Dynamic coverage control in unicycle multi-robot networks under anisotropic sensing
 Dimitra Panagou
Dimitra Panagou Dušan M. Stipanović
Dušan M. Stipanović Petros G. Voulgaris3
Petros G. Voulgaris3
- 1Department of Aerospace Engineering, University of Michigan, Ann Arbor, MI, USA
- 2Coordinated Science Laboratory, Department of Industrial and Enterprise Systems Engineering, University of Illinois at Urbana-Champaign, Champaign, IL, USA
- 3Coordinated Science Laboratory, Department of Aerospace Engineering, University of Illinois at Urbana-Champaign, Champaign, IL, USA
This paper considers dynamic coverage control for non-holonomic agents along with collision avoidance guarantees. The novelties of the approach rely on the consideration of anisotropic sensing, which is realized via conic sensing footprints and sensing (coverage) functions for each agent, and on a novel form of avoidance functions. The considered sensing functions encode field-of-view and range constraints, and also the degradation of effective sensing close to the boundaries of the sensing footprint. Thus, the proposed approach is suitable for surveillance applications where each agent is assigned with the task to gather enough information, such as video streaming in an obstacle environment. The efficacy of the approach is demonstrated through simulation results.
1. Introduction
Mobile sensor and robotic networks have been of major research interest during the past decade, in part due to their usefulness in applications ranging from surveillance and monitoring, to situational awareness, to tasks involving industrial and domestic robots (e.g., for painting, floor cleaning, lawn mowing). A mobile sensor or robotic network is typically realized as a group of agents, which are characterized by local sensing capabilities and which need to collaborate to achieve a global objective, often addressed as coverage.
Coverage is typically classified into static coverage control and dynamic coverage control. The static coverage control problem mainly addresses the optimal placement of sensors to cover a region and reduces to finding control laws, which deploy mobile sensing agents to the centroids of Voronoi cells in a Voronoi partitioning of a given domain (Cortes et al., 2004; Cheng and Savkin, 2010; Ferrari et al., 2010; Schwager et al., 2011; Zhong and Cassandras, 2011). On the contrary, the term dynamic coverage control has traditionally been used to describe problems where a group of mobile sensing agents is deployed to search an area sufficiently well over time, see, for instance, Hokayem et al. (2007), Hussein and Stipanovic (2007), Atinç et al. (2013), and Stipanovic et al. (2013) and the references therein. The main concept, which realizes sufficient (or effective) coverage, is a parameter C⋆, which is associated with the amount of time that a sensing agent should spend on every point of the area. One common thread in earlier work on dynamic coverage is the consideration of isotropic sensing for each agent, which is realized as a bell-shaped sensing function over a circular sensing footprint. Nevertheless, although this model is suitable for agents carrying sensors such as laser range finders, it is not pertinent for agents with onboard cameras.
This paper is in part motivated by surveillance applications where vision is the main means of sensing and information gathering and addresses dynamic coverage for multiple non-holonomic agents along with collision avoidance guarantees. We extend our earlier work (Stipanovic et al., 2013) by considering a new dynamic coverage and avoidance control design, which can be implemented in a decentralized fashion. The main difference here is the consideration of (i) anisotropic sensing, realized via conic sensing footprints and conic sensing (coverage) functions for each agent, and (ii) a novel form of avoidance functions. The considered sensing functions encode field-of-view and range constraints, and furthermore the degradation of effective sensing close to the boundaries of the sensing footprint. In this spirit, the proposed control design is suitable for surveillance tasks, where a group of robots is assigned with the task to gather enough information about an environment (such as video streaming or snapshots) locally, while avoiding collisions. More specifically, the considered scenario in this paper addresses the case of non-holonomic robots, each one carrying a forward-looking camera of limited angle-of-view and a rear proximity sensor, such as a laser scanner. Each robot is thus capable of detecting objects both in the forward and the backward looking direction, and more specifically, objects lying within the finite conic sensing footprints dictated by the available sensor limitations. The dynamic coverage control is defined as ensuring that each point of a domain of interest is sensed by the forward-looking sensing footprint of at least one agent (that is, the same point may be sensed by more than one agent) for a sufficient amount of time. A coverage error function encoding this objective is defined for each agent, and control laws, which guarantee that this error is driven to zero, are designed. The local encoding of coverage capability through the adopted error function implies that agents may stop moving before the entire domain has been sufficiently covered. For this reason, a supervisory logic is additionally implemented; this is realized as the exchange of information among agents regarding their individually covered areas, so that at least one agent has knowledge of the entire coverage map, and the selection of waypoints in the uncovered area toward, which the agents are forced to move after their individual coverage errors have become arbitrarily close to zero. The implementation for the supervisory logic is based on Atinç et al. (2013) and further refined to the conic sensing and coverage models considered here. Avoidance is considered only pairwise in this paper, and is implemented through novel avoidance functions, which are compatible with the available conic sensing footprints. Extending this encoding to multi-robot avoidance control is currently ongoing work.
The consideration of anisotropic sensors for coverage control problems has been also considered in Gusrialdi et al. (2008a,b), Laventall and Cortes (2008), and Hexsel et al. (2013); however, these contributions refer to static coverage problems, i.e., to agents covering areas in a deployment sense, and therefore are not relevant to the dynamic coverage formulation presented here. To the best of our knowledge, the most relevant work to this paper is Franco et al. (2012), which addresses vision-based dynamic coverage for mobile robots. Yet, the current paper differs in the sensing modeling, which is realized via a novel form of conical functions, as well as in the proposed coverage and avoidance control strategies, which here are based on novel coverage and avoidance functions.
A shorter version of this paper appeared in Panagou et al. (2014). The current version includes the complete technical analysis on the considered control design, which is omitted in the conference version in the interest of space, and additionally presents a way of addressing the “global” coverage objective via a supervisory logic, which eliminates the limitations of the “local” dynamic coverage control design. The difference between global and local coverage will become clear in later sections.
The paper is organized as follows: Section 2.1 describes the system modeling along with the sensing constraints and functions. Sections 2.2 and 2.3 include the novel formulations regarding the (local) coverage and collision avoidance control, while the technical analysis on the proposed control strategies is presented in Section 2.3.3. Simulation results are reported in Section 3, along with a way of addressing the global coverage objective. Section 4 summarizes our results and thoughts on future research, followed by some pertinent acknowledgments.
2. Materials and Methods
2.1. Problem Formulation
Consider a group of N mobile agents, whose motion is governed by unicycle kinematics:
where i ∈{1, , N}, pi = [xi yi]T is the position vector and θi is the orientation of an agent i (w.r.t) a global coordinate frame , and ui, ωi are the linear and angular velocities of agent i, respectively (w.r.t), the body frame . Denote the state vector of agent i.
Each agent is assumed to be equipped with a fixed onboard camera of limited angle-of-view and furthermore to be able to detect objects, which lie within a limited region (w.r.t) the forward-looking direction. The limited sensing region of agent i is realized as a circular sector of angle 2αi and radius Ri, where Ri > 0, αi ∈ (0, π/2) (Figure 1).
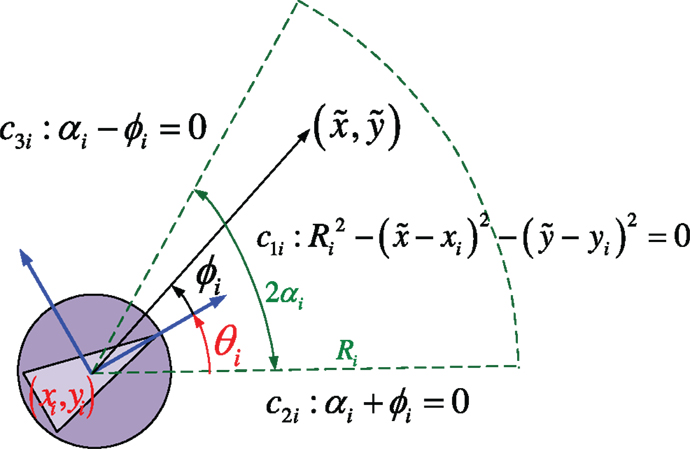
Figure 1. The forward-looking sensing footprint for agent i.
Furthermore, each agent is assumed to have a rear proximity sensor, whose sensing footprint is for simplicity modeled as the symmetric circular sector of (w.r.t) the body-fixed axis of agent i. In that respect, each agent i is able to detect objects lying within a limited range in the backward direction as well. The role of the rear proximity sensor is to ensure that each agent i is able to detect and avoid objects (obstacles and other agents j ≠ i) when forced to move backwards.
2.1.1. Modeling of conic sensing footprints
Consider the functions defined as:
where k ∈ {1, 2, 3}, is the position vector of a point on , pi(t) = [xi(t) yi(t)]T is the position vector, and θi(t) is the orientation of agent i at time instant t, and
is the angle of a point (w.r.t) the body frame Bi of agent i at time instant t. The region of the state space where all functions equation (2) take non-negative values encode a circular sector of radius Ri and angle 2αi centered at pi(t). This circular sector models the forward-looking sensing footprint for agent i (Figure 1). For simplicity, in the sequel, we assume that all agents have the same sensing capabilities, i.e., that Ri = R, αi = α.
Let us now note that the barrier function:
tends to +∞ as the k-th constraint cki → 0+, i.e., as a point on the interior of the set approaches the boundary of . To keep notation compact, denote max{0, cki} = Cki, k ∈ {1, 2, 3}, and consider the function:
which is zero on the exterior of the sensing footprint , zero on the boundary except for at the points where any two of the constraints cki are concurrently zero, and positive on the interior of . Furthermore, equation (4) tends to zero as the k-th constraint cki → 0+ (Figure 2). We define that the sensing function is zero at the points where any two of the constraints are active at the same time.
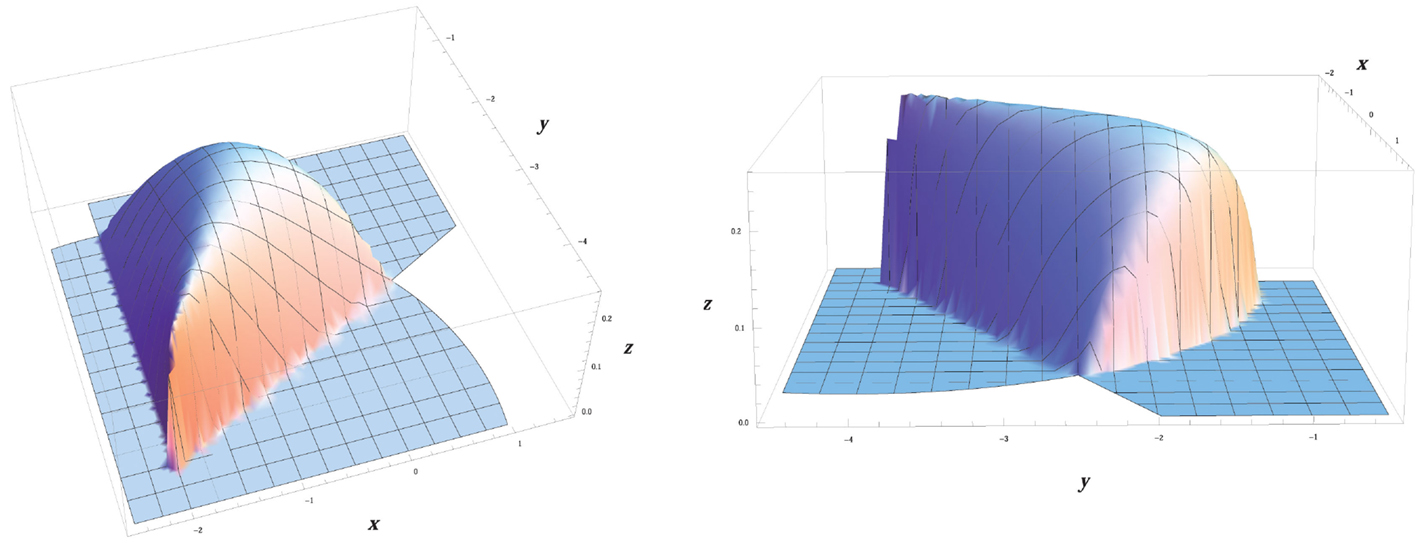
Figure 2. The considered sensing model Si(t) for agent i, given by equation (9). The agent is positioned at pi = | − 2 − 4|T and its orientation is θi = π/3.
In this respect, the function Si can be used as a realistic modeling of the available sensing capability, in the sense that the quality of sensing typically degrades as an object lies far from the camera or close to the boundaries of the camera angle-of-view. In other words, the function Si encodes that sensing of objects (or, in other words, “seeing”) becomes less effective as these lie closer to the boundaries of the sensing footprint of agent i.
Following our earlier work (Stipanovic et al., 2013), the sensing function for the i-th agent is defined:
Let us also define the function h(w) = (max{0, w})3, so that its first derivative reads: h′ = dh/dw = 3(max{0, w})2, and its second derivative reads: h″ = d2h/dw2 = 6(max{0, w}).
2.2. Coverage Control
Given a compact region D, we are interested in deriving control strategies, which guarantee that the agents cover (or search) the whole region up to a satisfactory level. In other words, the term satisfactory coverage denotes that each point of D should be sensed by at least one agent for a sufficient amount of time. In order to mathematically capture the notion of satisfactory coverage, we use a positive constant C⋆. The value of this constant is chosen depending on how well we would like to search the area; more specifically, larger values of C⋆ are meant to force each agent to spend more time sensing each point on the domain.
2.2.1. Coverage error function
The coverage error for the i-th agent is defined as:
where D is the compact region to be covered and C⋆ is the positive constant realizing the satisfactory coverage level. A meaningful choice of the value C⋆ is to pick C⋆ ≥ t max Si, where t is the least amount of time that an agent needs to spend on each point of the domain D and max Si is the maximum value of the sensing function equation (4). The time derivative of equation (6) reads:
Remark 1. In general, the derivative of the area integral
of a function over a compact region D(t), which is bounded by a closed curve C(t), which is continuous and consists of smooth arcs, is given as:
where:
with the integration performed along the counterclockwise direction. It can be shown that for the considered sensing function which is exactly zero almost everywhere on the boundary C(t), the term I(t) is zero. This justifies why the term involving the line integral has been dropped in equation (7). The same holds later on for the time derivative equation (9) of the modified error function equation (8).
As discussed in Stipanovic et al. (2013), the use of equation (7) as a candidate Lyapunov-like function for guaranteeing the accomplishment of satisfactory coverage is not a good choice, in the sense that this function may become zero when the Si(⋅) term becomes zero, and this condition may occur, for instance, when agent i leaves the domain D. Thus, the following modified error function is utilized instead as a Lyapunov-like function:
where S⋆ > N max Si a positive constant; this functional is negative and vanishes when the term becomes zero, i.e., only when the satisfactory coverage level C⋆ for a point has been achieved. The time derivative of equation (8) reads as in equation (9),
and is further rewritten as:
where:
As the functional equation (8) is non-positive, it follows that for the error converging to zero, it suffices that its time derivative is non-negative (Stipanovic et al., 2013).
Theorem 1. If agent i moves under the control law:
where then the modified coverage error equation (8) converges to zero. This in turn implies that the coverage error ei(t) defined by equation (6) converges to zero.
Proof. Under the control law equation (11), the time derivative equation (10) of the modified error function equation (8) is non-negative; as explained earlier, this implies that equation (8) is non-decreasing.
Denote int() the interior of the set , the boundary of the set , the closure of the set , and the exterior of the set . Since , one has:
Thus, the control inputs equations (11a) and (11b) vanish on the set
which further reads that the control inputs equations (11a) and (11b) vanish on the set , where:
The set reads:
This further reads that the control law equation (11) vanishes on the set 1, which contains the points for which the effective coverage level C⋆ has been reached, or equivalently that the control law equation (11) vanishes when the coverage error equation (6) becomes zero.
Remark 2. This physically means that agent i does not stop moving unless at some time t it holds that all the points , which are contained in the interior of the sensing footprint at time t have been effectively covered.
Let us now consider the set 2. The first condition in 2 reduces to the set
Furthermore, the concurrent satisfaction of the second condition reduces to the subset of Ai described as
where . Geometrically, this condition describes the set of points where the gradient vector ∂Si/∂pi is orthogonal to the body-fixed axis of agent i, or the set of points where ∂Si/∂pi = 0. Let us take the analytical expression of the gradient vector ∂Si/∂pi evaluated at the points that is, for ϕi = 0, which reads . This implies that ∂Si/∂pi ≠ 0 on the set Ai (recall that the point belongs to the boundary , i.e., not the interior of the set ), and furthermore that the gradient ∂Si/∂pi on is co-linear with, i.e., can not be orthogonal to, the body-fixed axis . Consequently, one has that , which implies that , hence . Thus, the control law equation (11) ensures that the coverage error ei(t) equation (6) converges to zero, which furthermore reads that the agent does not stop moving before all the points have been effectively covered. This completes the proof.
Remark 3. The coverage error ei(t) equation (6) encodes whether agent i has effectively covered the area included in the sensing footprint only, i.e., it does not provide any measure on whether the entire domain D has been effectively covered. Furthermore, the control law equation (11) vanishes when all the points have been effectively covered, which means that the agent stops moving before the entire domain D has necessarily been covered. Coverage of the entire area requires the use of a supervisory logic, which is presented in Section 3.
Remark 4. The control law equation (11) depends on the current state of each agent i, only. In other words, it requires information, which is locally available to each agent i, and as thus it can be implemented in a decentralized fashion.
2.3. Avoidance Control
The safety requirement for the robotic network dictates that each agent i should avoid collisions with any other agent j ≠ i, where i, j ∈ {1, , N}, and with any physical static obstacles in the domain D.
2.3.1. Avoidance functions
The avoidance control between agents i and j has been encoded in Stipanovic et al. (2013) via functions of the form:
where Rij > rij > 0. These functions’ development was motivated by the concept of avoidance control, which was introduced and further developed by Leitmann and Skowronski (1977, 1983), Leitmann (1980), Corless et al. (1987), and Corless and Leitmann (1989). The function equation (12) encodes:
(i) a safety circular region of radius rij centered at the position pi = [xi yi]T of agent i, in which agent j should never enter, and
(ii) a detection circular region of radius Rij centered at pi = [xi yi]T, which models the footprint of sensors such as omni directional laser scanners or range finders.
In the sequel, it is considered that all agents have homogenous detection and safety regions, i.e., Rij = R, rij = r, . Define the vector pij : = pi − pj and denote with ||⋅|| the standard Euclidean norm. The function vij is zero for ||pij|| > R, i.e., when agent j lies out of the detection region of agent i, and tends to +∞ as ||pij|| tends to r, i.e., as agent j tends to the safety region of agent i. For reasons that will become clear later on, we consider the scaled function:
so that Vij takes its values in the interval (0,1), see also Figure 3.
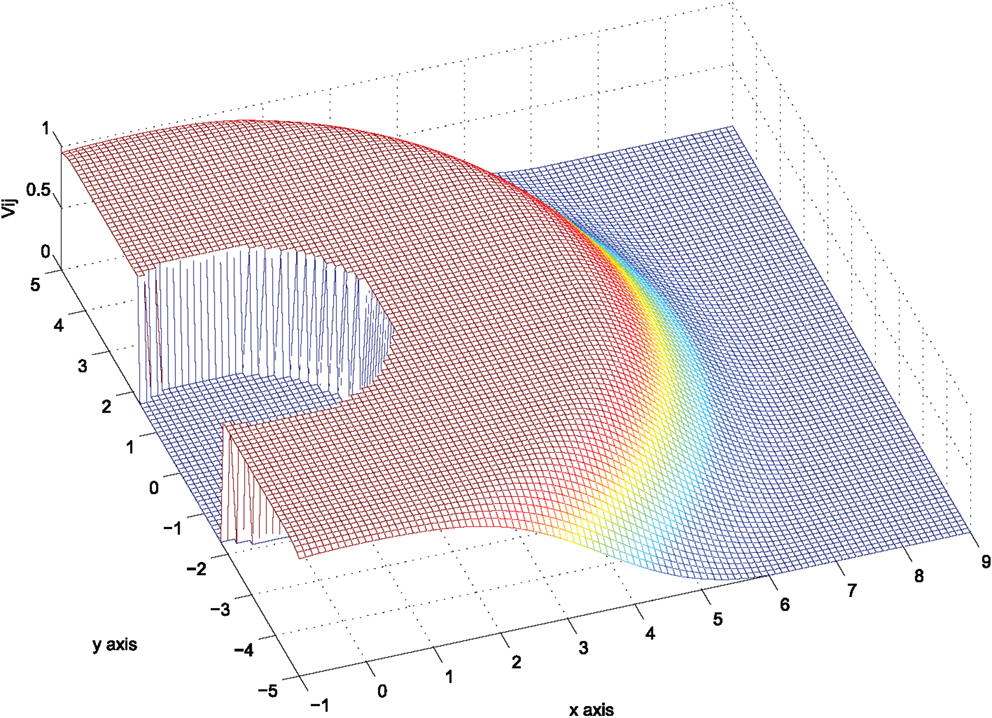
Figure 3. The avoidance function Vij given by equation (13).
The gradient of equation (12) (w.r.t), the state vector reads:
whereas the gradient of equation (12) (w.r.t), the state vector reads:
. Let us note that:
2.3.2. Encoding collision avoidance
Avoiding collisions should be encoded in a way consistent with the available sensing constraints. Each agent i is assumed to be capable of detecting objects (static obstacles and other agents j ≠ i), which lie in its sensing area and therefore the motion of agent i should be collision-free (w.r.t) any object lying within (Figure 4).
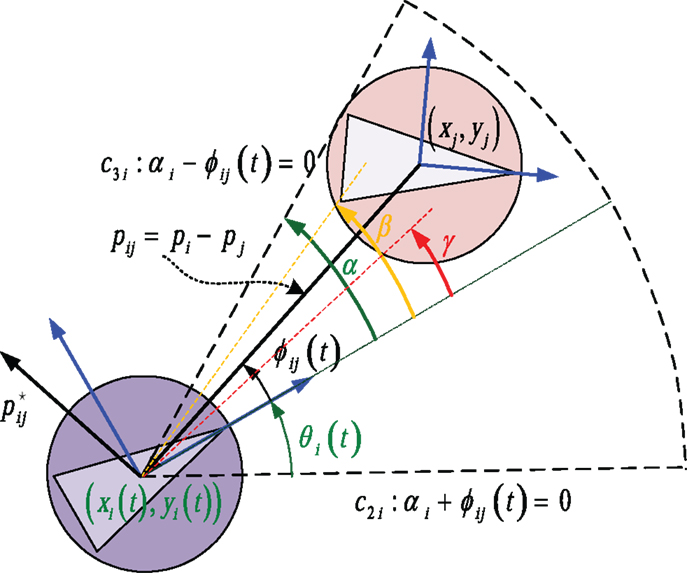
Figure 4. An agent j is effectively sensed by agent i only when it enters in the sensing area of agenti.
To this end, we not only need to encode that an agent i should keep a safe distance ||pij|| ≥ r (w.r.t) an agent j ≠ i but also to encode that this requirement takes effect only for agents j lying in the sensing area of agent i. Assume that an agent j has entered the region . The active constraint function c3 i: α − ϕij(t) = 0, where
encodes that agent j lies on the boundary of at the time instant t and becomes visible to agent i. A meaningful maneuvering for agent i could be then to move so that agent j gets out of . We thus consider the angle 0 < β < α and penalize the position trajectories pj(t) = [xj(t) yj(t)]T of agent j from approaching the interior of the set where the angle |ϕij(t)| has value less than β. To this end, we take:
and, in a similar spirit to the definition of the avoidance function equation (12), define the function:
The function wij is: (i) zero for |ϕij| ≥ α i.e., on the exterior of the set , (ii) positive when the second argument in the minimum function gets negative values, i.e., for β < |ϕij| < α, and (iii) tends to +∞ as |ϕij| tends to β. In this sense, it can be used as a Lyapunov-like function encoding that the value of the angle trajectories |ϕij(t)| should always remain greater than β.
The gradient of equation (16) (w.r.t), the state vector reads:
whereas the gradient of equation (12) (w.r.t), the state vector reads:
where . Note that:
Again, we take the scaled function:
so that Wij takes its values in the interval (0,1), see Figure 5.
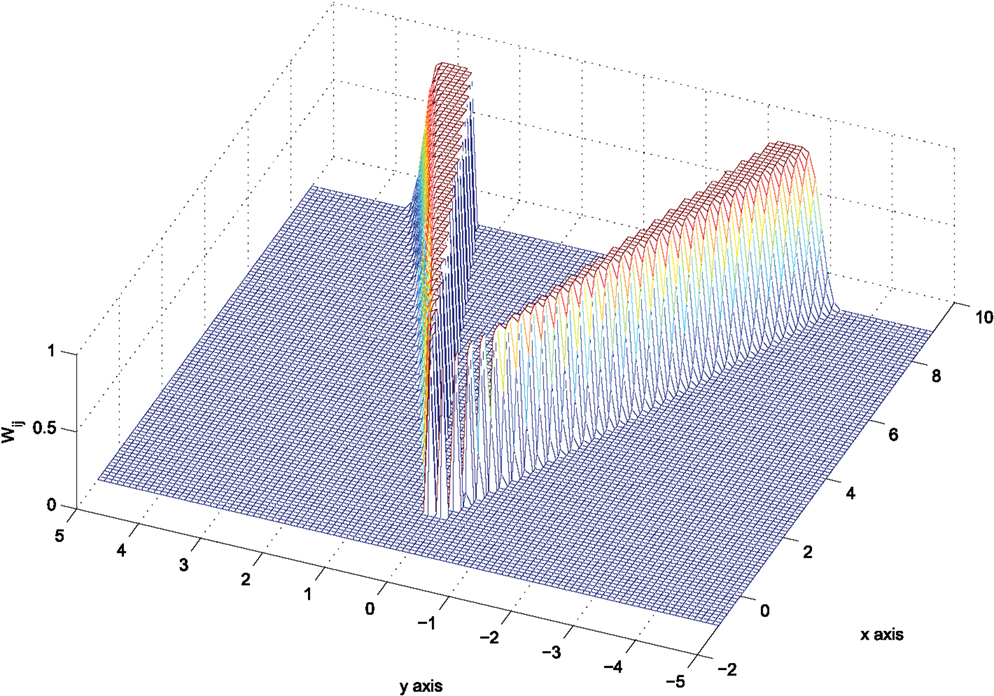
Figure 5. The function , given by equation (19).
In order to combine equations (13) and (19) into a single function that varies between zero and one, define:
which vanishes when at least one of the functions in equation (13), equation (19) vanishes, and varies in (0,1) anywhere else. However, this function does not penalize system trajectories with |ϕij(t) < β| from tending to ||pij|| = r, or in simpler words, it does not encode that agent i maintains a safe distance ||pij|| > r (w.r.t) agent j when |ϕij(t) < β|. For this reason, we consider the function:
and encode the transition between the functions Pij, Vij as:
This function now encodes that for |ϕij| < β one has σij = 0 and as thus Aij = Vij. This further reads that the term equation (13) is active in this region of the state space, rendering the desirable avoidance objective. The function equation (22) is depicted in Figure 6 for agent i positioned at pi = [0 0]T with θi = 0.
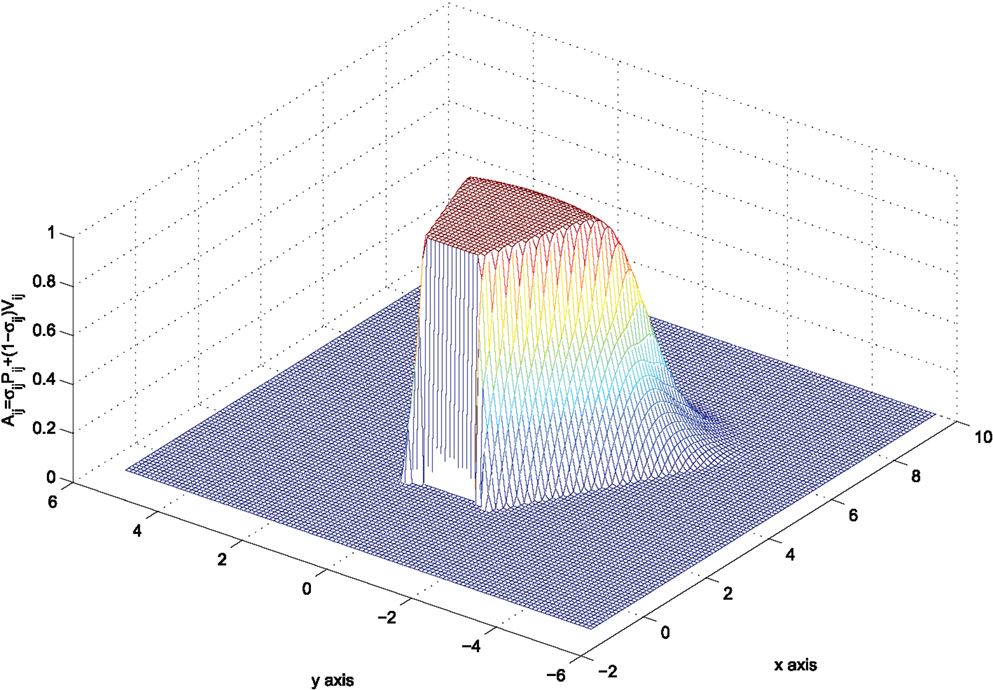
Figure 6. The avoidance function Aij given by equation (22).
The bump function equation (21) defines three regions in the state space of agent i, in which the expression of equation (22) reads:
It can be easily verified after some algebraic calculations that: . Then, making use of equations (15) and (18), it is straightforward to verify that the following symmetry relation between the gradient vectors of Aij (w.r.t), the position vectors pi and pj holds everywhere:
Of course, the analytical expressions of ∂Aij/∂pi in each of the three regions of the state space of agent i do not coincide, as it will furthermore become evident in the next section.
Finally, note that the construction of a conical avoidance function for agent i (w.r.t) an agent j lying in the backward sensing footprint follows exactly the same logic, with the difference that the angle ϕij takes values in the interval [π + θi − α, π + θi + α], instead of the interval [θi − α, θi + α], and is omitted here in the interest of space.
2.3.3. Control strategy for pairwise collision avoidance
The function Aij given by equation (23) serves as an encoding of collision avoidance for agent i (w.r.t) agent j. Studying the evolution of its time derivative (w.r.t), the system trajectories may thus offer a way of designing control strategies that realize the safety of the overall multi-agent system. The time derivative of equation (23) reads:
where , k ∈ {i, j}.
Theorem 2. Assuming pairwise interactions among agents, collisions are avoided under the control strategy:
where is given by equation (11) and
Proof. Let us study the evolution of the time derivative of equation (23) in each region of the state space.
2.3.4. Region R1
In this region, one has: σij = 1 ⇔ |ϕij| ≥ α. Then, out of equation (23): Aij = 0. This implies that agent i does not take into account the collision avoidance objective for any agent j ≠ i which lies out of the sensing area . The linear and angular velocity for agent i may thus be dictated by the coverage control law equation (11).
2.3.5. Region R2
In this region, one has: 0 < σij < 1 ⇔ β < |ϕij| < α. Then out of equation (23): .
The analytical expression of the gradients involved in equation (25) in this case is given by equation (28), where:
Plugging equation (28) into equation (25) yields equation (30):
while substituting the angular velocity equation (27b) of agent i into equation (30) yields:
so that one finally has:
where pij = pi − pj, pji = pj − pi and Ωij < 0.
In region R2, it always holds that: . Thus, if the linear velocity ui of agent i is set as ui < 0, then the first term of the time derivative equation (31) is negative.
Consider the velocity equation (27a) where ki > 0, and study the effect of the second term in the evolution of the time derivative equation (31). Clearly, this depends on the orientation θj of agent j and its linear velocity uj. Let us consider the following cases.
2.3.5.1. Agent i lies in the sensing area of agent j. Then, for the same reasoning as for agent i, agent j realizes its own Lyapunov-like avoidance function Aji, given by equation (22) after replacing i with j and vice versa. The time derivative of this function, after setting the angular velocity wj equal to:
ends up reading:
where and the second term in equation (33) is non-positive.
Then setting the linear velocity for agent j equal to:
renders the first term in equation (33) negative. Note that the angular velocities equations (27b) and (32) coincide, which is consistent with what one would expect from physical intuition; namely, that for agents i and j facing each other, it is plausible to both rotate either clockwise, or counterclockwise, to avoid collision.
2.3.5.2. Agent i does not lie in the sensing area of agent j. This implies that agent j moves under the coverage control law . The signum of the linear velocity depends on the signum of . Also, one has that:
Let us go back to equation (31), which now reads:
and consider the following cases:
(a) and : then , ensuring that collision is avoided.
(b) and : then a sufficient condition on avoiding collision is to set:
Now note that:
which further reads that it suffices to choose the control gains so that:
Furthermore, in this region of the state space one has that: .1 Consequently, it suffices to pick the avoidance control gain:
(c) and : same as case (b).
(d) and : same as case (a).
2.3.6. Region R3
In this region, one has: σij = 0 ⇔ |ϕij| ≤ β. Then out of equation (22): Aij = Vij. Then:
This case reduces to equation (31) after setting σij = 0; thus, the same analysis as in the previous case follows regarding the linear velocity ui, which is set equal to equation (27a). The angular velocity ωi is set equal to .
The angular velocity control law equation (27b) for agent i requires information involving the state and control vectors of agent j, through the effect of dpj/dt. Denote the orthogonal vector to pij and consider the analytical expression of equation (27b), which reads:
The first term of equation (36) depends on the state vector of agent i only, and dictates that agent i should rotate clockwise (recall that we are considering the case ϕij > 0), forcing thus the sensing area away from agent j.
Finally, we would like to explore conditions under which the resulting maneuvering is sufficient for ensuring collision avoidance but without the need for information exchange between agents i and j, i.e., under the assumption that agent i does not sense or measure the linear velocity uj and the orientation θj of agent j and vice versa. This may also be seen as a robustness feature in the presence of communication failures.
To study the effect of the motion of agent j through uj and θj in equation (36), we consider the following two cases:
2.3.6.1. Agent i lies in the sensing area of agent j. Then, equation (36) further reads:
The signum of dictates the signum of the second term. More specifically:
(a) If : the second term is then negative, and furthermore renders a clockwise rotation for agent j. This condition (i.e., both agents rotating along the same direction) has the effect of setting each one out of the sensing area of the other. Consequently, the angular velocity for agent i can be taken out of equation (27b) with dpj/dt = 0.
(b) If : the second term is then positive, and furthermore renders a counterclockwise rotation for agent j. We would like to make sure that the angular velocity remains negative, i.e., that agent i will keep rotating clockwise to set agent j out of the sensing area . This condition reads:
It is now easy to verify that: (i) The maximum value of is achieved for agent i lying on the boundary of , where ϕji = −α. Thus, . (ii) The minimum value of is achieved for agent j lying on a point such that ϕij = β; recall that we are studying the case when β < ϕij < α. Thus, .
Substituting these values in equation (38) further yields: kj sin α < kj sin β. It is noteworthy that for ki = kj this inequality does not hold since 0 < β < α < π/2. This further means that we can not get any guarantees on the signum of the angular velocity unless we assume that the agents somehow exchange information on their control gains ki, kj (or their linear velocities ui, uj). Nevertheless, the condition equation (38) is quite conservative and only sufficient, not necessary. Furthermore, it does hold when the relative position of the agents i, j is such that: |ϕji| < ϕij. The condition for inter-agent collision avoidance is to ensure that ||pij|| > r, which is ensured through the linear control laws .
2.3.6.2. Agent i does not lie in the sensing area of agent j. This further implies that agent j moves under the coverage control law . Then the problem reduces into guaranteeing that: which has been treated before.
3. Results
The proposed control strategy equation (26), equation (11), equation (27) is evaluated through numerical simulations. We consider a scenario of 5 agents with sensing capabilities realized as conical sensing functions, which need to sufficiently explore a relatively open area D populated with two circular static obstacles. The area is a rectangle of dimension da = 25, the obstacles are positioned at po1 = [11 15]T, po2 = [15 5]T, respectively, and are of radius ro = 1. The satisfactory coverage level is set equal to C⋆ = 0.7, and this selection is guided based on the maximum value of the considered sensing function Si(⋅), which in this scenario is approximately 0.2. The sensing and coverage parameters are R = 6, r = 3, α = π/6. The agents know the positions and the geometry of the obstacles. The agents have also the ability of broadcast information to other agents regarding the areas they have individually covered, so that at least one agent (called the supervisor) has access to the globally covered area.
In Figures 7–9, dark blue stands for totally uncovered area (i.e., zero time has been spent on these points of D by the agents footprints), dark red stands for totally covered area (i.e., agents footprints have stayed on these points of D for the satisfactory amount of time encoded via C⋆), while color variations between dark blue and dark red stand for partially covered area, i.e., for points of D, which have been sensed by the agents footprints but not for the satisfactory amount of time.
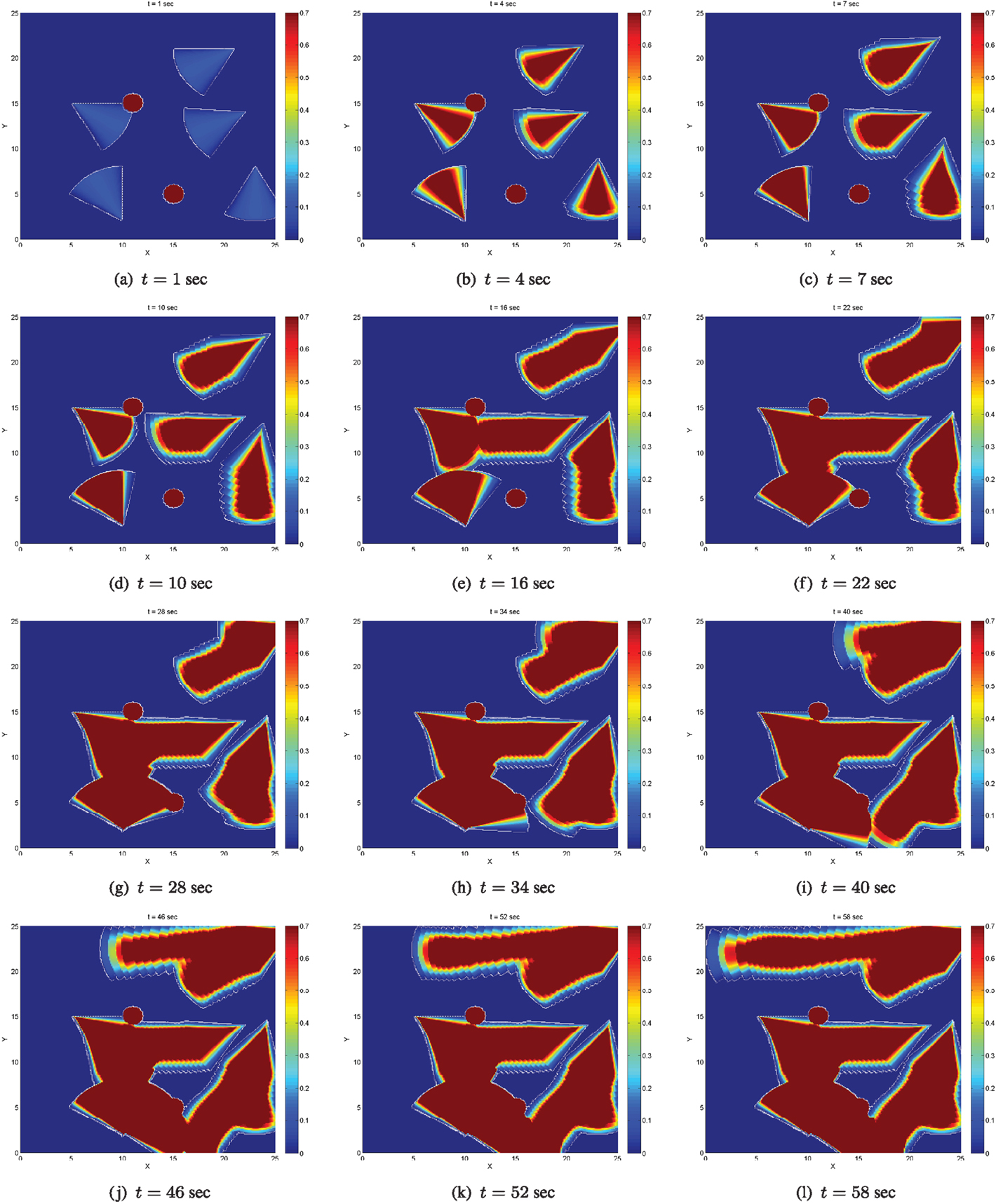
Figure 7. Evolution of the coverage level under the proposed control strategy equation (26).
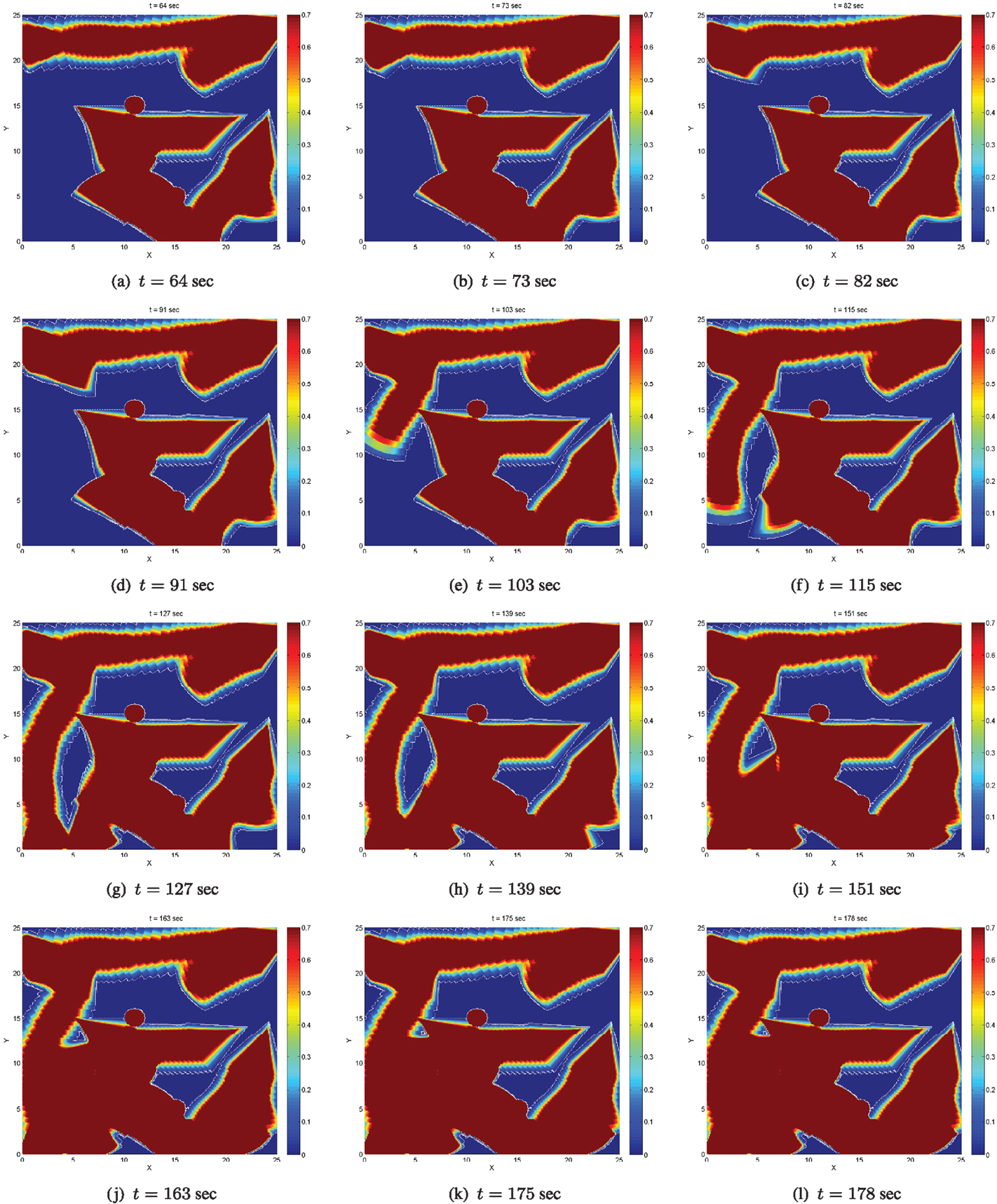
Figure 8. Evolution of the coverage level under the proposed control strategy equation (26).
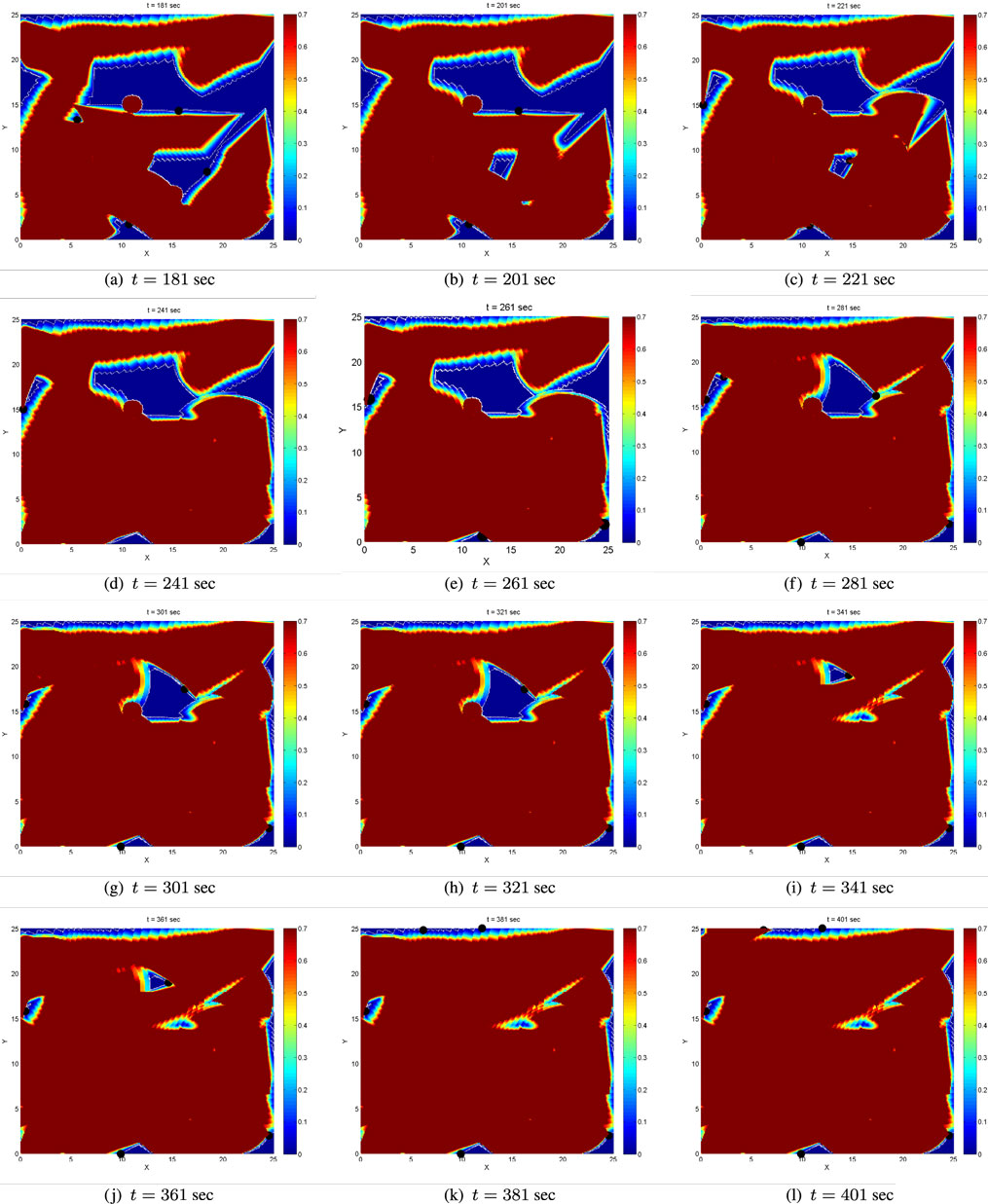
Figure 9. Evolution of the coverage level after the supervisory logic on global coverage has been activated for the first time.
The coverage level at initial time t = 0 is zero. Figures 7 and 8 depict the evolution of the coverage level over time under the control strategy equation (26) up to the time when all agents’ coverage errors equation (6) become very small, implying that the agents have practically stop moving. The boundaries of the sensing footprints are depicted with white lines. Focusing on the interior of the sensing footprints during at simulation time t = 1, one may notice that the color remains darker blue on the points closer to the boundaries of the footprints, while it gets lighter blue on the points closer to the centers of the footprints. This is consistent with the definition of the sensing function equation (4) and the coverage error equation (6) for each agent: recall that the sensing function equation (4) takes lower values close to the boundary of the sensing footprint, encoding that the sensor performance (“seeing”) is not good enough there, and higher values on the points in the interior and far away from the boundary, encoding that sensing performance is better there. Thus, more time is required to sense the points close to the boundary of the sensing footprint up to the satisfactory coverage level, and this is encoded via the coverage error equation (6). For this reason, the points in the interior of the sensing footprint but far away from its boundary turn red sooner than those closer to the boundary. Note also that the agents’ coverage errors equation (6) are exactly what sets them in motion via their coverage control laws equation (11). In other words, as long as the agents’ footprints touch points in D where the satisfactory coverage encoded via C⋆ has not been met, their control inputs realized via equation (11) are non-zero and therefore the agents keep moving toward zeroing their coverage errors.
In general, the area of the satisfactorily covered regions by a given number of agents under the control law equation (11) depends on the coverage (sensing) function equation (4), the parameter C⋆, the control law gains in equation (11), and the initial conditions. As expected and explained in Section 2.2, the agents may stop moving before the entire area D has necessarily been covered up to the satisfactory level. Let us define the global coverage error E(t) as the non-satisfactorily covered area at time t. In the considered scenario, the agents stop moving before the global coverage error E(t) has converged to zero; more specifically, the agents stop moving when almost 76% of the domain D has been sufficiently covered at time t = 180, as illustrated via the evolution of the (normalized) global coverage error E(t) in Figure 10A.
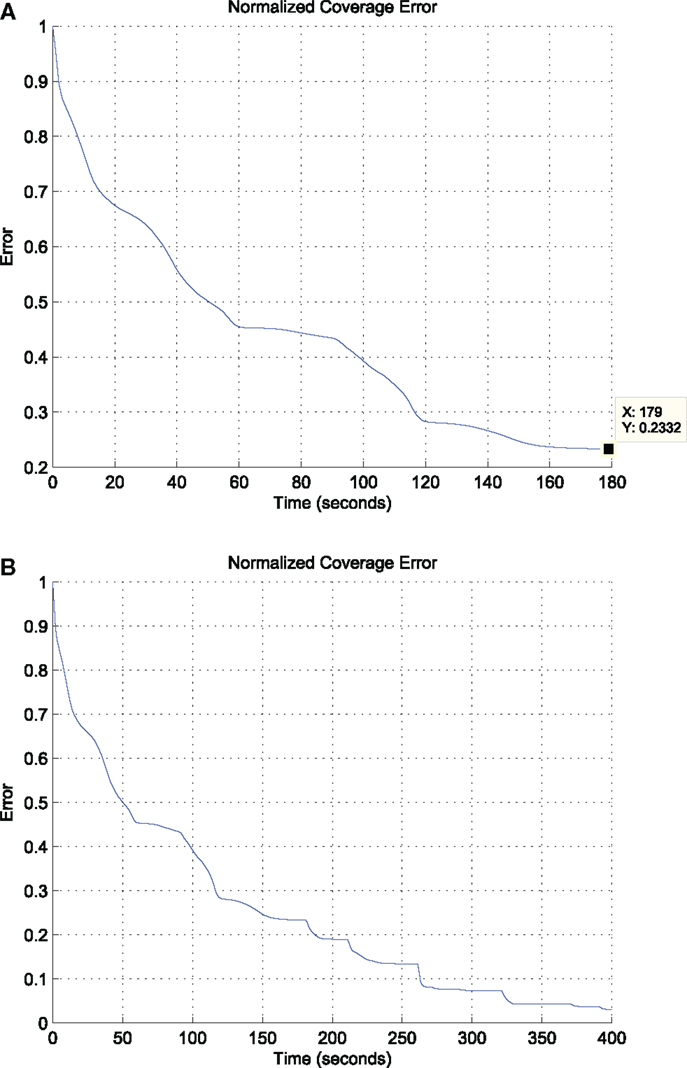
Figure 10. The evolution of the (normalized) global coverage error E(t) under (i) the proposed control strategy equation (26) (above) and (ii) under the same strategy facilitated with the supervisory global coverage controller, which takes action for the first time at time t = 180 (below). (A) Evolution of the global coverage error E(t) w.r.t time under the proposed control strategy equation (26). (B) Evolution of the global coverage error E(t) w.r.t time under the control strategy equation (26) and the supervisory logic on the global coverage control. The global coverage controller becomes active for the first time at time t = 180 and keeps getting active when the rate of change of the global coverage error E(t) becomes less than a given threshold.
A way to bypass this limitation is to additionally consider a global coverage controller, implemented by a supervisor agent who has an access to the coverage map of the environment, i.e., to the global coverage error E(t) at each time instant t, in the spirit proposed in Atinç et al. (2013). We modify the strategy in Atinç et al. (2013) to be compatible with the conic sensing footprints considered here. More specifically, we implement the following logic:
• If the normalized coverage error E(tk) is non-zero at some time instant tk and its absolute rate of change, realized as the difference |E(tk) − E(tk−1)/tk − tk−1| drops below a predefined level, then this physically means that the agents have driven their coverage errors ei(t) very close to zero. Thus, the supervisor agent needs to select new waypoints within the uncovered areas toward which the agents will move.
• The selection of waypoints is performed under the (heuristic) formula suggested in Atinç et al. (2013), which provides the closest point in the uncovered region of the domain D for each one of the agents. This search for the closest uncovered point in principle returns points, which lie on the boundaries between covered and uncovered regions, see also Figure 9, the waypoints depicted as black circles.
• The motion of the agents toward their waypoints can be guaranteed to be safe under the algorithms in our prior work (Panagou et al., 2013); nevertheless, the motion of the agents toward their waypoints is not simulated here.
• Once an agent has reached its assigned waypoint, it performs an in place rotation so that its sensing footprint touches the uncovered area and its coverage error defined by equation (6) becomes non-zero. Note that this maneuvering was not necessary in Atinç et al. (2013), as the sensing footprints considered there are circular; however, it is essential when it comes to conic sensing footprints. The agent switches to its coverage control law equation (11) and starts moving toward driving its coverage error equation (6) to zero.
• This process, i.e., switching between local and global coverage controllers, is repeated as many times as necessary, so that the normalized coverage error E(t) is forced to decrease and eventually to converge to zero.
During the selection of waypoints, the supervisor agent makes sure that waypoints close to physical obstacles or points, which will result in agents approaching closer than the safe distance are excluded. Note also that the shape of the uncovered areas cannot be predicted a priori, as this would involve the computation of the forward reachable sets of all agents for any possible initial condition, something which is impossible due to the curse of dimensionality (or state explosion) even when only few agents are concerned. However, given the aforementioned constraints, it is not impossible that searching for the closest uncovered point may not provide a feasible solution. Thus, the supervisor additionally monitors whether this search produces new waypoints for the agents, otherwise it selects waypoints, which lie in the interior of the uncovered areas in a randomized way, i.e., does not pick the closest uncovered points. This is the case at time t = 263 s, where under this selection two of the agents are forced to move to waypoints lying in the interior, not the boundary, of the uncovered area. The evolution of the (normalized) global coverage error E(t) including the periods when the supervisory logic is active is depicted in Figure 10B. The error E(t) is decreasing, and the switching between global and local coverage controllers can be repeated as many times as necessary until it converges to zero.
The formalization of these set of rules within a suitable control theoretic framework, e.g., by means of switched systems theory, so that specific performance guarantees can be acquired for the supervisory controller is beyond the scope of the current paper. Addressing questions such as how an agent, or a group of agents, can select waypoints in the uncovered areas in more efficient ways, i.e., not merely selecting the closed uncovered point, but rather try to select points, which satisfy various objectives, such as minimizing the total number of switches between local and global coverage controllers is ongoing work.
The evolution of inter-agent distances and agent-static obstacle distances under the proposed control strategy equation (26), i.e., before the supervisory logic takes action for the first time, is depicted in Figure 11A. The effect of the collision avoiding maneuvers imposed when pertinent by equation (26) becomes evident through the trajectories, which end up in the detection regions of the agents’. The detection radius is illustrated in green, while the avoidance radius, which encodes the minimum safe distance, is illustrated in red. The distances remain always greater than the avoidance radius, implying that the motion of the agents remains collision-free. Again, it is important to stress out that this strategy is suitable for pairwise interactions only, and for this reason the number of the agents and their initial conditions are chosen such that agents are not congested. Finally, the resulting agents’ paths under equation (26) are illustrated in Figure 11B. Initial positions are depicted with dots, final positions are depicted with “x.” It is worth noticing that some agents tend to travel larger distances compared to others, compare for instance the blue path over the green path. The reason is that the agent in green starts close to the boundary of the domain D, and therefore as it starts rotating toward zeroing its coverage error, its sensing footprint ends up touching outside the domain D, where the coverage error is by definition zero.
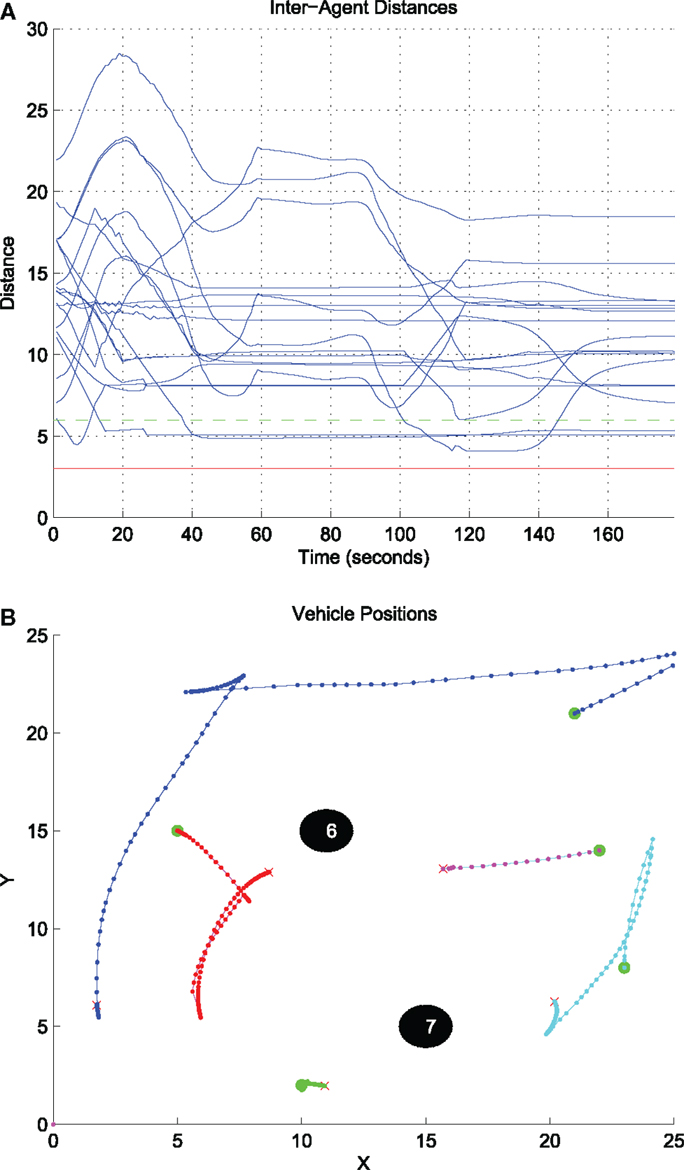
Figure 11. Inter-agent distances and resulting agents’ paths under the control strategy equation (26). (A) Evolution of the inter-agent distances dij w.r.t time under the control strategy equation (26). (B) The resulting paths under the control strategy equation (26).
4. Discussion
This paper presented a dynamic coverage control design for non-holonomic vehicles along with collision avoidance guarantees. The key difference compared to earlier similar work is the consideration of anisotropic sensing, which is relevant to vision-based control and surveillance applications. More specifically, we extended our earlier work (Panagou et al., 2013; Stipanovic et al., 2013) by considering a new dynamic coverage and avoidance control design, which can be implemented in a decentralizedfashion. The main difference here is the consideration of (i) anisotropic sensing, realized via conic sensing footprints and conic sensing (coverage) functions for each agent, and (ii) a novel form of avoidance functions. The considered sensing functions encode field-of-view and range constraints, and furthermore the degradation of effective sensing close to the boundaries of the sensing footprint. In this spirit, the proposed control design is suitable for surveillance tasks, where a group of robots is assigned with the task to gather enough information about an environment (such as video streaming or snapshots) locally, while avoiding collisions. The efficacy of the proposed control strategies has been demonstrated through numerical simulations for unicycle robots operating in a known environment populated with static circular obstacles.
Current work focuses on the consideration of supervisory logics to orchestrate efficient global coverage in a distributed sense along with certain performance guarantees, as well as on the consideration of agents with more complicated dynamics and constraints, such as Dubins-like vehicles.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work has been supported by Qatar National Research Fund under NPRP Grant 4-536-2-199 and the AFOSR grant FA95501210193. The authors would like to acknowledge the contribution of Dr. G. Atinç and Dr. C. Valicka through fruitful discussions and their help on the simulation implementations.
Footnote
- ^This inner product expresses the projection of the vector pij onto the body-fixed axis of agent i, while the value of this projection becomes minimum for agent j lying on the boundary of the sensing region of agent i, i.e., when ϕij = α.
References
Atinç, G., Stipanovíc, D. M., Voulgaris, P. G., and Karkoub, M. (2013). “Supervised coverage control with guaranteed collision avoidance and proximity maintenance,” in Proc. of the 2013 IEEE Conference on Decision and Control (Florence), 3463–3468.
Cheng, T. M., and Savkin, A. V. (2010). “Decentralized control of mobile sensor networks for triangular blanket coverage,” in Proc. of the 2010 American Control Conf (Baltimore, MD), 2903–2908.
Corless, M., and Leitmann, G. (1989). Adaptive controllers for avoidance or evasion in an uncertain environment: some examples. Comput. Math. Appl. 18, 161–170. doi: 10.1016/0898-1221(89)90133-8
Corless, M., Leitmann, G., and Skowronski, J. (1987). Adaptive control for avoidance or evasion in an uncertain environment. Comput. Math. Appl. 13, 1–11. doi:10.1109/IEMBS.2009.5333948
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Cortes, J., Martínez, S., Karatas, T., and Bullo, F. (2004). Coverage control for mobile sensing networks. IEEE Trans. Rob. Autom. 20, 243–255. doi:10.1109/TRA.2004.824698
Ferrari, S., Zhang, G., and Wettergren, T. A. (2010). Probabilistic track coverage in cooperative sensor networks. IEEE Trans. Syst. Man Cybern. 40, 1492–1504. doi:10.1109/TSMCB.2010.2041449
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Franco, C., López-Nicolás, G., Stipanovic, D. M., and Sagüés, C. (2012). “Anisotropic vision-based coverage control for mobile robots,” in IROS Workshop on Visual Control of Mobile Robots (Vilamoura), 31–36.
Gusrialdi, A., Hatanaka, T., and Fujita, M. (2008a). “Coverage control for mobile networks with limited-range anisotropic sensors,” in Proc. of the 47th IEEE Conf. on Decision and Control (Cancun), 4263–4268.
Gusrialdi, A., Hirche, S., Hatanaka, T., and Fujita, M. (2008b). “Voronoi based coverage control with anisotropic sensors,” in Proc. of the 2008 American Control Conf (Seattle, WA), 736–741.
Hexsel, B., Chakraborty, N., and Sycara, K. (2013). Distributed Coverage Control for Mobile Anisotropic Sensor Networks. Technical Report CMU-RI-TR-13-01. Pittsburgh, PA: Robotics Institute.
Hokayem, P., Stipanovíc, D., and Spong, M. (2007). “On persistent coverage control,” in Proc. of the 2007 IEEE Conference on Decision and Control (New Orleans, LA), 6130–6135.
Hussein, I. I., and Stipanovic, D. M. (2007). Effective coverage control for mobile sensor networks with guaranteed collision avoidance. IEEE Trans. Control Syst. Technol. 15, 642–657. doi:10.1109/TCST.2007.899155
Laventall, K., and Cortes, J. (2008). “Coverage control by robotic networks with limited-range anisotropic sensory,” in Proc. of the 2008 American Control Conference (Seattle, WA), 2666–2671.
Leitmann, G. (1980). Guaranteed avoidance strategies. J. Optim. Theory Appl. 32, 569–576. doi:10.1007/BF00934040
Leitmann, G., and Skowronski, J. (1977). Avoidance control. J. Optim. Theory Appl. 23, 581–591. doi:10.1007/BF00933298
Leitmann, G., and Skowronski, J. (1983). A note on avoidance control. Optim. Control Appl. Methods 4, 335–342. doi:10.1002/oca.4660040406
Panagou, D., Stipanovic, D. M., and Voulgaris, P. G. (2013). “Multi-objective control for multi-agent systems using Lyapunov-like barrier functions,” in Proc. of the 52nd IEEE Conference on Decision and Control (Florence), 1478–1483.
Panagou, D., Stipanovic, D. M., and Voulgaris, P. G. (2014). “Vision-based dynamic coverage control for multiple nonholonomic agents,” in Proc. of the 53rd IEEE Conference on Decision and Control (Los Angeles, CA).
Schwager, M., Slotine, J., and Rus, D. (2011). Unifying geometric, probabilistic and potential field approaches to multi-robot coverage control. Int. J. Rob. Res. 30, 371–383. doi:10.1177/0278364910383444
Stipanovic, D. M., Valicka, C., Tomlin, C. J., and Bewley, T. R. (2013). Safe and reliable coverage control. Numer. Algebra Contr. Optim. 3, 31–48. doi:10.3934/naco.2013.3.31
Keywords: coverage algorithms, multi-agent systems, cooperative control, collision avoidance, vision-based control
Citation: Panagou D, Stipanović DM and Voulgaris PG (2015) Dynamic coverage control in unicycle multi-robot networks under anisotropic sensing. Front. Robot. AI 2:3. doi: 10.3389/frobt.2015.00003
Received: 08 September 2014; Accepted: 06 February 2015;
Published online: 10 March 2015.
Edited by:
Konstantinos Bekris, Rutgers University, USAReviewed by:
Konstantinos Karydis, University of Delaware, USARoberto Tron, University of Pennsylvania, USA
Copyright: © 2015 Panagou, Stipanović and Voulgaris. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dimitra Panagou, Department of Aerospace Engineering, University of Michigan, 3057 Francois-Xavier Bagnoud Building, 1320 Beal Avenue, Ann Arbor, MI 48109-2140, USA e-mail: dpanagou@umich.edu