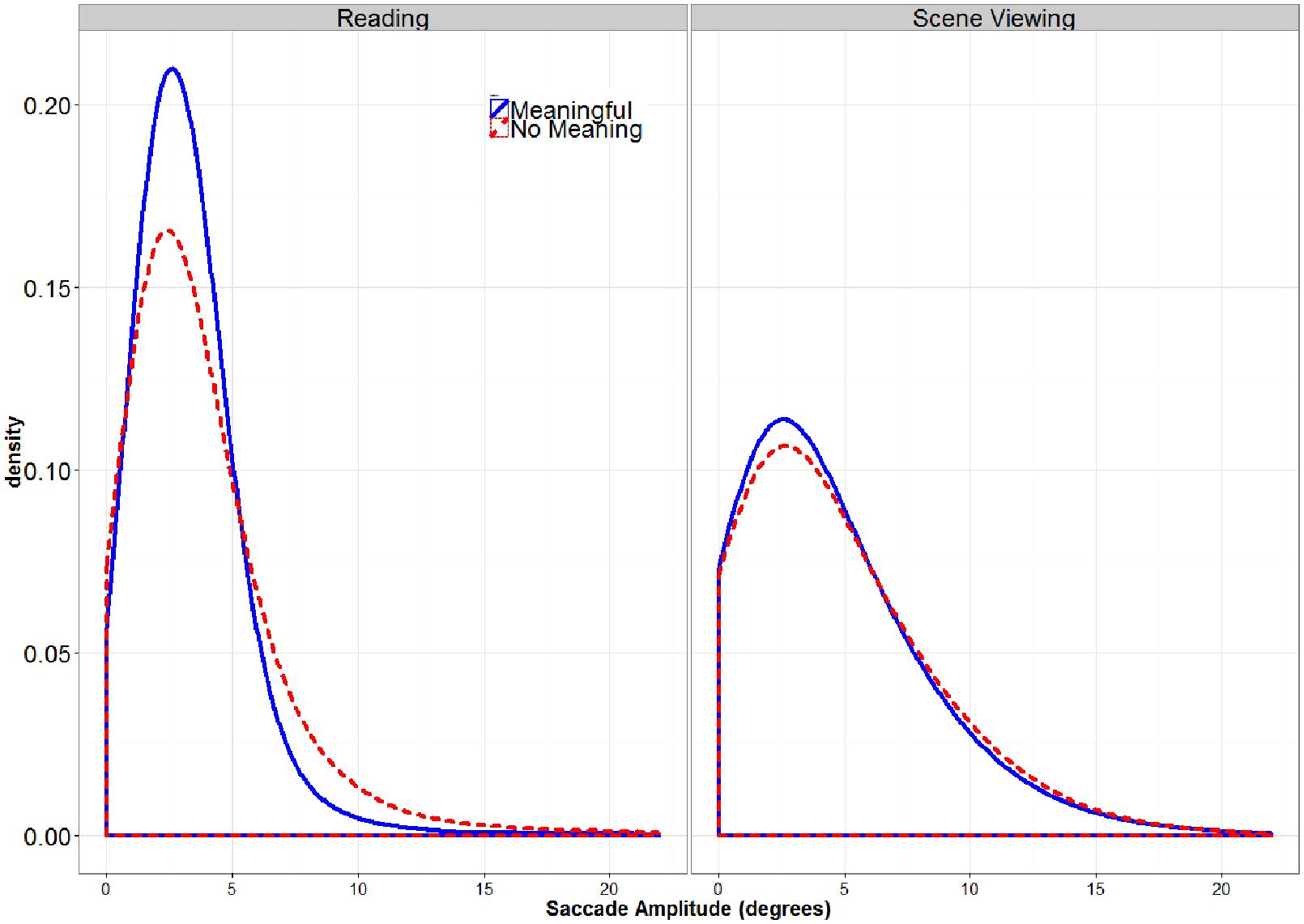
FIGURE 3. Global Distribution of Saccade Amplitudes. There was a greater proportion of very short and long saccades for the pseudo-stimuli (dashed lines) than for the meaningful stimuli, especially for the reading task.
Fixation Duration
Figure 4 shows the distribution of fixation durations for both scenes and text in the meaningful and pseudo-stimulus conditions. This figure illustrates that fixation duration distributions are not normal but are skewed to the right. Any difference in means between the meaningful and pseudo-stimuli might reflect a difference in the center of the two distributions, which occurs when most fixations in one condition are longer. However, since means are strongly influenced by outliers and extreme scores, a difference between means can also occur because one distribution is more skewed than another, which occurs when some subset (but not all) of the fixations are longer. Mean differences can reflect either of these differences or both in combination (Balota and Yap, 2011). Since the center and skew of fixation duration distributions vary independently of each other and often reflect different processes (Staub and Benatar, 2013), it is important to consider them separately.
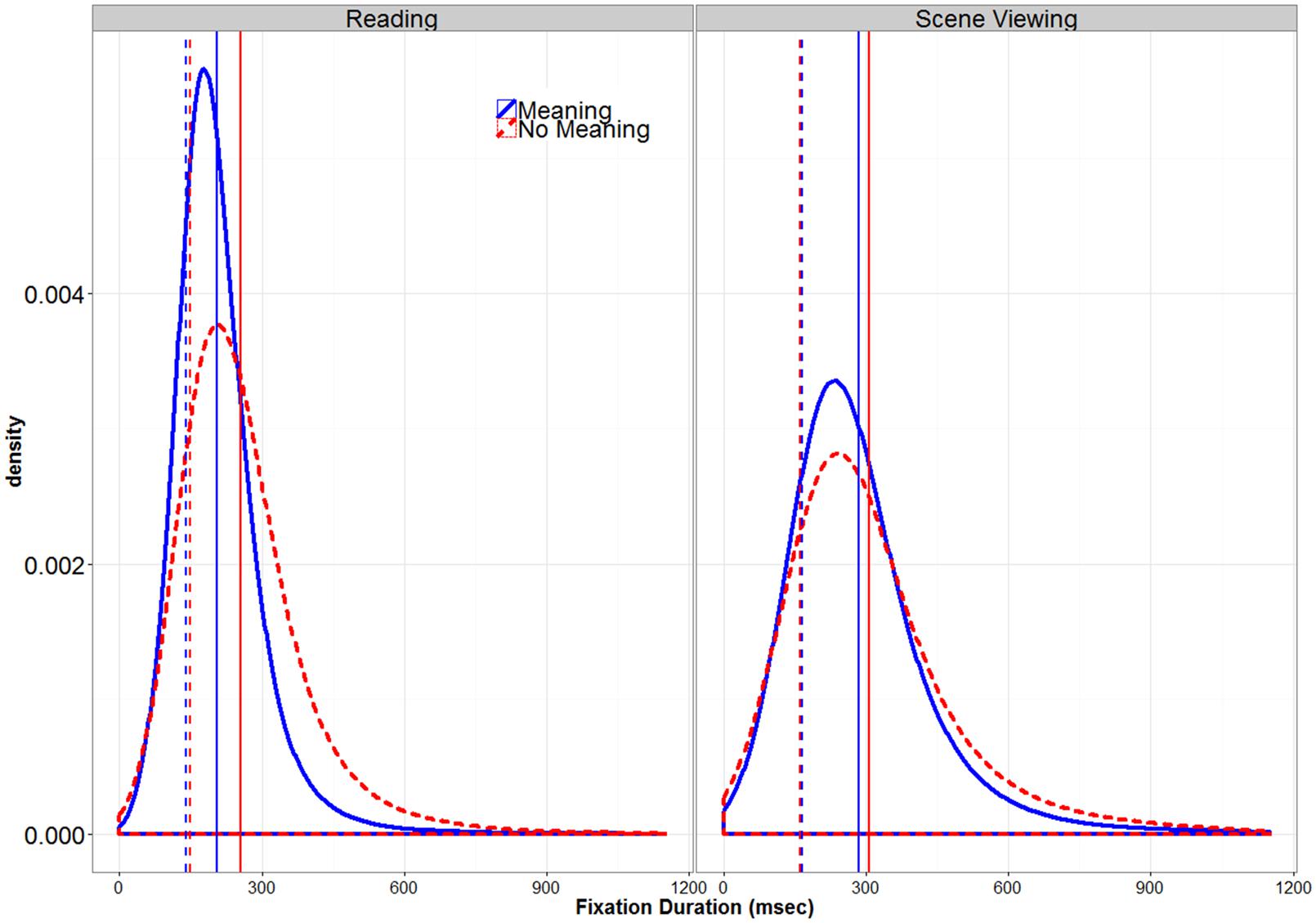
FIGURE 4. Global Distribution of Fixation Durations. The solid vertical lines represent overall means, while the dotted vertical lines represent the values for μ derived from the response time distribution analysis.
To test whether the removal of meaningfulness had similar effects in the different tasks, the fixation duration distributions for each participant in each condition were analyzed using a response time distributional analysis (Balota and Yap, 2011). This analysis fits participants’ response time data with an ex-Gaussian distribution (Ratcliff, 1979), which is the convolution of a normal (Gaussian) distribution and an exponential distribution, with two parameters representing the normal component (μ, the mean, and σ, the SD), and a single exponential parameter (τ). Any changes in μ and σ indicate changes in the distribution’s normal component (i.e., the center), whereas increases in τ indicate increased skew to the right. Ex-Gaussian distributions fit eye-movement data quite well (Staub et al., 2010; Staub, 2011; White and Staub, 2012; Luke and Henderson, 2013; Luke et al., 2013). The ex-Gaussian distribution was fitted to the data from each participant in each task in each meaning condition using QMPE software (Heathcote et al., 2004). The mean ex-Gaussian parameters are found in Table 2.
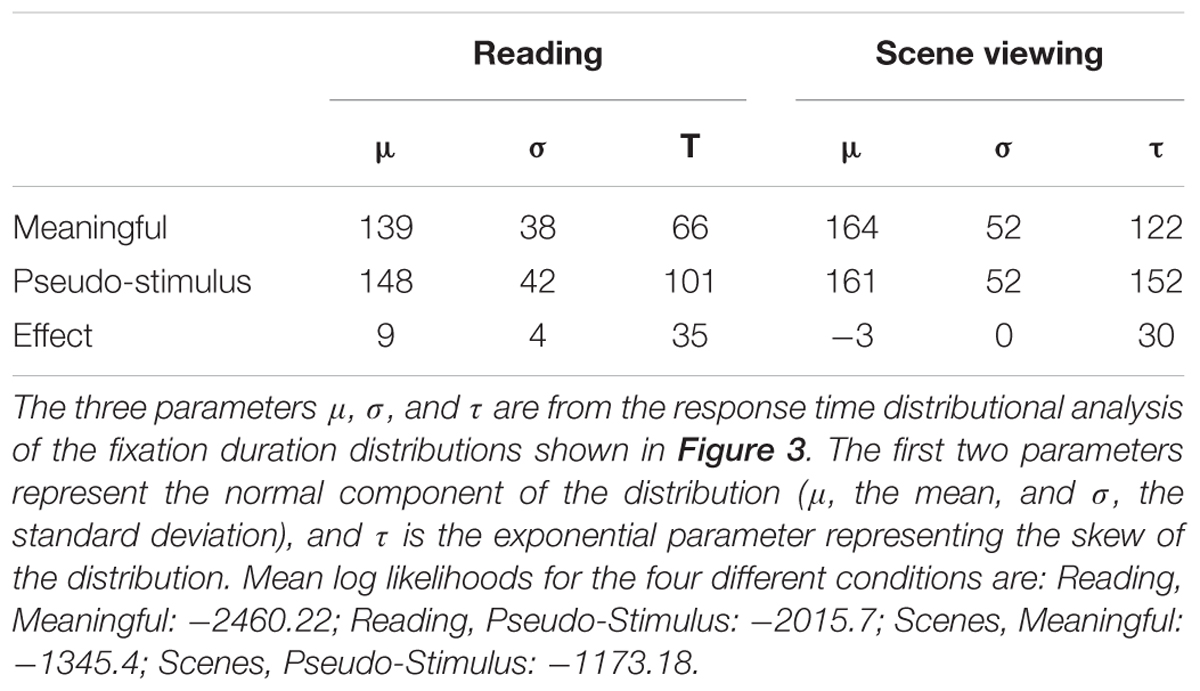
TABLE 2. Parameters from the response time distributional analysis of fixation durations.
Previous research comparing fixation duration distributions in scene viewing and reading has observed that the distribution in scene viewing is both shifted to the right and more skewed to the right compared to reading (Luke et al. (2013); see also Henderson and Hollingworth (1998)). The removal of meaningfulness from a text stimulus has been shown to result in a “fatter tail”, skewing the distribution to the right compared to the normal, meaningful stimulus condition, but does not appear to influence μ or σ (Luke and Henderson, 2013). Figure 4 and Table 2 suggests that the primary difference between the Meaningful and Pseudo-Stimulus conditions in both tasks is indeed an increase in skew in the Pseudo-Stimulus condition, with no large shifts in the center of the distribution apparent. To look for any interactions between task and stimulus type that might indicate task-based differences in fixation duration control, especially in the analysis of the skew of the distribution (τ), by-participant 2 (TASK: Reading vs. Scene Viewing) × 2 (STIMULUS TYPE: Meaningful vs. Pseudo-Stimulus) ANOVAs were conducted on all three of the ex-Gaussian parameters. In the analyses of μ and σ, there were main effects of TASK (both Fs > 43.75, all ps < 0.0046), indicating that both parameters were larger for scenes than for text. The main effects of STIMULUS TYPE were not significant (both Fs < 3.9, both ps > 0.056). The interaction of the two factors was significant in both analyses (both Fs > 6.9, all ps < 0.012), indicating that the effect of TASK was somewhat smaller in the Pseudo-Stimulus condition (Meaning: both ts > 5.61, both ps < 0.0001; No meaning: both ts > 2.28, both ps < 0.025). When the effect of STIMULUS TYPE was considered separately for each task, no significant differences were found in the analysis of μ (Reading: t(39) < 1.78, p = 0.072; Scene Viewing: t(39) < 0.57, p > 0.57). The effect was significant (although numerically tiny, only 4 ms) for reading only in the analysis of σ (t(39) < 2.03, p = 0.046; Scene Viewing: t(39) < 0.07, p > 0.94). These results indicate that if semantic content has an influence on the center or spread of the fixation duration distributions, such influences are quite small (<10 ms; see Table 2) and mostly non-significant. Accordingly, between-task differences in the influence of semantic content on μ or σ, if they exist at all, are on the order of a few milliseconds. Thus, these results are consistent with previous studies (Luke and Henderson, 2013).
In the analysis of τ, both main effects (TASK and STIMULUS TYPE) were significant (both Fs > 99.06, both ps < 0.0001). The interaction of the two was not significant (p > 0.32). These findings indicate that while all three parameters of the fixation duration distribution were larger in scene viewing than in reading, consistent with previous research (Luke et al., 2013), meaningfulness only had a significant effect on the skew of the distribution (Luke and Henderson, 2013). The size of this effect was statistically the same in the two tasks.
Discussion
The present study investigated how the meaningfulness of a visual stimulus influences how our eyes move. More specifically, we globally manipulated the meaningfulness of both texts and scenes in a within-subjects design, enabling us to explore potential differences in eye movement control across two visual tasks.
Saccade amplitudes were found to increase significantly in reading for pseudo-text. This difference in mean saccade amplitude across conditions appears to result from an increase in very short and long saccade amplitudes when meaning is removed from text. This shift in the distribution has been observed in other studies (Luke and Henderson, 2013), although in these studies means decreased because the proportion of short saccades increased more than was observed here. In scene viewing there was a numeric trend toward an increase (see Table 1) but it was small and far from significant. There was some suggestion of an increase in the proportion of longer fixations for pseudo-scenes as well. The absence of a significant effect of semantic content on saccades amplitudes in scene viewing may simply reflect a ceiling effect; saccades are larger by default in scene viewing, and it is probably not possible to increase them much more and still keep the eyes within the bounds of the stimulus. Regardless, these observed changes in saccade amplitude likely reflect a reduced need for foveal processing when the stimulus is not being processed for meaning.
One goal of the present study was to investigate whether the influence of stimulus meaningfulness differs across tasks. A close look at the distribution parameters from the fixation duration distribution analysis (Table 2) shows that the removal of meaningfulness affected the fixation duration distributions in the same way in both tasks, influencing the skew (τ) but not consistently influencing the center (μ, σ) of the distributions. That is, the distribution analysis showed no consistent evidence of any significant effects of meaning on either μ or σ. There was, however, a main effect of stimulus type in the analysis of τ. Further, the interaction of stimulus type and task was not significant in the analysis of τ, indicating that the removal of meaningfulness from the stimulus had a statistically identical influence in reading and in scene viewing. Thus, it appears that the influence of cognitive control on eye movements in reading and scene viewing is both qualitatively and quantitatively similar; not only did the removal of meaningfulness influence the same component of the distribution in both tasks, the magnitude of that influence was nearly identical. This observation is highly consistent with other research with the SOD paradigm showing that eye movements respond similarly to processing difficulty in reading and in scene viewing (Luke et al., 2013).
Increases in τ like those observed here occur when some, but not all, of the fixations are longer, which elongates the tail of the distribution but does not significantly shift its center. Thus, the fact that for the pseudo-stimuli τ was increased but the other parameters of the ex-Gaussian distribution were not indicates that not all fixations were affected by the removal of meaningfulness. This finding fits nicely with research using the SOD paradigm that reveals two populations of eye movements, providing converging evidence that longer duration fixations are under cognitive control and shorter duration fixations are not (Henderson and Pierce, 2008; Henderson and Smith, 2009; Nuthmann and Henderson, 2012; Luke et al., 2013). This finding is most consistent with models of eye movement control in which only longer fixations are influenced by the currently fixated stimulus (e.g., the competition-inhibition theory; Yang and McConkie (2001).
While the global manipulation employed here is useful for cross-task comparisons, it of course has certain limitations. Since our manipulation altered the stimuli in multiple ways, removing or changing some low-level visual features as well as obscuring the identity of words and objects, it is not possible to determine which cognitive processes (or which stage in processing) has the most influence on eye movements. This technique cannot therefore adjudicate cleanly between different proposals about the nature and source of cognitive control. The present study does, however, provide additional evidence, first, that reading, and scene viewing share a common control mechanism, and, second, that only some fixations are under the direct influence of the visual stimulus. Most models of eye-movement control apply to reading only (Reichle et al., 1998; Engbert et al., 2002, 2005), and so may not generalize to other tasks (but see Reichle et al. (2012) for an example of how E–Z reader can generalize to non-reading tasks). One model of eye-movement control that has been shown to successfully predict eye movements in both reading and scene viewing is the CRISP model (Nuthmann et al., 2010; Nuthmann and Henderson, 2012). CRISP also predicts that some eye movements will not be under cognitive control; fixation duration is determined by a random walk timer, after which a new saccade program is initiated. Prior to saccade program initiation, cognitive intervention can occur via inhibition of the saccade program when processing difficulty is encountered, but after the timer expires no cognitive intervention is possible. Thus, CRISP is consistent with the findings of this and other studies. The results of the current study suggest that current and future models of eye movement control should, first, be able to account for eye movements across multiple tasks, and second, incorporate a mechanism for cognitive control that exempts some subset of fixations.
Author Contributions
Both authors (SL, JH) made substantial contributions to the conception or design of the work. SL was primarly responsible for the acquisition, analysis, or interpretation of data for the work. SL Drafted the work and JH revised it critically for important intellectual content. Both SL and JH gave final approval of the version to be published, and agree to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Balota, D. A., and Yap, M. J. (2011). Moving beyond the mean in studies of mental chronometry the power of response time distributional analyses. Curr. Dir. Psychol. Sci. 20, 160–166. doi: 10.1177/0963721411408885
Buhrmester, M., Kwang, T., and Gosling, S. D. (2011). Amazon’s mechanical turk a new source of inexpensive, yet high-quality, data? Perspect. Psychol. Sci. 6, 3–5. doi: 10.1177/1745691610393980
Choi, W., and Henderson, J. M. (2015). Neural correlates of active vision: an fMRI comparison of natural reading and scene viewing. Neuropsychologia 75, 109–118. doi: 10.1016/j.neuropsychologia.2015.05.027
Cohen, L., Dehaene, S., Naccache, L., Lehéricy, S., Dehaene-Lambertz, G., Hénaff, M.-A., et al. (2000). The visual word form area. Brain 123, 291–307. doi: 10.1093/brain/123.2.291
Dambacher, M., Slattery, T. J., Yang, J., Kliegl, R., and Rayner, K. (2013). Evidence for direct control of eye movements during reading. J. Exp. Psychol. Hum. Percept. Perform. 39, 1468–1484. doi: 10.1037/a0031647
Engbert, R., Longtin, A., and Kliegl, R. (2002). A dynamical model of saccade generation in reading based on spatially distributed lexical processing. Vis. Res. 42, 621–636. doi: 10.1016/S0042-6989(01)00301-7
Engbert, R., Nuthmann, A., Richter, E. M., and Kliegl, R. (2005). SWIFT: a dynamical model of saccade generation during reading. Psychol. Rev. 112, 777–813. doi: 10.1037/0033-295X.112.4.777
Epstein, R., Harris, A., Stanley, D., and Kanwisher, N. (1999). The parahippocampal place area: recognition, navigation, or encoding? Neuron 23, 115–125. doi: 10.1016/S0896-6273(00)80758-8
Epstein, R., and Kanwisher, N. (1998). A cortical representation of the local visual environment. Nature 392, 598–601. doi: 10.1038/33402
Heathcote, A., Brown, S., and Cousineau, D. (2004). QMPE: estimating lognormal, wald, and weibull RT distributions with a parameter-dependent lower bound. Behav. Res. Methods Instrum. Comput. 36, 277–290. doi: 10.3758/BF03195574
Henderson, J. (2003). Human gaze control during real-world scene perception. Trends Cogn. Sci. 7, 498–504. doi: 10.1016/j.tics.2003.09.006
Henderson, J. M., and Choi, W. (2015). Neural correlates of fixation duration during real-world scene viewing: evidence from fixation-related (FIRE) fMRI. J. Cogn. Neurosci 27, 1137–1145. doi: 10.1162/jocn_a_00769
Henderson, J. M., Choi, W., and Luke, S. G. (2014a). Morphology of primary visual cortex predicts individual differences in fixation duration during text reading. J. Cogn. Neurosci. 26, 2880–2888. doi: 10.1162/jocn_a_00668
Henderson, J. M., Choi, W., Luke, S. G., and Desai, R. H. (2015). Neural correlates of fixation duration in natural reading: evidence from fixation-related fMRI. NeuroImage 119, 390–397. doi: 10.1016/j.neuroimage.2015.06.072
Henderson, J. M., and Hollingworth, A. (1998). “Eye movements during scene viewing: an overview eye guidance in reading and scene perception,” in Eye Guidance While Reading and While Watching Dynamic Scenes, ed. G. Underwood (Oxford: Elsevier), 269–293.
Henderson, J. M., and Luke, S. G. (2012). Oculomotor inhibition of return in normal and mindless reading. Psychon. Bull. Rev. 19, 1101–1107. doi: 10.3758/s13423-012-0274-2
Henderson, J. M., and Luke, S. G. (2014). Stable individual differences in saccadic eye movements during reading, pseudoreading, scene viewing, and scene search. J. Exp. Psychol. Hum. Percept. Perform. 40, 1390–1400. doi: 10.1037/a0036330
Henderson, J. M., Luke, S. G., Schmidt, J., and Richards, J. E. (2013). Co-registration of eye movements and event-related potentials in connected-text paragraph reading. Front. Syst. Neurosci. 7:28. doi: 10.3389/fnsys.2013.00028
Henderson, J. M., Olejarczyk, J., Luke, S. G., and Schmidt, J. (2014b). Eye movement control during scene viewing: immediate degradation and enhancement effects of spatial frequency filtering. Vis. Cogn. 22, 486–502. doi: 10.1080/13506285.2014.897662
Henderson, J. M., and Pierce, G. L. (2008). Eye movements during scene viewing: evidence for mixed control of fixation durations. Psychon. Bull. Rev. 15, 566–573. doi: 10.3758/pbr.15.3.566
Henderson, J. M., and Smith, T. J. (2009). How are eye fixation durations controlled during scene viewing? Further evidence from a scene onset delay paradigm. Vis. Cogn. 17, 1055–1082. doi: 10.1080/13506280802685552
Henderson, J. M., Weeks, P. A., and Hollingworth, A. (1999). Effects of semantic consistency on eye movements during scene viewing. J. Exp. Psychol. Hum. Percept. Perform. 25, 210–228.
Just, M. A., and Carpenter, P. (1980). A theory of reading: from eye fixations to comprehension. Psychol. Rev. 87, 329–354. doi: 10.1037/0033-295X.87.4.329
Kliegl, R., Nuthmann, A., and Engbert, R. (2006). Tracking the mind during reading: the influence of past, present, and future words on fixation durations. J. Exp. Psychol. Gen. 135, 12–35. doi: 10.1037/0096-3445.135.1.12
Luke, S. G., and Henderson, J. M. (2013). Oculomotor and cognitive control of eye movements in reading: evidence from mindless reading. Atten. Percept. Psychophys. 75, 1230–1242. doi: 10.3758/s13414-013-0482-5
Luke, S. G., Nuthmann, A., and Henderson, J. M. (2013). Eye movement control in scene viewing and reading: evidence from the stimulus onset delay paradigm. J. Exp. Psychol. Hum. Percept. Perform. 39, 10–15. doi: 10.1037/a0030392
Mannan, S. K., Ruddock, K. H., and Wooding, D. S. (1997). Fixation patterns made during brief examination of two-dimensional images. Perception 26, 1059–1072. doi: 10.1068/p261059
McCandliss, B. D., Cohen, L., and Dehaene, S. (2003). The visual word form area: expertise for reading in the fusiform gyrus. Trends Cogn. Sci. 7, 293–299. doi: 10.1016/S1364-6613(03)00134-7
Morrison, R. E. (1984). Manipulation of stimulus onset delay in reading: evidence for parallel programming of saccades. J. Exp. Psychol. Hum. Percept. Perform. 10, 667–682.
Nuthmann, A., Engbert, R., and Kliegl, R. (2007). The IOVP effect in mindless reading: experiment and modeling. Vision Res. 47, 990–1002. doi: 10.1016/j.visres.2006.11.005
Nuthmann, A., and Henderson, J. M. (2012). Using CRISP to model global characteristics of fixation durations in scene viewing and reading with a common mechanism. Vis. Cogn. 20, 457–494. doi: 10.1080/13506285.2012.670142
Nuthmann, A., Smith, T. J., Engbert, R., and Henderson, J. M. (2010). CRISP: a computational model of fixation durations in scene viewing. Psychol. Rev. 117, 382–405. doi: 10.1037/a0018924
Ratcliff, R. (1979). Group reaction time distributions and an analysis of distribution statistics. Psychol. Bull. 86, 446–461. doi: 10.1037/0033-2909.86.3.446
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 124, 372–422. doi: 10.1037/0033-2909.124.3.372
Rayner, K. (2009). Eye movements and attention in reading, scene perception, and visual search. Q. J. Exp. Psychol. (Hove) 62, 1457–1506. doi: 10.1080/17470210902816461
Rayner, K., and Fischer, M. (1996). Mindless reading revisited: eye movements during reading and scanning are different. Percept. Psychophys. 58, 734–747. doi: 10.3758/BF03213106
Rayner, K., Li, X., Williams, C. C., Cave, K. R., and Well, A. D. (2007). Eye movements during information processing tasks: individual differences and cultural effects. Vision Res. 47, 2714–2726. doi: 10.1016/j.visres.2007.05.007
Rayner, K., Liversedge, S. P., White, S. J., and Vergilino-Perez, D. (2003). Reading disappearing text: cognitive control of eye movements. Psychol. Sci. 14, 385–388. doi: 10.1111/1467-9280.24483
Rayner, K., and Pollatsek, A. (1981). Eye movement control during reading: evidence for direct control. Q. J. Exp. Psychol. 33, 351–373. doi: 10.1080/14640748108400798
Rayner, K., and Reingold, E. M. (2015). Evidence for direct cognitive control of fixation durations during reading. Curr. Opin. Behav. Sci. 1, 107–112. doi: 10.1016/j.cobeha.2014.10.008
Rayner, K., Smith, T. J., Malcolm, G. L., and Henderson, J. M. (2009). Eye movements and visual encoding during scene perception. Psychol. Sci. 20, 6–10. doi: 10.1111/j.1467-9280.2008.02243.x
Reichle, E. D., Pollatsek, A., Fisher, D. L., and Rayner, K. (1998). Toward a model of eye movement control in reading. Psychol. Rev. 105, 125–157. doi: 10.1037/0033-295X.105.1.125
Reichle, E. D., Pollatsek, A., and Rayner, K. (2012). Using E-Z Reader to simulate eye movements in nonreading tasks: a unified framework for understanding the eye–mind link. Psychol. Rev. 119, 155–185. doi: 10.1037/a0026473
Staub, A. (2011). The effect of lexical predictability on distributions of eye fixation durations. Psychon. Bull. Rev. 18, 371–376. doi: 10.3758/s13423-010-0046-9
Staub, A., and Benatar, A. (2013). Individual differences in fixation duration distributions in reading. Psychon. Bull. Rev. 20, 1304–1311. doi: 10.3758/s13423-013-0444-x
Staub, A., White, S. J., Drieghe, D., Hollway, E. C., and Rayner, K. (2010). Distributional effects of word frequency on eye fixation durations. J. Exp. Psychol. Hum. Percept. Perform. 36, 1280–1293. doi: 10.1037/a0016896
Vitu, F. (2003). The basic assumptions of EZ Reader are not well-founded. Behav. Brain Sci. 26, 506–507. doi: 10.1017/S0140525X0351010X
Vitu, F., O’Regan, J. K., Inhoff, A. W., and Topolski, R. (1995). Mindless reading: eye-movement characteristics are similar in scanning letter strings and reading texts. Percept. Psychophys. 57, 352–364. doi: 10.3758/BF03213060
Võ, M. L. H., and Henderson, J. M. (2009). Does gravity matter? Effects of semantic and syntactic inconsistencies on the allocation of attention during scene perception. J. Vis. 9, 24.1–24.15. doi: 10.1167/9.3.24
Walther, D. B., Caddigan, E., Fei-Fei, L., and Beck, D. M. (2009). Natural scene categories revealed in distributed patterns of activity in the human brain. J. Neurosci. 29, 10573–10581. doi: 10.1523/JNEUROSCI.0559-09.2009
Wang, H.-C., Hwang, A. D., and Pomplun, M. (2010). Object frequency and predictability effects on eye fixation durations in real-world scene viewing. J. Eye Move. Res. 3, 3.1–3.10.
White, S. J., and Staub, A. (2012). The distribution of fixation durations during reading: effects of stimulus quality. J. Exp. Psychol. Hum. Percept. Perform. 38, 603–617. doi: 10.1037/a0025338
Keywords: eye movements, cognitive control, meaning, reading, scene perception, eye tracking, eye movement control
Citation: Luke SG and Henderson JM (2016) The Influence of Content Meaningfulness on Eye Movements across Tasks: Evidence from Scene Viewing and Reading. Front. Psychol. 7:257. doi: 10.3389/fpsyg.2016.00257
Received: 19 October 2015; Accepted: 09 February 2016;
Published: 01 March 2016.
Edited by:
Guillaume A. Rousselet, University of Glasgow, UKReviewed by:
Sébastien M. Crouzet, Centre de Recherche Cerveau et Cognition, FranceFrançoise Vitu, Aix-Marseille Université, France
Copyright © 2016 Luke and Henderson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Steven G. Luke, steven_luke@byu.edu