 Matthias Hoben
Matthias Hoben Carole A. Estabrooks1
Carole A. Estabrooks1- 1Knowledge Utilization Studies Program, Faculty of Nursing, University of Alberta, Edmonton, AB, Canada
- 2Medical Faculty, Institute of Health and Nursing Sciences, Martin Luther University of Halle-Wittenberg, Halle, Germany
- 3Network Aging Research, Heidelberg University, Heidelberg, Germany
- 4Faculty of Health Sciences, School of Nursing, University of Ottawa, Ottawa, ON, Canada
- 5Clinical Epidemiology Program, Ottawa Hospital Research Institute, Ottawa Hospital, Ottawa, ON, Canada
We translated the Canadian residential long term care versions of the Alberta Context Tool (ACT) and the Conceptual Research Utilization (CRU) Scale into German, to study the association between organizational context factors and research utilization in German nursing homes. The rigorous translation process was based on best practice guidelines for tool translation, and we previously published methods and results of this process in two papers. Both instruments are self-report questionnaires used with care providers working in nursing homes. The aim of this study was to assess the factor structure, reliability, and measurement invariance (MI) between care provider groups responding to these instruments. In a stratified random sample of 38 nursing homes in one German region (Metropolregion Rhein-Neckar), we collected questionnaires from 273 care aides, 196 regulated nurses, 152 allied health providers, 6 quality improvement specialists, 129 clinical leaders, and 65 nursing students. The factor structure was assessed using confirmatory factor models. The first model included all 10 ACT concepts. We also decided a priori to run two separate models for the scale-based and the count-based ACT concepts as suggested by the instrument developers. The fourth model included the five CRU Scale items. Reliability scores were calculated based on the parameters of the best-fitting factor models. Multiple-group confirmatory factor models were used to assess MI between provider groups. Rather than the hypothesized ten-factor structure of the ACT, confirmatory factor models suggested 13 factors. The one-factor solution of the CRU Scale was confirmed. The reliability was acceptable (>0.7 in the entire sample and in all provider groups) for 10 of 13 ACT concepts, and high (0.90–0.96) for the CRU Scale. We could demonstrate partial strong MI for both ACT models and partial strict MI for the CRU Scale. Our results suggest that the scores of the German ACT and the CRU Scale for nursing homes are acceptably reliable and valid. However, as the ACT lacked strict MI, observed variables (or scale scores based on them) cannot be compared between provider groups. Rather, group comparisons should be based on latent variable models, which consider the different residual variances of each group.
Introduction
Use of best practices based on research (research utilization) is less than optimal in German residential long term care (LTC) settings (Kuske et al., 2009; Meyer et al., 2009; Majic et al., 2010; Treusch et al., 2010; Wilborn and Dassen, 2010; Reuther et al., 2013) with far-reaching consequences for the highly vulnerable residents in LTC. In 2011, the 12,354 LTC facilities in Germany were home to 743,120 residents (Statistisches Bundesamt, 2013). These LTC residents each typically suffer from four to five medical conditions (Balzer et al., 2013), such as: dementia diagnosis (50–70% of the residents), bladder or bowel incontinence (70–80%), oral-dental problems (50–90%), and mood or behavior problems (25–50%). Furthermore, many are functionally impaired (e.g., hearing problems, visual limitations, decreased communication abilities, reduced mobility) and are highly vulnerable to infections, falls and fractures, malnutrition, pressure ulcers, and many other risks (Lahmann et al., 2010; Volkert et al., 2011; Balzer et al., 2013). Due to these complex care needs LTC residents are particularly vulnerable to problems in quality of care, and it is important that caregivers are providing care in line with research based best practices.
Organizational context factors are thought to be centrally important to implementing research findings for improved quality of care (Greenhalgh et al., 2004; Dopson and Fitzgerald, 2005; Meijers et al., 2006; Squires et al., 2013a). For example, in their systematic review Kaplan et al. (2010) found that important factors for the success of quality improvement initiatives are leadership from top management, organizational culture, data infrastructure and information systems, years involved in quality improvement initiatives, physician involvement, microsystem motivation to change, resources, and team leadership. However, Kaplan et al. found key limitations in the literature: (a) an insufficient theoretical foundation, (b) insufficiently defined contextual factors, and (c) lack of well-specified measures. Especially in LTC settings, contextual factors are not well understood and their measurement has rarely been addressed (Estabrooks et al., 2009a; Masso and McCarthy, 2009; Boström et al., 2012; Rahman et al., 2012). This is particularly true for German LTC where dissemination and implementation research has played a small role and few such research tools are available (Hoben et al., 2014b). In three previous publications (Hoben et al., 2013, 2014a,b) we pointed out the lack of research tools to study the association of organizational context factors (e.g., leadership, organizational culture, feedback) with research utilization in German LTC settings.
One of the most pressing gaps in dissemination and implementation (DI) research is the lack of well-developed outcomes and measurement tools (Graham et al., 2010; Proctor et al., 2011; Proctor and Brownson, 2012). By dissemination we mean “an active approach of spreading evidence-based interventions to the target audience via determined channels using planned strategies” (Rabin and Brownson, 2012, p. 26). Implementation “is the process of putting to use or integrating evidence-based interventions within a setting” (Rabin and Brownson, 2012, p. 26). Reliable and valid research tools equip researchers to test theoretical assumptions about dissemination and implementation processes, and about the effectiveness of strategies, by using statistical methods in large samples (Proctor and Brownson, 2012). A lack of robust research tools hampers our understanding of how these processes work and how they can be effectively improved (Proctor and Brownson, 2012).
With the LTC versions of the Alberta Context Tool (ACT) (Estabrooks et al., 2011b) and the Conceptual Research Utilization (CRU) Scale (Squires et al., 2011a), we have two robust and widely used tools developed in Canada with which to study organizational context and research utilization in LTC settings. The Canadian research team was able to demonstrate that more favorable organizational context as assessed by the ACT is positively associated with staff outcomes such as use of best practice (Estabrooks et al., 2015b), lower burnout (Estabrooks et al., 2012), and a better trajectory of resident symptom burden in the last 12 months of life (Estabrooks et al., 2015a). Comparable German research tools were unavailable, therefore we translated the Canadian tools into German, adapted them to the context of German LTC settings, and studied their psychometric properties. In two previously published papers, we report on the translation process (Hoben et al., 2013) and the linguistic validation of the translated tools (Hoben et al., 2014a). Here we report the factor structure (dimensionality), the reliability (based on the results of the factor analyses), and the multiple-group measurement invariance of the translated ACT and CRU Scale.
Materials and Methods
Framework for Psychometric Testing: The Standards for Educational and Psychological Testing
The Standards for Educational and Psychological Testing (AERA et al., 2014) (hereafter referred to as “The Standards”) are recognized as best practice in psychometric testing (Streiner and Norman, 2008). At the time we carried out this study, the 1999 version of The Standards (AERA et al., 1999) were the current version. They were the basis for validating the Canadian versions of the ACT and the CRU Scale (Squires et al., 2011a, 2013b; Estabrooks et al., 2011b) and were used to assess the psychometric properties of similar tools for use in LTC (e.g., Gagnon et al., 2011; Zúñiga et al., 2013). The principles and the reliability and validity concepts outlined in The Standards guided our methods here.
The Standards define validity as a multi-faceted but unitary concept. Different facets of validity can be evaluated from different sources of validity evidence. Validity then is “the degree to which all the accumulated evidence supports the intended interpretation of test scores for the proposed purpose” (AERA et al., 1999, p. 11). According to The Standards, the four sources of evidence for validity of a research tool are defined as follows:
1. Evidence based on test content. To generate this kind of validity evidence, researchers evaluate if the instrument contents (concepts, topics, wording and format of the introductory texts, items, scales, etc.) represent the intended constructs. Methods typically used for this purpose are theory- and evidence-based tool development, and evaluation of the tools by content experts. We used rigorous methods of instrument translation based on best practice guidelines, including two independent forward and back translations, forward translation review by a panel of content experts, and back translation review by the tool developers (Hoben et al., 2013).
2. Evidence based on response processes. Evaluating response processes helps researchers to find out if participants understand the items as intended, if they understand how to use the tools, and if and why they encounter any difficulties when answering the questions. This kind of validity evidence is typically assessed by linguistic validation methods, such as cognitive interviews with target persons (Willis, 2005). Results of cognitive debriefings of the translated tools based on semi-structured cognitive interviews with care providers are published elsewhere (Hoben et al., 2014a).
3. Evidence based on internal instrument structure. These analyses evaluate the extent of the association between instrument items/components and the proposed constructs of the tool. Principal component analyses, exploratory factor analyses, or confirmatory factor analyses are the methods traditionally used here. We report methods and results of this analysis for the German-language versions of the ACT and the CRU Scale in this article.
4. Evidence based on relations to other variables. The relationship between the instrument variables and other (external) parameters can be evaluated in many different ways. Methods range from simple bivariate correlations to complex latent variable causal models. These analyses evaluate if the instrument constructs are associated with other constructs as expected, based on available theory and evidence. We are currently working on these analyses for the German-language versions of the ACT and the CRU Scale.
Measures
The Alberta Context Tool
The ACT is based on the Promoting Action on Research Implementation in Health Services (PARiHS) framework (Kitson et al., 1998; Rycroft-Malone, 2004) and related literature (Fleuren et al., 2004; Greenhalgh et al., 2004), and it is constructed to assess modifiable characteristics of organizational context (Squires et al., 2013b). According to the PARiHS framework, organizational context is “the environment or setting in which people receive health care services, or in the context of improving care practices, the environment or setting in which the proposed change is to be implemented” (Rycroft-Malone, 2004, p. 299). The ACT is available in versions for adult acute care, pediatric acute care, LTC, and home care, has been translated into French, Dutch, Swedish, Chinese, and German, and is being used in Canada, the United States, Sweden, the Netherlands, the United Kingdom, the Republic of Ireland, Australia, China, and Germany (Squires et al., 2013b). The Canadian ACT LTC (Estabrooks et al., 2011b) contains questionnaires for six different provider groups: (1) care aides, (2) professional (registered or licensed) nurses, (3) allied health providers, (4) practice specialists (e.g., clinical educators, nurse practitioners, clinical nursing specialists, quality improvement specialists), (5) care managers, and 6) physicians. The 56 to 58 items (depending on the form) reflect 10 concepts of organizational context. These 10 concepts are delineated in Table 1, along with a definition and an example item for each concept.
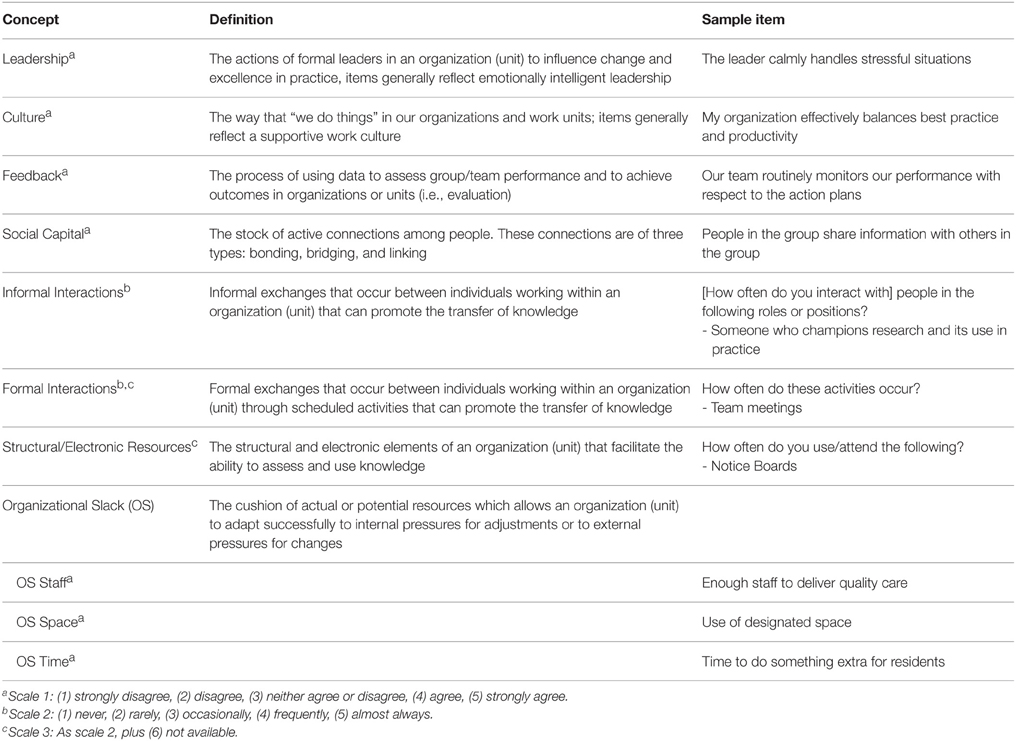
Table 1. Concepts, definitions and example items of the Canadian Alberta Context Tool Long Term Care version (Estabrooks et al., 2011b).
Estabrooks et al. (2009b) describe the development and initial validation of the Canadian ACT. Validity of instrument contents was established by the tool developers who were all content experts in the respective fields (Squires et al., 2013b). Response process validity evidence was assessed for all four ACT versions (Squires et al., 2013b). To date, eight studies providing information on the reliability and validity of the ACT have been published (Table 2). Estabrooks et al. (Estabrooks et al., 2009b) found that the pediatric acute care version was acceptably reliable, had a 13-factor structure based on principle component analyses (evidence based on internal instrument structure), and that the ACT concepts were significantly associated with instrumental research utilization (evidence based on relationships with other variables). Furthermore, the instrument developers demonstrated that the ACT scores obtained from individual participants could be validly aggregated at the unit level. This provided evidence for the correlation of individual ACT observations within hospital units. These findings could be confirmed for the ACT LTC version, based on responses from care aides (Estabrooks et al., 2011b), and for the ACT questionnaire for nurses, based on combined results of five studies conducted in LTC, acute adult and pediatric hospitals, and community/home care (Squires et al., 2015). However, the hypothesized 10-factor structure was not confirmed by the confirmatory factor analyses (CFA) (Estabrooks et al., 2011b; Squires et al., 2015). The relative fit indices of the 10-factor model and the two additional models (one including the seven scale-based concepts, and the other including the three count-based concepts) suggested best fit for the model including the seven scale-based concepts. χ2 tests of all models were significant, which the authors expected, as the ACT was not developed as a factor model. Using hierarchical linear models, the authors also demonstrated that the ACT pediatric acute care (Estabrooks et al., 2011c) and the ACT LTC (Estabrooks et al., 2011a) were able to discriminate between different care units. Most recent evidence based on multi-level models suggests that the ACT concepts are significant predictors of research utilization (Squires et al., 2013a; Estabrooks et al., 2015b) as well as resident outcomes (Estabrooks et al., 2015a; relation to other variables validity evidence).
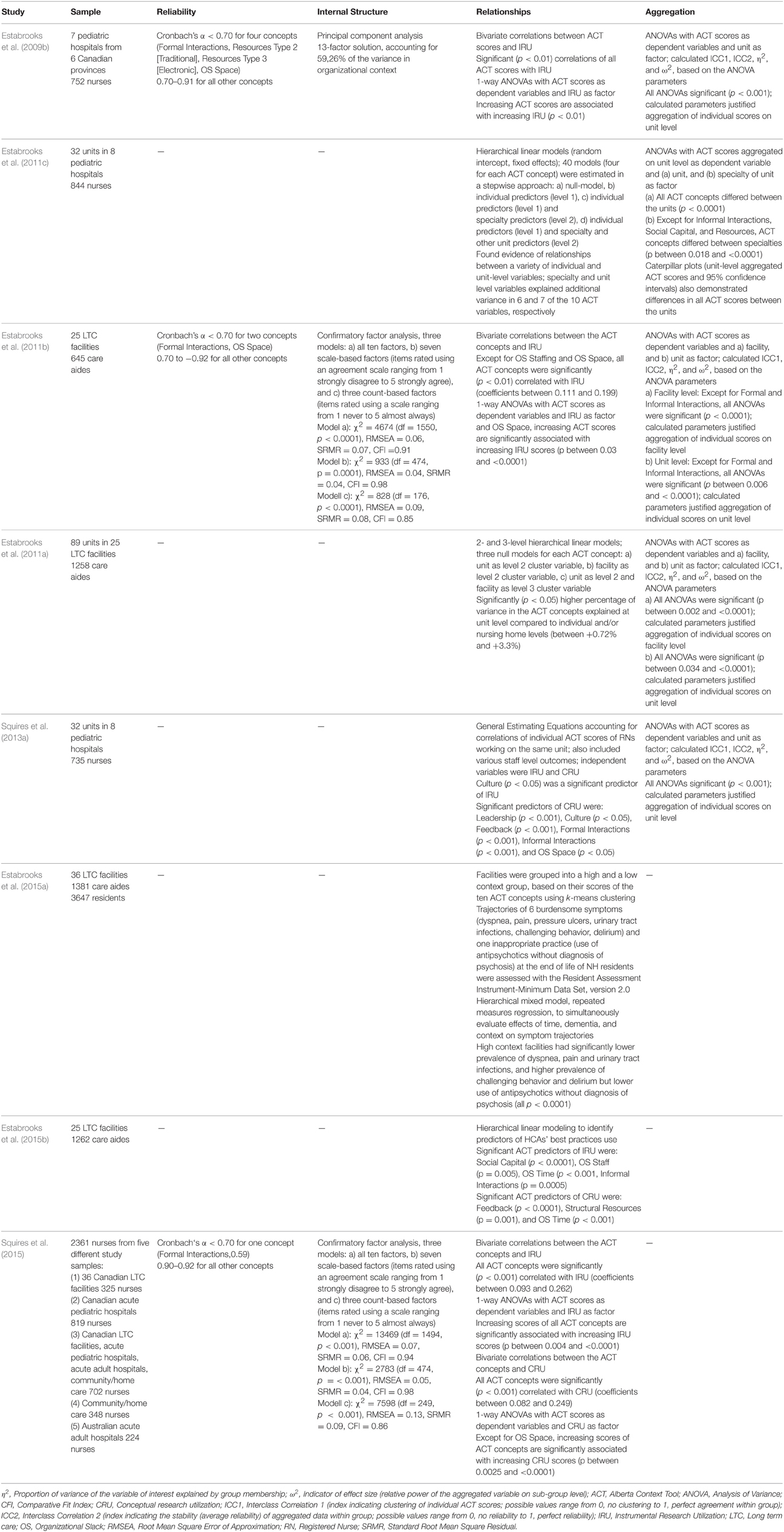
Table 2. Overview of studies examining the reliability and validity of the Alberta Context Tool.
Information is limited on the psychometric characteristics of translated ACT versions. In addition to the results of the German LTC version (Hoben et al., 2013, 2014a), only results for the Swedish LTC version (Eldh et al., 2013) have been published. The authors report internal consistency reliability (Cronbach's α) values (all >0.70 except for Culture and Informal Interactions) and some validity evidence relating to instrument content and response processes.
The Conceptual Research Utilization (CRU) Scale
Conceptual Research Utilization is defined as “the cognitive use of research where the research findings may change one's opinion or mind set about a specific practice area but not necessarily one's particular action” (Squires et al., 2011a). Among the different types of research utilization, CRU is of particular importance as it seems to occur more frequently than other types or research utilization (e.g., instrumental = direct application of research knowledge in bed-side care or symbolic = using research to justify own activities or to convince others to change their actions) and therefore “is believed to be more reflective of the process of research utilization at the individual practitioner level” (Squires et al., 2011a). Policy makers and knowledge users frequently do not use research to act upon a situation, but rather to inform their decision making (Squires et al., 2011a).
To assess CRU, researchers need a robust research tool that can be validly used with various provider groups (particularly care aides) in LTC settings. Squires et al. (2011a) developed the CRU Scale for this purpose. The five-item tool is available in two versions: one for care aides and one for regulated care providers. Participants are asked how often research had five different specific effects on their last typical day of work e.g., “Help to change your mind about how to care for residents.” Participants rate each of the five items on a scale ranging from “1 = Never” (care aides) or “10% or less of the time” (regulated providers) to “5 = Almost Always” (care aides) or “Almost 100% of the time” (regulated providers).
The psychometric properties of the CRU Scale were comprehensively assessed based on The Standards (Squires et al., 2011a). Validity of the instrument content was evaluated in a formal process with a sample of nine international research utilization experts. Response processes were studied with ten care aides from two LTC facilities. In a third sample of 707 care aides from 30 LTC facilities, the authors assessed the reliability of the CRU Scale (Cronbach's α = 0.89, Guttman Split Half = 0.86, Spearman-Brown = 0.89). The internal structure of the scale was assessed using CFA. Removal of one sub-optimal item and correlation of residual variances led to a well-fitting four-item one-factor model: χ2 = 2.43, df = 1, p = 0.119, RMSEA = 0.045, SRMR = 0.007, CFI = 0.999. For the five-item CRU version we used in this study, the tool developers had revised this sub-optimal item. Finally, the relationships between CRU and other types of research utilization were assessed using bivariate correlations (significant correlations for the CRU Scale score and all five CRU items) and multivariate linear regression (CRU Scale score was a significant predictor of overall research utilization).
The authors also assessed the precision of the CRU Scale using item response theory models (Squires et al., 2014). While the scale demonstrated acceptable precision at low and average trait levels (i.e., an individual's levels of CRU), the included items are less optimal in reflecting higher trait levels.
Sample
Facility Sample
Our study population included all 251 LTC facilities in one German region (Metropolregion Rhein-Neckar) recognized as a residential elder care facility by the German social law (XIth German social security statute book–SGB XI). These facilities were stratified by three criteria (Table 3).
1. Federal state: Baden-Württemberg, Hessia, Rhineland-Palatinate.
2. Size: small (≤ 60 beds), medium (61–120 beds), large (>120 beds).
3. Provider type: voluntary not-for-profit, public not-for-profit, private for-profit.
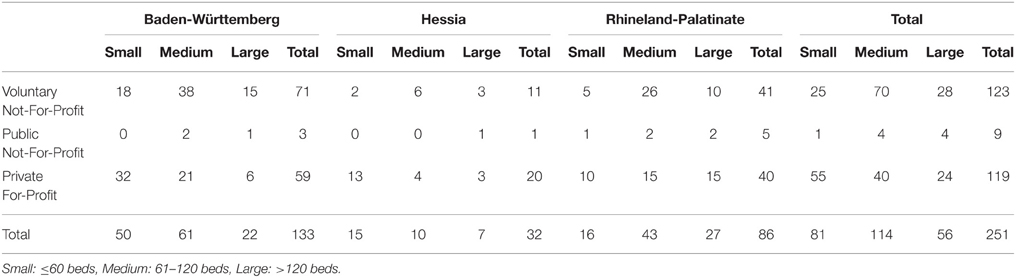
Table 3. Residential long term care facilities in the German region Metropolregion Rhein-Neckar.
An independent person not involved in other parts of this study drew a stratified random sample of 38 facilities from this pool of facilities. In each of the 27 categories (3 provider types × 3 size categories × 3 federal states) one facility was randomly selected. In each of the three federal states two additional facilities were drawn for the categories “medium, voluntary not-for-profit” and “large, voluntary not-for-profit,” because facilities of these categories are also over-represented in the overall population of German national LTC facilities (Statistisches Bundesamt, 2013). In the case of empty categories (e.g., Baden-Württemberg, small, public not-for-profit), we included facilities of a similar category (e.g., Baden-Württemberg, small, voluntary not-for-profit). If a selected facility was approached but declined to participate in our study, another facility of the same category was drawn. If, in any one federal state, all facilities in a category and in similar categories declined to participate, facilities in the same category from another federal state were contacted.
Provider Sample
Eligible participants for this study were all care providers (care aides, nurses, allied providers), nursing students (who complete the care aide survey), clinical specialists, and managers who met the inclusion criteria:
1. Employed in one of the included LTC facilities.
2. Have been working on their unit (care aides, nurses, students, care managers) or in the facility (allied providers, specialists, directors of care, facility managers) for ≥3 months (this criterion was applied in previous usage of the ACT as providers need to have sufficient time on the unit to report on the unit context).
3. Work at least 25% of the hours of a full-time job.
4. Able to read and write in German.
Voluntary workers or casual staff were not eligible.
Data Collection
At one-day data collection appointments, a researcher distributed questionnaires to all eligible persons present during the morning and evening shifts at the facility. The participants filled out the questionnaires during their work time and returned the completed questionnaires to the researcher. The researcher was available for questions and concerns at all times while participants completed the questionnaires.
Data Analysis
Missing Data, Distribution and Descriptive Statistics
We used SPSS version 20 (IBM, 2011) to analyze missing data, normal distribution of variables, and descriptive statistics. Except for an answer to item five of the CRU Scale, which was missing in 25 questionnaires (3%), answers to all ACT and CRU Scale items were missing in less than 3% of the questionnaires. According to the Missing Completely at Random (MCAR) Test (Little and Rubin, 2002) (χ2 = 12,426.806, df = 12,434, p = 0.517) missing items were distributed completely at random. This indicates that no systematic problems caused the missing answers (Graham, 2012), therefore we removed three questionnaires with >25% of data missing (one each of the care aide, nurse, and allied questionnaires). Missing data were not imputed, but deleted listwise in the analyses.
Our analyses indicated that none of the variables were distributed normally. Skewedness and kurtosis values were substantially different from zero, and their values were clearly more than twice the values of their corresponding standard errors (Miles and Shevlin, 2001). The Kolmogorov-Smirnov Test (Kolmogorov, 1933; Smirnov, 1948) and the Shapiro-Wilk Test (Shapiro and Wilk, 1965) supported those findings; the distribution of all ACT and CRU Scale variables was significantly different from normal (p < 0.0001). However, descriptive analyses indicated no extreme outliers (> 3 × interquartile range).
Factor Structure and Measurement Invariance
We assessed the internal structures of the ACT and the CRU Scale, using CFA. We tested whether the factor structure of the translated tool was the same as the factor structure proposed for the Canadian versions. Further, we assessed the measurement invariance of the translated tools across the different provider groups, using multiple-group CFA models. Measurement invariance analyses evaluate if the constructs of a tool are measured equally well in different groups or if their measurement differs substantially (Byrne et al., 1989; Brown, 2006; Dimitrov, 2010; Sass, 2011; Wang and Wang, 2012). We could not run factor models in the specialist sub-sample, as this sample only included six participants. However, we included the responses of the six specialists in the models of the entire sample. We used Mplus Version 7.11 (Muthén and Muthén, 2013) for these analyses. Due to the non-normality of our data we used a robust mean- and variance-adjusted maximum likelihood estimator (MLMV) (Asparouhov and Muthén, 2010). Unless reported otherwise, we fixed the first item loading of each factor to 1.0 in all models to identify the models (default setting in Mplus) (Muthén and Muthén, 2012).
The items related to each ACT concept are explicitly developed to be non-redundant, although they capture similar aspects of that context feature (Estabrooks et al., 2011b). With these similarities of items, the factor structure is still the most appropriate of the available model structures, even if it is not a 100% perfectly specified model (Estabrooks et al., 2011b). Model fit evaluation followed well-established recommendations (Brown, 2006; Raykov and Marcoulides, 2006; Kline, 2011a; Wang and Wang, 2012; West et al., 2012). We report the χ2 test, as this is the only statistical test available to determine the consistency between the model-implied covariance matrix (from the CFA model) and the sample covariance matrix (from our data); a non-significant χ2 value (p>0.05) implies no detectable ill fit (Hayduk, 1996; Hayduk and Glaser, 2000; Hayduk et al., 2007). We also report common “close-fit” indices: (a) Root Mean Square Error of Approximation (RMSEA), (b) Comparative Fit Index (CFI), (c) Tucker Lewis Index (TLI), and d) Standardized Root Mean Square Residual (SRMR). These are independent of the sample size. Our interpretation of these indices followed the recommendations of Hu and Bentler (Hu and Bentler, 1999) who suggested cut-off values for each index based on simulation studies: RMSEA < 0.06, CFI and TLI > 0.95, and SRMR < 0.08. In addition to this global evaluation of model fit, we also investigated models for local areas of strain. We evaluated the estimated model parameters (e.g., statistical significance, expected size and direction of loadings, intercepts, residual variances), and the modification indices (e.g., evidence of misspecifications and suggestions for model modifications; Brown, 2006; Raykov and Marcoulides, 2006; Kline, 2011a; Wang and Wang, 2012; West et al., 2012). In assessing measurement invariance, we followed the steps outlined in Figure 1 (Byrne et al., 1989; Brown, 2006; Dimitrov, 2010; Sass, 2011; Wang and Wang, 2012).
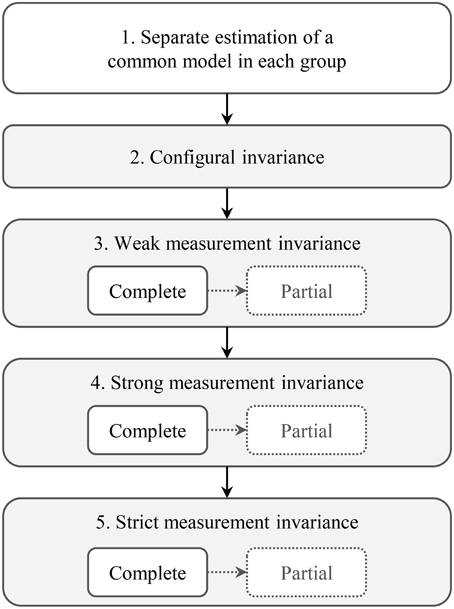
Figure 1. Steps of the measurement invariance analysis.
Step 1: Separate estimation of a common model in each group
Our first step was to find a model that properly fit each of the different participant groups. We therefore ran all models separately on each of the sub-samples (care aide, nurse, allied providers, managers, students) and on the entire sample. In our analyses we included only items that are available in all questionnaire versions, as comparable models with the same structure are required to run multiple-group CFA. Therefore, we removed the eight group-specific items (Organizational Slack [OS] Staffing, item 3; Formal Interactions, items 3 and 4; Informal Interactions, items 3, 7-9, and 12). The first model (Figure 2, model 1) included all ten ACT concepts. We also decided a priori to run two separate models for the scale-based and the count-based ACT concepts (Figure 2, models 2a, 3a) as suggested by Estabrooks et al. (2011b). We allowed residual variances of items of the same concept to correlate in specific sub-samples if (a) suggested by the modification indices and (b) item contents and experiences during the instrument translation and pretesting or during the data collection of this study justified this. For rationales in correlating residual variances see Supplementary Table 1.
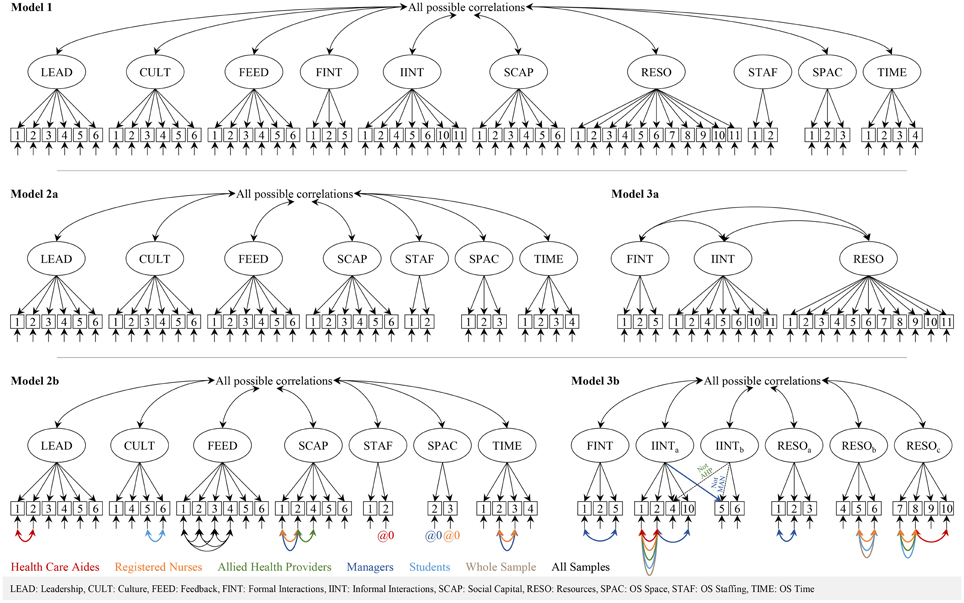
Figure 2. Alberta Context Tool factor models.
We ran a one-factor model of the CRU Scale (Figure 3, model 4) as suggested in the validation study of the original Canadian tool (Squires et al., 2011a).
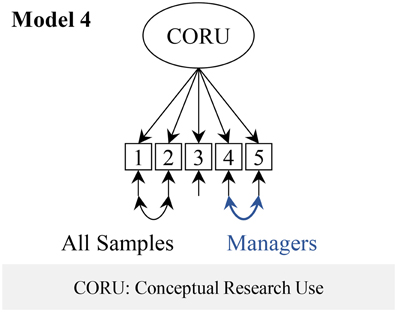
Figure 3. Conceptual Research Utilization Scale factor models.
Step 2: Configural invariance
We estimated each of the three models (2b, 3b, and 4) simultaneously in all five provider group sub-samples. All model parameters were freely estimated in each group.
Step 3: Weak measurement invariance
In this step we assessed if the associations (loadings) between the latent factors and the related indicators (items) were the same across the provider groups. We restrained the loadings to be equal across the five provider groups, with all other model specifications remaining the same as in the previous model (configural invariance). If the item loadings are the same across the groups, a change in the latent construct (e.g., the ACT factor TIME) by one unit changes the value of the related items (e.g., the ACT Time item “How often do you have time to do something extra for residents?”) equally strongly and in the same direction in all five groups. Weak measurement invariance allows group comparisons of associations between latent factors and external variables, and of factor variances and covariances (Byrne et al., 1989; Brown, 2006; Dimitrov, 2010; Sass, 2011; Wang and Wang, 2012). However, structural coefficients of the model and factor means cannot be compared (Byrne et al., 1989; Brown, 2006; Dimitrov, 2010; Sass, 2011; Wang and Wang, 2012). Equal loadings indicate a common scale across the groups, but we do not know if the starting point of this scale is the same in all groups.
Weak measurement invariance was noted if the fit of the restrained model (equal loadings) was not significantly worse than the fit of the previous (configural invariance) model. We assessed this using the χ2 difference test (p value expected to be >0.05). The MLMV estimator in Mplus uses the DIFFTEST function for this, which produces a corrected χ2 difference test (Muthén and Muthén, 2012). If weak measurement invariance was established for a latent factor, we continued with step 4. Otherwise we freed individual loadings sequentially, starting with the loading with the highest modification index value. If less than 20% of the loadings in the model needed to be freed to gain a non-significant χ2 difference test, partial weak measurement invariance was accepted (Byrne et al., 1989; Vandenberg and Lance, 2000; Dimitrov, 2010) and we continued with step 4. Otherwise we stopped the procedure here.
Step 4: Strong measurement invariance
Based on the previous model (equal loadings except for the freed ones) we now restrained the item intercepts to be equal across the groups. An item intercept can be interpreted as the predicted item value if the score of the latent construct is zero (Brown, 2006). If the item intercepts differ across the groups, groups with the same value of the latent construct (e.g., the ACT factor TIME) on average give different answers to the related items (e.g., the ACT Time items). This is called item bias or differential item functioning (Byrne et al., 1989; Brown, 2006; Dimitrov, 2010; Sass, 2011; Wang and Wang, 2012). If a tool is strongly measurement invariant, factor means and structural coefficients of the model can be compared across groups. Again, this model was compared to the previous model (weak measurement invariance). If strong measurement invariance was established we continued with step 5, otherwise we freed intercepts sequentially according to the previously described procedure. If partial strong measurement invariance could not be established we stopped our procedure here.
Step 5: Strict measurement invariance
Based on the (partial) strong measurement invariance model we now restrained the residual variances to be equal across the groups. We then freed residual variances again until strict or partial strict measurement invariance was established or had to be rejected. If residual variances differ across the participant groups, this means that the constructs are measured with different precision (contain different amounts of measurement error) in the different groups. Group differences, therefore, are not only caused by differing “true scores” (i.e., the latent factor scores), but also by differing errors. To compare values of observed variables or scores derived from these values across groups, strict measurement invariance is required (Dimitrov, 2010; Sass, 2011).
Reliability
Cronbach's α (internal consistency reliability) is the most commonly reported index to assess reliability, although numerous publications discuss various problems with this index (see Green and Yang, 2009; Sijtsma, 2009; Yang and Green, 2011 for an overview). In particular, two assumptions required for valid results of Cronbach's α are rarely met in practice: (a) essential tau equivalence (all items of a scale have the same loadings on the corresponding factor), and (b) uncorrelated residual variances. If those requirements are not met, Cronbach's α values will be biased. Therefore, the internal consistency reliability of a scale should be assessed using a more robust method based on latent variable models (Green and Hershberger, 2000; Raykov and Shrout, 2002; Green and Yang, 2009; Yang and Green, 2011). As Cronbach's α is a popular index and for comparability reasons, we also report Cronbach's α. however, we are relying on a more robust reliability index (ω in the following). According to this approach, reliability is the ratio of the true score variance (σtrue) and the total variance (σtot.) of a scale. Total variance of a scale (σtot) is the sum of σtrue and the residual variance σres. of the scale. From this it follows that ω = σtrue/(σtrue + σres.). As each ACT concept represents a distinct construct, we calculated a separate reliability score for each. Therefore, σtrue is the squared sum of the loadings of the respective factor and σres. is the sum of the residual variances of the corresponding items. For the reliability calculations we used the individual factor models (2b, 3b, and 4). As we needed to estimate all loadings in these models, we freed the first loading of each factor (previously fixed to 1), and instead fixed the factor variances to zero in order to obtain an identified model.
Ethics Approval
The study was approved in writing by the ethics board of the Medical Faculty, Martin-Luther University Halle-Wittenberg, Halle (Saale), Germany (reference number: 2011-39). All participants completed written informed consent before participation.
Results
Sample
We contacted 133 facilities and 41 agreed to participate, but three canceled their participation before start of data collection due a shortage of staff. Our participation rate was therefore 28.6% of facilities contacted. Reasons given by facilities for not participating were: (a) other projects (e.g., implementation of new care documentation software or participation in other research projects; n = 37), (b) staff shortage (n = 27), (c) no senior person available to make this decision (e.g., due to a change of leadership; n = 11), (d) staff surveys unwelcome (n = 6), (e) no reasons stated (n = 5), (f) refusal by works council or staff (n = 3), team problems (n = 2), and (h) bad experiences with previous research projects (n = 1).
Overall, we retrieved 824 questionnaires from six different provider groups (Table 4). This is a response rate of 37.7% for all potentially eligible persons employed in the 38 participating facilities (response rate 1). However, we could not approach all these potentially eligible persons during our data collection appointments. Based on the number of eligible persons available during our data collection appointments, our response rate was 81.5% (response rate 2).
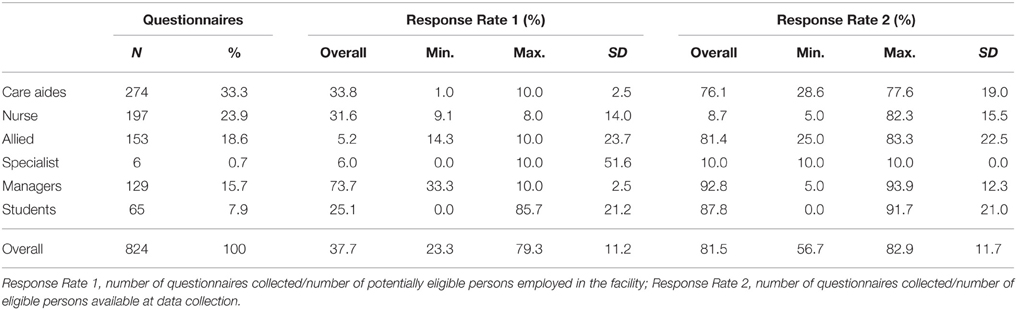
Table 4. Response rates overall and by provider groups.
Three questionnaires were excluded due to extensive missingness as described in the methods section, leaving us with 821 questionnaires. Table 5 displays the socio-demographic characteristics of the participants. The characteristics of sex, age, native language, percentage of a full-time job, and general education differed significantly (p < 0.0001) between the provider groups. Job training is specific to each group, thus not analyzed across groups. All care aides, nurses, care managers, and nursing students were assigned to a certain unit in their facility, and all specialists and other managers were working across the entire facility, except in the allied group. Of the 152 allied providers, 101 were working across various units in their facility and 51 were permanently assigned to one unit.
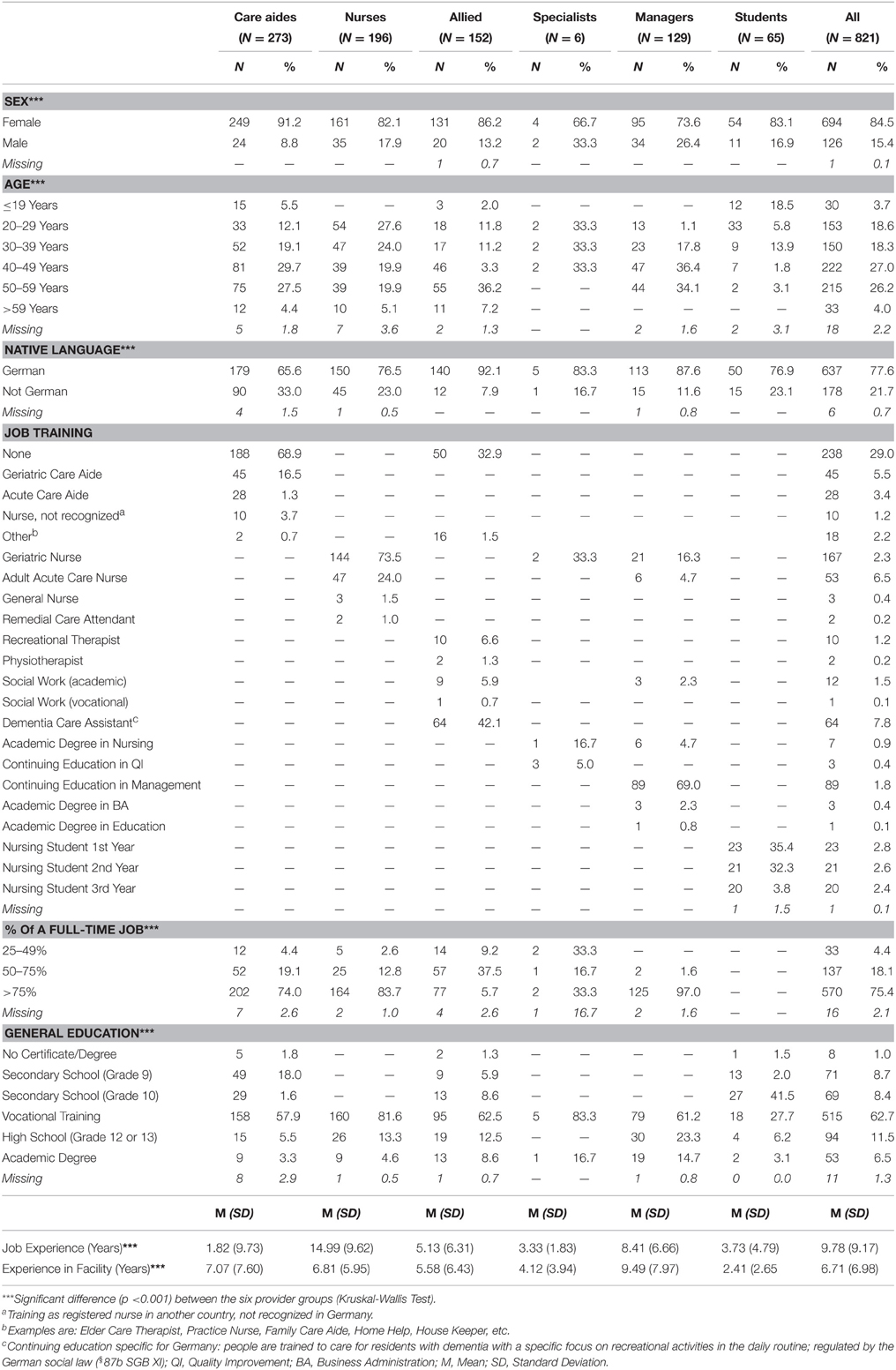
Table 5. Socio-demographic characteristics of the included participants.
The characteristics of the participating facilities are illustrated in Table 6. The absolute numbers of care aides, nurses, care managers, facility level managers, and nursing students differed substantially between small, medium, and large facilities. However, these differences became smaller when taking into account the amount of work time (i.e., care minutes for each provider group per resident day). Only the nurses and the facility level managers differed significantly in staffing minutes per resident day between facilities of different size. Between facilities of different federal states only nursing care minutes per resident day differed significantly (p < 0.05), and facilities of different provider types did not differ in any of the provider group characteristics.
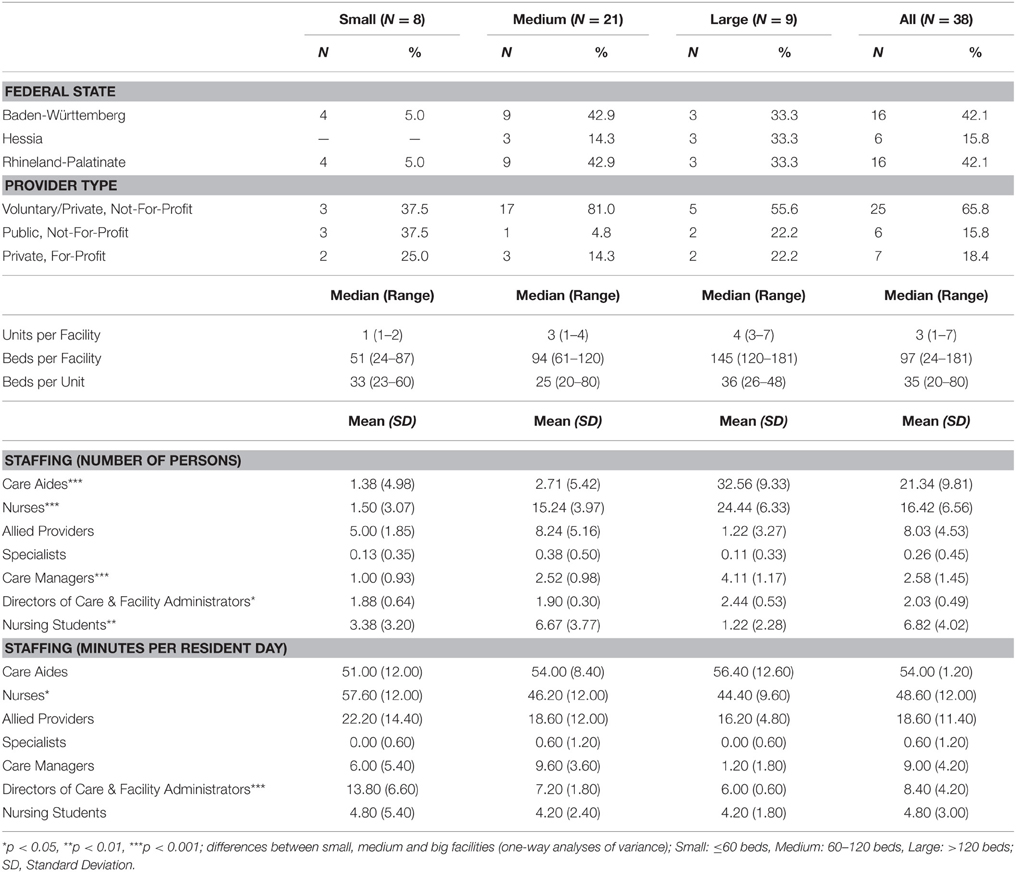
Table 6. Characteristics of the participating facilities.
Factor Structure and Reliability
Factor Structure of the Alberta Context Tool
Table 7 shows the model fit indices of all factor models. Fit of the ACT model 1 (ten factors) was poor and could not be estimated in the student sub-sample. While fit of the ACT model 2a (seven scale based concepts) improved substantially compared to model 1, it was still not acceptable. Fit of ACT model 3a (three count-based concepts) decreased compared to model 1.
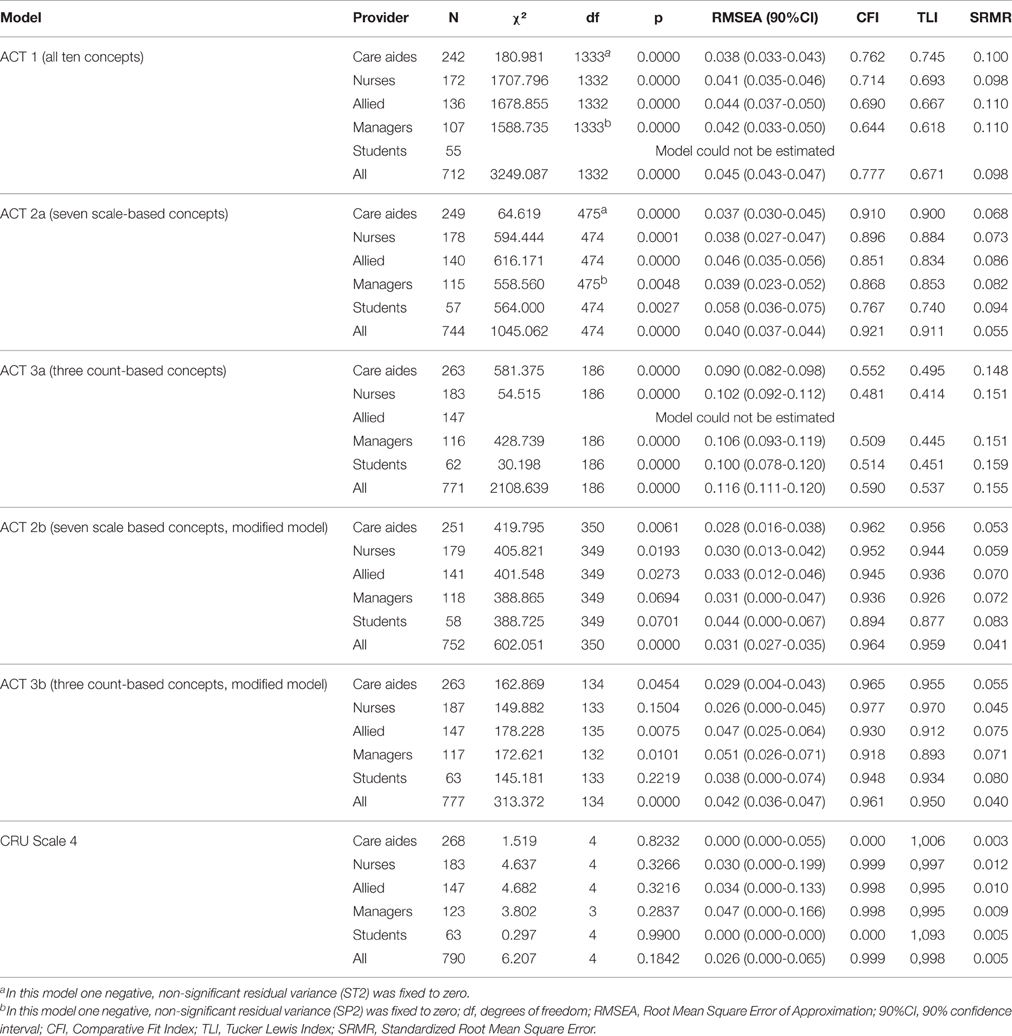
Table 7. Model fit indices of the ACT and CRU Scale factor models.
Fit improved substantially with ACT model 2a but inspection still revealed four items substantially contributing to poor model fit: Culture items 2 (member of a supportive work group) and 3 (organization effectively balances best practice and productivity), Social Capital item 3 (other teams share information with my team) and Space item 1 (private space available on this unit or floor). In most or all groups, these items also had substantially smaller loadings than the other items of the same concept (Tables 8–10), or high modification indices (indicating, for example, cross-loadings on other than the expected factors. We further fixed three negative, not statistically significant residual variances to zero; and correlated some residual variances. Except for the student sub-sample, model fit indices were around the recommended thresholds.
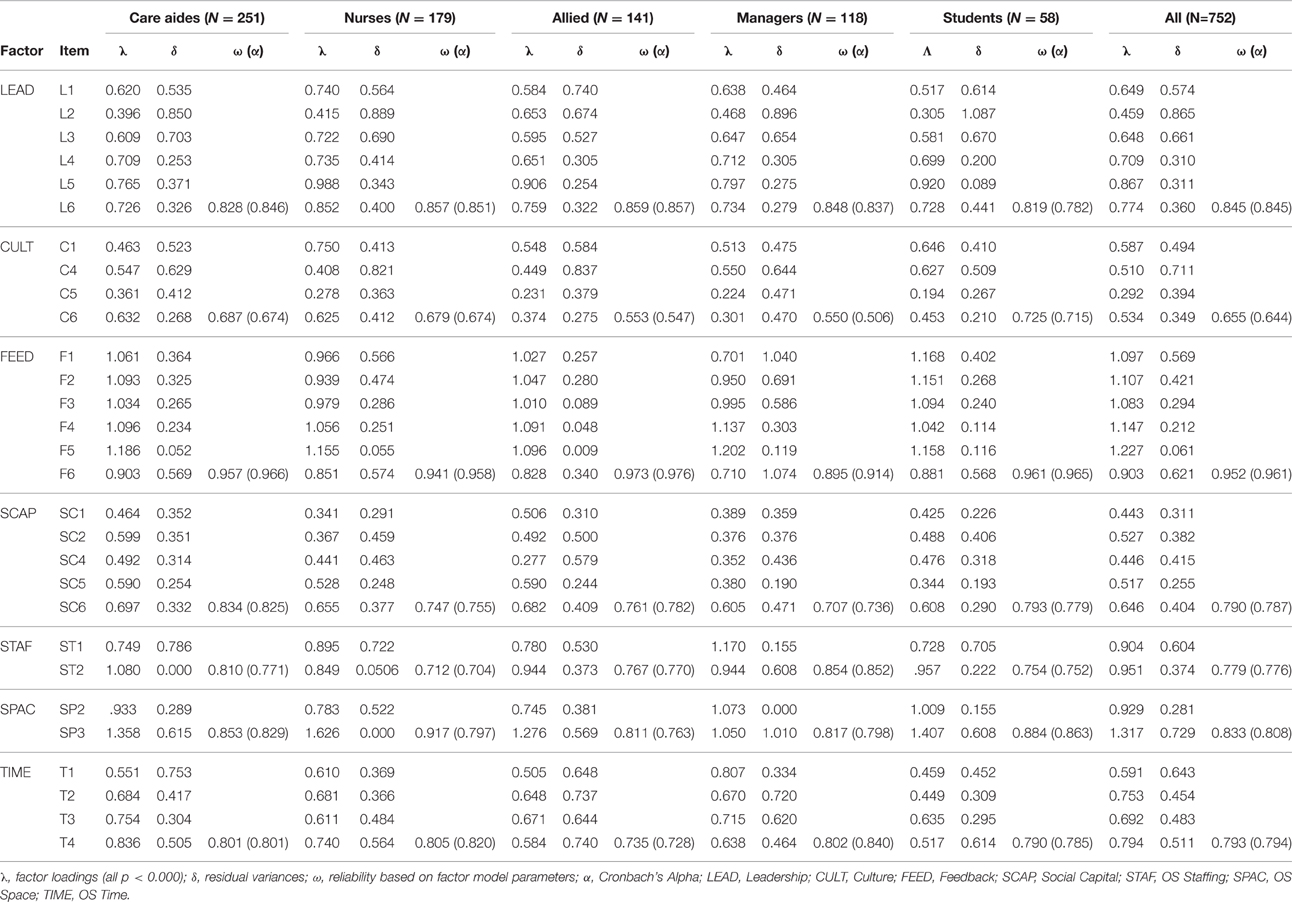
Table 8. Loadings, residual variances, and reliability of the scale-based Alberta Context Tool sub-scales.
Fit of ACT model 3a (three count-based concepts) was poor. This model could not be estimated in the allied group. Our analysis of the model and the item contents indicated that the factors Informal Interactions and Resources should be split into two and three factors, respectively. In this model we also removed two ill-fitting items (Informal Interactions item 11, informal bedside teaching sessions, and resources item 11, in-services in your facility) and correlated residual variances (see Figure 2, model 3b). In addition, we allowed cross-loading of one item. Except for the allied and managers sub-sample, model fit indices were around the recommended thresholds.
A 13-factor model (combination of models 2b and 3b) fit poorly and could not be estimated reliably in the sub-samples of managers and student due to a non-positive first-order derivative product matrix.
Factor Structure of the Conceptual Research Utilization Scale
Fit of the CRU Scale model (Figure 2, model 4) was excellent. In this model we allowed the residual variances of items 1 and 2 to correlate in all groups and the residual variances of items 4 and 5 in the managers group.
Reliability
Using the item loadings and residual variances of these final models (2b, 3b, and 4), we calculated the reliability (ω) of each ACT sub-scale and the CRU Scale (Tables 8–10). Except for Culture, all scale-based ACT concepts were acceptably reliable (ω > 0.7) in all provider groups (Table 8). The same is true for the count-based ACT concepts of Informal Interactions with direct care providers (IINTa), Reading Resources (RESOa), and Electronic Resources (RESOc) (Table 9). Reliability of instructive/informative resources (RESOb) only falls below.7 in the student group. Less reliable ACT concepts are Formal Interactions (FINT; ω > 0.7 only in the nurses group and in the entire sample), and Informal Interactions with indirect care providers (IINTb; ω > 0.7 only in the student group). Reliability of the CRU Scale is excellent in all groups (Table 10).
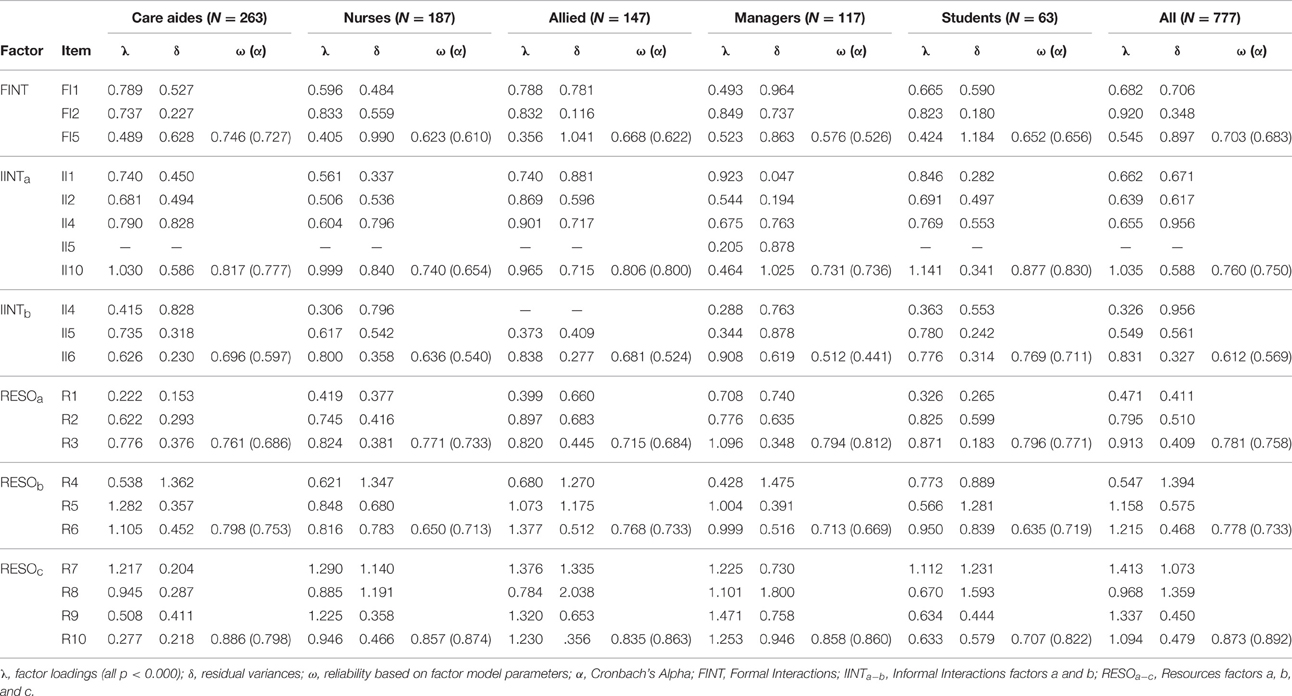
Table 9. Loadings, residual variances, and reliability of the count-based Alberta Context Tool sub-scales.

Table 10. Loadings, residual variances, and reliability of the CRU Scale.
Measurement Invariance
Results of the measurement invariance analyses are summarized in Table 11. The ACT scale-based model (2b) demonstrated partial weak measurement invariance after we freed three (2.1%) of the 145 fixed loadings (29 in each of the five provider group models). After freeing eight (5.5%) of the 145 item intercepts this model also demonstrated partial strong measurement invariance. However, we found neither strict nor partially strict measurement invariance for this model.
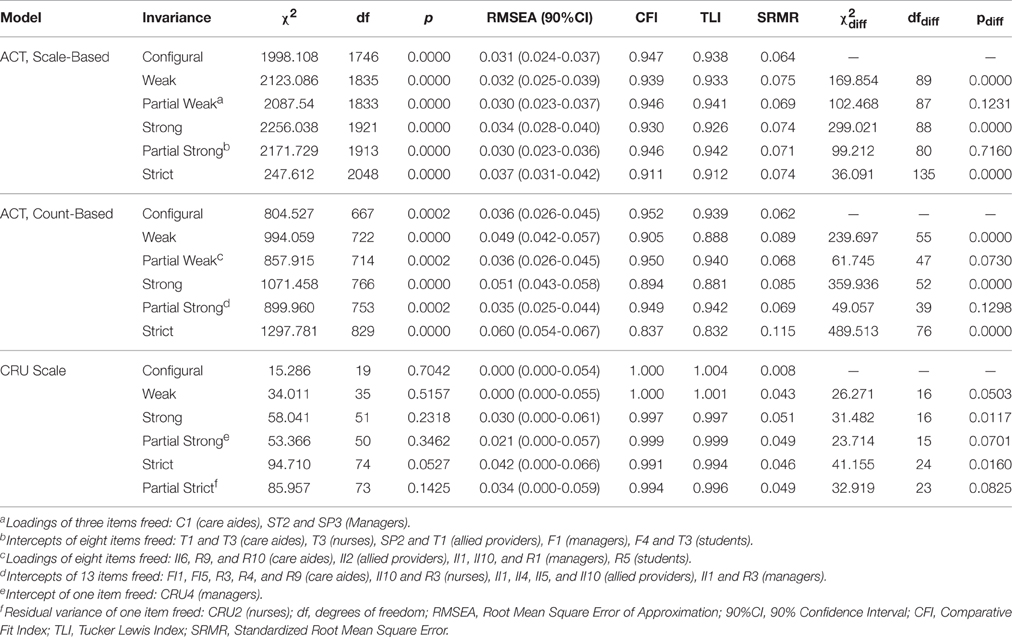
Table 11. Results of the measurement invariance analyses.
The count-based ACT model (3b) also demonstrated partial weak measurement invariance after we freed eight (8.2%) of the 98 fixed loadings. Partial strong measurement invariance was met after we freed 13 (13.7%) of the 95 fixed item intercepts. As for the model of the ACT scale-based items (2b), we were not able to obtain strict or partially strict measurement invariance for this model.
The CRU Scale proved to be fully weak invariant as well as partially strong invariant (only one [4%] of the 25 fixed item intercepts was freed). Additionally, after freeing one (4%) of the fixed residual variances, this Scale showed partial strict measurement invariance.
Discussion
Mounting evidence links organizational context in health care to care provider outcomes of quality of work life, attitudes toward research utilization, and use of best practice, and to patient outcomes of safety and quality of care (Glisson, 2002; Greenhalgh et al., 2004; Meijers et al., 2006; Kaplan et al., 2010; Aarons et al., 2012; Grabowski et al., 2014; Harvey et al., 2015). However, we lack robust quantitative studies that use sound theory and validated research tools to assess and better understand organizational context factors and how they affect these outcomes (Kaplan et al., 2010; Flodgren et al., 2012). This is particularly true in the LTC sector (Boström et al., 2012). Robust research tools are a prerequisite for such studies (Graham et al., 2010; Proctor et al., 2011; Proctor and Brownson, 2012), but only a few robust tools are available to assess organizational context and research utilization in LTC settings (Squires et al., 2011b; Chaudoir et al., 2013).
The German versions of the ACT and the CRU Scale are to date the only tools available to assess modifiable factors of organizational context and the extent of conceptual research utilization in German LTC facilities. Applying The Standards, we generated evidence for the validity of scores derived from these tools based on feedback from content experts and the tool developers (instrument content evidence; Hoben et al., 2013), and based on responses from target persons (response process evidence; Hoben et al., 2014a). This paper presents the assessment of the third source of validity evidence: the internal structure of the instruments. We demonstrated that both the scale-based ACT concepts and the CRU Scale reflect the hypothesized seven- and one-factor structure, respectively. This corresponds with the findings of the Canadian validation studies (Estabrooks et al., 2011b; Squires et al., 2011a, 2015). The finding of an ill-fitting three-factor model of the count-based ACT concepts also is in agreement with the Canadian results (Estabrooks et al., 2011b; Squires et al., 2015).
We removed four items from the scale-based ACT model, which negatively influenced the model fit. care aides in particular frequently asked for the meaning of the Culture item 2 (are you a member of a supportive work group) during data collection. Culture item 3 (organization effectively balances best practice and productivity; Hoben et al., 2014a). Social Capital item 3 does not focus on the unit level (asks for the exchange with other teams in the facility), and therefore clearly differs from the five other Social Capital items. Space item 1 (private space available on this unit or floor) was also removed in the analysis of the Canadian tool (Estabrooks et al., 2011b), and in the German study participants frequently struggled with the meaning of this item.
In the count-based ACT model, we also removed two items. Informal bedside teaching sessions (Informal Interactions item 11) are not very common in German nursing homes. In contrast, in-services (Resources item 11) are very common. Almost all continuing education happens inside the facilities, and care providers rarely are sent to trainings outside their facility. In both cases, the result is almost no variance in the item responses.
In contrast to the Canadian validation studies (Estabrooks et al., 2011b; Squires et al., 2015), we not only assessed the factor structure of the ACT care aides version (separate models for care aides and nursing students) and nurses, but also of the allied and manager versions. In order to compare the factor models, we not only excluded items contributing to model ill-fit, but also items not included in all ACT versions. Furthermore, we decided to split up the Informal Interactions factor and the Resources factor in two, and three factors, respectively. Informal interactions take place with persons providing direct care to residents (care aides, nurses, allied providers) and, with indirect care providers (e.g., quality improvement specialists, clinical educators), reflecting two somewhat distinct concepts. The allied group includes both direct care providers (e.g., recreational therapists) and indirect care providers (e.g., the social service leader). Therefore, the item referring to interactions with allied providers is associated with both Informal Interaction factors in all groups except the allied group itself. Resources items refer to three types of resources: reading resources (e.g., a library, text books, journals), instructive/informative resources (e.g., notice boards, policies/procedures, clinical practice guidelines), and electronic resources (e.g., computer connected to the internet, software assisting with care and decision making, electronic reminders, websites on the internet). This reflects the factor structure of the count-based ACT concepts that was found by Estabrooks et al. (Estabrooks et al., 2009b) using a principal component analysis.
Our factor models did not fit perfectly. χ2 tests of most models were statistically significant. Relevance of the χ2 test in relation to relative model fit indices for model fit evaluation has been debated at length. The most radical position is to ban relative model fit indices completely (Barrett, 2007) and to only accept p values of χ2 tests that are above. 75 (Hayduk, 1996; Hayduk and Glaser, 2000; Hayduk et al., 2007). The χ2 test is the only available statistical test for the null hypothesis that the sample covariance matrix (data collected) matches the model-implied covariance matrix. Its p value is the probability of observing the sample covariance matrix if the model-implied covariance matrix reflected the true population values (Hayduk, 1996; Hayduk and Glaser, 2000; Hayduk et al., 2007). However, the ACT items do not reflect truly redundant indicators of the concepts under which they are subsumed, therefore we did not expect that our factor models would be perfectly well-specified. We assessed model fit using recognized relative fit indices and looking for local areas of strain. When meeting these criteria, even a model with a significant χ2 value can be accepted as a reasonably close approximation to reality (Bentler, 2000; Millsap, 2007; Mulaik, 2007).
This paper adds two unique insights to the literature on the validity of the two tools: information on measurement invariance across provider groups and reliability based on latent variable model parameters. The ACT models showed partial strong measurement invariance (>80% of the loadings and intercepts restricted to be equal across the groups), indicating that the constructs to be measured (Leadership, Culture, Feedback, etc.) are the same in all groups and are measured equally across groups (Byrne et al., 1989; Brown, 2006; Dimitrov, 2010; Sass, 2011; Wang and Wang, 2012). The CRU Scale showed partial strict measurement invariance (>80% of the residual variances restricted to be equal across groups). This means, that not only the construct is the same across groups and is measured equally across groups, but that the amount of unexplained variance (including measurement error) also is equal across groups. It is not surprising that the ACT models were not strictly measurement invariant. The provider groups differ substantially in various characteristics (age, language skills, qualification, job experience, education), influencing their ability to understand the questionnaire instructions and items. Therefore, we expected the residual variances to differ substantially between provider groups. These results indicate that comparisons between the provider groups should not be based on the observed items or item scores, but rather on models accounting for the different residual variances (latent variable models; Byrne et al., 1989; Brown, 2006; Dimitrov, 2010; Sass, 2011; Wang and Wang, 2012).
Limitations
Although we reached an appropriate sample size (821 responses from 38 facilities) and although we applied a strong sampling method (stratified random sampling), some sampling limitations must be noted. Many facilities refused to participate in the study, mainly due to staffing problems. Therefore, the included facilities likely represent a selection of facilities with more favorable organizational context. We assume that facilities agreeing to participate were motivated, rated themselves as well organized, and felt they had sufficient resources to participate.
The optimal methods to determine the required sample size for CFA are model-based methods, such as the procedure described by Satorra and Saris (1985), and the approach of Muthén and Muthén (2002) based on Monte Carlo simulations. However, they require information on model parameters based on previous studies, information that was not available. Our overall sample size exceeded requirements based on common rules of thumb discussed in the literature, such as a minimum sample size of 100–200 cases, 5–10 cases per observed variable, or 5–10 cases per parameter to be estimated in the model (Brown, 2006; Kline, 2011b; Lee et al., 2012; Wang and Wang, 2012; Hancock and Mueller, 2013). However, our student and manager sub-samples were rather small (n = 65 and n = 129, respectively), given the relatively complex ACT factor models. Further studies could determine sample size requirements more precisely by using parameter estimates and effect sizes from this study to inform model-based approaches.
Post-hoc modification of latent variable models based solely on modification indices is problematic, as with each modification the covariance residuals become more and more biased, their distribution does not correspond to a χ2 distribution any longer, and the risk of type I error (accepting a failing model) increases (capitalization by chance) (MacCallum, 1986; MacCallum et al., 1992). As recommended by Silvia and MacCallum (Silvia and MacCallum, 1988) we therefore based our model modifications not primarily on the modification indices but rather on theory (item contents, experiences during data collection, discussions with instrument developers, and logic). However, in this study we were not able to test our final models in an independent sample, as our sample size was not large enough to randomly split the sample in two halves. Future studies should therefore further test these models in independent samples.
Conclusions
The scores of the German versions of the ACT and the CRU Scale are sufficiently reliable and valid. Building on two previous publications providing validity evidence based on instrument contents and response processes, this study provides validity evidence based on the internal structure of the tools. The ACT items reflect seven scale-based concepts and six count-based concepts of organizational context. The CRU Scale items reflect one common factor. These findings supplement the results of the Canadian validation studies, indicating that robust translation and adaptation methods can retain the good psychometric properties of original tools. This study extends the international findings on the psychometric properties of the ACT and the CRU Scale by adding information on their measurement invariance across different provider groups. Partial strong measurement invariance (ACT) and partial strict measurement invariance (CRU Scale) indicate that the concepts are measured equally well across the different provider groups. However, as the ACT lacked strict measurement invariance, observed variables (or scale scores based on observed variables) cannot be compared between provider groups. Instead, group comparisons should be based on latent variable models, which take into account the different residual variances of each group. The two translated tools will facilitate robust research on organizational context factors and their association with research utilization in German LTC facilities – an important prerequisite to improving quality of care and quality of life of LTC residents.
Author Contributions
MH conducted the data collections, statistical analyses, and prepared figures, tables and a first draft of this manuscript. CE and JS are the developers of the Alberta Context Tool and the Research Utilization Scale. They gave methodological input, reviewed the analyses and drafts, and critically reviewed and revised the manuscript. JB was MH's primary PhD supervisor and critically reviewed and revised the manuscript.
Funding
MH conducted this study as part of his PhD work. MH was member of an interdisciplinary Graduate Program on Dementia, located at the Network Aging Research (NAR), University of Heidelberg, Germany, and received a Doctoral Fellowship funded by the Robert Bosch Foundation, Stuttgart, Germany. The funder had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank the NAR for providing infra-structure and support. Particularly we want to express our gratitude to Dr. Konrad T. Beyreuther, the director of the NAR, for his valuable contribution to this project. Finally, we want to thank the care providers who participated in this study and the participating facilities for all their support.
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fpsyg.2016.01339
References
Aarons, G. A., Glisson, C., Green, P. D., Hoagwood, K., Kelleher, K. J., and Landsverk, J. A. (2012). The organizational social context of mental health services and clinician attitudes toward evidence-based practice: a United States national study. Implement. Sci. 7:56. doi: 10.1186/1748-5908-7-56
Asparouhov, T., and Muthén, B. (2010). Simple Second Order Chi-Square Correction: Technical Appendix Related to New Features in Mplus Version 6. Los Angeles, CA: Muthén & Muthén.
Balzer, K., Butz, S., Bentzel, J., Boulkhemair, D., and Lühmann, D. (2013). Beschreibung und Bewertung der fachärztlichen Versorgung von Pflegeheimbewohnern in Deutschland. Köln: Deutsches Institut fMedizinische Dokumentation und Information (DIMDI).
Barrett, P. (2007). Structural equation modelling: adjudging model fit. Pers. Individ. Dif. 42, 815–824. doi: 10.1016/j.paid.2006.09.018
Bentler, P. M. (2000). Rites, wrongs, and gold in model testing. Struct. Eq. Model. 7, 82–91. doi: 10.1207/S15328007SEM0701_04
Boström, A.-M., Slaughter, S. E., Chojecki, D., and Estabrooks, C. A. (2012). What do we know about knowledge translation in the care of older adults? A scoping review. J. Am. Med. Dir. Assoc. 13, 210–219. doi: 10.1016/j.jamda.2010.12.004
Byrne, B. M., Shavelson, R. J., and Muthén, B. (1989). Testing for the equivalence of factor covariance and mean structures: the issue of partial measurement invariance. Psychol. Bull. 105, 456–466. doi: 10.1037/0033-2909.105.3.456
Chaudoir, S. R., Dugan, A. G., and Barr, C. H. (2013). Measuring factors affecting implementation of health innovations: a systematic review of structural, organizational, provider, patient, and innovation level measures. Implement. Sci. 8:22. doi: 10.1186/1748-5908-8-22
Dimitrov, D. M. (2010). Testing for factorial invariance in the context of construct validation. Meas. Eval. Couns. Dev. 43, 121–149. doi: 10.1177/0748175610373459
Dopson, S., and Fitzgerald, L. (2005). Knowledge to action? Evidence-based health care in context. New York, NY: Oxford University Press.
Eldh, A. C., Ehrenberg, A., Squires, J. E., Estabrooks, C. A., and Wallin, L. (2013). Translating and testing the Alberta context tool for use among nurses in Swedish elder care. BMC Health Serv. Res. 13:68. doi: 10.1186/1472-6963-13-68
Estabrooks, C. A., Hoben, M., Poss, J. W., Chamberlain, S. A., Thompson, G. N., Silvius, J. L., et al. (2015a). Dying in a nursing home: Treatable symptom burden and its link to modifiable features of work context. J. Am. Med. Dir. Assoc. 16, 515–520. doi: 10.1016/j.jamda.2015.02.007
Estabrooks, C. A., Hutchinson, A. M., Squires, J. E., Birdsell, J., Cummings, G. G., Degner, L., et al. (2009a). Translating research in elder care: an introduction to a study protocol series. Implement. Sci. 4, 51. doi: 10.1186/1748-5908-4-51
Estabrooks, C. A., Morgan, D. G., Squires, J. E., Boström, A. M., Slaughter, S. E., Cummings, G. G., et al. (2011a). The care unit in nursing home research: evidence in support of a definition. BMC Med. Res. Methodol. 11:46. doi: 10.1186/1471-2288-11-46
Estabrooks, C. A., Niehaus, L., Doiron, J., Squires, J. E., Cummings, G. G., and Norton, P. G. (2012). Translating Research in Elder Care (TREC): Technical Report (Report No. 12-03-TR). (Edmonton, AB: Knowledge Utilization Studies Program (KUSP), Faculty of Nursing, University of Alberta).
Estabrooks, C. A., Squires, J. E., Cummings, G. G., Birdsell, J. M., and Norton, P. G. (2009b). Development and assessment of the Alberta Context Tool. BMC Health Serv. Res. 9:234. doi: 10.1186/1472-6963-9-234
Estabrooks, C. A., Squires, J. E., Hayduk, L. A., Cummings, G. G., and Norton, P. G. (2011b). Advancing the argument for validity of the Alberta Context Tool with healthcare aides in residential long-term care. BMC Med. Res. Methodol. 11:107. doi: 10.1186/1471-2288-11-107
Estabrooks, C. A., Squires, J. E., Hayduk, L., Morgan, D., Cummings, G. G., Ginsburg, L., et al. (2015b). The influence of organizational context on best practice use by care aides in residential long-term care settings. J. Am. Med. Dir. Assoc. 16, 537.e531–537.e510. doi: 10.1016/j.jamda.2015.03.009
Estabrooks, C. A., Squires, J. E., Hutchinson, A. M., Scott, S., Cummings, G. G., Kang, S. H., et al. (2011c). Assessment of variation in the Alberta Context Tool: the contribution of unit level contextual factors and specialty in Canadian pediatric acute care settings. BMC Health Serv. Res. 11:251. doi: 10.1186/1472-6963-11-251
Fleuren, M., Wiefferink, K., and Paulussen, T. (2004). Determinants of innovation within health care organizations: literature review and Delphi study. Int. J. Qual. Health Care 16, 107–123. doi: 10.1093/intqhc/mzh030
Flodgren, G., Rojas-Reyes, M. X., Cole, N., and Foxcroft, D. R. (2012). Effectiveness of organisational infrastructures to promote evidence-based nursing practice. Cochrane Database Syst. Rev. 15:CD002212. doi: 10.1002/14651858.CD002212.pub2
Gagnon, M. P., Labarthe, J., Legare, F., Ouimet, M., Estabrooks, C. A., Roch, G., et al. (2011). Measuring organizational readiness for knowledge translation in chronic care. Implement. Sci. 6:72. doi: 10.1186/1748-5908-6-72
Glisson, C. (2002). The organizational context of children's mental health services. Clin. Child Fam. Psychol. Rev. 5, 233–253. doi: 10.1023/A:1020972906177
Grabowski, D. C., O'Malley, A. J., Afendulis, C. C., Caudry, D. J., Elliot, A., and Zimmerman, S. (2014). Culture change and nursing home quality of care. Gerontologist 54, S35–S45. doi: 10.1093/geront/gnt143
Graham, I. D., Bick, D., Tetroe, J., Straus, S. E., and Harrison, M. B. (2010). “Measuring outcomes of evidence-based practice: distinguishing between knowledge use and its impact,” in Evaluating the Impact of Implementing Evidence Based Practice, eds D. Bick and I. D. Graham (Chichester: Wiley-Blackwell), 18–37.
Green, S. B., and Hershberger, S. L. (2000). Correlated errors in true score models and their effect on Coefficient Alpha. Struct. Eq. Model. 7, 251–270. doi: 10.1207/S15328007SEM0702_6
Green, S. B., and Yang, Y. (2009). Commentary on Coefficient Alpha: a cautionary tale. Psychometrika 74, 121–135. doi: 10.1007/s11336-008-9098-4
Greenhalgh, T., Robert, G., Macfarlane, F., Bate, P., and Kyriakidou, O. (2004). Diffusion of innovations in service organizations: systematic review and recommendations. Milbank Q. 82, 581–629. doi: 10.1111/j.0887-378X.2004.00325.x
Hancock, G. R., and Mueller, R. O. (2013). Structural Equation Modeling: A Second Course. Greenwich, CT: Information Age Publishing.
Harvey, G., Jas, P., and Walshe, K. (2015). Analysing organisational context: case studies on the contribution of absorptive capacity theory to understanding inter-organisational variation in performance improvement. BMJ Qual. Saf. 24, 48–55. doi: 10.1136/bmjqs-2014-002928
Hayduk, L. A. (1996). LISREL: Issues, Debates, and Strategies. Baltimore, MD; London: The Johns Hopkins University Press.
Hayduk, L. A., Cummings, G., Boadu, K., Pazderka-Robinson, H., and Boulianne, S. (2007). Testing! testing! one, two, three – Testing the theory in structural equation models! Pers. Individ. Dif. 42, 841–850. doi: 10.1016/j.paid.2006.10.001
Hayduk, L. A., and Glaser, D. N. (2000). Jiving the four-step, waltzing around factor analysis, and other serious fun. Struct. Eq. Model. 7, 1–35. doi: 10.1207/S15328007SEM0701_01
Hoben, M., Bär, M., Mahler, C., Berger, S., Squires, J. E., Estabrooks, C. A., et al. (2014a). Linguistic validation of the Alberta Context Tool and two measures of research use, for German residential long term care. BMC Res. Notes 7:67. doi: 10.1186/1756-0500-7-67
Hoben, M., Berendonk, C., Buscher, I., Quasdorf, T., Riesner, C., Wilborn, D., et al. (2014b). Scoping review of nursing-related dissemination and implementation research in German-speaking countries: mapping the field. Int. J. Health Prof. 1, 34–49. doi: 10.2478/ijhp-2014-0002
Hoben, M., Mahler, C., Bär, M., Berger, S., Squires, J. E., Estabrooks, C. A., et al. (2013). German translation of the Alberta context tool and two measures of research use: methods, challenges and lessons learned. BMC Health Serv. Res. 13:478. doi: 10.1186/1472-6963-13-478
Hu, L.-T., and Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: conventional criteria versus new alternatives. Struct. Eq. Model. 6, 1–55. doi: 10.1080/10705519909540118
Kaplan, H. C., Brady, P. W., Dritz, M. C., Hooper, D. K., Linam, W. M., Froehle, C. M., et al. (2010). The influence of context on quality improvement success in health care: a systematic review of the literature. Milbank Q. 88, 500–559. doi: 10.1111/j.1468-0009.2010.00611.x
Kitson, A., Harvey, G., and McCormack, B. (1998). Enabling the implementation of evidence based practice: a conceptual framework. Qual. Health Care 7, 149–158. doi: 10.1136/qshc.7.3.149
Kline, R. B. (2011a). Principles and Practice of Structural Equation Modeling. New York, NY; London: The Guilford Press.
Kline, R. B. (2011b). Principles and Practice of Structural Equation Modeling. New York, NY: Guilford Press.
Kolmogorov, A. N. (1933). Sulla determinazione empirica di una legge di distribuzione (On the empirical determination of a distribution law). Giornale dell'Istituto Italiano degli Attuari 4, 83–91.
Kuske, B., Luck, T., Hanns, S., Matschinger, H., Angermeyer, M. C., Behrens, J., et al. (2009). Training in dementia care: a cluster-randomized controlled trial of a training program for nursing home staff in Germany. Int. Psychogeriatr. 21, 295–308. doi: 10.1017/S1041610208008387
Lahmann, N. A., Dassen, T., Poehler, A., and Kottner, J. (2010). Pressure ulcer prevalence rates from 2002 to 2008 in German long-term care facilities. Aging Clin. Exp. Res. 22, 152–156. doi: 10.1007/BF03324789
Lee, T., Cai, L., and MacCallum, R. C. (2012). “Power analysis for tests of structural equation models,” in Handbook of Structural Equation Modeling, ed R. H. Hoyle (New York, NY: Guilford Press), 181–194.
Little, R. J. A., and Rubin, D. B. (2002). Statistical Analysis with Missing Data. New York, NY: Wiley.
MacCallum, R. (1986). Specification searches in covariance structure modeling. Psychol. Bull. 100, 107–120. doi: 10.1037/0033-2909.100.1.107
MacCallum, R. C., Roznowski, M., and Necowitz, L. B. (1992). Model modifications in covariance structure analysis: the problem of capitalization on chance. Psychol. Bull. 111, 490–504. doi: 10.1037/0033-2909.111.3.490
Majic, T., Pluta, J. P., Mell, T., Aichberger, M. C., Treusch, Y., Gutzmann, H., et al. (2010). The pharmacotherapy of neuropsychiatric symptoms of dementia: a cross-sectional study in 18 homes for the elderly in Berlin. Dtsch Ärztebl Int. 107, 320–327. doi: 10.3238/arztebl.2010.0320
Masso, M., and McCarthy, G. (2009). Literature review to identify factors that support implementation of evidence-based practice in residential aged care. Int. J. Evid. Based Healthc. 7, 145–156. doi: 10.1111/j.1744-1609.2009.00132.x
Meijers, J. M. M., Janssen, M. A. P., Cummings, G. G., Wallin, L., Estabrooks, C. A., and Halfens, R. Y. G. (2006). Assessing the relationships between contextual factors and research utilization in nursing: systematic literature review. J. Adv. Nurs. 55, 622–635. doi: 10.1111/j.1365-2648.2006.03954.x
Meyer, G., Köpke, S., Haastert, B., and Mülhauser, I. (2009). Restraint use among nursing home residents: cross-sectional study and prospective cohort study. J. Clin. Nurs. 18, 981–990. doi: 10.1111/j.1365-2702.2008.02621.x
Miles, J., and Shevlin, M. (2001). Applying Regression & Correlation: A Guide for Students and Researchers. London: Sage.
Millsap, R. E. (2007). Structural equation modeling made difficult. Pers. Individ. Dif. 42, 875–881. doi: 10.1016/j.paid.2006.09.021
Mulaik, S. (2007). There is a place for approximate fit in structural equation modelling. Pers. Individ. Dif. 42, 883–891. doi: 10.1016/j.paid.2006.10.024
Muthén, B. O., and Muthén, L. K. (2013). Mplus Version 7.11 – Base Program and Combination Add-On. Los Angeles, CA.
Muthén, L. K., and Muthén, B. O. (2002). How to use a Monte Carlo study to decide on sample size and determine power. Struct. Eq. Model. 9, 599–620. doi: 10.1207/S15328007SEM0904_8
Muthén, L. K., and Muthén, B. O. (2012). Mplus User's Guide: Statistical Analysis With Latent Variables. Los Angeles, CA: Muthén & Muthén.
Proctor, E. K., and Brownson, R. C. (2012). “Measurement issues in dissemination and implementation research,” in Dissemination and Implementation Research in Health: Translating Science to Practice, eds R. C. Brownson, G. A. Colditz, and E. K. Proctor (Oxford: Oxford University Press), 261–280.
Proctor, E., Silmere, H., Raghavan, R., Hovmand, P., Aarons, G., Bunger, A., et al. (2011). Outcomes for implementation research: conceptual distinctions, measurement challenges, and research agenda. Adm. Policy Ment. Health 37, 65–76. doi: 10.1007/s10488-010-0319-7
Rabin, B. A., and Brownson, R. C. (2012). “Developing the terminology for dissemination and implementation research,” in Dissemination and Implementation Research in Health: Translating Science to Practice, eds R. C. Brownson, G. A. Colditz, and E. K. Proctor (Oxford: Oxford University Press), 23–51.
Rahman, A. N., Applebaum, R. A., Schnelle, J. F., and Simmons, S. F. (2012). Translating research into practice in nursing homes: Can we close the gap? Gerontologist 52, 597–606. doi: 10.1093/geront/gnr157
Raykov, T., and Marcoulides, G. A. (2006). A First Course in Structural Equation Modeling. New York, NY: Psychology Press.
Raykov, T., and Shrout, P. E. (2002). Reliability of scales with general structure: point and interval estimation using a structural equation modeling approach. Struct. Eq. Model. 9, 195–212. doi: 10.1207/S15328007SEM0902_3
Reuther, S., van Nie, N., Meijers, J., Halfens, R., and Bartholomeyczik, S. (2013). Malnutrition and dementia in the elderly in German nursing homes: results of a prevalence survey from the years 2008 and 2009. Z. Gerontol. Geriat. 46, 260–267. doi: 10.1007/s00391-012-0346-y
Rycroft-Malone, J. (2004). The PARIHS framework: a framework for guiding the implementation of evidence-based practice. J. Nurs. Care Qual. 19, 297–304. doi: 10.1097/00001786-200410000-00002
Sass, D. A. (2011). Testing measurement invariance and comparing latent factor means within a confirmatory factor analysis framework. J. Psychoeduc. Assess. 29, 347–363. doi: 10.1177/0734282911406661
Satorra, A., and Saris, W. E. (1985). Power of the likelihood ratio test in covariance structure analysis. Psychometrika 50, 83–90. doi: 10.1007/BF02294150
Shapiro, S. S., and Wilk, M. B. (1965). An analysis of variance test for normality (complete samples). Biometrika 52, 591–611. doi: 10.1093/biomet/52.3-4.591
Sijtsma, K. (2009). On the use, the misuse, and the very limited usefulness of Cronbach's Alpha. Psychometrika 74, 107–120. doi: 10.1007/s11336-008-9101-0
Silvia, E. S. M., and MacCallum, R. C. (1988). Some factors affecting the success of specification searches in covariance structure modeling. Multivariate Behav. Res. 23, 297–326. doi: 10.1207/s15327906mbr2303_2
Smirnov, N. (1948). Table for estimating the goodness of fit of empirical distributions. Ann. Math. Stat. 19, 279–281. doi: 10.1214/aoms/1177730256
Squires, J. E., Estabrooks, C. A., Hayduk, L., Gierl, M., and Newburn-Cook, C. V. (2014). Precision of the conceptual research utilization scale. J. Nurs. Meas. 22, 145–163. doi: 10.1891/1061-3749.22.1.145
Squires, J. E., Estabrooks, C. A., Newburn-Cook, C. V., and Gierl, M. (2011a). Validation of the conceptual research utilization scale: an application of the standards for educational and psychological testing in healthcare. BMC Health Serv. Res. 11, 107. doi: 10.1186/1472-6963-11-107
Squires, J. E., Estabrooks, C. A., O'Rourke, H. M., Gustavsson, P., Newburn-Cook, C. V., and Wallin, L. (2011b). A systematic review of the psychometric properties of self-report research utilization measures used in healthcare. Implement. Sci. 6:83. doi: 10.1186/1748-5908-6-83
Squires, J. E., Estabrooks, C. A., Scott, S. D., Cummings, G. G., Hayduk, L., Kang, S. H., et al. (2013a). The influence of organizational context on the use of research by nurses in Canadian pediatric hospitals. BMC Health Serv. Res. 13:351. doi: 10.1186/1472-6963-13-351
Squires, J. E., Hayduk, L., Hutchinson, A. M., Cranley, L. A., Gierl, M., Cummings, G. G., et al. (2013b). A protocol for advanced psychometric assessment of surveys. Nurs. Res. Pract. 2013:156782. doi: 10.1155/2013/156782
Squires, J. E., Hayduk, L., Hutchinson, A. M., Mallick, R., Norton, P. G., Cummings, G. G., et al. (2015). Reliability and validity of the Alberta Context Tool (ACT) with professional nurses: findings from a multi-study analysis. PLoS ONE 10:e0127405. doi: 10.1371/journal.pone.0127405
Statistisches Bundesamt (ed.). (2013). Pflegestatistik 2011: Pflege im Rahmen der Pflegeversicherung – Deutschlandergebnisse. Wiesbaden, WI: Statistisches Bundesamt.
Streiner, D. L., and Norman, G. R. (2008). Health Measurement Scales: A Practical Guide to Their Development and Use. Oxford: Oxford University Press.
Treusch, Y., Jerosch, D., Majic, T., Heinz, A., Gutzmann, H., and Rapp, M. A. (2010). How can we provide better services for demented nursing home residents suffering from apathy? Psychiatr. Prax. 37, 84–88. doi: 10.1055/s-0029-1223472
Vandenberg, R. J., and Lance, C. E. (2000). A Review and synthesis of the measurement invariance literature: suggestions, practices, and recommendations for organizational research. Organ. Res. Methods 3, 4–70. doi: 10.1177/109442810031002
Volkert, D., Pauly, L., Stehle, P., and Sieber, C. C. (2011). Prevalence of malnutrition in orally and tube-fed elderly nursing home residents in Germany and Its relation to health complaints and dietary intake. Gastroenterol. Res. Pract. 2011:247315. doi: 10.1155/2011/247315
Wang, J., and Wang, X. (2012). Structural Equation Modeling: Applications Using Mplus. Chichester: Wiley.
West, S. G., Taylor, A. B., and Wu, W. (2012). “Model fit and model selection in structural equation modeling,” in Handbook of Structural Equation Modeling, ed R. H. Hoyle (New York, NY: The Guildford Press), 209–231.
Wilborn, D., and Dassen, T. (2010). Pressure ulcer prevention in German healthcare facilities: adherence to national expert standard? J. Nurs. Care Qual. 25, 151–159. doi: 10.1097/NCQ.0b013e3181b7a675
Willis, G. B. (2005). Cognitive Interviewing: A Tool for Improving Questionnaire Design. Thousand Oaks, CA: Sage.
Yang, Y., and Green, S. B. (2011). Coefficient Alpha: a reliability coefficient for the 21st century? J. Psychoeduc. Assess. 29, 377–392. doi: 10.1177/0734282911406668
Keywords: Alberta Context Tool, conceptual research utilization scale, organizational context, best practice use, psychometric testing, confirmatory factor analysis, measurement invariance, residential long term care
Citation: Hoben M, Estabrooks CA, Squires JE and Behrens J (2016) Factor Structure, Reliability and Measurement Invariance of the Alberta Context Tool and the Conceptual Research Utilization Scale, for German Residential Long Term Care. Front. Psychol. 7:1339. doi: 10.3389/fpsyg.2016.01339
Received: 15 April 2016; Accepted: 22 August 2016;
Published: 07 September 2016.
Edited by:
Radha R. Sharma, Hero MotoCorp & Management Development Institute, IndiaReviewed by:
M. Teresa Anguera, University of Barcelona, SpainRobert Jason Emmerling, ESADE Business School, Spain
Copyright © 2016 Hoben, Estabrooks, Squires and Behrens. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Matthias Hoben, mhoben@ualberta.ca