 Ali Ünlü
Ali Ünlü Martin Schrepp
Martin Schrepp- 1Centre for International Student Assessment, Technical University of Munich, Munich, Germany
- 2SAP AG, Walldorf, Germany
Quasi-orders, that is, reflexive and transitive binary relations, have numerous applications. In educational theories, the dependencies of mastery among the problems of a test can be modeled by quasi-orders. Methods such as item tree or Boolean analysis that mine for quasi-orders in empirical data are sensitive to the underlying quasi-order structure. These data mining techniques have to be compared based on extensive simulation studies, with unbiased samples of randomly generated quasi-orders at their basis. In this paper, we develop techniques that can provide the required quasi-order samples. We introduce a discrete doubly inductive procedure for incrementally constructing the set of all quasi-orders on a finite item set. A randomization of this deterministic procedure allows us to generate representative samples of random quasi-orders. With an outer level inductive algorithm, we consider the uniform random extensions of the trace quasi-orders to higher dimension. This is combined with an inner level inductive algorithm to correct the extensions that violate the transitivity property. The inner level correction step entails sampling biases. We propose three algorithms for bias correction and investigate them in simulation. It is evident that, on even up to 50 items, the new algorithms create close to representative quasi-order samples within acceptable computing time. Hence, the principled approach is a significant improvement to existing methods that are used to draw quasi-orders uniformly at random but cannot cope with reasonably large item sets.
1. Introduction
We begin with motivational considerations. We address why discrete modeling with quasi-orders is useful and why we need to sample quasi-orders we want to be representative. In addition, this section gives an overview of the main contributions and organization of this paper.
1.1. Why Discrete Order Structures Are Important
A quasi-order on a set, for instance, of educational or psychological test or questionnaire items, is any binary relation that is reflexive and transitive. Relational dependencies or discrete order structures such as the quasi-orders can model the dependencies of mastery or precedence relations among the problems of an achievement test or the statements of an attitude questionnaire. The general idea is to represent any empirically plausible dependency of the type “The mastery of problem y implies the mastery of problem x” between the questions x and y of the test I as the item pair x ≤ y of a quasi-order ≤ on I. This quasi-order structure imposed on the test can be employed to design efficient test administration procedures. One can mimic the adaptive approach of a teacher, for instance, when the teacher's experience and knowledge about the prerequisite relations between the problems are used to avoid asking a student questions that are either too easy or too difficult. The most pertinent protagonist of this idea is the theory of knowledge or learning spaces (Doignon and Falmagne, 1985, 1999; Falmagne and Doignon, 2011; Falmagne et al., 2013). In this theory, discrete mathematical concepts, including the quasi-orders, have played an important role. They have been employed for the adaptive modeling, assessment, and training of knowledge, competence, and learning dynamics in human (e.g., student) populations. More generally, orders may be deemed a pivotal contribution to the behavioral and social sciences, amongst others. For a thorough motivation of orders and knowledge or learning space theory, including further references (see Schrepp and Ünlü, 2015).
1.2. Why Representative Quasi-Order Samples Are Important
Methods that reconstruct quasi-orders from empirical data are computational. Examples are the algorithms of item tree analysis (van Leeuwe, 1974; Schrepp, 1999; Sargin and Ünlü, 2009). For applications of item tree analysis to real datasets in knowledge or learning space theory, (see also Schrepp, 2002, 2003, 2006; Ünlü and Sargin, 2010). Computational methods of this sort have been developed, evaluated, and compared predominantly based on extensive simulation studies. It is worth mentioning that simulation is the key methodology relied on in this field, as the objective as well as systematic approach to studying these computer-oriented data mining techniques. The design of the conducted simulation studies critically depends on large samples of randomly generated quasi-orders used at their basis. Why? Each quasi-order of the sample is posited to represent the true relational dependencies that a tested mining algorithm has to reconstruct from simulated data, so one wants to ensure that no interesting quasi-order has been missed. All of the algorithms depend on the underlying quasi-order structure. For some structural types, it may be easier to detect the correct dependencies based on a dataset compared with others, and this may vary across the methods or with different datasets. Moreover, in practical contexts, the structure of the true quasi-order is typically unknown. These considerations warrant the importance of simulation studies and of controlling in these studies for the dependency on quasi-order structure.
If we do not want to exclude quasi-orders a priori from consideration, which is generally not ideal, a natural solution is to evaluate and compare the performance of the mining algorithms in the set of all possible quasi-orders. However, considering all of the quasi-orders in a simulation study is not feasible in general. A sample is needed. Once again, a natural choice is to give each quasi-order on the item set the same chance of being included in the simulation study. This will produce the least-biased results when generalizing the findings obtained from the simulation study to the population of all possible quasi-orders on the item set. Thus, it is essential for us to base any simulation study that aims to investigate the performance of such data mining techniques in a meaningful and reliable manner on representative quasi-order samples.
Definition 1. In the sequel, the representativeness of a random sample of quasi-orders means that each quasi-order on the item set has the same probability of being selected as part of the sample.
Why sampling quasi-orders is necessary for us was also concretized in Ünlü and Schrepp (2015). In their study, the importance of representative sampling of quasi-orders and the biases and errors induced by non-representative samples were clearly evidenced. The representativeness of the quasi-orders employed in extensive simulation studies was seen to be an important requirement for the sound comparison of such exploratory data analysis methods as item tree analysis. In particular, Ünlü and Schrepp (2015) found that utilizing non-representative quasi-order samples yielded biased simulative assessment results with regard to the recovery and coverage qualities associated with the existing item tree analysis algorithms. For further motivation of representative random quasi-orders (see also Schrepp and Ünlü, 2015, Section Introduction).
1.3. Content and Structure of This Work
Schrepp and Ünlü (2015) introduced an inductive algorithm, which represents the state-of-affairs sampling technique for quasi-orders. In this procedure, trace quasi-orders of lower dimension l are extended, uniformly at random, to dimension l + 1. This construction step is described later in detail. It constitutes one of the two inductive components of the proposed procedure. These random extensions are checked for transitivity. Transitive extensions are retained. Non-transitive relations are rejected without further analysis. This algorithm improves on two direct methods for drawing representative random quasi-orders (for details, see Schrepp and Ünlü, 2015). However, when the number of items n increases, all of these procedures become computationally too intensive, particularly because the proportion of extensions representing quasi-orders decreases very quickly with n.
We introduce a constructive procedure that in a second inductive step corrects the extensions that violate the transitivity property. Thus, on all trials of the new procedure, quasi-orders are obtained. Correcting for transitivity in a combinatorial manner, this randomized doubly inductive procedure is biased. However, bias correction is possible. Three algorithms are proposed. A truly representative variant, termed absolute rejection method, outright rejects the randomly generated quasi-orders based on the penalizing weights that can be computed using the inductive correction procedure. Here, the penalizing weight corresponding to a random quasi-order is the number of possible uniform extensions that, when being corrected according to the algorithm, do yield the quasi-order under reference. The second and third variants, respectively termed simple resampling method and stratified resampling method, apply proportional weighting based on the procedural bias correction factors. These methods take resamples from the constructed sample as if it were the population. The simple resampling method operates on the quasi-orders directly as the units being weighted and resampled. With the stratified resampling method, the quasi-orders of the sample are divided into strata defined by those weights before resampling. The strata are the units being weighted and resampled, and simple random sampling is applied within each drawn stratum to obtain a quasi-order sample. The two resampling-based methods are the recommended procedures. In extensive simulation studies, we will see that these algorithms are efficient and feasible for reasonably large item sets while providing close to representative random quasi-order samples.
This paper is organized as follows. In Section 2, we describe the methods currently available for sampling quasi-orders, including the pertinent inductive uniform extension approach by Schrepp and Ünlü (2015). In Section 3, we introduce the discrete doubly inductive procedure for the construction of potentially all quasi-orders on a finite item set. In Section 4, the doubly inductive procedure is randomized, thereby yielding a probabilistic procedure for quasi-order sampling. The sampling biases induced in the process of randomization are addressed, and the corresponding bias correction factors are derived. In Section 5, we propose the three algorithms for bias correction, the absolute rejection method, the simple resampling method, and the stratified resampling method. Section 6 reports the simulation results obtained for these sampling techniques. In Section 7, we summarize our findings, and we conclude with final remarks and suggestions for further research.
2. State-of-the-Art Sampling Techniques
2.1. Flexible but Non-representative Ad hoc Strategies
We present two example strategies of this sort that have been published in the literature. Because these methods are ad hoc, modifications or alternative procedures are easily possible. Ad hoc strategies are flexible and quick to compute. However, they generally lack representativeness of the generated sets of quasi-orders. For this class of procedures, it seems to be very complicated to address the issue of representativeness on a principled theoretical basis, if it can be addressed at all. Nonetheless, samples obtained from these techniques may approximate true distributions reasonably well by adjusting their parameters fittingly.
One method is based on the normal distribution, the other on the uniform distribution. Both come in two variants, absolute and averaged. Let I be an item set of size |I| = n.
1. Start with the diagonal relation on I consisting of all reflexive item pairs (i, i) with i ∈ I.
2. Let δ ~ N(μ, σ) for the normal method or δ ~ U(0, b) for the uniform method. The parameters μ (mean), σ (standard deviation), and b (upper interval bound) are specified in such a way that the realization δ constitutes a probability value between 0 and 1.
Example specifications in Sargin and Ünlü (2009) are μ = 0.16 and σ = 0.06, with the additional boundary restrictions that δ values < 0 or > 0.3 are set to 0 or 0.3, respectively. For the uniform method (Schrepp, 1999), b can be set to 0.4 or 1, for instance.
3. For any non-reflexive item pair, add that pair to the diagonal relation with probability δ (or discard it with probability 1 − δ). This yields a binary relation , which is reflexive.
4. To satisfy transitivity, take the transitive closure of . (The transitive closure of a binary relation on an item set I is the smallest binary relation on I that contains and is transitive. Note that the transitive closure always exists for any binary relation.) The resulting binary relation is the random quasi-order obtained according to the ad hoc strategy.
5. In the absolute variant, for each random δ, only one random quasi-order is drawn. In the averaged variant, for each random δ, multiple random quasi-orders are generated and jointly used in the analyses.
As shown in Ünlü and Schrepp (2015), these ad hoc random processes yield non-representative quasi-order samples. In decreasing order of representativeness were the averaged followed by the absolute normal variants, whereas both variants of the uniform method produced the worst results with random samples of overly represented large quasi-orders.
2.2. Representative but Infeasible Direct Methods
Two direct or natural sampling techniques that do yield representative random quasi-orders are census-like and entry-wise uniform sampling.
In census-like uniform sampling, all possible quasi-orders on a small-sized item set are constructed and known. The quasi-orders are randomly chosen from an accessible population. However, constructing, storing, and uniformly sampling from a known population only works for a small item number n. The total (labeled) quasi-order counts increase very rapidly (Brinkmann and McKay, 2002, 2005; Pfeiffer, 2004). For example, the counts are 9, 535, 241/642, 779, 354/63, 260, 289, 423/8, 977, 053, 873, 043 for 7/8/9/10 items, respectively. In Ünlü and Schrepp (2015), the census-like sampling approach was demonstrated with six items, where we have a total of 209, 527 quasi-orders in the population. In this method, each draw, if feasible, is a quasi-order, although the equal sampling probability for each quasi-order may be very small.
Entry-wise uniform sampling uses the relational (or adjacency) matrix representation of a quasi-order (defined below). For reflexivity, the diagonal entries are set to 1 beforehand. Each of the remaining entries of the relational matrix are randomly filled with equal probability 1/2: 1 (in relation) or 0 (not in relation). The resulting random reflexive relation is retained if it satisfies transitivity. Otherwise, the relation is rejected without further analysis.1 This procedure also becomes infeasible in n (Schrepp and Ünlü, 2015). The probability of selecting any of the reflexive and, in particular, transitive relations is the same, 0.5n(n − 1). The proportion of quasi-orders among all reflexive relations very rapidly decreases with increasing item number n. There are 2n(n − 1) reflexive relations, and for 6 ≤ n ≤ 10, the proportions are 1.95·10−4, 2.17·10−6, 8.92·10−9, 1.34·10−11, and 7.25·10−15, respectively. This very small proportion gives the probability for a draw to result in the set of all quasi-orders on n items, denoted by . Thus, draws under entry-wise uniform sampling are almost exclusively reflexive relations that do not satisfy the transitivity property. This is true especially in realistic contexts with larger item numbers. However, given a draw that occurs in , the probability for any quasi-order of being selected is the same, .
2.3. Inductive Uniform Extension Approach by Schrepp and Ünlü (2015)
The direct procedures are theoretically representative but practically infeasible. The ad hoc procedures are practically feasible but theoretically not representative. The inductive uniform extension approach by Schrepp and Ünlü (2015) is a good compromise in this regard. It relies on the same idea as the entry-wise uniform sampling but at a more informational level of matrix structures. For these matrix structures, the proportion of quasi-orders becomes sparse only for higher item numbers. Thus, the inductive procedure improves on the feasibility of the entry-wise uniform sampling method for larger values of n. It can be shown that samples generated under this approach remain representative. For details (see Schrepp and Ünlü, 2015).
The inductive uniform extension technique is essential. It constitutes one of the two inductive components of the proposed randomized doubly inductive procedure. To describe this method, we introduce the required notation. Let R ⊂ I × I be a binary relation on the item set I = {1, 2, …, n}. A pair (i, j) ∈ R is also denoted by iRj for i, j ∈ I. The relational or adjacency matrix rR of R is the binary matrix (indexing omitted subsequently) defined by rij = 1 if iRj, and 0 otherwise.
In this notation, “R is reflexive” means rii = 1 for all i = 1, …, n. The transitivity of R states that for all 1 ≤ i, j, k ≤ n, if rij = 1 and rjk = 1, then rik = 1. Moreover, the entry-wise uniform sampling can be recapped: rii : = 1 for all i ∈ I, and rij ~ iid Bernoulli(1/2) for all i, j ∈ I with i ≠ j. Here, Bernoulli(1/2) is the Bernoulli distribution with success (i.e., rij = 1) probability p = 1/2, and iid stands for “independent and identically distributed” (subsequently being omitted). In the entry-wise uniform sampling, all off-diagonal entries of the relational matrix are randomly filled. Exemplified with n = 3 items, these entries are marked:
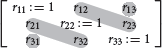
and r12, r13, r21, r23, r31, r32 ~ Bernoulli(1/2).
Let R be a trace quasi-order on the items 1, …, l. In the inductive uniform extension approach, we construct a random reflexive relation on the items 1, …, l, l + 1, which extends the relational matrix rR of R with a new (l + 1)th row and (l + 1)th column, retaining the original values of rR. The new entries are randomly filled (except for the diagonal element, which is set to 1). Exemplified with l = 2, for a trace adjacency matrix rR of dimension 2 × 2, the randomly filled entries are marked:
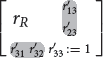
and .
More generally, we use a random variable formulation. Let (rij) be a trace reflexive matrix of independent random variables rij ~ Bernoulli(pij), with success probabilities pij of either 0, 1, or 1/2, and with pii = 1 for all i = 1, …, l. Any realization of this matrix random vector defines the relational (or adjacency) matrix of a random reflexive relation on I = {1, …, l}. A random variable reflexive extension of this trace matrix random vector is the matrix of random variables for all i, j = 1, …, l (extension), of for j = 1, …, l + 1 with p(l + 1)j = 1 for j = l + 1 (reflexivity) and 1/2 otherwise, and of for i = 1, …, l + 1 with pi(l + 1) = 1/2 for all i ≠ l + 1. Any realization of this random variable reflexive extension (on l + 1 items) that coincides with a realization of the trace matrix random vector (on l items) is called a random reflexive extension of this trace reflexive relation.
The method proposed by Schrepp and Ünlü (2015) is inductive and relies on this notion of a random reflexive extension.
Anchoring. The inductive procedure starts with a representative sample of quasi-orders on a sufficiently small number of items, l. This may include the complete inventory of all possible quasi-orders.
For example, the procedure can be anchored by using the set of all 355 (labeled) quasi-orders on l = 4 items, or with a simple random sample of 1000 quasi-orders for l = 6 items.
Inductive step. Suppose we have a representative sample of quasi-orders on n ≥ l items, denoted by (n). (Note that .) For each quasi-order in (n), we compute a pre-specified number z of random reflexive extensions of the quasi-order. These extensions are checked for transitivity. Non-transitive extensions are excluded without further analysis. The transitive extensions are added to a new collection of quasi-orders on n + 1 items, (n + 1).
Modifications are possible. Duplicates can be removed from (n + 1), depending on the envisaged application. An intermediate-step (n + 1) can be reduced to a simple random sample of feasibly limited size if the inductive construction is repeated several times to run from small to larger item numbers.
Schrepp and Ünlü (2015) showed that this procedure theoretically yields representative samples. Their study also investigated the quality of the inductive uniform extension approach in simulation. On up to 15 items, this method created representative quasi-order samples within acceptable computing time. This procedure improves on the two direct methods (Section 2.2). However, with more items, it too becomes computationally intensive. The randomized doubly inductive procedure described in the following sections significantly improves on the efficiency and feasibility of this method.
3. Doubly Inductive Procedure for Quasi-Order Construction
The driving force for the new procedure is to develop a discrete combinatorial algorithm for the construction of, in principle, all quasi-orders on a given item set (the doubly inductive component). This algorithm then can be obtained probabilistically by randomization in individual construction steps (the randomized component), eventually yielding a random process for quasi-order sampling.
3.1. Description of the Deterministic Construction Procedure
The discrete construction procedure can be termed doubly inductive in the following sense. The outer level, or Level 2, parallels the inductive uniform extension method (UEM) by Schrepp and Ünlü (2015). The trace quasi-orders of lower dimensions, l < n, are successively extended in each step by one more item, l + 1, to eventually yield final quasi-orders on n items. The inner level, or Level 1, is nested within each unit (i.e., intermediate l-dimensional trace quasi-order) at the higher Level 2. The entries of the added (l + 1)th column and (l + 1)th row of the relational matrix are filled, again inductively, according to a specific procedure we call top-down–right-left inductive discrete extension.
This strategy starts from a given trace quasi-order on the items 1, …, l and extends it, in doubly inductive manner, to a quasi-order on the items 1, …, l, l + 1, …, n. This approach is conceptually depicted by Figure 1.
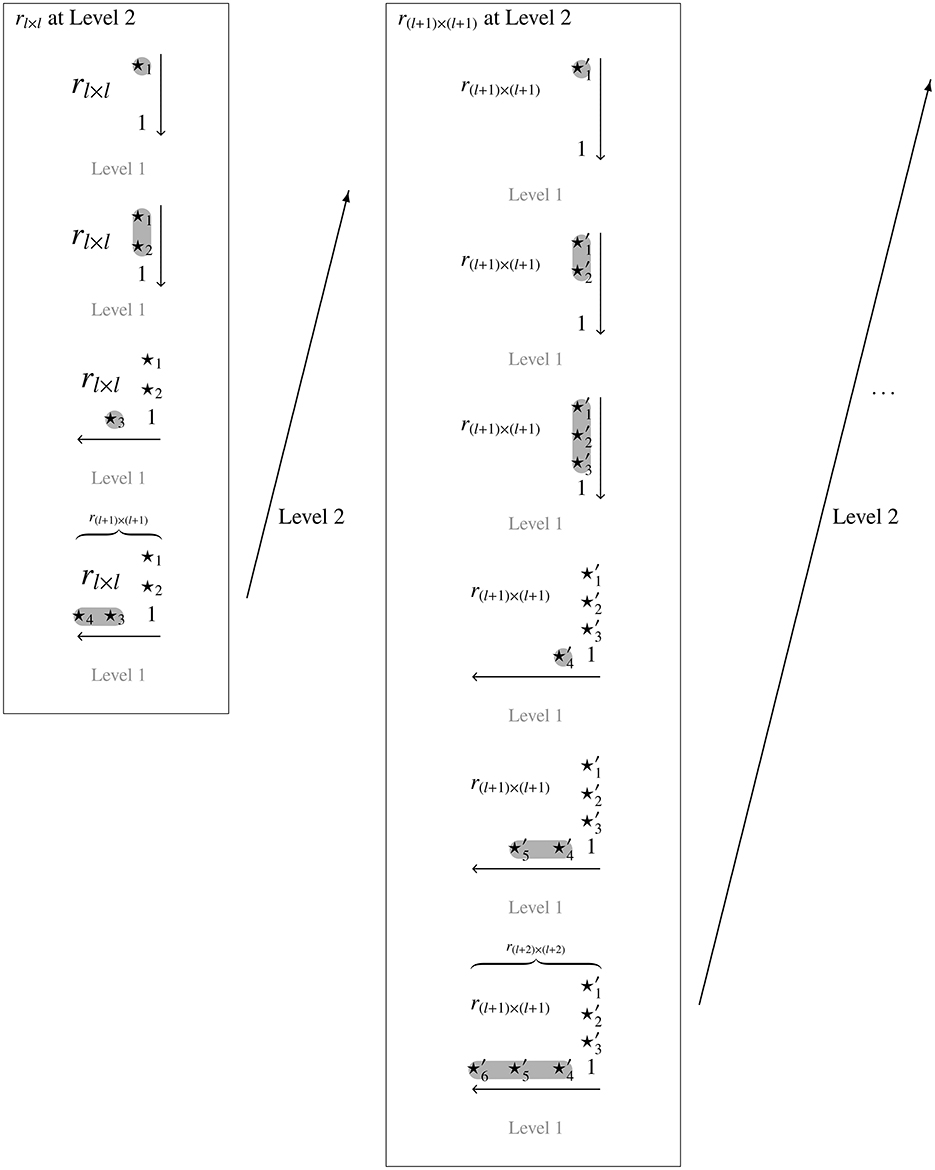
Figure 1. The doubly inductive construction procedure exemplified with l = 2. For one Level 2 inductive step leading from l to l + 1, and with four and six Level 1 inductive steps within the Level 2 units or trace quasi-orders (in relational matrix notation), rl × l and r(l + 1) × (l + 1), respectively. This leads to discrete reflexive extensions of rl × l on three items and of r(l + 1) × (l + 1) on four items. The symbols ⋆i and denote the entries of the adjacency matrices that are deterministically filled with 0's and 1's (random fillings follow later) according to the top-down–right-left inductive extension.
Throughout, we use the adjacency matrix notation. Let n : = {1, …, n}. The set of all quasi-orders on n is . The introduced procedure allows one to construct from the set of all quasi-orders on n + 1, Qn + 1. For , let : = {rn + 1 ∈ Qn + 1 : rn + 1⋂n × n = rn}. That is, is the parent family of rn of quasi-orders or extensions rn + 1 on n + 1 that coincide with rn when restricted to n ⊂ n + 1. It holds that
in the sense that forms a partition of . Thus, the target quasi-orders in can be generated by constructing for any trace quasi-order the corresponding parent family . This can be achieved as follows.
Let the additional (n + 1)th column and (n + 1)th row of any extension of be denoted by r1, n + 1, r2, n + 1, …, rn, n + 1 and rn + 1, n, rn + 1, n − 1, …, rn + 1, 1, which are listed in the order in which they are filled. Note that all other entries of rn + 1 are known. More precisely, rn + 1, n + 1: = 1, and the entries related to n are inherited from rn. Thus, the construction of means constructing all 2n-dimensional binary vectors
such that rn+1(x), that is, the matrix rn extended with these fillings, satisfies the transitivity property. Instead of filling these entries all at once and then testing for transitivity overall in the full matrix, the construction is inductive. A next step of the construction is built based on the construction steps preceding it.
Here is the description of the top-down–right-left inductive discrete extension procedure. We will verify that this procedure leads to a construction of the parent family (Proposition 2).
Filling the column n + 1 such that transitivity holds (top - down component):
The order of filling the column entries is r1, n + 1, followed by r2, n + 1, …, and finally, rn, n + 1 is filled (see Figure 1).
Anchoring. The first entry r1, n + 1 can be set to any of the values 0 and 1. No violation of transitivity occurs in either case in the sense of the two conditions required when filling the next entries rk, n + 1, k = 2, …, n (detailed below in the inductive step).
For each of the admissible values r1, n + 1 : = 0 and 1, all of the subsequent construction steps are carried out.
Inductive step. Suppose the K entries rk, n + 1 for 1 ≤ k ≤ K < n have been filled with 1's or 0's such that the following two transitivity conditions are satisfied, respectively:2
Condition C1(k), when rk,n+1 := 1. For all i ∈ {1, …, k − 1}, it holds that ri, k = 0 or ri, n + 1 = 1 (inclusive “or”).
Condition C2(k), when rk,n+1 := 0. For all i ∈ {1, …, k − 1}, it holds that rk, i = 0 or ri, n + 1 = 0.
For the construction procedure to yield the whole set , all of the admissible values for any of the entries must be combined with one another.
For the (k + 1)th entry rk + 1, n + 1, the inductive step, 1 or 0 must be assigned to rk + 1, n + 1, if they are admissible, that is, if C1(k + 1) or C2(k + 1) are satisfied, respectively. According to Proposition 2, at least one of the two conditions necessarily holds true.
For each of the admissible values for rk + 1, n + 1, all of the subsequent construction steps are carried out.
The inductive step is repeated until K = n and the column n + 1 is fully specified. We denote with the set of all possible specifications of admissible values for the (n + 1)th column, which depends on the trace quasi-order .
An example may help to illustrate this top-down construction component. On n = 2 items, consider the trace quasi-order
The entry r1, 3 of the added third column can be set to any of the admissible values 0 and 1,
Filling the entry r2, 3 yields the following possible patterns
where the values not admissible for this entry are highlighted in red. The two patterns containing inadmissible values are rejected in subsequent construction steps.
For any resulting and thus subsequently given values
the procedure continues to fill the entries of the (n + 1)th row.
Filling the row n + 1 such that transitivity holds (right - left component):
The order of filling the row is rn + 1, n, rn + 1, n − 1, …, rn + 1, 1 (see Figure 1). In this case, the value 1 is called admissible for an entry rn + 1, k (1 ≤ k ≤ n) if the following two transitivity conditions are satisfied:3
Condition R1a(k), when rn+1,k := 1. For all i ∈ {1, …, n} \ {k}, it holds that ri, k = 1 or ri, n + 1 = 0.
Condition R1b(k), when rn+1,k := 1. For all i ∈ {k + 1, …, n}, it holds that rk, i = 0 or rn + 1, i = 1.
The value 0 is admissible for an entry rn + 1, k (1 ≤ k ≤ n) if the following transitivity condition is fulfilled:
Condition R2(k), when rn+1,k := 0. For all i ∈ {k + 1, …, n}, it holds that ri, k = 0 or rn + 1, i = 0.
All of the admissible values for any of the entries must be combined with one another for the construction procedure to yield every element of .
Anchoring. The first entry rn + 1, n can be set to 0, since R2(k = n) is trivially satisfied (independent of any given ). The value 1 is admissible for rn + 1, n if condition R1a(n) is satisfied [condition R1b(n) holds true trivially]. For each of the admissible values for rn + 1, n, all of the subsequent construction steps are carried out.
Inductive step. Suppose the K entries rn + 1, k (1 < n − k + 1 ≤ k ≤ n) have been filled with 1's or 0's such that the conditions R1a(k) and R1b(k) or R2(k) are satisfied, respectively.
For the (k + 1)th entry rn + 1, n − K, the inductive step, 1 or 0 must be assigned to rn + 1, n − K, if they are admissible, that is, if the conditions R1a(n − K) and R1b(n − K) or R2(n − K) are satisfied, respectively. According to Proposition 2, at least one of the conditions R1a(n − K) and R1b(n − K) or R2(n − K) necessarily holds true.
For each of the admissible values for rn + 1, n − K, all of the subsequent construction steps are carried out.
The inductive step is repeated until K = n and the row n + 1 is fully specified. We denote with the set of all possible specifications of admissible values for the (n + 1)th row, which depends on the vector and trace quasi-order .
In the above example, the patterns to be further filled are
Filling the entry r3, 2 gives
All of the possible patterns contain admissible values. The entry r3, 1 must be filled for each of these patterns, yielding
and
Inadmissible values for this entry are shown in red and the corresponding matrices do violate the transitivity conditions. Thus, the parent family of the quasi-order
of all reflexive and transitive extensions on 3 that coincide with r2 when restricted to 2 ⊂ 3 is
3.2. Properties of the Doubly Inductive Procedure
We discuss a few important properties of this construction procedure. From the example above, we can see that for any position that is filled, one or both of the values 0 or 1 is admissible. For instance, in the construction step
both 0 and 1 are admissible values for the entry r3, 2. In a subsequent step of filling the entry r3, 1,
the value 0 is the only admissible. Moreover, surveying the known population of all quasi-orders on a set of three items, we have verified in the example that the extensions constructed according to the procedure are exactly those quasi-orders in that population which have the initial quasi-order r2 as the trace. In the example, the corresponding parent family has been constructed and consists of four quasi-orders.
The afore mentioned properties are not specific to the example and can be proven in the general case.
Proposition 2. Under the aforementioned prerequisites and notation, we have:
1. In any step of the construction procedure, that is, for any of the entries r1, n + 1, r2, n + 1, …, rn, n + 1, rn + 1, n, rn + 1, n − 1, …, rn + 1, 1, at least one of the values 1 or 0 is always admissible for the position that is filled. More precisely:
(a) In the case of filling column n + 1, for any position k = 1, …, n , at least one of the conditions C1(k) or C2(k) is satisfied.
(b) In the case of filling row n + 1, for any position k = 1, …, n , the conditions R1a(k) and R1b(k) are satisfied or the condition R2(k) is fulfilled.
2. The set of all relational matrices resulting from this construction is equal to the parent family of . More precisely:
where rn + 1(x) is the matrix rn extended with the fillings in x as the (n + 1)th column and (n + 1)th row added to rn.
Proof. 1, a. Assume that k > 1 is the smallest position such that both conditions C1(k) and C2(k) are violated. Then, there exist an i1 ≤ k − 1 with ri1, k = 1 and ri1, n + 1 = 0, and an i2 ≤ k − 1 with rk,i2 = 1 and ri2, n + 1 = 1. If i1 = i2, the contradiction is 0 = ri1, n + 1 = ri2, n + 1 = 1. Let i1 ≠ i2. Since rn is a quasi-order on n, we have ri1, i2 = 1. If i1 < i2, since k is the smallest such critical position and ri2, n + 1 = 1, the condition C1(i2) is satisfied. Since ri1, n + 1 = 0, it follows 0 = ri1, i2 = 1. If i2 < i1, because ri1, n + 1 = 0, the condition C2(i1) is fulfilled. Since ri2, n + 1 = 1, the resulting contradiction is 0 = ri1, i2 = 1.
1, b. Assume that k < n is the largest position such that R1a(k) or R1b(k) is violated and the condition R2(k) is not satisfied. Then, there is an i1 ∈ n, i1 ≠ k, with ri1, k = 0 and ri1, n + 1 = 1, or there is an k < i2 ≤ n such that rk,i2 = 1 and rn + 1,i2 = 0, and we have an k < i3 ≤ n with ri3, k = 1 and rn + 1,i3 = 1. First, consider the case of i1 and i3. If i1 = i3, 0 = ri1, k = ri3, k = 1. Let i1 ≠ i3. Since k is the largest such critical position, i3 > k, and rn + 1,i3 = 1, the condition R1a(i3) is fulfilled. Since i1 ∈ n\{i3} and ri1, n + 1 = 1, this implies ri1, i3 = 1. Since rn on n is transitive and ri3, k = 1, we obtain the contradiction 0 = ri1, k = 1. Second, consider the case of i2 and i3. If i2 = i3, 0 = rn + 1,i2 = rn + 1,i3 = 1. Let i2 ≠ i3. Since rn is transitive, and ri3, k = 1 and rk,i2 = 1, it holds that ri3, i2 = 1. If (k <)i3 < i2, since rn + 1,i3 = 1, R1b(i3) holds true. Because rn + 1,i2 = 0, we have ri3, i2 = 0. If i2 < i3, since rn + 1,i2 = 0, R2(i2) is satisfied. Therefore, ri3, i2 = 0, because rn + 1,i3 = 1. In both cases, this is in contradiction to ri3, i2 = 1.
2, Obviously, rn + 1(x) is reflexive, and rn + 1(x)⋂n × n = rn. We show that rn + 1(x) on n + 1 is transitive. We have to distinguish three cases, with x, y ∈ n, x ≠ y: (a) rn + 1, x = 1 and rx, y = 1 implies rn + 1, y = 1, (b) rx, n + 1 = 1 and rn + 1, y = 1 implies rx, y = 1, and (c) rx, y = 1 and ry, n + 1 = 1 implies rx, n + 1 = 1.
Re (a): Let x < y. Since rn + 1, x = 1 is an admissible value set in the (n + 1)th row, R1b(x) is true. Because rx, y = 1, it follows rn + 1, y = 1. Let y < x. Assume that rn + 1, y = 0. This leads to a contradiction. The condition R2(y) would hold true. Since rx, y = 1, this would imply rn + 1, x = 0. According to the first part of the proposition, thus rn + 1, y = 1.
Re (b): The filling rn + 1, y = 1 is admissible and R1a(y) is fulfilled. Thus, rx, n + 1 = 1 implies rx, y = 1.
Re (c): Let x < y. The filling ry, n + 1 = 1 in the (n + 1)th column is admissible and C1(y) is satisfied. Then, rx, y = 1 implies rx, n + 1 = 1. Let y < x. Assume that the xth position filled in the (n + 1)th column is rx, n + 1 = 0. The condition C2(x) would be fulfilled, and rx, y = 1 would imply ry, n + 1 = 0. This contradicts the assumption ry, n + 1 = 1. The first part of the proposition yields rx, n + 1 = 1.
2, . Let . That is, rn + 1 is a quasi-order on {1, …, n + 1}, and rn + 1⋂n × n = rn. Let x = (r1, n + 1, …, rn, n + 1, rn + 1, n, …, rn + 1, 1), with rn + 1(x) = rn + 1, be the relevant entries of rn + 1 the construction needs to retrieve. We show that (a) and (b) .
Re (a): Assume that there exists an k = 2, …, n such that the value rk, n + 1 is not admissible for the kth entry of the column n + 1, presupposing the given specifications r1, n + 1,…,rk, n + 1 up to this critical position. If rk, n + 1 = 1, C1(k) must be violated. Then, there is an i < k such that ri, k = 1 and ri, n + 1 = 0. This contradicts the assumption that rn + 1 is transitive on {1, …, n + 1}. If rk, n + 1 = 0, C2(k) is violated. Then, for an i < k, rk, i = 1 and ri, n + 1 = 1. However, rk, n + 1 = 0. Thus, .
Re (b): Assume that there exists an k = 1, …, n such that the value rn + 1, k is not admissible for that entry of the row n + 1, conditional on the given values c1, rn + 1, n, rn + 1, n − 1, …, rn + 1, k. If rn + 1, k = 1, R1a(k) or R1b(k) must be violated. If R1a(k) is not satisfied, there is an i ≠ k such that ri, n + 1 = 1. However, ri, k = 0. If R1b(k) is not satisfied, there exists an i > k with rk, i = 1. However, rn + 1, i = 0. If rn + 1, k = 0, R2(k) must be violated. Then, there is an i > k such that rn + 1, i = 1 and ri, k = 1. However, rn + 1, k = 0. Thus, . □
The overall deterministic construction procedure starts with the set of all quasi-orders on a sufficiently small number of items l. Based on the top-down–right-left inductive discrete extension method, every is extended by one more item. This yields the parent families . Thus, is constructed. This process is repeated with to generate , and so forth, until a targeted set of all quasi-orders for some n > l has been achieved.
4. Randomization of the Discrete Doubly Inductive Construction Procedure
This section introduces a probabilistic modification of the deterministic construction that will be used for the representative sampling of quasi-orders. The general aim is to randomize based on the discrete uniform distribution the construction procedure shown in Figure 1 to transform it into a Laplace random experiment. Another view on the proposed sampling method is to combine the deterministic construction with the uniform extension approach described in Section 2.3. That is, the top-down–right-left method is deployed to correct the random reflexive extensions of the Schrepp and Ünlü (2015) approach that do not satisfy the transitivity property.
4.1. Description of the Probabilistic Sampling Procedure
The proposed doubly inductive procedure consists of two levels: the outer Level 2 and inner Level 1 inductive constructions, which are alternated. It starts with a sufficiently small number of items l successively extending lower-dimensional trace quasi-orders by one additional item to eventually yield final quasi-orders on a larger number of items n > l (see Figure 1). It suffices to randomize Level 1 computations, which is the top-down–right-left inductive discrete extension method.
There is a disadvantage of the randomization procedure. The applied corrections are of a combinatorial or non-probabilistic type and entail sampling biases. However, the bias correction factors can be computed based on the following notion of a biasing position (see Proposition 4).
Definition 3. Traversing the entries r1, n + 1, …, rn, n + 1, rn + 1, n, …, rn + 1, 1 to be filled in the successive order given according to the procedure below, a position of this sequence is called biasing if one, and only one, of the values 0 or 1 is admissible for this position.
Randomized Level 1 procedure:
Presuppose a given Level 2 trace quasi-order . To randomly extend it to n + 1, rn + 1, we pursue the following strategy (cf. Section 3.1).
1. Randomly fill r1, n + 1 ~ Bernoulli(1/2). No checks are necessary. Both of the simulated values 1 and 0 are admissible for this position according to C1(k = 1) and C2(1), respectively. (Because the position r1, n + 1 can always be set to any of the two values 0 and 1 without violating the transitivity conditions, the first entry always represents a non-biasing position.)
2. Randomly fill r2, n + 1 ~ Bernoulli(1/2). The conditions C1(k = 2) and C2(2) are tested. If the simulated value is admissible, we keep it and proceed to fill the next position. (In this case, the second position may or may not be a biasing position. This depends on whether the complementary value, 1 − r2, n + 1, is inadmissible or admissible for this entry, respectively.) If the simulated value is not admissible, 1 − r2, n + 1 is assigned, which necessarily must be admissible according to Proposition 2. (Obviously, the second entry is a biasing position in this case.)
This process is repeated until the last entry rn, n + 1 ~ Bernoulli(1/2) of column n + 1 is randomly filled, the conditions C1(k = n) and C2(n) are checked, and an admissible value is assigned to this position. Overall, this yields a random vector c of admissible values in fully specifying column n + 1.
3. The sampling procedure continues to randomly fill the positions in the (n + 1)th row based on the conditions R1a, R1b, and R2. First, rn + 1, n ~ Bernoulli(1/2) needs to be checked for admissibility only if it equals 1. If the sampled value is admissible, we keep that value and continue. Otherwise, if we sampled 1 and R1a(n) is not satisfied, the complementary value 0 is admissible (Proposition 2) and assigned to this position.
4. Then, rn + 1, n − 1 ~ Bernoulli(1/2) is randomly filled. The conditions R1a(k = n − 1) and R1b(n − 1) or R2(n − 1) are examined, and analogously, an admissible value is assigned to this position. This process is repeated until the last entry of row n + 1 is filled, rn + 1, 1 ~ Bernoulli(1/2). Based on the conditions R1a(k = 1) and R1b(1) or R2(1), the admissibility of the simulated value is checked and, if necessary, replaced by the complementary value.
This fully specifies the (n + 1)th row with a random vector of admissible values in 2(c, rn). Thus, the whole relational matrix for rn + 1 has been randomly constructed, which must be a quasi-order on n + 1 according to Proposition 2.
An example may be helpful. Consider the quasi-order given by
which is the relational matrix of a chain structure. Applying the above probabilistic procedure, this quasi-order may be randomly extended by one more item as follows. The first entry is filled with any of the possible Bernoulli realizations, say r1, 4 = 1,
Both 0 and 1 are then admissible values for the entry r2, 4. The procedure selects one of the two values uniformly at random, say r2, 4 = 0,
Given the previous values, we see that for r3, 4 the only admissible value is 0. This value is assigned,
With this vector of admissible values fully specifying the fourth column, both the values 0 and 1 are admissible for the entry r4, 3. A Bernoulli realization is taken to fill this entry, say r4, 3 = 1,
For the entry r4, 2, both the values 0 and 1 are admissible. A value is assigned uniformly at random, say r4, 2 = 0,
Then, for r4, 1, the only admissible value is 0. This yields
In this example, there are two biasing positions. For each of the entries r3, 4 and r4, 1, the only admissible value is 0.4
The overall probabilistic sampling procedure is a randomized counterpart of the discrete construction procedure shown in Figure 1. It starts with a representative collection of quasi-orders (l) on a sufficiently small number of items l. Applying the randomized top-down–right-left inductive extension, every rl ∈ (l) is extended by one more item. Thus, a sample (l + 1) of random quasi-orders rl + 1 is generated. This process is repeated with Q(l + 1) to create some (l + 2), and so forth, until a targeted sample (n) of random quasi-orders for some n > l has been achieved.
This sampling procedure can be viewed as a correction technique for the uniform extension approach by Schrepp and Ünlü (2015). This procedure can be used to correct the random extensions that violate the transitivity property. Subsequently, we follow the line of reasoning in the proof of the part “2, ” of Proposition 2. In the next section, this result will be used to determine the correction factors needed to balance the sampling biases induced by the combinatorial corrections.
Correcting random reflexive extensions to satisfy transitivity, :
Assume that is a random reflexive, but not necessarily transitive, extension on n + 1 of a quasi-order rn on n (in the sense of the definition given in Section 2.3).
Let r1, n + 1, …, rn, n + 1, and rn + 1, n, …, rn + 1, 1 be the relevant entries of that we want to correct if necessary. In this order, we successively apply the admissibility tests. Entry for entry, the transitivity conditions C1, C2, R1a, R1b, and R2 are verified. If a value in this sequence is not admissible for the corresponding position (necessarily a biasing position), we replace it with the complementary value. This assigned new value must be admissible (Proposition 2). However, if a value in this sequence is admissible for the corresponding position, we leave it intact. (Such a position may or may not be biasing. If the complementary value is also admissible, this position is non-biasing. Otherwise, it is a biasing position.)
The resulting corrected matrix is the adjacency matrix of a quasi-order on n + 1, unlike obtained in the original approach by Schrepp and Ünlü (2015). It extends the quasi-order rn as the trace on n.
If we replace one or both of the biasing positions r3, 4 = 0 or r4, 1 = 0 of the quasi-order r4 constructed in the preceding example with the complementary value 1 (in red), the resulting extensions (of r3)
are reflexive but not transitive. Such a matrix may be obtained in the inductive uniform extension approach. We can apply the procedure to correct for transitivity. For any of these matrices , it holds that .
4.2. Induced Sampling Biases and Bias Correction Factors
This sampling procedure has the advantage that it can generate, very quickly and efficiently, samples of random quasi-orders on very large item sets. The disadvantage is that the combinatorial corrections entail sampling biases in the random process of quasi-order generation. However, as we will discuss next, the induced biases can be corrected.
Why are sampling biases induced in this procedure? That is, why can two quasi-orders rn + 1 and sn + 1 with corresponding trace quasi-orders rn and sn, or similarly, and with the same trace quasi-order rn, be drawn with different probabilities? The sampling procedure is equivalent to uniformly creating random reflexive extensions in a first probabilistic step, and these extensions are corrected for transitivity using the strategy described in the previous section in a second deterministic step. For an item number n, all random reflexive extensions have the same probability 2−2n of being drawn. Thus, the probabilities for sampling rn + 1 and sn + 1, or and , are proportional to the numbers of random reflexive extensions that yield the corresponding quasi-orders under reference when corrected according to the procedure. (The same proportionality factor is 2−2n.) Those sets generally do differ in their cardinalities. However, we can determine their sizes and use this information to adjust for an equal, or approximately equal, sampling probability (Proposition 4).
We require some notation. Let denote the set of all reflexive relations on n + 1. For a trace quasi-order , let be the set of all possible random reflexive extensions of rn. The correction of random reflexive extensions described in Section 4.1 can be viewed as the operator . For a sampled quasi-order , let denote the set of all random reflexive extensions of the underlying trace quasi-order rn that yield the quasi-order rn + 1 when corrected according to the correction procedure .
Proposition 4. Let rn + 1 be a quasi-order randomly generated from a trace quasi-order rn according to the sampling procedure. It holds that:
1. The probability for sampling rn + 1 is
where is the number of random reflexive extensions of rn that, when being corrected using the procedure , yield rn + 1.
2. The size can be computed based on the inductive character of the correction. We have
where 0 ≤ B(rn + 1) ≤ 2n − 1 is the number of the biasing positions (Definition 3) among the 2n − 1 entries r2, n + 1, …, rn, n + 1 and rn + 1, n, …, rn + 1, 1 of rn + 1 that have been filled.
Proof. 1. The problem can be framed in complete mathematical form based on probability theory. Let be the Laplace probability space, where Ω′ is the sample or outcome space of random reflexive extensions (of rn), and is the σ-algebra (power-set) of measurable events or subsets of random reflexive extensions. Since each elementary event or random reflexive extension occurs with the same probability , this is the Laplace probability measure that assigns to each subset of random reflexive extensions, , the probability . Let be the measurable space representing the quasi-orders on n + 1. Under these prerequisites, the correction operator is a random variable, that is, a measurable function mapping the Laplace probability space to the measurable space . Thus, according to probability theory,
2. A position among the filled admissible values r1, n + 1, …, rn, n + 1, rn + 1, n, …, rn + 1, 1 of the quasi-order rn + 1 is a biasing position if and only if the value corresponding to this position cannot be replaced by its complementary value, leaving the (preceding) other values of this vector unchanged, without violating the transitivity conditions according to the procedure . Let B(rn + 1) = 0. That is, all positions are non-biasing. We must have . Since any of the two admissible values for each non-biasing position will not be altered under the correction procedure, , and implies . Thus, . Let B(rn + 1) ≥ 1 biasing positions be denoted by the ordered sequence of their position indices 1 < b1 < b2 < … < bB(rn + 1) ≤ 2n among the entries r1, n + 1, …, rn, n + 1, rn + 1, n, …, rn + 1, 1 of the quasi-order rn + 1. For ease of notation, for any , we refer to its relevant entries , , …, , , , …, as , , …, , , , …, , respectively. We show that the projection
is bijective, thus proving the statement .
Injectivity: Let , . There is a position with index i0 such that . Suppose i0 represents a non-biasing position. Then, and are admissible values for this position in matrices and , respectively. Since the admissible values of a reflexive extension are not altered when corrected, this implies , yielding the contradiction rn + 1 ≠ rn + 1. Thus, i0 ∈ {b1, …, bB(rn + 1)}, and .
Surjectivity: Let . Replace the entries of the relational matrix rn + 1 at the positions given by the indices b1 < b2 < … < bB(rn + 1) with the values , respectively. For this resulting matrix , we have , and . □
We continue with the previous example. Consider the two quasi-orders
and
with the same trace quasi-order
It holds that and ; the biasing positions are shown in bold. For their sets of all random reflexive extensions of the underlying trace quasi-order r3, which yield these quasi-orders when corrected according to the procedure , we have (inadmissible values highlighted in red)
and
These sets do differ in their cardinalities, which are equal to “2 to the power their numbers of the biasing positions.” In particular, the sampling probabilities are and .
The cardinalities determined in Proposition 4 are essential. They can be used as the penalizing weights to adjust for representative, or close to representative, quasi-order sampling. In short, let rn+1 and sn+1 be two quasi-orders generated according to the sampling procedure from their trace quasi-orders rn and sn. The bias correction factors and can be used in post-construction sampling to equalize the corresponding probabilities. That is, and . Details are discussed in the following section.
5. Procedural Variants for Bias Correction
Three algorithms are introduced to combine the randomized doubly inductive construction with the precise bias correction. The absolute rejection method is the exact approach. However, it is computationally the most intensive. The simple and stratified resampling methods are the recommended procedures. They are computationally viable and efficient, and they provide close to representative random quasi-orders.
5.1. Absolute Rejection Method
The following steps define the absolute rejection method (ARM); see Proposition 5. In each inductive step, from k to k + 1 items, three random experiments are concatenated.
Random experiment RE1. The random quasi-orders are drawn such that they are equally probable.
Random experiment RE2. The randomized doubly inductive procedure is applied to construct from the drawn quasi-orders (random experiment RE1) the random extensions rk+1 in with respective probabilities .
Random experiment RE3. After this construction (concatenated random experiment RE2 ∘ RE1), a bias-correcting random process is utilized for penalizing the sampled quasi-orders rk+1. If W = 1 occurs with probabilities , the quasi-orders rk+1 are retained. They are rejected if the outcome W = 0 is obtained.
We denote the rejection outcome of the concatenated random experiment RE3 ∘ (RE2 ∘ RE1), that is, of “an inductively constructed quasi-order not being retained,” with symbol . Thus, the extended sample spaces for all stages l < i ≤ n of the procedure are given by :. (Except for the anchoring or start stage l, in which no penalization is required.) For the overall bias-corrected sampling procedure, we obtain the representativeness result that is analogous to the main result in Schrepp and Ünlü (2015, p. 4, Proposition).
Proposition 5. Let the bias correction factors be applied to equalize probabilities in repetitions of the randomized Level 1 computations over the Level 2 stages of the randomized doubly inductive procedure from a start stage l (sufficiently small) up to an end stage n > l. Then:
The final sampling probabilities obtained for the last Level 2 stage n are defined for all of the possible quasi-orders on n items, and all of these probabilities are equal. That is, traversing the proposed hierarchical sampling procedure, we eventually end up with simple random (or uniform) sampling from the quasi-order population .
Proof. As anchoring, the procedure starts with some Laplace probability space for a sufficiently small item number l. Here, “” means Pl is defined by for all , and additively extended to .
In the inductive step, from l ≤ k < n to k + 1, assume that we are uniformly sampling from the set of all quasi-orders on k items, represented by the Laplace probability space . According to the properties of the deterministic component of the doubly inductive construction procedure (see Section 3.1 and Part 2 of Proposition 2),
where “∑ over ” stands for the Level 2 construction, and
represents the Level 1 construction within a given Level 2 unit . The concatenation RE3 ∘ (RE2 ∘ RE1) can be represented by the probability space . We see from the above deterministic properties that the sample space of all possible outcomes of this concatenated random experiment is the set . According to the formula of total probability, for any ,
where and for all with , and
Therefore, for any , the marginal probability for sampling rk+1 is the same value . We only focus on and work with the retained inductively constructed quasi-orders. So if we condition on the negation , the effective probability for sampling any is . This yields the Laplace probability space , which represents simple random sampling from the quasi-order population . □
5.2. Simple and Stratified Resampling Methods
The simple resampling method (SIRM) and the stratified resampling method (STRM) are approximate, sufficiently precise variants for bias correction. Their usefulness is demonstrated based on simulation studies (Section 6). The theoretical study of the probability theory foundation of the SIRM and STRM and of their interrelationship require more work, which is an interesting direction for future research (cf. Section 7).
5.2.1. SIRM Approach
The SIRM is anchored with simple random sampling for a small item number l. That is, we start with a Laplace probability space . In each inductive step of the doubly inductive procedure, from l ≤ k < n to k + 1 items, the SIRM is the concatenation of the following random experiments.
First, we run the construction component. A bias-corrected sample (explained below) of a fixed size N, denoted by N(k), of approximately representative to representative random quasi-orders on k items is presupposed and extended based on the randomized doubly inductive construction procedure. For the anchoring k = l, N(l) is any simple random sample of size N drawn with replacement (or without, if possible) from the known quasi-order population . That is, the randomized doubly inductive construction procedure is applied to extend each quasi-order rk of the sample and multiset (possibly with repetitions) N(k) to a random quasi-order with probability . We collect all of these extensions rk+1 in a constructed multiset of size N, denoted by .
Second, with the correction component, the constructed sample is corrected for biases. This is achieved by weighted resampling with replacement. The weight assigned to an element rk+1 of is
These are the probability weights for obtaining the quasi-orders of . The resulting resample and multiset of the fixed size N is the bias-corrected sample obtained for the induction step k + 1 of the SIRM. It consists of close to representative random quasi-orders on k + 1 items, denoted by N(k + 1).
5.2.2. STRM Approach
The STRM is anchored with simple random sampling for a feasibly small item number l, that is, with some Laplace probability space . In each inductive step of the doubly inductive procedure, from l ≤ k < n to k + 1 items, the STRM is the concatenation of the following random experiments.
The first step of the STRM equals the SIRM. As the construction component, a bias-corrected sample N(k) of a fixed size N of close to representative or representative random quasi-orders on k items is extended based on the randomized doubly inductive construction procedure. As the anchoring, N(l) is a simple random sample of size N drawn with (or without) replacement from the quasi-order population . All extensions of the quasi-orders rk ∈ N(k) are collected in a constructed sample of size N.
In their second steps, the STRM and SIRM do differ. The correction component of the STRM is an approach based on stratification, whereby the biased constructed multiset is partitioned into specific submultisets or strata. Let
be the set of the unique numbers of the biasing positions implied by the quasi-orders in the sample ; see Definition 3 and Proposition 4. The family
is a partition of the sample , where
is the submultiset of quasi-orders in with the same number b of their biasing positions. The partition elements for are called strata. Thus, the strata are defined ex post in the constructed sample, based on the numbers of the biasing positions obtained for the sampled quasi-orders. We denote with |Sb| the cardinality of a stratum Sb, that is, the total number of elements including repeated membership. Note that |Sb| is the absolute frequency of how often the number of biasing positions is observed in the sample .
With the correction component of the STRM, the constructed sample is corrected for biases. This is achieved by weighted resampling after stratification, followed by simple random sampling within the drawn strata. Both the resampling and sampling occur with replacement. By definition, the strata uniquely correspond to the numbers of biasing positions. Thus, weighting and resampling of the strata can be implemented by weighting and resampling the elements of the set . The weight assigned to an element b of is
These are the probability weights for obtaining the elements of . Let this sample be denoted by BS (|BS| = N).
For any b in BS, including repeated membership, consider the uniquely determined stratum Sb. All quasi-orders of this “drawn” multiset Sb have the same sampling probability 1/|Sb|. From Sb, one element is randomly selected. This can be equivalently formulated as follows. Let be the underlying set of the unique elements of the multiset BS. That is, only one instance of an element is allowed. For every , let the multiplicity or number of occurrences of b* in the multiset BS be denoted with m(b*) ≥ 1 (). From each stratum for , a simple random sample with replacement of size m(b*) is drawn. All resampled quasi-orders are put together. The resulting multiset of size N, of close to representative random quasi-orders on k + 1 items, is the bias-corrected sample obtained for the induction step k + 1 of the STRM.
Section 6 reports the simulation results demonstrating the usefulness of the SIRM and STRM approaches for representative quasi-order sampling.
6. Simulation Results
We present simulation results for the ARM, SIRM, and STRM used to sample quasi-orders. The representativeness of the quasi-order samples was assessed using as an evaluation criterion the size or cardinality of a quasi-order. In addition, the per–hundred–quasi-orders mean computing time in seconds (s) required on average for randomly generating 100 quasi-orders is reported. We also computed the Tukey (1977) five-number summaries (here, box plot statistics), the lower-whisker extreme, lower-hinge (first quartile), median, upper-hinge (third quartile), and the upper-whisker extreme. Moreover, the mean, scatter plot, histogram, and kernel density estimate of the sample quasi-order sizes are presented. These summary measures are used to describe and visualize their distribution. The whiskers of the box plot extend to the most extreme data points that are no more than 1.5 times the interquartile range, or the length of the box, away from the box edges. Thus, the box plot represents both the summary statistics about center and spread and the distribution of the primary data (Tukey, 1977).
The computations were run in R (The R Core Team, 2016, www.R-project.org) on an Intel Core i7 3.4 GHz processor. Throughout the simulation studies, in all of the cases, the inductive construction processes were anchored by using the population of all four (labeled) quasi-orders on l = 2 items.
6.1. Assessing Representativeness in the Complete Inventory Cases of n = 3, 4, 5, and 6 Items
First, we evaluate the quality of the representativeness of the sampling techniques for n = 3, 4, 5, and 6 items. For these item numbers, the complete population of all quasi-orders can be constructed reasonably quickly. Thus, the created samples can be compared to the true population properties. On a set of n = 3, 4, 5, and 6 items, there exist 29, 355, 6942, and 209, 527 (labeled) quasi-orders, respectively (e.g., Brinkmann and McKay, 2002). These populations were known and were used in the following analyses.
Figure 2 shows the sample (solid red line or filled green dot) and population (solid dark line) distributions of the quasi-order sizes (without the reflexive item pairs). The reported sample values are the averages taken over 100 trials or quasi-order samples drawn according to the respective methods. The population values were computed in the given sets of all possible quasi-orders. Two sample sizes of randomly generated quasi-orders were considered. In Figure 2, the solid red line and filled green dot are for quasi-order samples of sizes N = 100 and 500, respectively. The columns stand for n = 3, 4, 5, and 6 items, and the rows represent the sampling methods ARM, SIRM, and STRM, respectively.
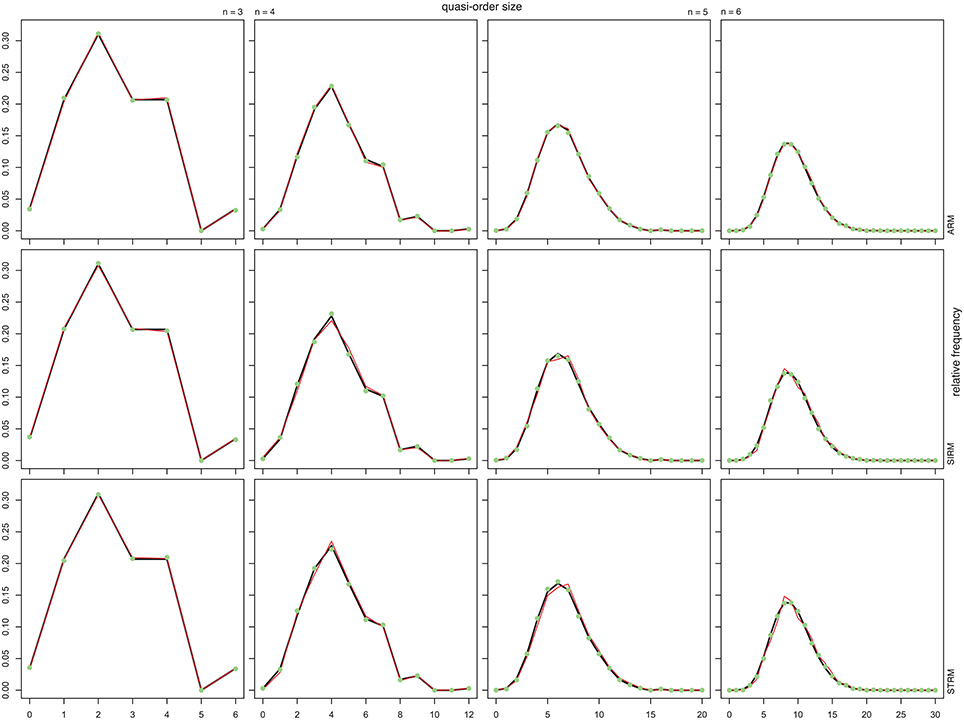
Figure 2. The relative frequencies of the quasi-order sizes (excluding the reflexive item pairs) computed in the populations of all quasi-orders (solid dark line), which are compared with the means of the relative frequencies of the sizes computed over 100 trials in each of the samples of 100 (solid red line) and 500 (filled green dot) quasi-orders. From left to right, the first, second, third, and fourth columns stand for n = 3, 4, 5, and 6 items, respectively. From top to bottom, the first, second, and third rows represent the ARM, SIRM, and STRM, respectively. In each of these cases, we started the inductive construction anchoring with l = 2 items.
From Figure 2, we see that under any method, the true distributions were estimated very well for all item numbers and with especially higher accuracy as the sample size increased. In contrast to the practicable resampling methods SIRM and STRM, the theoretical rejection method ARM yielded more representative quasi-order samples with smaller sample sizes. However, we will demonstrate in the following section that this result is obtained with substantial extra computation cost when more items are used.
6.2. Assessing Representativeness in Comparison to Schrepp and Ünlü (2015) or up to n = 20 Items
For comparison with the UEM by Schrepp and Ünlü (2015), Figure 3 shows the percent-percent (P-P) plots (e.g., Tukey, 1977). These plots compare the empirical cumulative distribution functions of the sample quasi-order sizes for ARM, SIRM, and STRM, placed on the y-axes, with the sample cumulative probabilities for the quasi-order sizes observed under the UEM, as the reference distribution functions placed on the x-axes. The straight lines in red, y = x, are used for comparison. Deviations of the points from the lines indicate differences between the two distributions being plotted against each other. The comparisons were made for the item numbers n = 7, 8, 9, and 10. For the computationally intensive methods ARM and UEM, ten trials each with N = 1000 quasi-orders were run, compared to the much faster SIRM and STRM procedures, with 50 trials each of N = 10, 000 simulated quasi-orders. The cumulative probabilities graphed in Figure 3 are the mean values computed over the trials, where the empirical cumulative distribution functions were evaluated at the potential and unique quasi-order sizes 0, 1, …, n2 − n (i.e., excluding the reflexive item pairs).
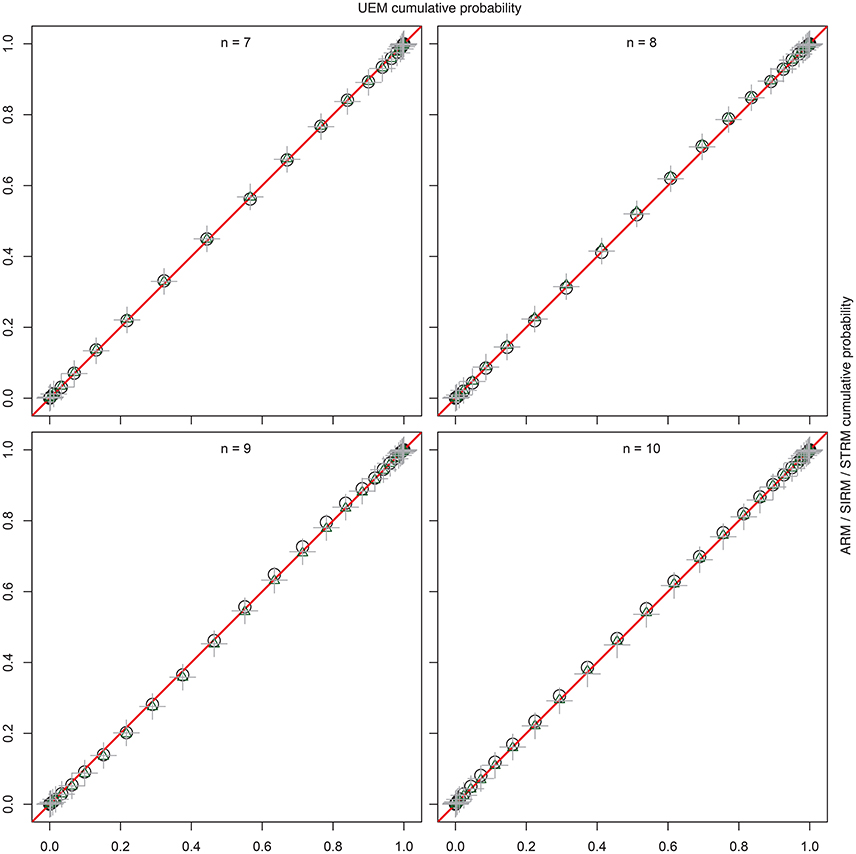
Figure 3. For item numbers n = 7, 8, 9, and 10, P-P plots are shown comparing the empirical cumulative distribution functions of the sample quasi-order sizes for the ARM, SIRM, and STRM (y-axes) to the cumulative distribution functions for the UEM as the references (x-axes). All methods were anchored with l = 2 items. The empirical cumulative distribution functions were evaluated at the potential knots or sizes 0, 1, …, n2 − n (without the reflexive item pairs). They represent mean cumulative probabilities taken over the samples (ARM, UEM: 10 trials, N = 1000; SIRM, STRM: 50 trials, N = 10, 000). The plotting symbols used for the ARM, SIRM, and STRM are unfilled black circles, unfilled green triangles, and gray plus-signs, respectively. All points fall on the comparison lines y = x (in red), which indicates that the four methods yield virtually the “same” and representative size sampling distributions.
From Figure 3, we can see that the points in the P-P plots all fall on the straight lines (in red). This indicates that the sampling methods ARM, SIRM, STRM, and UEM give virtually the “same” size distributions for quasi-orders being randomly and representatively generated by any of these methods. In particular, we conclude that the fast resampling-based SIRM and STRM methods in the studied simulation conditions yielded representative quasi-order samples by comparison with such theoretically exact, but computationally intensive, procedures as the ARM and UEM.
Under any method, the per–hundred–quasi-orders mean computing time (in s) is shown in Table 1. The time required on average was calculated over 100 trials of quasi-order samples of the size N = 100. The UEM and ARM methods are computationally intensive. This result is strikingly highlighted by the per–hundred–quasi-orders mean computing time reported for n = 13 and 14 items under the UEM in Table 1. These times were computed over five trials each of N = 1000 simulated quasi-orders.
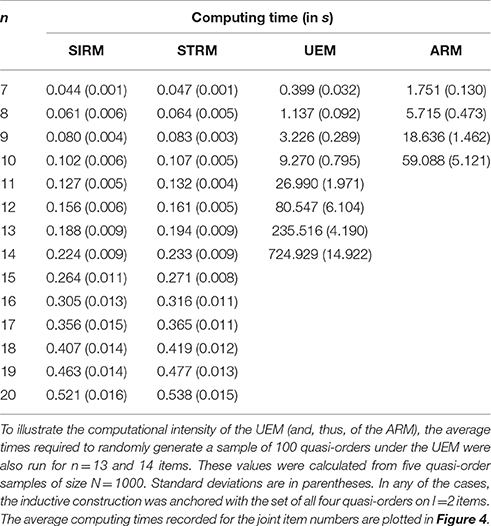
Table 1. Per–hundred–quasi-orders mean computing time (in s) calculated over 100 trials of quasi-order samples of size N = 100 for item numbers n = 7, …, 20 (SIRM and STRM), n = 7, …, 12 (UEM), and n = 7, …, 10 (ARM).
The joint results shown in Table 1 are visualized using bar plot representations in Figure 4. The juxtaposed bars depict the average computing times, in respective order, obtained for the item numbers n = 7, …, 10 under the different methods.
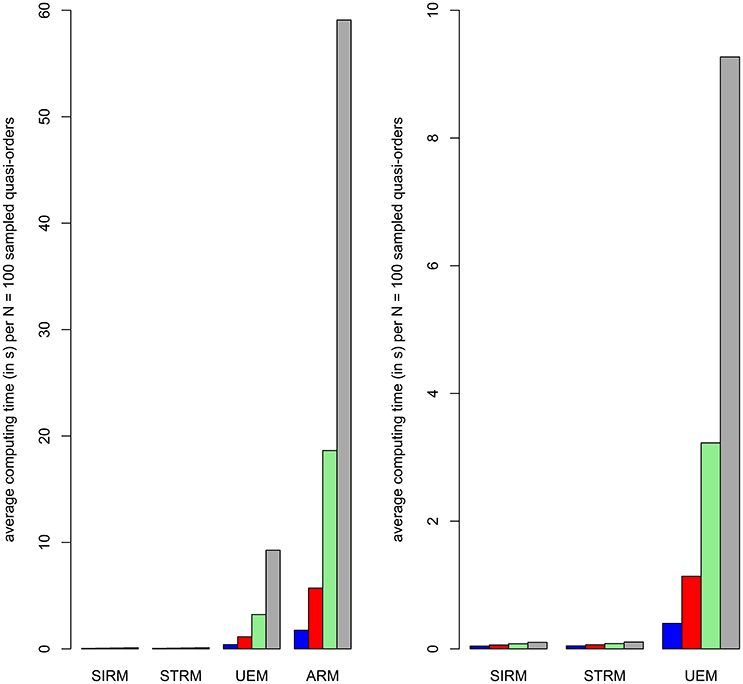
Figure 4. Bar plot representations of the average computing times (in s) for randomly generating a sample of N = 100 quasi-orders under any of the four methods (cf. Table 1). From left to right, the juxtaposed bars within a method represent the computing times obtained for item numbers n = 7, …, 10 in blue, red, green, and gray colors, respectively. The second column plot zooms in on the fast computing times achieved with the SIRM and STRM. It omits plotting the most intensive computing times required by the ARM.
As can be seen from Table 1 or Figure 4, the SIRM and STRM methods were very fast. The ARM and UEM required considerably higher computing times. Worst in this regard was the ARM, followed by the UEM. We observed that the ARM first ran into a relatively longer computing time, requiring one-and-a-half hours or more, with the item number n = 10. Such a critical threshold for the UEM was attained with n = 12 items. In this sense, the UEM may be said to be “Δn = 2 items ahead of” the ARM. Throughout the simulation studies, the SIRM and STRM methods generally gave comparable results. The time savings with the SIRM and STRM are significant. In Section 6.3, we will use these methods to construct exemplary close to representative quasi-order samples for item numbers as high as n = 20, 30, 40, and 50. Even more is conceivable. This could not be realized with any of the other approaches.
In Table 2, we catalog the five-number summaries and the means of the sizes of randomly generated quasi-orders, shown for item numbers n = 11, …, 20.
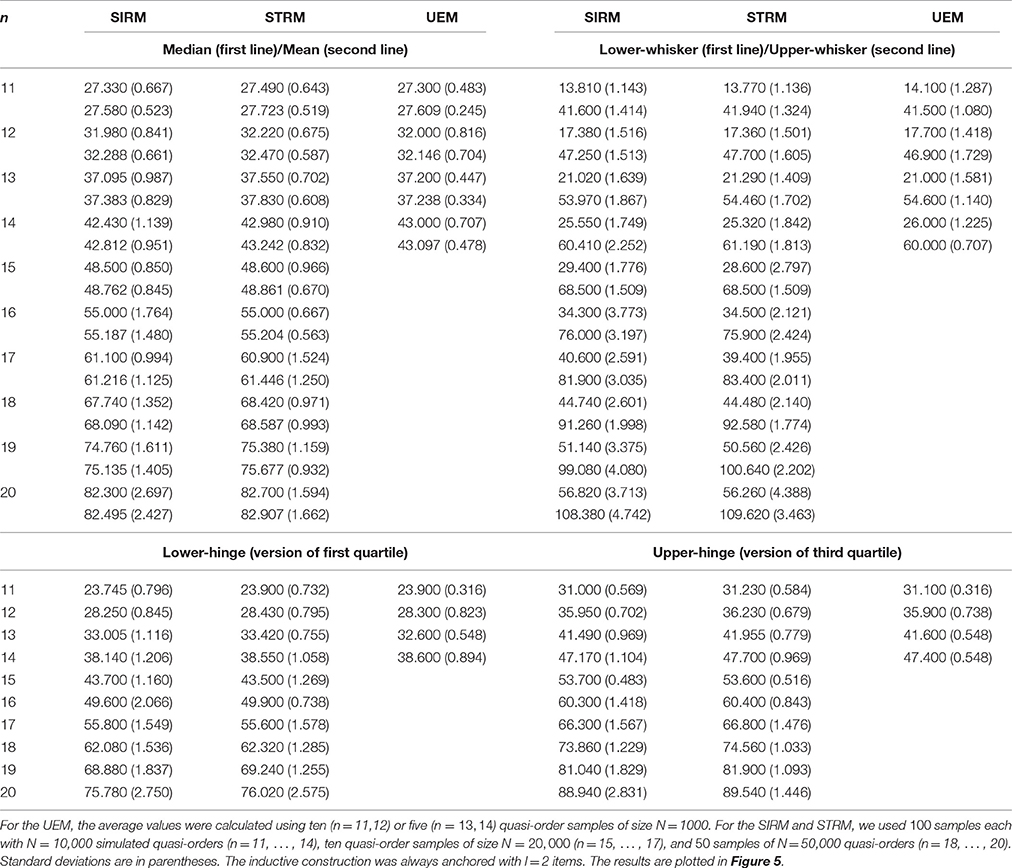
Table 2. Averaged five-number summaries (with whiskers as defined) and arithmetic means of the sizes (excluding the reflexive item pairs) of randomly generated quasi-orders for item numbers n = 11, …, 14 (UEM) and n = 11, …, 20 (SIRM and STRM).
The box plot statistics and the means reported in Table 2 are visualized in Figure 5.
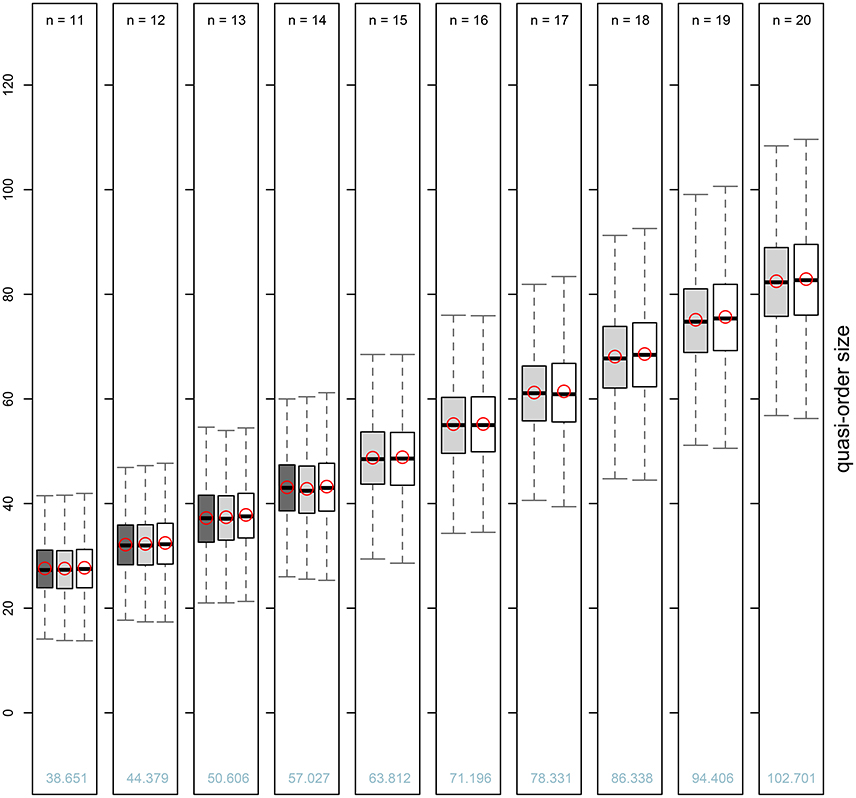
Figure 5. Box plot representations for the averaged five-number summaries and arithmetic means of the sizes of randomly generated quasi-orders (see Table 2) for item numbers n = 11, …, 14 under the UEM (dark gray boxes) and n = 11, …, 20 under the SIRM and STRM (light gray and white boxes, respectively). The “within-method” average mean values are plotted as unfilled red circles in their respective boxes. The numerical values of the “across-methods” overall means of the quasi-order sizes (including the reflexive item pairs) averaged over the SIRM and STRM are printed as light blue figures for the different item numbers.
From Table 2 or Figure 5, we can see that the fast methods SIRM and STRM yielded quasi-order samples that were close to the theoretically representative samples of the exact UEM method. The SIRM and STRM could be well matched in simulation yielding comparable results. This leads to concurrent and agreeing evidence for the representativeness of the obtained results. Compared to the whisker extremes, the location measures median and mean and the interquartile range as the spread were similar and exhibited less variation across the different methods.
In Section 6.3, the median and mean quasi-order sizes will be extended to larger item numbers. The cataloged location estimates represent useful information and may be referenced as benchmarking figures for the quick and frugal evaluation of the representativeness of candidate sets of quasi-orders. In addition, we will present scatter plots, histograms, and kernel density estimates for the nuanced visualization of the quasi-order samples obtained from the SIRM and STRM procedures.
6.3. Resampling-Based Quasi-Order Samples On up to n = 50 Items
In Table 3, we catalog the mean and median quasi-order sizes for n = 3, …, 50 items estimated under the SIRM and STRM. For each item number, one sample of N = 500, 000 quasi-orders was randomly drawn according to the SIRM and STRM. The true population values known for n = 3, …, 6 are highlighted.
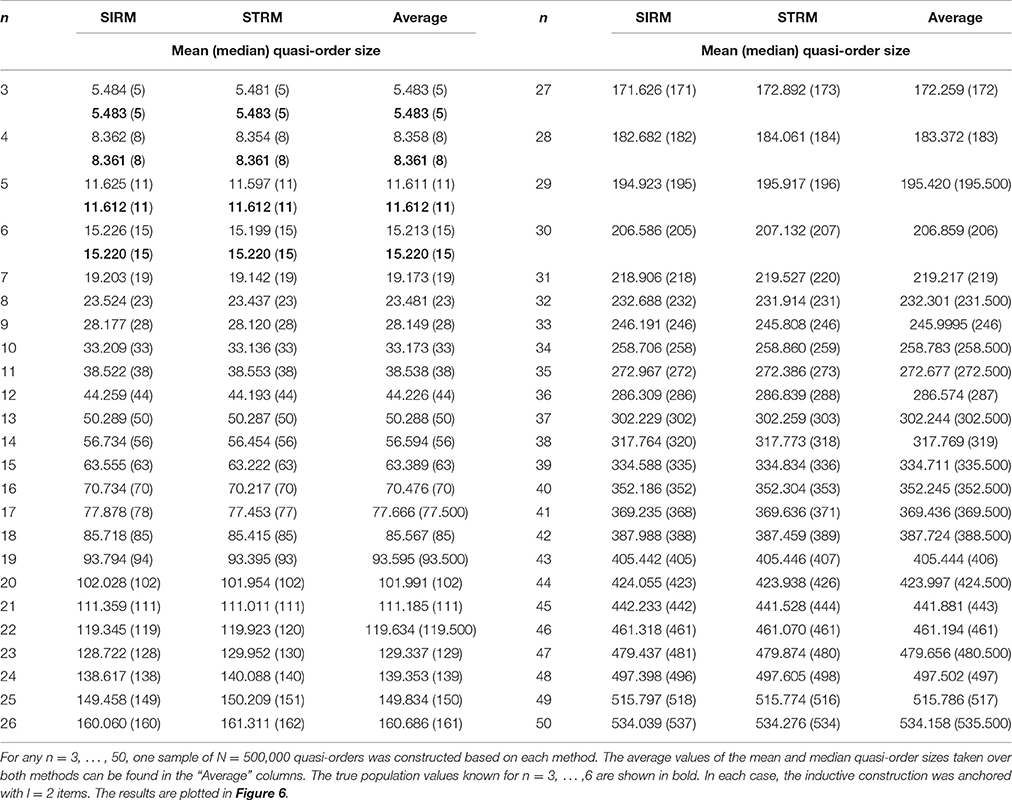
Table 3. The mean and median (in parentheses) quasi-order sizes (including the reflexive item pairs) estimated under the SIRM and STRM for item numbers up to n = 50.
With larger item numbers, we have seen substantial variability in the location estimates. Greater sample sizes or many repetitions may be necessary to control for such instability effects. These effects may particularly arise when point-estimating the population mean quasi-order sizes. However, the SIRM and STRM sampling techniques could be well matched in the simulation study, thus leading to culminating evidence. From Figure 6, we see that the mean and median values reported in Table 3 were very close or comparable. The resulting graph for the mean quasi-order size, as a function of the item number, seems to be following a quadratic polynomial function. Future research into these issues is needed (cf. Section 7).
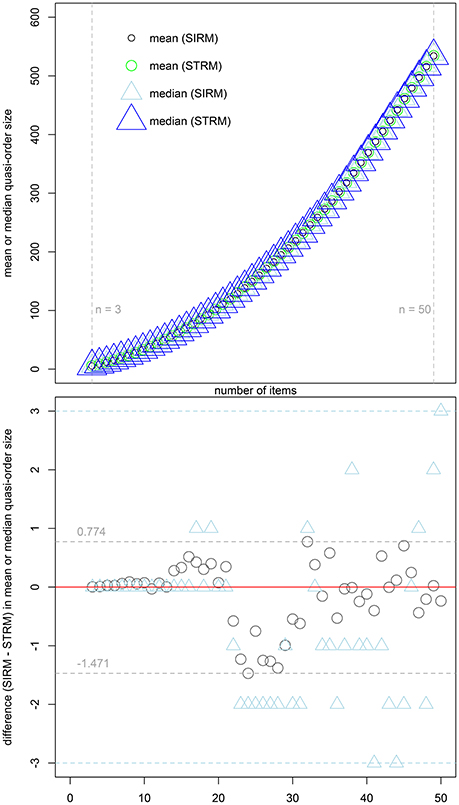
Figure 6. The first row scatter plot shows the mean quasi-order sizes (unfilled black and green circles for the SIRM and STRM, respectively) and median quasi-order sizes (unfilled light blue and blue triangles for the SIRM and STRM, respectively) as a function of item numbers n = 3, …, 50 (x-axis). The reflexive item pairs are included. The values were computed in the SIRM and STRM samples, each having half-a-million quasi-orders (cf. Table 3). The second row scatter plot zooms in to the differences in mean and median quasi-order sizes, here of values obtained under the SIRM minus the corresponding values for the STRM. The differences in mean and median are depicted as unfilled dark gray circles and unfilled light blue triangles, respectively. Their minima and maxima are represented by the horizontal dashed lines of the same colors.
Exemplarily, the quasi-order samples of the size N = 500, 000 obtained for the item numbers n = 20, 30, 40, and 50 based on the SIRM and STRM procedures were further examined. In Figure 7, we present scatter plots, histograms, and kernel density estimates for the nuanced visualization. Figure 7 is arranged in pairs of plots. The plots of a pair refer to and are labeled with the same item number n ∈ {20, 30, 40, 50}. There is a left panel of scatter plots and a right panel containing kernel and histogram density estimates. The plots have the observed quasi-order sizes placed on the x-axes. Their relative frequencies or kernel and histogram density function values are placed on the y-axes. The results for the SIRM and STRM methods are seen in gray and green shades, respectively. The solid red lines in the right panels are the (pointwise) average density functions of the two kernel density estimates under the SIRM and STRM. The mean quasi-order sizes are added as vertical dashed lines in light blue. From Figure 7, we observe that for all of the item numbers considered, the distributions of the quasi-order sizes exhibit roughly Gaussian-like curves. Thus, it can be conjectured that this may also hold true in the corresponding populations of all possible quasi-orders.
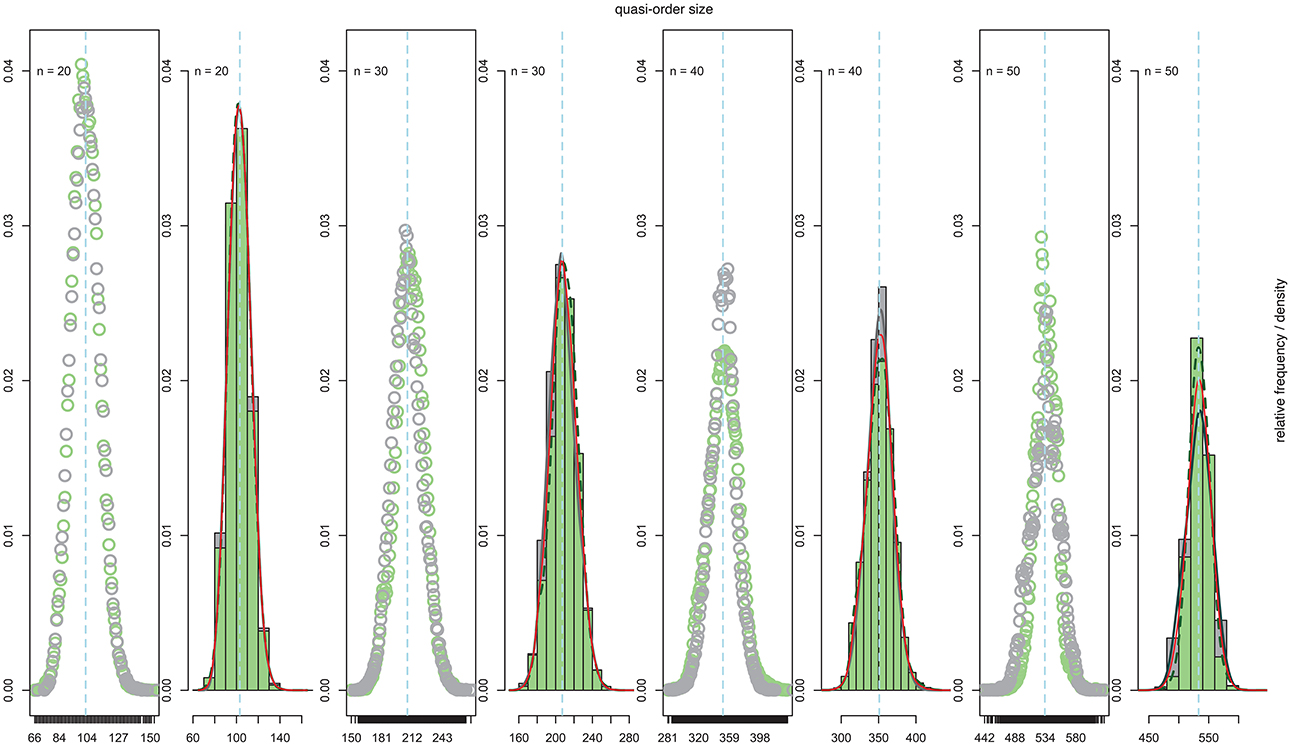
Figure 7. For item numbers n = 20, 30, 40, and 50, pairs of scatter plots (left panel) and histograms and kernel density estimates (right panel) of the sizes observed in the samples each of N = 500, 000 quasi-orders under the SIRM and STRM are presented (cf. Table 3).For all plots, duplicates were excluded. The x-axes stand for the observed quasi-order sizes (including the reflexive item pairs). Their relative frequencies or kernel and histogram density function values are placed on the y-axes. In the left panel scatter plots, the relative frequencies of the observed sizes for the SIRM method are shown in unfilled dark gray circles. For the STRM, unfilled light green circles are used. The right panel bell-shaped histograms for the SIRM and STRM are depicted in dark gray and light green colors, respectively. In the right panel kernel density representations, the Gaussian-like curves as the estimates of the size distributions under the SIRM and STRM are portrayed as solid dim gray and dashed dark green lines, respectively. The solid red lines plotted in the right panels are the graphs of the mean density functions averaged over both the SIRM and STRM kernel density estimates. The vertical dashed lines in light blue visualize the sample mean quasi-order sizes as the proxy and estimates of the true population means.
7. Conclusion
7.1. Summary and Final Remarks
This paper has investigated how to randomly construct quasi-orders on finite sets such that a notion of representativeness for the process of sampling the discrete mathematical structures can be substantiated theoretically. An envisaged random process for quasi-order sampling must be feasible practically as well. It must be applicable in realistic settings when larger sets are used. For example, this is pertinent to the study of psychological or educational tests. Tests can be structured and efficiently employed based on quasi-orders. Quasi-orders on tests can be derived using data mining algorithms. Algorithms for mining quasi-orders have to be compared based on demanding simulation studies. In particular, Schrepp and Ünlü (2015) and Ünlü and Schrepp (2015) discussed the importance of representative random quasi-order samples needed in extensive simulation studies for the reliable comparison of data mining algorithms used to reconstruct relational dependencies among behavioral test items (cf. Section 1).
We have reviewed the state-of-the-art techniques currently available for quasi-order sampling (Section 2). For item numbers not greater than n = 15, the computations become prohibitively intensive. This can be attributed to the fact that the subsets of quasi-orders become quickly sparse with larger item numbers. However, in absolute terms, the quasi-order subsets are rapidly expanding in cardinalities. This situation is coupled with yet another problem. We have observed a substantial increase in variability of the constructed quasi-orders and of the summary statistics or estimates computed from the quasi-order samples for population parameters such as the mean size. Higher variability means greater imprecision. This may cause unstable estimation results. Two sources of variability seem to be effective in the present context. There is the typical sampling variability, that is, partial sample vs. complete population. From a combinatorial perspective, a second source of variation, termed structural variability, may entail effects on the computed aggregation measures. Structural variability is viewed as arising out of the deterministic order-theoretic constraints. Here, the transitivity constraint is imposed on the quasi-order as the sampled unit and an axiomatically defined mathematical object.
Thus, a general framework for a principled sampling theory for such mathematical structures as the quasi-orders will generally differ from the well-known statistical theory of survey sampling (e.g., Cochran, 1977; Thompson, 2012). In contrast to classical surveys (e.g., in the social or political sciences), sampling mathematical structures typically includes preparatory combinatorial work. For example, we have developed the discrete doubly inductive quasi-order construction. In particular, approaches similar to the simple random and stratified sampling techniques used in surveys have not been feasible or have been lacking in the context of sampling quasi-orders. In this paper, we have introduced variants of these basic survey techniques for the quasi-orders. Conceptually, the general idea comprises two building blocks that can also be applied to other discrete structures.
First, we have developed a combinatorial algorithm for incrementally constructing potentially all quasi-orders on a finite item set (Section 3). Proposition 2 shows that for any item number, the set of quasi-orders can be partitioned into specific constructive subsets.
Second, this deterministic procedure has been obtained probabilistically by randomization in the individual construction steps (Section 4). In the outer level inductive component, we have considered uniform random extensions of the trace quasi-orders to a higher dimension. We have combined this with an inner level inductive component to combinatorially correct the extensions that violate transitivity. The inner level deterministic corrections entail sampling biases. According to Proposition 4, the bias correction factors required for representative sampling can be derived.
Based on the correction factors, we have introduced three techniques for sampling quasi-orders (Section 5): the absolute rejection method (ARM), the simple resampling method (SIRM), and the stratified resampling method (STRM). These techniques have been compared with the uniform extension method (UEM) by Schrepp and Ünlü (2015). Analogous to the representativeness result for the UEM, Proposition 5 shows that for any item number, the bias-corrected hierarchical ARM procedure yields simple random sampling from the population of all quasi-orders. In extensive simulation studies (Section 6), we have demonstrated the usefulness of the sampling techniques for representative quasi-order generation. However, the ARM and UEM methods represent theoretical results. They become computationally intensive when larger item numbers are tried. We have seen that the conservative critical threshold for the ARM and UEM were n = 10 and n = 12 items, respectively. In contrast, the SIRM and STRM are the recommended procedures. They can be used with significantly higher item numbers. Within acceptable computing time, the SIRM and STRM methods have provided close to representative random quasi-orders on up to n = 50 items.
There are other characteristics than size that could be used to compare how representative the samples are. In Schrepp and Ünlü (2015), the quasi-order width (i.e., size of a longest anti-chain) and height (i.e., size of a longest chain) were used as the evaluation criteria to assess representativeness for the UEM method. Representativeness according to Definition 1 is assumed for arbitrary quasi-orders. Thus, we may infer that such a representative quasi-order sample will be unbiased for the population distributions of these and any other characteristic. In particular, based on the comparisons made of the SIRM and STRM with the UEM and ARM, we expect similar results for the evaluation criteria. As an example, for a set of n = 6 items, we compared representativeness for the UEM, ARM, SIRM, and STRM based on the quasi-order characteristics width, height, number of maximal elements (i.e., elements not in relation to any other element), and number of minimal elements (i.e., elements which no other element is in relation to). The average values are reported for 100 samples each of N = 1000 simulated quasi-orders.
The true mean values in the population of all quasi-orders on n = 6 items are 2.624 (width), 3.625 (height), and 1.899 (number of maximal elements = number of minimal elements). In respective order, for the UEM, the values (standard deviations in parentheses) are 2.626 (0.033), 3.623 (0.044), 1.898 (0.038), and 1.902 (0.046). For the ARM, we have 2.624 (0.032), 3.628 (0.040), 1.894 (0.041), and 1.900 (0.043), respectively. The respective values obtained under the SIRM are 2.623 (0.068), 3.619 (0.083), 1.899 (0.074), and 1.890 (0.087). The STRM yields 2.622 (0.069), 3.624 (0.076), 1.900 (0.076), and 1.896 (0.080), respectively.
7.2. Further Research
What are interesting directions for future research? The SIRM and STRM sampling techniques were evaluated based on simulation. Theoretical work may study the probability theory foundation of these methods and of their interrelationship. With a finite sample size, the SIRM and STRM methods are approximate. Thus, further research may aim to investigate the large-sample or asymptotic properties of these resampling-based techniques. This could include quantifying the quality of approximation to representativeness and the development of related diagnostic error terms.
Variability reduction and the investigation of interval estimation techniques in the context of sampling quasi-orders are interesting directions for future research. Moreover, we have seen that the resulting graph for the mean quasi-order size, as a function of the item number, may be quadratic polynomial. We have also observed that the distributions of the quasi-order sizes are roughly bell-shaped. More in-depth analyses of these issues are needed.
Eventually, the discussion could be generalized to other combinatorial structures, which could include unlabeled (equivalence classes of) isomorphic quasi-orders and such special cases as weak, partial, or linear orderings.
Author Contributions
AÜ conceived the mathematical theory. AÜ and MS designed the software used in analysis. AÜ and MS wrote the paper. All the authors (AÜ and MS) reviewed the manuscript, approving the final version of the paper prior to submission.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^If we take the transitive closure of a rejected random reflexive relation, the result is a quasi-order. This modified entry-wise uniform sampling approach represents an ad hoc strategy. Although flexible, it lacks representativeness.
The impact of forming the transitive closure of a random relation on the notion of representativeness, to our knowledge, seems to be an interesting and open problem for further research. Note that this problem cannot be answered with the current paper. The transitive closure used to correct for transitivity is different from the inductive correction procedure introduced in Section 4.1. The transitive closure is the most parsimonious extension of a relation that additionally contains all indirectly accessible transitive pairs. The procedure , however, can add and/or remove pairs according to the specific inductive routine to obtain transitivity. Thus, it is not obvious how a similar discussion can be elaborated for the transitive closure as a correction operator.
2. ^For any k = 1, …, n, if the condition C1(k) holds true, we call the value 1 admissible for the entry rk, n+1. Similarly, for any k = 1, …, n, if C2(k) is satisfied, 0 is admissible for rk, n+1.
In particular, C1(k) and C2(k) can be interpreted as follows. When filling an entry rk, n+1 at the kth position, only the previously filled entries at the positions 1, 2, …, k − 1 of the (n+1)th column are relevant. The possible values that may be chosen for the remaining unfilled entries of the added (n+1)th column and (n+1)th row need not be considered.
For k = 1, the anchoring, C1(k = 1) and C2(1) are trivially satisfied. Thus, 0 and 1 are admissible for r1, n+1. In the construction process, r1, n+1 must take both values for the procedure to yield all of .
3. ^Analogous to the top-down component, the three conditions can be interpreted as follows. For filling the entries rn+1, k of the row n+1, only knowledge of the previously filled entries is relevant. Here, the previously filled entries are rn+1, i for i = k + 1, …, n in the (n+1)th row [conditions R1b(k) and R2(k)] and ri, n+1 for i = 1, …, n in the (n+1)th column [condition R1a(k)].
4. ^Note that with this procedure, we randomize the values filled into the positions r1, n+1, …, rn, n+1, rn+1, n, …, rn+1, 1, but not the order in which these positions are filled. A randomized order approach would probably make impossible the exhaustive discrete construction or would complicate the probabilistic extension. In the latter case, it may be difficult to correct for transitivity, and thus accompanied by induced sampling biases, even more intricate to determine the required bias correction factors. In Proposition 4, we will see that this is possible, and relatively straightforward, for the fixed order approach of this paper.
References
Brinkmann, G., and McKay, B. D. (2002). Posets on up to 16 points. Order 19, 147–179. doi: 10.1023/A:1016543307592
Brinkmann, G., and McKay, B. D. (2005). Counting unlabelled topologies and transitive relations. J. Integer Seq. 8, 1–7.
Doignon, J.-P., and Falmagne, J.-C. (1985). Spaces for the assessment of knowledge. Int. J. Man Mach. Stud. 23, 175–196. doi: 10.1016/S0020-7373(85)80031-6
Doignon, J.-P., and Falmagne, J.-C. (1999). Knowledge Spaces. Berlin; Heidelberg: Springer. doi: 10.1007/978-3-642-58625-5
Falmagne, J.-C., Albert, D., Doble, C., Eppstein, D., and Hu, X. (eds.) (2013). Knowledge Spaces: Applications in Education. Berlin; Heidelberg: Springer. doi: 10.1007/978-3-642-35329-1
Falmagne, J.-C., and Doignon, J.-P. (2011). Learning Spaces. Berlin; Heidelberg: Springer. doi: 10.1007/978-3-642-01039-2
Sargin, A., and Ünlü, A. (2009). Inductive item tree analysis: corrections, improvements, and comparisons. Math. Soc. Sci. 58, 376–392. doi: 10.1016/j.mathsocsci.2009.06.001
Schrepp, M. (1999). On the empirical construction of implications between bi-valued test items. Math. Soc. Sci. 38, 361–375. doi: 10.1016/S0165-4896(99)00025-6
Schrepp, M. (2002). Explorative analysis of empirical data by boolean analysis of questionnaires. Zeitschrift für Psychol. 210, 99–109. doi: 10.1026/0044-3409.210.2.99
Schrepp, M. (2003). A method for the analysis of hierarchical dependencies between items of a questionnaire. Methods Psychol. Res. Online 19, 43–79.
Schrepp, M. (2006). ITA 2.0: a program for classical and inductive item tree analysis. J. Stat. Softw. 16, 1–14. doi: 10.18637/jss.v016.i10
Schrepp, M., and Ünlü, A. (2015). On the creation of representative samples of random quasi-orders. Front. Psychol. 6:1791. doi: 10.3389/fpsyg.2015.01791
The R Core Team (2016). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Ünlü, A., and Sargin, A. (2010). DAKS: an R package for data analysis methods in knowledge space theory. J. Stat. Softw. 37, 1–31. doi: 10.18637/jss.v037.i02
Ünlü, A., and Schrepp, M. (2015). Untangling comparison bias in inductive item tree analysis based on representative random quasi-orders. Math. Soc. Sci. 76, 31–43. doi: 10.1016/j.mathsocsci.2015.03.005
Keywords: discrete doubly inductive quasi-order construction, simple random sampling, stratified sampling, absolute rejection, resampling, item tree analysis, knowledge or learning space theory, representative random quasi-order
Citation: Ünlü A and Schrepp M (2016) Toward a Principled Sampling Theory for Quasi-Orders. Front. Psychol. 7:1656. doi: 10.3389/fpsyg.2016.01656
Received: 30 May 2016; Accepted: 10 October 2016;
Published: 29 November 2016.
Edited by:
Pietro Cipresso, Istituto Auxologico Italiano (IRCCS), ItalyCopyright © 2016 Ünlü and Schrepp. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ali Ünlü, ali.uenlue@tum.de